17 Des 2025·6 menit
Pooling koneksi PostgreSQL: pooling aplikasi vs PgBouncer
Pooling koneksi PostgreSQL: bandingkan pool di aplikasi dan PgBouncer untuk backend Go, metrik yang dipantau, dan misconfig yang memicu lonjakan latensi.
Pooling koneksi PostgreSQL: bandingkan pool di aplikasi dan PgBouncer untuk backend Go, metrik yang dipantau, dan misconfig yang memicu lonjakan latensi.
Sebuah koneksi database seperti saluran telepon antara aplikasi Anda dan Postgres. Membukanya butuh waktu dan kerja di kedua sisi: setup TCP/TLS, autentikasi, memori, dan sebuah proses backend di sisi Postgres. Pool koneksi menjaga sejumlah kecil “saluran telepon” ini tetap terbuka sehingga aplikasi bisa menggunakannya ulang daripada men-dial untuk setiap permintaan.
Saat pooling dimatikan atau ukuran pool tidak tepat, Anda jarang mendapat error yang rapi dulu. Yang muncul adalah kelambatan acak. Permintaan yang biasanya 20–50 ms tiba-tiba jadi 500 ms atau 5 detik, dan p95 melejit. Lalu muncul timeout, diikuti oleh “too many connections,” atau antrian di dalam aplikasi sambil menunggu koneksi bebas.
Batas koneksi penting bahkan untuk aplikasi kecil karena traffic itu bursty. Email marketing, cron job, atau beberapa endpoint lambat bisa membuat puluhan permintaan menghantam database sekaligus. Jika setiap permintaan membuka koneksi baru, Postgres bisa menghabiskan kapasitasnya hanya untuk menerima dan mengelola koneksi alih-alih menjalankan query. Jika Anda sudah punya pool tapi terlalu besar, Anda bisa membanjiri Postgres dengan terlalu banyak backend aktif dan memicu context switching serta tekanan memori.
Waspadai gejala awal seperti:
Pooling mengurangi churn koneksi dan membantu Postgres menangani lonjakan. Pooling tidak akan memperbaiki SQL yang lambat. Jika sebuah query melakukan full table scan atau menunggu lock, pooling lebih mengubah cara sistem gagal (antrian lebih cepat, timeout belakangan), bukan membuatnya cepat.
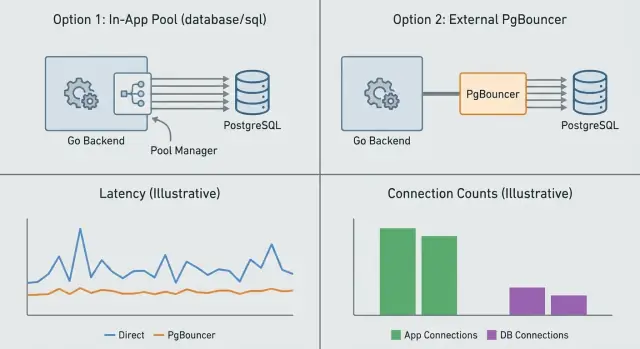
Pooling koneksi tentang mengendalikan berapa banyak koneksi database yang ada sekaligus dan bagaimana mereka digunakan ulang. Anda bisa melakukan ini di dalam aplikasi (app-level pooling) atau dengan layanan terpisah di depan Postgres (PgBouncer). Keduanya menyelesaikan masalah terkait tapi berbeda.
App-level pooling (di Go, biasanya pool bawaan database/sql) mengelola koneksi per proses. Ia memutuskan kapan membuka koneksi baru, kapan memakai ulang, dan kapan menutup yang idle. Ini menghindari biaya setup di setiap permintaan. Yang tidak bisa dilakukannya adalah berkoordinasi antar banyak instance aplikasi. Jika Anda menjalankan 10 replika, pada dasarnya Anda mempunyai 10 pool terpisah.
PgBouncer berada di antara aplikasi dan Postgres dan melakukan pooling atas nama banyak klien. Ini paling berguna ketika Anda punya banyak permintaan pendek, banyak instance aplikasi, atau traffic yang spiky. Ia membatasi koneksi sisi server ke Postgres meski ratusan koneksi klien tiba bersamaan.
Pembagian sederhana tanggung jawab:
Keduanya bisa bekerja bersama tanpa masalah “double pooling” selama setiap lapisan punya tujuan jelas: pool database/sql yang masuk akal per proses Go, plus PgBouncer untuk menegakkan anggaran koneksi global.
Kebingungan umum adalah berpikir “lebih banyak pool berarti lebih banyak kapasitas.” Biasanya berarti sebaliknya. Jika setiap service, worker, dan replika punya pool besar sendiri, total koneksi bisa meledak dan menyebabkan antrian, context switching, dan lonjakan latensi tiba-tiba.
database/sql di Go sebenarnya berperilakuDi Go, sql.DB adalah pengelola pool koneksi, bukan satu koneksi tunggal. Ketika Anda memanggil db.Query atau db.Exec, database/sql mencoba memakai koneksi idle. Jika tidak ada, ia mungkin membuka yang baru (sampai batas Anda) atau membuat permintaan menunggu.
Di situlah “mystery latency” sering muncul. Ketika pool jenuh, permintaan mengantri di dalam aplikasi. Dari luar, terlihat seperti Postgres melambat, padahal waktu sebenarnya dihabiskan menunggu koneksi yang bebas.
Sebagian besar tuning berakhir pada empat pengaturan:
MaxOpenConns: batas keras untuk koneksi terbuka (idle + in use). Ketika tercapai, pemanggil akan diblokir.MaxIdleConns: berapa banyak koneksi yang bisa siap untuk digunakan. Terlalu rendah menyebabkan reconnect sering.ConnMaxLifetime: memaksa daur ulang koneksi secara periodik. Berguna untuk load balancer dan timeout NAT, tapi terlalu pendek menyebabkan churn.ConnMaxIdleTime: menutup koneksi yang tidak dipakai terlalu lama.Pemakaian ulang koneksi biasanya menurunkan latency dan CPU database karena Anda menghindari setup berulang (TCP/TLS, auth, inisialisasi session). Tapi pool yang terlalu besar bisa melakukan sebaliknya: membolehkan lebih banyak query konkuren daripada yang bisa ditangani Postgres dengan baik, meningkatkan kontensi dan overhead.
Pikirkan dalam total, bukan per proses. Jika setiap instance Go membolehkan 50 koneksi terbuka dan Anda skala ke 20 instance, pada dasarnya Anda mengizinkan 1.000 koneksi. Bandingkan angka itu dengan apa yang server Postgres Anda bisa jalankan dengan mulus.
Pendekatan praktis adalah mengikat MaxOpenConns ke concurrency yang diharapkan per instance, lalu validasi dengan metrik pool (in-use, idle, dan wait time) sebelum meningkatkannya.
PgBouncer adalah proxy kecil antara aplikasi Anda dan PostgreSQL. Service Anda terhubung ke PgBouncer, dan PgBouncer memegang sejumlah koneksi server nyata ke Postgres. Saat lonjakan, PgBouncer mengantri pekerjaan klien alih-alih langsung membuat lebih banyak backend Postgres. Antrian itu bisa menjadi pembeda antara perlambatan terkontrol dan database yang tumbang.
PgBouncer punya tiga mode pooling:
Session pooling paling mirip dengan koneksi langsung ke Postgres. Ini paling sedikit mengejutkan, tapi menghemat lebih sedikit koneksi server saat beban bursty.
Untuk API HTTP Go tipikal, transaction pooling sering menjadi default yang baik. Sebagian besar permintaan melakukan query singkat atau transaksi kecil, lalu selesai. Transaction pooling memungkinkan banyak koneksi klien berbagi anggaran koneksi Postgres yang lebih kecil.
Tradeoff-nya adalah state sesi. Dalam mode transaction, apa pun yang mengandalkan koneksi server yang sama bisa rusak atau berperilaku aneh, termasuk:
SET, SET ROLE, search_path)Jika aplikasi Anda bergantung pada tipe state seperti itu, session pooling lebih aman. Statement pooling paling membatasi dan jarang cocok untuk web app.
Aturan praktis: jika setiap permintaan bisa menyiapkan apa yang dibutuhkannya di dalam satu transaksi, transaction pooling cenderung menjaga latensi lebih stabil saat beban. Jika Anda butuh perilaku session jangka panjang, gunakan session pooling dan fokus pada batasan di aplikasi.
Jika Anda menjalankan service Go dengan database/sql, Anda sudah punya pooling sisi aplikasi. Untuk banyak tim, itu cukup: beberapa instance, traffic stabil, dan query yang tidak sangat spike-y. Dalam setelan itu, pilihan paling sederhana dan aman adalah menyetel pool Go, menjaga batas koneksi database realistis, dan berhenti di situ.
PgBouncer paling membantu ketika database mendapat terlalu banyak koneksi klien sekaligus. Ini terlihat pada banyak instance aplikasi (atau skala bergaya serverless), traffic bursty, dan banyak query pendek.
PgBouncer juga bisa merugikan jika digunakan dalam mode yang salah. Jika kode Anda bergantung pada state session (temporary table, prepared statement yang dipakai lintas request, advisory lock yang dipegang antar panggilan, atau pengaturan session-level), transaction pooling bisa menyebabkan kegagalan membingungkan. Jika Anda benar-benar butuh perilaku session, gunakan session pooling atau lewati PgBouncer dan atur pool aplikasi dengan hati-hati.
Gunakan aturan ini:
Batas koneksi adalah anggaran. Jika Anda menghabiskannya sekaligus, setiap permintaan baru menunggu dan tail latency melonjak. Tujuannya adalah membatasi concurrency dengan cara terkontrol sambil menjaga throughput tetap stabil.
Ukur puncak hari ini dan tail latency. Catat peak active connections (bukan rata-rata), plus p50/p95/p99 untuk permintaan dan query kunci. Catat error koneksi atau timeout.
Tentukan anggaran koneksi Postgres yang aman untuk aplikasi. Mulai dari max_connections dan kurangi ruang untuk akses admin, migration, background job, dan lonjakan. Jika beberapa service berbagi database, bagi anggaran itu dengan sengaja.
Peta anggaran ke batas Go per instance. Bagi anggaran aplikasi dengan jumlah instance dan atur MaxOpenConns ke angka itu (atau sedikit lebih rendah). Atur MaxIdleConns cukup tinggi untuk menghindari reconnect terus-menerus, dan atur lifetime supaya koneksi ter-recycle sesekali tanpa churn.
Tambahkan PgBouncer hanya jika perlu, dan pilih mode. Gunakan session pooling jika Anda butuh state session. Gunakan transaction pooling ketika Anda ingin pengurangan terbesar pada koneksi server dan aplikasi kompatibel.
Roll out bertahap dan bandingkan sebelum/ sesudah. Ubah satu hal tiap kali, lakukan canary, lalu bandingkan tail latency, pool wait time, dan CPU database.
Contoh: jika Postgres aman memberi service Anda 200 koneksi dan Anda menjalankan 10 instance Go, mulai dengan MaxOpenConns=15-18 per instance. Itu memberi ruang untuk lonjakan dan mengurangi kemungkinan setiap instance mencapai batas bersamaan.
Masalah pooling jarang muncul pertama kali sebagai “too many connections.” Lebih sering Anda melihat kenaikan lambat pada wait time lalu lonjakan p95 dan p99.
Mulai dari apa yang dilaporkan aplikasi Go Anda. Dengan database/sql, pantau open connections, in-use, idle, wait count, dan wait time. Jika wait count naik sementara traffic tetap, pool Anda terlalu kecil atau koneksi ditahan terlalu lama.
Di sisi database, lacak active connections vs max, CPU, dan aktivitas lock. Jika CPU rendah tapi latency tinggi, seringkali itu antrian atau lock, bukan pemrosesan mentah.
Jika Anda menjalankan PgBouncer, tambahkan pandangan ketiga: client connections, server connections ke Postgres, dan queue depth. Antrian yang tumbuh dengan server connections stabil jelas menunjukkan anggaran tersaturasi.
Sinyal alert yang baik:
Masalah pooling sering muncul saat lonjakan: permintaan menumpuk menunggu koneksi, lalu semuanya kembali normal. Akar masalah sering pengaturan yang masuk akal pada satu instance tapi berbahaya ketika Anda menjalankan banyak salinan service.
Penyebab umum:
MaxOpenConns set per instance tanpa anggaran global. 100 koneksi per instance di 20 instance menjadi 2.000 koneksi potensial.ConnMaxLifetime / ConnMaxIdleTime terlalu pendek. Ini bisa memicu reconnect storm saat banyak koneksi direcycle bersamaan.Cara sederhana mengurangi lonjakan adalah memperlakukan pooling sebagai batas bersama, bukan default lokal aplikasi: batasi total koneksi di semua instance, pertahankan pool idle yang moderat, dan gunakan lifetime yang cukup panjang untuk menghindari reconnect sinkron.
Saat traffic melonjak, biasanya Anda melihat salah satu dari tiga hasil: permintaan mengantri menunggu koneksi bebas, permintaan timeout, atau semuanya melambat sehingga retry menumpuk.
Queueing adalah yang licik. Handler Anda masih berjalan, tapi parkir menunggu koneksi. Waktu tunggu itu menjadi bagian dari waktu respons, jadi pool kecil bisa mengubah query 50 ms menjadi endpoint beberapa detik di bawah beban.
Model mental yang membantu: jika pool Anda punya 30 koneksi yang dapat dipakai dan tiba-tiba ada 300 permintaan konkuren yang semuanya butuh DB, 270 harus menunggu. Jika setiap permintaan memegang koneksi 100 ms, tail latency cepat melonjak ke detik.
Tetapkan anggaran timeout yang jelas dan patuhi. Timeout aplikasi harus sedikit lebih pendek daripada timeout database agar Anda gagal cepat dan mengurangi tekanan alih-alih membiarkan pekerjaan menggantung.
statement_timeout supaya satu query buruk tidak menghabiskan koneksiLalu tambahkan backpressure agar Anda tidak membanjiri pool sejak awal. Pilih satu atau dua mekanisme yang dapat diprediksi, seperti membatasi concurrency per endpoint, shedding beban dengan error jelas (mis. 429), atau memisahkan background job dari traffic user.
Akhirnya, perbaiki query lambat dulu. Di bawah tekanan pooling, query lambat menahan koneksi lebih lama, yang meningkatkan wait, yang meningkatkan timeout, yang memicu retry. Lingkaran umpan balik itu mengubah “sedikit lambat” menjadi “semua lambat.”
Anggap load testing sebagai cara untuk memvalidasi anggaran koneksi Anda, bukan hanya throughput. Tujuannya mengonfirmasi bahwa pooling berperilaku di bawah tekanan sama seperti di staging.
Uji dengan traffic realistis: campuran permintaan yang sama, pola burst yang sama, dan jumlah instance aplikasi yang sama seperti di produksi. Benchmark “satu endpoint” sering menyembunyikan masalah pool sampai hari peluncuran.
Sertakan warm-up supaya Anda tidak mengukur cold cache dan efek ramp-up. Biarkan pool mencapai ukuran normalnya, lalu mulai merekam angka.
Jika Anda membandingkan strategi, pertahankan beban identik dan jalankan:
database/sql, tanpa PgBouncer)Setelah tiap run, catat scorecard kecil yang bisa Anda pakai ulang setelah setiap rilis:
Seiring waktu, ini mengubah capacity planning menjadi sesuatu yang dapat diulang alih-alih tebak-tebakan.
Sebelum mengubah ukuran pool, catat satu angka: anggaran koneksi Anda. Itu adalah jumlah maksimal koneksi Postgres aktif yang aman untuk environment ini (dev, staging, prod), termasuk background job dan akses admin. Jika Anda tidak bisa menyebutkannya, Anda menebak.
Checklist singkat:
MaxOpenConns) sesuai anggaran (atau cap PgBouncer).max_connections dan koneksi yang dicadangkan sesuai rencana Anda.Rencana rollout yang memudahkan rollback:
Jika Anda membangun dan meng-host aplikasi Go + PostgreSQL di Koder.ai (koder.ai), Planning Mode dapat membantu memetakan perubahan dan apa yang akan Anda ukur, dan snapshot plus rollback memudahkan revert jika tail latency memburuk.
Langkah berikutnya: tambahkan satu pengukuran sebelum lonjakan traffic berikutnya. “Time spent waiting for a connection” di aplikasi sering kali paling berguna, karena menunjukkan tekanan pooling sebelum pengguna merasakannya.
Sebuah pool menjaga sejumlah kecil koneksi PostgreSQL tetap terbuka dan menggunakannya ulang untuk beberapa permintaan. Ini menghindari biaya pembukaan koneksi berulang (TCP/TLS, autentikasi, proses backend) sehingga membantu menjaga tail latency tetap stabil saat lonjakan traffic.
Ketika pool penuh, permintaan menunggu di dalam aplikasi untuk koneksi yang bebas, dan waktu tunggu itu muncul sebagai respons lambat. Karena itu sering terjadi secara sporadis selama lonjakan, rata-rata bisa tetap normal sementara p95/p99 melonjak.
Tidak. Pooling mengubah bagaimana sistem berperilaku di bawah beban dengan mengurangi churn koneksi dan mengendalikan concurrency. Jika query lambat karena full table scan, lock, atau indeks yang buruk, pooling tidak akan membuatnya cepat; pooling hanya membatasi berapa banyak query lambat yang berjalan bersamaan.
App-level pooling mengelola koneksi per proses sehingga setiap instance aplikasi mempunyai pool sendiri dan batasannya sendiri. PgBouncer berdiri di depan Postgres dan menerapkan anggaran koneksi global di antara banyak client — berguna ketika ada banyak replika atau traffic yang spiky.
Jika Anda menjalankan sedikit instance dan total koneksi terbuka tetap jauh di bawah batas database, menyetel pool database/sql di Go biasanya sudah cukup. Tambahkan PgBouncer ketika banyak instance, autoscaling, atau traffic bursty dapat mendorong total koneksi melampaui kapasitas Postgres.
Tentukan anggaran koneksi total untuk layanan, bagi dengan jumlah instance, lalu atur MaxOpenConns sedikit di bawah angka itu per instance. Mulai dari kecil, pantau wait time dan p95/p99, dan naikkan hanya jika Anda yakin database masih punya headroom.
Untuk API HTTP tipikal, transaction pooling sering menjadi default yang baik karena memungkinkan banyak koneksi klien berbagi lebih sedikit koneksi server dan tetap stabil saat lonjakan. Gunakan session pooling jika kode Anda bergantung pada state sesi yang bertahan antar statement.
Prepared statement, temp table, advisory lock, dan pengaturan session-level bisa berperilaku berbeda karena klien mungkin tidak selalu mendapat koneksi server yang sama. Jika Anda membutuhkan fitur-fitur itu, jalankan semua yang diperlukan dalam satu transaksi per permintaan atau gunakan session pooling.
Pantau p95/p99 bersama metrik wait time pool di aplikasi, karena wait time sering naik sebelum pengguna merasakan masalah. Di Postgres, perhatikan active connections, CPU, dan lock; di PgBouncer, pantau client connections, server connections, dan queue depth untuk melihat apakah anggaran koneksi tersaturasi.
Pertama, hentikan menunggu tanpa batas dengan menetapkan deadline permintaan dan statement_timeout sehingga satu query buruk tidak memegang koneksi selamanya. Lalu tambahkan backpressure: batasi concurrency pada endpoint berat DB, lempar 429 untuk shedding, dan hindari lifetime koneksi yang terlalu pendek yang memicu reconnect storm.