07 Agu 2025·8 menit
Noam Shazeer dan Arsitektur Transformer di Balik LLM
Pelajari bagaimana Noam Shazeer ikut membentuk Transformer: self-attention, multi-head attention, dan mengapa desain ini menjadi tulang punggung LLM modern.
Pelajari bagaimana Noam Shazeer ikut membentuk Transformer: self-attention, multi-head attention, dan mengapa desain ini menjadi tulang punggung LLM modern.
Transformer adalah cara membantu komputer memahami urutan—hal-hal di mana urutan dan konteks penting, seperti kalimat, kode, atau rangkaian kueri pencarian. Alih-alih membaca satu token sekaligus dan mengandalkan memori rapuh, Transformer melihat seluruh urutan dan memutuskan apa yang harus diperhatikan saat menafsirkan setiap bagian.
Perubahan sederhana itu ternyata berpengaruh besar. Ini salah satu alasan utama mengapa model bahasa besar modern (LLM) bisa mempertahankan konteks, mengikuti instruksi, menulis paragraf yang koheren, dan menghasilkan kode yang merujuk fungsi dan variabel sebelumnya.
Jika Anda pernah menggunakan chatbot, fitur “ringkas ini”, pencarian semantik, atau asisten pengkodean, Anda sudah berinteraksi dengan sistem berbasis Transformer. Cetak biru inti yang sama mendukung:
Kita akan memecah bagian-bagian kunci—self-attention, multi-head attention, positional encoding, dan blok Transformer dasar—serta menjelaskan kenapa desain ini sangat mudah diskalakan seiring model membesar.
Kita juga akan menyinggung varian modern yang menjaga ide inti sama tetapi mengubahnya untuk kecepatan, biaya, atau jendela konteks lebih panjang.
Ini tur tingkat tinggi dengan penjelasan bahasa awam dan sedikit matematika. Tujuannya membangun intuisi: apa fungsi bagian-bagian, mengapa mereka bekerja bersama, dan bagaimana itu diterjemahkan ke kapabilitas produk nyata.
Noam Shazeer adalah peneliti dan insinyur AI yang paling dikenal sebagai salah satu penulis bersama paper 2017 “Attention Is All You Need.” Paper itu memperkenalkan arsitektur Transformer, yang kemudian menjadi fondasi banyak model bahasa besar (LLM) modern. Karya Shazeer berada dalam konteks kerja tim: Transformer dibuat oleh sekelompok peneliti di Google, dan penting memberi kredit seperti itu.
Sebelum Transformer, banyak sistem NLP bergantung pada model rekuren yang memproses teks langkah demi langkah. Proposal Transformer menunjukkan bahwa urutan bisa dimodelkan secara efektif tanpa rekuren dengan menggunakan attention sebagai mekanisme utama untuk menggabungkan informasi di seluruh kalimat.
Perubahan itu penting karena membuat pelatihan lebih mudah diparalelkan (Anda bisa memproses banyak token sekaligus), dan membuka jalan untuk menskalakan model dan dataset dengan cara yang cepat menjadi praktis untuk produk nyata.
Kontribusi Shazeer—bersama penulis lain—tidak berhenti di benchmark akademik. Transformer menjadi modul yang dapat digunakan kembali yang bisa diadaptasi tim: menukar komponen, mengubah ukuran, menyetel untuk tugas, dan kelak melakukan pretrain pada skala besar.
Inilah bagaimana banyak terobosan menyebar: sebuah paper memperkenalkan resep umum; insinyur merinci; perusahaan mengoperasionalkan; dan akhirnya itu menjadi pilihan default untuk membangun fitur bahasa.
Tepat untuk mengatakan Shazeer adalah kontributor kunci dan salah satu penulis paper Transformer. Tidak tepat menggambarkannya sebagai penemu tunggal. Dampak datang dari desain kolektif—dan dari banyak peningkatan lanjutan yang dibangun komunitas di atas cetak biru awal itu.
Sebelum Transformer, sebagian besar masalah urutan (terjemahan, ucapan, generasi teks) didominasi oleh Recurrent Neural Networks (RNN) dan kemudian LSTMs (Long Short-Term Memory). Ide besarnya sederhana: baca teks satu token pada satu waktu, simpan “memori” berjalan (hidden state), dan gunakan state itu untuk memprediksi apa yang berikutnya.
RNN memproses kalimat seperti rantai. Setiap langkah memperbarui hidden state berdasarkan kata saat ini dan hidden state sebelumnya. LSTM memperbaiki ini dengan menambahkan gerbang yang memutuskan apa yang disimpan, dilupakan, atau dikeluarkan—memudahkan untuk mempertahankan sinyal berguna lebih lama.
Dalam praktik, memori sekuensial punya hambatan: banyak informasi harus dipadatkan lewat satu state saat kalimat memanjang. Bahkan dengan LSTM, sinyal dari kata yang jauh di awal bisa memudar atau tertumpuk.
Ini menyulitkan pembelajaran hubungan tertentu secara andal—misalnya menghubungkan kata ganti dengan kata benda yang benar beberapa kata sebelumnya, atau melacak topik di beberapa klausa.
RNN dan LSTM juga lambat dilatih karena tidak bisa sepenuhnya diparalelkan sepanjang waktu. Anda bisa melakukan batch di banyak kalimat, tetapi dalam satu kalimat, langkah 50 bergantung pada langkah 49, yang bergantung pada 48, dan seterusnya.
Perhitungan langkah-demi-langkah ini menjadi batas serius saat Anda menginginkan model lebih besar, lebih banyak data, dan eksperimen lebih cepat.
Para peneliti butuh desain yang dapat mengaitkan kata-kata satu sama lain tanpa harus maju-kiri-ke-kanan selama pelatihan—cara untuk memodelkan hubungan jarak jauh langsung dan memanfaatkan hardware modern. Tekanan ini membuka panggung untuk pendekatan attention-pertama yang diperkenalkan di Attention Is All You Need.
Attention adalah cara model bertanya: "Kata-kata lain mana yang harus saya lihat sekarang untuk memahami kata ini?" Alih-alih membaca kalimat tegas kiri-ke-kanan dan mengandalkan memori, attention membiarkan model mengintip bagian paling relevan dari kalimat saat dibutuhkan.
Modelnya seperti mesin pencari kecil yang berjalan di dalam kalimat.
Model membentuk query untuk posisi saat ini, membandingkannya dengan keys semua posisi, lalu mengambil campuran values.
Perbandingan itu menghasilkan skor relevansi: sinyal kasar "seberapa terkait ini?". Model lalu mengubahnya menjadi bobot attention, proporsi yang jumlahnya menjadi 1.
Jika satu kata sangat relevan, ia mendapat porsi fokus yang lebih besar. Jika beberapa kata penting, attention bisa tersebar di antara mereka.
Ambil: “Maria told Jenna that she would call later.”
Untuk menafsirkan she, model harus melihat kandidat seperti “Maria” dan “Jenna.” Attention memberi bobot lebih tinggi pada nama yang paling cocok dengan konteks.
Atau pertimbangkan: “The keys to the cabinet are missing.” Attention membantu menghubungkan “are” ke “keys” (subjek sebenarnya), bukan “cabinet,” meskipun “cabinet” lebih dekat. Manfaat inti: attention menghubungkan makna melintasi jarak, sesuai kebutuhan.
Self-attention adalah gagasan bahwa setiap token dalam urutan dapat melihat token-token lain dalam urutan yang sama untuk memutuskan apa yang penting sekarang. Alih-alih memproses kata secara ketat kiri-ke-kanan (seperti model rekuren lama), Transformer membiarkan setiap token mengumpulkan petunjuk dari mana saja dalam input.
Bayangkan kalimat: “I poured the water into the cup because it was empty.” Kata “it” harus terhubung ke “cup,” bukan “water.” Dengan self-attention, token untuk “it” memberi bobot lebih tinggi ke token yang membantu menyelesaikan maknanya (“cup,” “empty”) dan bobot lebih rendah ke yang tidak relevan.
Setelah self-attention, setiap token bukan lagi hanya dirinya sendiri. Ia menjadi versi yang sadar-konteks—campuran berbobot informasi dari token lain. Anda bisa memikirkan setiap token membuat ringkasan yang dipersonalisasi dari seluruh kalimat, disesuaikan dengan apa yang dibutuhkan token itu.
Secara praktis, ini berarti representasi “cup” dapat membawa sinyal dari “poured,” “water,” dan “empty,” sementara “empty” bisa menarik apa yang dijelaskannya.
Karena setiap token dapat menghitung attentionnya atas seluruh urutan pada saat yang sama, pelatihan tidak perlu menunggu token sebelumnya diproses langkah demi langkah. Pemrosesan paralel ini adalah alasan utama Transformer efisien dilatih pada dataset besar dan dapat diskalakan ke model besar.
Self-attention mempermudah menghubungkan bagian teks yang berjauhan. Sebuah token dapat langsung fokus pada kata yang relevan jauh di tempat lain—tanpa meneruskan informasi melalui rantai panjang langkah menengah.
Jalur langsung ini membantu tugas seperti koreferensi ("she", "it", "they"), melacak topik antar paragraf, dan menangani instruksi yang bergantung pada detail sebelumnya.
Satu mekanisme attention sangat kuat, tapi masih seperti mencoba memahami percakapan hanya dari satu sudut kamera. Kalimat sering mengandung beberapa hubungan sekaligus: siapa melakukan apa, apa yang dimaksud "itu", kata-kata yang menentukan nada, dan topik umum.
Saat Anda membaca “The trophy didn’t fit in the suitcase because it was too small,” Anda mungkin perlu melacak beberapa petunjuk sekaligus (tata bahasa, makna, konteks dunia nyata). Satu "head" attention mungkin tertarik pada kata benda terdekat; head lain bisa memakai frasa kerja untuk menentukan apa yang dirujuk "it".
Multi-head attention menjalankan beberapa perhitungan attention secara paralel. Setiap “head” didorong untuk melihat kalimat melalui lensa berbeda—sering digambarkan sebagai subruang berbeda. Dalam praktik, head bisa mengkhususkan diri pada pola seperti:
Setelah setiap head menghasilkan wawasan masing-masing, model tidak memilih hanya satu. Ia menggabungkan (concatenate) keluaran head (menyusunnya berdampingan) lalu memproyeksikannya kembali ke ruang kerja utama model dengan lapisan linear yang dipelajari.
Pikirkan ini seperti menggabungkan beberapa catatan parsial menjadi satu ringkasan bersih yang dapat dipakai layer berikutnya. Hasilnya adalah representasi yang dapat menangkap banyak hubungan sekaligus—salah satu alasan kenapa Transformer sangat efektif pada skala besar.
Self-attention hebat dalam mendeteksi hubungan—tetapi sendirian ia tidak tahu siapa datang lebih dulu. Jika Anda mengacak kata-kata dalam kalimat, layer self-attention polos dapat memperlakukan versi yang diacak seolah sama validnya, karena ia membandingkan token tanpa sense posisi bawaan.
Positional encoding memecah masalah ini dengan menyuntikkan informasi “saya berada di mana dalam urutan?” ke dalam representasi token. Setelah posisi terpasang, attention dapat mempelajari pola seperti “kata tepat setelah tidak penting” atau “subjek biasanya muncul sebelum predikat” tanpa harus menebak urutan dari awal.
Ide inti sederhana: embedding token digabungkan dengan sinyal posisi sebelum masuk ke blok Transformer. Sinyal posisi ini bisa dipandang sebagai fitur tambahan yang memberi tag token sebagai posisi ke-1, ke-2, ke-3… dalam input.
Beberapa pendekatan umum:
Pilihan posisi dapat secara nyata memengaruhi pemodelan konteks panjang—mis. merangkum laporan panjang, melacak entitas di banyak paragraf, atau mengambil detail yang disebutkan ribuan token sebelumnya.
Dengan input panjang, model tidak hanya belajar bahasa; ia belajar ke mana harus melihat. Skema relatif dan rotary cenderung mempermudah membandingkan token yang berjauhan dan mempertahankan pola saat konteks bertambah, sementara beberapa skema absolut bisa menurun lebih cepat ketika didorong melampaui jendela pelatihannya.
Dalam praktiknya, positional encoding adalah keputusan desain tenang yang bisa menentukan apakah sebuah LLM terasa tajam dan konsisten pada 2.000 token—dan tetap koheren pada 100.000.
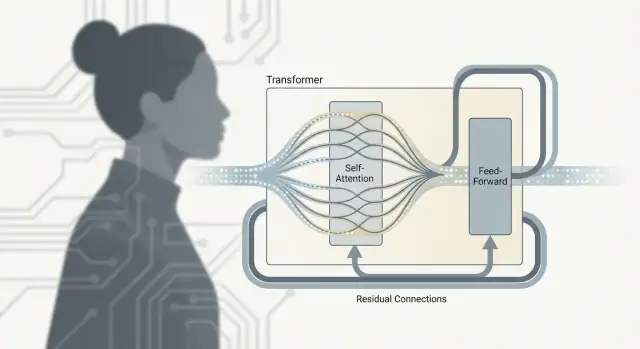
Transformer bukan hanya “attention.” Pekerjaan nyata terjadi di unit berulang—sering disebut blok Transformer—yang mencampur informasi antar token lalu menyempurnakannya. Menumpuk banyak blok ini memberi kedalaman yang membuat model bahasa besar begitu kapabel.
Self-attention adalah langkah komunikasi: setiap token mengumpulkan konteks dari token lain.
Feed-forward network (FFN), juga disebut MLP, adalah langkah berpikir: ia mengambil representasi token yang diperbarui dan menjalankan jaringan kecil yang sama pada setiap token secara independen.
Secara sederhana, FFN mentransformasi dan membentuk kembali apa yang kini diketahui setiap token, membantu model membangun fitur lebih kaya (seperti pola sintaks, fakta, atau petunjuk gaya) setelah mengumpulkan konteks relevan.
Pergantian ini penting karena kedua bagian melakukan tugas berbeda:
Mengulang pola ini memungkinkan model secara bertahap membangun makna tingkat tinggi: komunikasi, komputasi, komunikasi lagi, komputasi lagi.
Setiap sub-layer (attention atau FFN) dibungkus dengan residual connection: input ditambahkan kembali ke output. Ini membantu model dalam pelatihan karena gradien bisa mengalir melalui “jalur lewati” meskipun layer tertentu masih belajar. Ini juga membiarkan layer membuat penyesuaian kecil, bukan harus mempelajari semuanya dari awal.
Layer normalization adalah penstabil yang menjaga aktivasi agar tidak menyimpang terlalu besar atau kecil saat melewati banyak layer. Pikirkan ini seperti menjaga level volume konsisten sehingga layer berikutnya tidak kewalahan atau kekurangan sinyal—membuat pelatihan lebih mulus dan andal, terutama pada skala LLM.
Transformer asli di Attention Is All You Need dibangun untuk terjemahan mesin, di mana Anda mengubah satu urutan (mis. bahasa A) menjadi urutan lain (bahasa B). Pekerjaan itu alami terbagi menjadi dua peran: membaca input dengan baik, dan menulis output secara lancar.
Dalam Transformer encoder–decoder, encoder memproses seluruh kalimat input sekaligus dan menghasilkan set representasi kaya. Decoder kemudian menghasilkan output satu token pada satu waktu.
Penting: decoder tidak hanya bergantung pada token masa lalunya. Ia juga menggunakan cross-attention untuk melihat kembali output encoder, membantu tetap berlandaskan teks sumber.
Susunan ini tetap sangat baik ketika Anda harus sangat mengondisikan pada suatu input—terjemahan, ringkasan, atau tanya jawab yang terikat pada sebuah passage.
Sebagian besar model bahasa besar modern adalah decoder-only. Mereka dilatih untuk tugas sederhana dan kuat: memprediksi token berikutnya.
Untuk membuat itu bekerja, mereka menggunakan masked self-attention (sering disebut causal attention). Setiap posisi hanya bisa menghadiri token-token sebelumnya, bukan yang akan datang, sehingga generasi tetap konsisten: model menulis kiri-ke-kanan, terus memperpanjang urutan.
Ini dominan untuk LLM karena mudah dilatih pada korpora teks masif, cocok langsung dengan kasus penggunaan generasi, dan diskalakan secara efisien dengan data dan compute.
Encoder-only (seperti model gaya BERT) tidak menghasilkan teks; mereka membaca seluruh input secara bidirectional. Mereka hebat untuk klasifikasi, pencarian, dan embedding—apa pun yang membutuhkan pemahaman teks lebih daripada menghasilkan kelanjutan panjang.
Transformer ternyata ramah terhadap skala: jika Anda memberinya lebih banyak teks, lebih banyak compute, dan model lebih besar, mereka cenderung terus meningkat dengan cara yang dapat diprediksi.
Salah satu alasannya adalah kesederhanaan struktural. Transformer dibangun dari blok berulang (self-attention + FFN kecil, plus normalisasi), dan blok-blok itu berperilaku serupa apakah Anda melatih pada sejuta kata atau triliun kata.
Model urutan sebelumnya (seperti RNN) harus memproses token satu per satu, yang membatasi berapa banyak pekerjaan yang bisa dilakukan sekaligus. Transformer, sebaliknya, bisa memproses semua token dalam sebuah urutan secara paralel selama pelatihan.
Itu membuatnya cocok untuk GPU/TPU dan setup terdistribusi besar—tepat yang Anda butuhkan saat melatih LLM modern.
Jendela konteks adalah potongan teks yang bisa “dilihat” model sekaligus—prompt Anda ditambah riwayat percakapan atau teks dokumen terbaru. Jendela yang lebih besar memungkinkan model menghubungkan ide di lebih banyak kalimat atau halaman, melacak batasan, dan menjawab pertanyaan yang bergantung pada detail sebelumnya.
Tetapi konteks tidak gratis.
Self-attention membandingkan token satu sama lain. Saat urutan semakin panjang, jumlah perbandingan bertambah cepat (kira-kira kuadrat panjang urutan).
Itulah sebabnya jendela konteks sangat panjang bisa mahal dalam memori dan komputasi, dan kenapa banyak upaya modern fokus membuat attention lebih efisien.
Saat Transformer dilatih pada skala besar, mereka tidak hanya menjadi lebih baik pada satu tugas sempit. Mereka sering mulai menunjukkan kemampuan luas dan fleksibel—merangkum, menerjemahkan, menulis, mengkode, dan bernalar—karena mesin pembelajar umum yang sama diterapkan pada data besar dan beragam.
Desain Transformer asli masih menjadi titik acuan, tetapi sebagian besar LLM produksi adalah “Transformer plus”: penyempurnaan praktis kecil yang mempertahankan blok inti (attention + MLP) sambil memperbaiki kecepatan, stabilitas, atau panjang konteks.
Banyak peningkatan lebih soal membuat model dilatih dan dijalankan lebih baik daripada mengubah apa model adalah:
Perubahan ini biasanya tidak mengubah “ke-Transformer-an” fundamental dari model—mereka memurnikan desain.
Memperpanjang konteks dari beberapa ribu token ke puluhan atau ratus ribu sering mengandalkan sparse attention (hanya menghadiri token terpilih) atau varian attention efisien (mengaproksimasi atau merestrukturisasi attention untuk memotong perhitungan).
Trade-off biasanya antara akurasi, memori, dan kompleksitas rekayasa.
MoE menambahkan banyak sub-jaringan “pakar” dan merutekan setiap token melalui hanya beberapa pakar. Secara konseptual: Anda mendapatkan otak yang lebih besar, tapi tidak mengaktifkan semuanya setiap kali.
Ini bisa menurunkan compute per token untuk jumlah parameter tertentu, tetapi menambah kompleksitas sistem (routing, menyeimbangkan pakar, serving).
Saat sebuah model mempromosikan varian Transformer baru, minta:
Sebagian besar peningkatan nyata—tetapi jarang gratis.
Gagasan Transformer seperti self-attention dan scaling menarik—tetapi tim produk akan merasakannya sebagai trade-off: berapa banyak teks yang bisa Anda masukkan, seberapa cepat jawaban keluar, dan berapa biayanya per permintaan.
Panjang konteks: Konteks lebih panjang memungkinkan Anda memasukkan lebih banyak dokumen, riwayat chat, dan instruksi. Ini juga menaikkan pengeluaran token dan bisa memperlambat respons. Jika fitur Anda bergantung pada “baca 30 halaman dan jawab”, prioritaskan panjang konteks.
Latensi: Pengalaman chat dan copilot untuk pengguna hidup atau mati pada waktu respons. Streaming keluaran membantu, tetapi pilihan model, region, dan batching juga penting.
Biaya: Harga biasanya per token (input + output). Model yang 10% “lebih baik” bisa 2–5× lebih mahal. Gunakan perbandingan gaya harga untuk memutuskan tingkat kualitas yang layak dibayar.
Kualitas: Definisikan untuk kasus Anda: akurasi faktual, kemampuan mengikuti instruksi, nada, penggunaan alat, atau kode. Evaluasi dengan contoh nyata dari domain Anda, bukan benchmark umum.
Jika kebutuhan utama Anda adalah pencarian, deduplikasi, klastering, rekomendasi, atau “cari yang mirip”, embeddings (sering model encoder-style) biasanya lebih murah, lebih cepat, dan lebih stabil daripada memanggil model generatif. Gunakan generasi hanya untuk langkah akhir (ringkasan, penjelasan, draf) setelah retrieval.
Untuk penjelasan lebih mendalam, arahkan tim Anda ke penjelasan teknis seperti /blog/embeddings-vs-generation.
Saat Anda mengubah kapabilitas Transformer menjadi produk, bagian tersulit biasanya kurang soal arsitektur dan lebih soal alur kerja di sekitarnya: iterasi prompt, grounding, evaluasi, dan deployment aman.
Salah satu jalur praktis adalah menggunakan platform vibe-coding seperti Koder.ai untuk membuat prototipe dan mengirim fitur berbasis LLM lebih cepat: Anda dapat menjelaskan aplikasi web, endpoint backend, dan model data dalam chat, beriterasi di mode perencanaan, lalu mengekspor kode sumber atau melakukan deploy dengan hosting, domain kustom, dan rollback lewat snapshot. Ini sangat berguna ketika bereksperimen dengan retrieval, embeddings, atau loop pemanggilan alat dan menginginkan siklus iterasi yang ketat tanpa membangun kembali fondasi yang sama.
Sebuah Transformer adalah arsitektur jaringan saraf untuk data berurutan yang menggunakan self-attention untuk mengaitkan setiap token dengan token-token lain dalam input yang sama.
Alih-alih membawa informasi langkah demi langkah (seperti RNN/LSTM), ia membangun konteks dengan menentukan apa yang perlu diperhatikan di seluruh urutan, sehingga meningkatkan pemahaman jarak jauh dan membuat pelatihan bisa berjalan lebih paralel.
RNN dan LSTM memproses teks satu token pada satu waktu, sehingga pelatihan sulit diparalelisasi dan ada hambatan untuk mempelajari dependensi jarak jauh.
Transformer menggunakan attention untuk menghubungkan token-token yang jauh secara langsung, dan selama pelatihan dapat menghitung banyak interaksi token-ke-token secara paralel—membuatnya lebih cepat untuk diskalakan dengan lebih banyak data dan komputasi.
Attention adalah mekanisme untuk menjawab: “Token-token lain mana yang paling penting untuk memahami token ini sekarang?”
Bisa dibayangkan seperti retrieval di dalam kalimat:
Keluaran adalah campuran berbobot dari token relevan, memberi setiap posisi representasi yang menyadari konteks.
Self-attention berarti token-token dalam sebuah urutan memperhatikan token-token lain di urutan yang sama.
Ini adalah alat utama yang memungkinkan model menyelesaikan hal seperti koreferensi (mis. apa yang dimaksud "itu"), hubungan subjek–predikat melintasi klausa, dan dependensi yang berjauhan dalam teks—tanpa mendorong semuanya melalui satu “memori” rekuren.
Multi-head attention menjalankan beberapa perhitungan attention secara paralel, dan tiap head dapat mengekspresikan pola yang berbeda.
Dalam praktiknya, head-head berbeda seringkali fokus pada hubungan yang berbeda (sintaks lokal, koreferensi, hubungan jangka panjang, sinyal topikal). Model kemudian menggabungkan pandangan-pandangan ini agar dapat mewakili berbagai struktur sekaligus.
Self-attention sendiri tidak otomatis mengetahui urutan token—tanpa informasi posisi, pengacakan kata bisa terlihat serupa.
Positional encoding menyuntikkan sinyal posisi ke dalam representasi token sehingga model dapat mempelajari pola seperti “kata setelah tidak memiliki pengaruh khusus” atau struktur subjek-sebelum-predikat.
Pilihan umum meliputi sinusoidal (tetap), posisi absolut yang dipelajari, dan metode relatif/rotary.
Sebuah blok Transformer biasanya menggabungkan:
Transformer asli pada paper Attention Is All You Need adalah encoder–decoder:
Namun kebanyakan LLM modern adalah , dilatih untuk memprediksi token berikutnya menggunakan , yang sesuai untuk generasi kiri-ke-kanan dan mudah diskalakan pada korpora besar.
Noam Shazeer adalah salah satu co-author pada paper 2017 “Attention Is All You Need,” yang memperkenalkan Transformer.
Tepat untuk menyebutnya sebagai kontributor kunci, tetapi arsitektur itu lahir dari kerja tim di Google, dan dampaknya juga datang dari banyak perbaikan komunitas dan industri yang dibangun di atas cetak biru awal tersebut.
Untuk input panjang, self-attention standar menjadi mahal karena jumlah perbandingan tumbuh kira-kira dengan kuadrat panjang urutan, yang memengaruhi memori dan komputasi.
Cara praktis yang biasa dipakai tim:
Menumpuk banyak blok menghasilkan kedalaman yang memungkinkan fitur lebih kaya dan perilaku yang kuat pada skala besar.