04 Apr 2025·8 menit
Cara Membangun Web App untuk Pelacakan Keandalan Tool Internal
Pelajari cara merancang dan membangun web app yang melacak keandalan tool internal dengan SLI/SLO, alur insiden, dashboard, alert, dan pelaporan.
Pelajari cara merancang dan membangun web app yang melacak keandalan tool internal dengan SLI/SLO, alur insiden, dashboard, alert, dan pelaporan.
Sebelum memilih metrik atau membangun dashboard, putuskan apa tanggung jawab aplikasi keandalan Anda—dan apa yang bukan tanggung jawabnya. Ruang lingkup yang jelas mencegah alat berubah menjadi “ops portal” serbaguna yang tidak dipercaya siapa pun.
Mulai dengan membuat daftar tool internal yang akan dicakup aplikasi (mis. tiket, payroll, integrasi CRM, pipeline data) dan tim yang memiliki atau bergantung pada mereka. Jelaskan batasannya: “website customer‑facing” mungkin diluar ruang lingkup, sementara “konsol admin internal” termasuk.
Organisasi berbeda menggunakan kata ini secara berbeda. Tuliskan definisi kerja Anda dalam bahasa sederhana—biasanya campuran dari:
Jika tim tidak sepakat, aplikasi Anda akan membandingkan apel dan jeruk.
Pilih 1–3 outcome utama, seperti:
Outcome ini nanti akan membimbing apa yang Anda ukur dan bagaimana menyajikannya.
Daftar siapa yang akan menggunakan aplikasi dan keputusan apa yang mereka buat: insinyur yang menyelidiki insiden, support yang mengeskalasi isu, manajer yang meninjau tren, dan pemangku kepentingan yang butuh update status. Ini akan membentuk terminologi, izin, dan tingkat detail yang ditampilkan tiap view.
Pelacakan keandalan hanya efektif jika semua pihak sepakat apa arti “baik”. Mulai dengan memisahkan tiga istilah yang mirip.
Sebuah SLI (Service Level Indicator) adalah pengukuran: “Berapa persen permintaan yang berhasil?” atau “Berapa lama halaman dimuat?”
Sebuah SLO (Service Level Objective) adalah target untuk pengukuran itu: “99.9% keberhasilan selama 30 hari.”
Sebuah SLA (Service Level Agreement) adalah janji dengan konsekuensi, biasanya bersifat eksternal (kredit, penalti). Untuk tool internal, seringkali Anda menetapkan SLO tanpa SLA formal—cukup untuk menyelaraskan ekspektasi tanpa mengubah keandalan menjadi kontrak hukum.
Buat agar bisa dibandingkan antar tool dan mudah dijelaskan. Baseline praktis:
Hindari menambah lebih banyak sampai Anda bisa menjawab: “Keputusan apa yang metrik ini akan pengaruhi?”
Gunakan rolling window supaya scorecard terupdate terus:
Aplikasi Anda harus mengubah metrik menjadi tindakan. Definisikan level severity (mis. Sev1–Sev3) dan pemicu eksplisit seperti:
Definisi ini membuat alerting, timeline insiden, dan pelacakan error budget konsisten antar tim.
Aplikasi pelacakan keandalan hanya sepercaya data yang menopangnya. Sebelum membangun pipeline ingestion, petakan setiap sinyal yang akan Anda anggap sebagai “kebenaran” dan catat pertanyaan apa yang dijawabnya (ketersediaan, latensi, error, dampak deploy, respons insiden).
Kebanyakan tim bisa menutup dasar dengan gabungan:
Jelaskan sistem mana yang authoritative. Contohnya, “SLI uptime” mungkin hanya bersumber dari synthetic probes, bukan log server.
Tetapkan frekuensi update berdasarkan use case: dashboard bisa refresh setiap 1–5 menit, sementara scorecard dihitung per jam/hari.
Buat ID konsisten untuk tool/service, environment (prod/stage), dan owner. Sepakati aturan penamaan lebih awal supaya “Payments-API”, “payments_api”, dan “payments” tidak menjadi tiga entitas berbeda.
Rencanakan apa yang disimpan dan berapa lama (mis. raw events 30–90 hari, agregat harian 12–24 bulan). Hindari meng‑ingest payload sensitif; simpan hanya metadata yang diperlukan untuk analisis keandalan (timestamp, status code, bucket latensi, tag insiden).
Skema Anda harus memudahkan dua hal: menjawab pertanyaan sehari‑hari (“apakah tool ini sehat?”) dan merekonstruksi apa yang terjadi selama insiden (“kapan gejala mulai, siapa mengubah apa, alert mana yang menyala?”). Mulai dengan set entitas inti kecil dan buat relasinya eksplisit.
Baseline praktis:
Struktur ini mendukung dashboard (“tool → status saat ini → insiden terbaru”) dan drill‑down (“incident → events → checks dan metrics terkait”).
Tambahkan field audit di mana Anda butuh akuntabilitas dan sejarah:
created_by, created_at, updated_atstatus plus status change tracking (baik di tabel Event atau tabel history terpisah)Terakhir, sertakan tags fleksibel untuk filtering dan pelaporan (mis. team, criticality, system, compliance). Tabel join tool_tags (tool_id, key, value) menjaga konsistensi tagging dan mempermudah scorecard serta rollup di kemudian hari.
Tracker keandalan Anda harus “membosankan” dalam arti terbaik: mudah dijalankan, mudah diubah, dan mudah didukung. Stack yang “benar” biasanya yang tim Anda bisa pelihara tanpa heroics.
Pilih framework web mainstream yang tim Anda kenal—Node/Express, Django, atau Rails semuanya pilihan solid. Prioritaskan:
Jika Anda mengintegrasikan dengan sistem internal (SSO, ticketing, chat), pilih ekosistem tempat integrasi tersebut paling mudah.
Jika Anda ingin mempercepat iterasi pertama, platform vibe‑coding seperti Koder.ai bisa jadi titik awal praktis: Anda dapat mendeskripsikan entitas (tools, checks, SLO, incident), alur kerja (alert → incident → postmortem), dan dashboard lewat chat, kemudian menghasilkan scaffold web app kerja dengan cepat. Karena Koder.ai umum menargetkan React di frontend dan Go + PostgreSQL di backend, ia cocok dengan stack default “membosankan, maintainable” yang disukai banyak tim—dan Anda bisa mengekspor kode sumber jika nanti pindah ke pipeline manual penuh.
Untuk kebanyakan aplikasi keandalan internal, PostgreSQL adalah default yang tepat: ia menangani relasional reporting, query berbasis waktu, dan auditing dengan baik.
Tambahkan komponen ekstra hanya jika mereka menyelesaikan masalah nyata:
Putuskan antara:
Mana pun yang dipilih, standarkan dev/staging/prod dan otomasi deployment (CI/CD), sehingga perubahan tidak mengubah angka keandalan secara diam‑diam. Jika menggunakan pendekatan platform (termasuk Koder.ai), cari fitur seperti pemisahan environment, deployment/hosting, dan rollback cepat (snapshot) supaya Anda bisa iterasi tanpa memecah tracker itu sendiri.
Dokumentasikan konfigurasi di satu tempat: environment variables, secrets, dan feature flags. Simpan panduan “cara menjalankan lokal” dan runbook minimal (apa yang dilakukan jika ingestion berhenti, antrean menumpuk, atau database mencapai limit). Halaman singkat di /docs biasanya cukup.
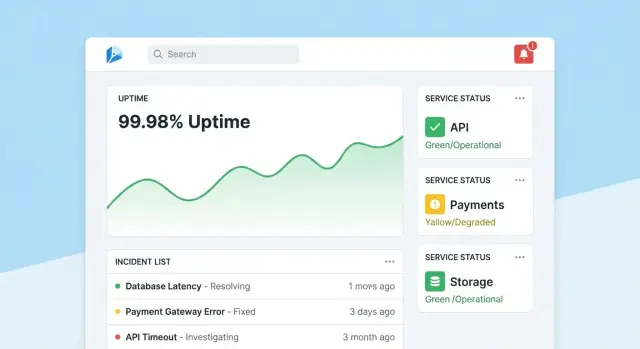
Aplikasi pelacakan keandalan berhasil ketika orang bisa menjawab dua pertanyaan dalam beberapa detik: “Apakah kita baik‑baik saja?” dan “Apa yang harus saya lakukan selanjutnya?” Rancang layar di sekitar keputusan itu, dengan navigasi jelas dari overview → tool spesifik → insiden spesifik.
Jadikan beranda sebagai command center ringkas. Mulai dengan ringkasan kesehatan keseluruhan (mis. jumlah tool yang memenuhi SLO, insiden aktif, risiko terbesar saat ini), lalu tampilkan insiden dan alert terbaru dengan badge status.
Jaga tampilan default tenang: sorot hanya yang perlu perhatian. Beri setiap tile drill‑down langsung ke tool atau insiden terkait.
Setiap halaman tool harus menjawab “Apakah tool ini cukup andal?” dan “Mengapa/kenapa tidak?” Sertakan:
Rancang grafik untuk non‑pakar: label unit, tandai threshold SLO, dan tambahkan penjelasan singkat (tooltip) daripada kontrol teknis yang padat.
Halaman insiden adalah catatan hidup. Sertakan timeline (event yang ditangkap otomatis seperti alert fired, acknowledged, mitigated), pembaruan manusia, pengguna terdampak, dan tindakan yang dilakukan.
Permudah publikasi pembaruan: satu kotak teks, status pra‑definisi (Investigating/Identified/Monitoring/Resolved), dan catatan internal opsional. Saat insiden ditutup, aksi “Start postmortem” harus mengisi otomatis fakta dari timeline.
Admin butuh layar sederhana untuk mengelola tools, checks, target SLO, dan owner. Optimalkan untuk kebenaran: default yang masuk akal, validasi, dan peringatan saat perubahan memengaruhi pelaporan. Tambahkan jejak “last edited” supaya orang percaya angkanya.
Data keandalan tetap berguna jika orang percaya. Itu berarti mengaitkan setiap perubahan ke identitas, membatasi siapa yang bisa membuat edit berdampak besar, dan menyimpan riwayat yang jelas untuk dikaji saat review.
Untuk tool internal, default ke SSO (SAML) atau OAuth/OIDC melalui identity provider (Okta, Azure AD, Google Workspace). Ini mengurangi manajemen password dan membuat onboarding/offboarding otomatis.
Detail praktis:
Mulai dengan peran sederhana dan tambahkan aturan lebih rinci hanya bila perlu:
Lindungi aksi yang dapat mengubah hasil atau narasi pelaporan:
Log setiap edit pada SLO, check, dan field insiden dengan:
Buat log audit dapat dicari dan terlihat dari halaman detail relevan (mis. halaman insiden menampilkan histori perubahan). Ini menjaga review tetap faktual dan mengurangi perdebatan saat postmortem.
Monitoring adalah “lapisan sensor” aplikasi keandalan Anda: itu mengubah perilaku nyata menjadi data yang bisa dipercaya. Untuk tool internal, synthetic check sering kali jalur tercepat karena Anda mengontrol apa arti “sehat”.
Mulai dengan set kecil tipe check yang menutupi sebagian besar aplikasi internal:
Jaga agar check deterministik. Jika validasi bisa gagal karena konten yang berubah, Anda akan menghasilkan noise dan mengikis kepercayaan.
Untuk tiap run check, tangkap:
Simpan data sebagai event time‑series (satu baris per run) atau sebagai agregat interval (mis. rollup per‑menit dengan count dan p95 latency). Data event bagus untuk debugging; rollup bagus untuk dashboard cepat. Banyak tim melakukan keduanya: simpan event raw 7–30 hari dan rollup untuk pelaporan jangka panjang.
Hasil check yang hilang tidak otomatis berarti “down.” Tambahkan status unknown untuk kasus seperti:
Ini mencegah downtime terpujangka dan membuat “gap monitoring” terlihat sebagai masalah operasional tersendiri.
Gunakan worker background (penjadwalan seperti cron, antrean) untuk menjalankan check pada interval tetap (mis. setiap 30–60 detik untuk tool kritikal). Bangun timeout, retry dengan backoff, dan batas concurrency supaya checker tidak membebani layanan internal. Persistenkan setiap hasil run—bahkan kegagalan—agar dashboard uptime menunjukkan status saat ini dan histori yang dapat dipercaya.
Alert adalah titik di mana pelacakan keandalan menjadi aksi. Tujuannya sederhana: beri tahu orang yang tepat, dengan konteks yang tepat, pada waktu yang tepat—tanpa membanjiri semua orang.
Mulai dengan mendefinisikan aturan alert yang memetakan langsung ke SLI/SLO. Dua pola praktis:
Untuk tiap aturan, simpan alasan (“mengapa”) bersama dengan apa yang dipantau: SLO mana yang terpengaruh, jendela evaluasi, dan severity yang dimaksud.
Kirim notifikasi lewat channel yang tim gunakan sehari‑hari (email, Slack, Microsoft Teams). Setiap pesan harus mencakup:
Hindari membuang metrik mentah. Berikan langkah singkat berikutnya seperti “Periksa deploy terbaru” atau “Buka logs.”
Implementasikan:
Walau untuk tool internal, orang perlu kontrol. Tambahkan eskalasi manual (tombol di halaman alert/insiden) dan integrasi dengan tooling on‑call bila tersedia (PagerDuty/Opsgenie), atau setidaknya daftar rotasi yang dapat dikonfigurasi disimpan di aplikasi Anda.
Manajemen insiden mengubah “kita lihat alert” menjadi respons bersama yang dapat dilacak. Bangun ini di dalam aplikasi keandalan Anda supaya orang bisa bergerak dari sinyal ke koordinasi tanpa lompat antar alat.
Buat kemungkinan untuk membuat insiden langsung dari alert, halaman service, atau grafik uptime. Isi otomatis field penting (service, environment, sumber alert, waktu pertama terlihat) dan tetapkan ID insiden unik.
Set field default yang ringan: severity, dampak pelanggan (team internal terdampak), owner saat ini, dan link ke alert pemicu.
Gunakan lifecycle sederhana yang sesuai kerja tim:
Setiap perubahan status harus mencatat siapa dan kapan. Tambahkan update timeline (catatan singkat ber‑timestamp), plus dukungan untuk lampiran dan link ke runbook dan tiket (mis. /runbooks/payments-retries atau /tickets/INC-1234). Ini menjadi thread tunggal untuk “apa yang terjadi dan apa yang kita lakukan.”
Postmortem harus cepat dimulai dan konsisten saat ditinjau. Sediakan template dengan:
Kaitkan action item kembali ke insiden, lacak penyelesaiannya, dan tampilkan item yang lewat tenggat di dashboard tim. Jika mendukung “learning reviews,” sediakan mode “tanpa menyalahkan” yang fokus pada perubahan sistem dan proses ketimbang kesalahan individu.
Pelaporan adalah tempat pelacakan keandalan menjadi pengambilan keputusan. Dashboard membantu operator; scorecard membantu pemimpin memahami apakah tool internal membaik, area mana perlu investasi, dan apa arti “baik”.
Buat tampilan konsisten, dapat diulang per tool (dan opsional per tim) yang menjawab beberapa pertanyaan cepat:
Jika memungkinkan, tambahkan konteks ringan: “SLO terlewat karena 2 deploy” atau “Downtime terbanyak dari dependency X,” tanpa menjadikan laporan itu review insiden penuh.
Pemimpin jarang ingin “semuanya.” Tambahkan filter untuk team, criticality tool (mis. Tier 0–3), dan jendela waktu. Pastikan satu tool dapat muncul di beberapa rollup (platform team memiliki, finance bergantung).
Sediakan ringkasan mingguan dan bulanan yang bisa dibagikan di luar aplikasi:
Jaga narasi konsisten (“Apa yang berubah sejak periode lalu?” “Di mana kita over budget?”). Jika perlu primer untuk pemangku kepentingan, link ke panduan singkat seperti /blog/sli-slo-basics.
Tracker keandalan cepat menjadi sumber kebenaran. Perlakukan seperti sistem produksi: aman secara default, tahan terhadap data buruk, dan mudah dipulihkan saat terjadi masalah.
Kunci setiap endpoint—bahkan yang “internal‑only”.
Jauhkan credential dari kode dan log.
Metrik keandalan berguna hanya jika event dasar dapat dipercaya.
Tambahkan pengecekan sisi server untuk timestamp (timezone/clock skew), field wajib, dan idempotency key untuk deduplikasi retry. Lacak error ingestion di dead‑letter queue atau tabel “quarantine” supaya event buruk tidak meracuni dashboard.
Otomatiskan migrasi database dan uji rollback. Jadwalkan backup, restore‑test secara berkala, dan dokumentasikan rencana recovery minimal (siapa, apa, berapa lama).
Terakhir, buat aplikasi keandalan itu sendiri andal: tambahkan health checks, monitoring dasar untuk lag antrean dan latensi DB, dan alert saat ingestion tiba‑tiba drop ke nol.
Aplikasi pelacakan keandalan berhasil saat orang percaya dan menggunakannya. Perlakukan rilis pertama sebagai loop pembelajaran, bukan peluncuran “big bang”.
Pilih 2–3 tool internal yang banyak digunakan dan punya owner jelas. Terapkan set kecil checks (mis. ketersediaan homepage, login success, dan satu endpoint API kunci) dan publikasikan satu dashboard yang menjawab: “Apakah ini up? Jika tidak, apa yang berubah dan siapa pemiliknya?”
Jaga pilot terlihat tapi terbatas: satu tim atau kelompok kecil power user cukup untuk memvalidasi alur.
Dalam 1–2 minggu pertama, aktif kumpulkan feedback tentang:
Ubah feedback menjadi backlog konkret. Tombol sederhana “Laporkan masalah dengan metrik ini” pada setiap grafik sering memunculkan insight tercepat.
Tambahkan nilai secara berlapis: hubungkan ke tool chat untuk notifikasi, lalu ke tool insiden untuk pembuatan tiket otomatis, lalu CI/CD untuk marker deploy. Setiap integrasi harus mengurangi kerja manual atau memperpendek time‑to‑diagnose—jika tidak, itu hanya menambah kompleksitas.
Jika Anda prototipe cepat, pertimbangkan menggunakan mode perencanaan Koder.ai untuk memetakan scope awal (entitas, peran, alur kerja) sebelum menghasilkan build pertama. Ini cara sederhana untuk menjaga MVP tetap ketat—dan karena Anda bisa snapshot dan rollback, Anda bisa iterasi dashboard dan ingestion dengan aman seiring definisi disempurnakan.
Sebelum rollout ke lebih banyak tim, definisikan metrik keberhasilan seperti weekly active users dashboard, pengurangan time‑to‑detect, lebih sedikit alert duplikat, atau review SLO yang konsisten. Publikasikan roadmap ringan di /blog/reliability-tracking-roadmap dan kembangkan tool demi tool dengan owner dan sesi pelatihan yang jelas.
Mulai dengan mendefinisikan ruang lingkup (tool dan environment yang termasuk) dan definisi kerja Anda tentang keandalan (ketersediaan, latensi, kesalahan). Setelah itu pilih 1–3 outcome yang ingin Anda tingkatkan (mis. deteksi lebih cepat, pelaporan yang lebih jelas) dan rancang layar pertama di sekitar keputusan inti pengguna: “Apakah kita baik‑baik saja?” dan “Apa yang harus saya lakukan selanjutnya?”
Sebuah SLI adalah apa yang Anda ukur (mis. % permintaan sukses, p95 latency). Sebuah SLO adalah target untuk pengukuran itu (mis. 99.9% selama 30 hari). Sebuah SLA adalah janji formal dengan konsekuensi (sering kali bersifat eksternal). Untuk tool internal, biasanya SLO dipakai untuk menyelaraskan ekspektasi tanpa overhead penegakan ala SLA.
Gunakan set baseline kecil yang konsisten antar tool:
Tambahkan metrik lain hanya jika Anda bisa menyebutkan keputusan yang akan didorong metrik tersebut (alerting, prioritisasi, pekerjaan kapasitas, dll.).
Gunakan rolling window agar scorecard terus terbarui:
Pilih window yang sesuai cara organisasi Anda mereview performa agar angka terasa intuitif dan dipakai.
Definisikan trigger severity eksplisit yang terkait dampak pengguna dan durasi, misalnya:
Tuliskan aturan‑aturan ini di dalam aplikasi agar alerting, timeline insiden, dan pelaporan konsisten antar tim.
Mulai dengan memetakan sistem mana yang menjadi “sumber kebenaran” untuk tiap pertanyaan:
Jelaskan secara eksplisit (mis. “SLI uptime hanya berasal dari probe”), kalau tidak tim akan berdebat tentang angka mana yang dianggap valid.
Gunakan pull untuk sistem yang bisa Anda polling secara terjadwal (API monitoring, API ticketing). Gunakan push (webhook/event) untuk event ber‑volume tinggi atau real‑time (deploy, alert, update insiden). Pola umum: dashboard menyegarkan setiap 1–5 menit, sedangkan scorecard dihitung per jam atau per hari.
Umumnya Anda butuh:
Catat setiap edit berdampak tinggi dengan siapa, kapan, apa yang berubah (sebelum/sesudah), dan dari mana itu berasal (UI/API/otomasi). Gabungkan dengan akses berbasis peran:
Garis‑garis ini mencegah perubahan diam‑diam yang merusak kepercayaan pada angka keandalan Anda.
Anggap hasil check yang hilang sebagai status terpisah unknown, bukan otomatis dianggap downtime. Data hilang bisa terjadi karena:
Menampilkan “unknown” mencegah inflasi downtime dan membuat gap monitoring terlihat sebagai masalah operasional sendiri.
Jelaskan relasi (tool → checks → metrics; incident → events) supaya query “overview → drill‑down” tetap sederhana.