27 Agu 2025·7 menit
Go worker pool untuk pekerjaan latar belakang: percobaan ulang, pembatalan, dan shutdown
Worker pool Go membantu tim kecil menjalankan pekerjaan latar belakang dengan retry, pembatalan, dan shutdown bersih menggunakan pola sederhana sebelum menambah infrastruktur berat.
Mengapa pekerjaan latar belakang cepat menjadi berantakan
Di layanan Go kecil, pekerjaan latar belakang biasanya dimulai dengan tujuan sederhana: kembalikan respons HTTP dengan cepat, lalu lakukan pekerjaan lambat setelahnya. Itu bisa berupa mengirim email, meresize gambar, sinkron ke API lain, membangun ulang indeks pencarian, atau menjalankan laporan malam.
Masalahnya adalah pekerjaan ini adalah kerja produksi nyata, hanya saja tanpa pegangan yang biasanya Anda dapatkan saat menangani request. Sebuah goroutine yang dipicu dari handler HTTP terasa aman sampai ada deploy di tengah tugas, API upstream melambat, atau request yang sama coba ulang dan memicu pekerjaan dua kali.
Rasa sakit pertama bisa diprediksi:
- Pekerjaan macet: satu panggilan menggantung dan pekerja berhenti maju.
- Pekerjaan duplikat: retry di lapisan HTTP menjalankan pekerjaan yang sama lagi.
- Tidak ada rencana shutdown: proses keluar dan pekerjaan hilang atau setengah selesai.
- Kegagalan senyap: error dicatat sekali (atau bahkan tidak sama sekali) dan menghilang.
- Badai retry: pekerjaan yang gagal langsung dicoba ulang dan membebani dependensi.
Di sinilah pola kecil dan eksplisit seperti worker pool Go membantu. Ini membuat konkurensi menjadi pilihan (N worker), mengubah “lakukan nanti” menjadi tipe job yang jelas, dan memberi satu tempat untuk menangani retry, timeout, dan pembatalan.
Contoh: aplikasi SaaS perlu mengirim faktur. Anda tidak ingin 500 kiriman sekaligus setelah import batch, dan Anda tidak ingin mengirim ulang faktur yang sama karena request di-retry. Worker pool membiarkan Anda membatasi throughput dan memperlakukan “kirim faktur #123” sebagai unit kerja yang dilacak.
Worker pool bukan alat yang tepat saat Anda membutuhkan jaminan tahan-gangguan lintas-proses. Jika job harus bertahan setelah crash, dijadwalkan untuk waktu tertentu di masa depan, atau diproses oleh banyak layanan, kemungkinan Anda membutuhkan antrean nyata plus penyimpanan persisten untuk status job.
Model worker pool dalam bahasa sederhana
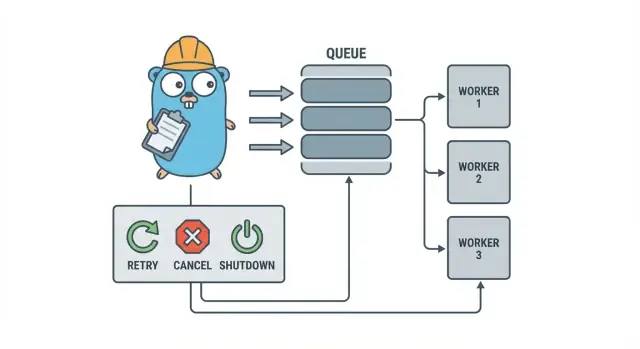
Worker pool Go sengaja membosankan: masukkan pekerjaan ke antrean, punya sejumlah pekerja tetap yang menarik dari situ, dan pastikan seluruh sistem bisa berhenti dengan bersih.
Istilah dasar:
- Job: satu unit kerja, seperti “resize gambar ini” atau “kirim email faktur ini”.
- Queue: tempat job menunggu.
- Worker: goroutine yang berulang kali mengambil job dan menjalankannya.
- Dispatcher: bagian yang menerima job dan memasukkannya ke antrean.
Dalam banyak desain in-process, sebuah channel Go adalah antreannya. Channel berbufffer bisa menahan sejumlah job terbatas sebelum producer terblok. Pemblokiran itu adalah backpressure, dan seringkali itulah yang mencegah service Anda menerima pekerjaan tanpa batas dan kehabisan memori saat trafik melonjak.
Ukuran buffer mengubah nuansa sistem. Buffer kecil membuat tekanan terlihat cepat (pemanggil menunggu lebih awal). Buffer besar meratakan lonjakan singkat tapi bisa menyembunyikan overload sampai nanti. Tidak ada angka sempurna, hanya angka yang cocok dengan seberapa banyak penantian yang Anda toleransi.
Anda juga memilih apakah ukuran pool tetap atau bisa berubah. Pool tetap lebih mudah dipahami dan menjaga penggunaan sumber daya tetap dapat diprediksi. Auto-scaling worker bisa membantu saat beban tidak merata, tapi menambah keputusan yang harus Anda pelihara (kapan menskalakan, berapa banyak, dan kapan menurunkan).
Akhirnya, “ack” dalam pool in-process biasanya hanya berarti “worker menyelesaikan job dan tidak mengembalikan error.” Tidak ada broker eksternal untuk mengonfirmasi pengiriman, jadi kode Anda yang mendefinisikan apa arti “selesai” dan apa yang terjadi saat job gagal atau dibatalkan.
Tujuan desain: retry, pembatalan, dan shutdown bersih
Worker pool sederhana secara mekanis: jalankan sejumlah worker tetap, beri mereka job, dan proses. Nilainya adalah kontrol: konkurensi yang dapat diprediksi, penanganan kegagalan yang jelas, dan jalur shutdown yang tidak meninggalkan pekerjaan setengah jadi.
Tiga tujuan yang membuat tim kecil tetap waras:
- Batasi konkurensi agar lonjakan tidak melelehkan database atau API eksternal.
- Hindari kehilangan kerja (atau setidaknya ketahui persis apa yang dijatuhkan dan mengapa).
- Tetap mudah dideteksi: setiap job harus bisa ditelusuri lewat log dan beberapa counter.
Sebagian besar kegagalan itu membosankan, tetapi Anda tetap ingin memperlakukan mereka berbeda:
- Error sementara (gangguan jaringan, limit, dsb.) yang harus dicoba ulang.
- Error permanen (input rusak, record hilang) yang tidak boleh dicoba ulang.
- Timeout (dependensi menggantung) yang harus diputus supaya worker tidak tersumbat.
Pembatalan bukan sama dengan “error.” Itu sebuah keputusan: pengguna membatalkan, deploy mengganti proses Anda, atau service sedang shutdown. Di Go, perlakukan pembatalan sebagai sinyal kelas-satu menggunakan pembatalan context, dan pastikan setiap job memeriksanya sebelum memulai pekerjaan mahal dan pada beberapa titik aman selama eksekusi.
Shutdown bersih adalah tempat banyak pool gagal. Tentukan sejak awal apa arti “aman” untuk job Anda: apakah Anda menyelesaikan pekerjaan yang sedang berjalan, atau berhenti cepat dan jalankan lagi nanti? Alur praktis adalah:
- Berhenti menerima job baru.
- Beri tahu worker untuk berhenti setelah job saat ini selesai (atau berhenti segera).
- Tunggu sampai batas waktu, lalu paksa keluar.
Jika Anda mendefinisikan aturan-aturan ini sejak awal, retry, pembatalan, dan shutdown tetap kecil dan dapat diprediksi alih-alih berubah menjadi framework buatan sendiri.
Langkah demi langkah: bangun worker pool dasar
Worker pool hanyalah sekumpulan goroutine yang menarik job dari channel dan melakukan pekerjaan. Bagian penting adalah membuat dasar yang dapat diprediksi: seperti apa job, bagaimana worker berhenti, dan bagaimana Anda tahu ketika semua pekerjaan selesai.
Mulai dengan tipe Job sederhana. Beri ID (untuk log), payload (apa yang diproses), counter percobaan (berguna untuk retry), timestamp, dan tempat menyimpan data context per-job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Beberapa pilihan praktis yang harus Anda buat segera:
- Pilih ukuran antrean berdasarkan seberapa banyak penantian yang Anda toleransi.
- Putuskan apa arti backpressure bagi pemanggil: blok, kembalikan error, atau drop.
- Jaga
Stop()danWait()terpisah supaya Anda bisa menghentikan intake dulu, lalu menunggu pekerjaan yang sedang berjalan selesai.
Menambahkan retry tanpa mengubahnya jadi framework
Retry berguna, tapi juga tempat di mana worker pool menjadi berantakan. Persempit tujuan: retry hanya ketika percobaan ulang punya peluang nyata untuk berhasil, dan berhenti cepat saat tidak.
Mulai dengan memutuskan apa yang bisa di-retry. Masalah sementara (gangguan jaringan, timeout, respons "coba lagi nanti") biasanya layak dicoba ulang. Masalah permanen (input rusak, record hilang, izin ditolak) tidak.
Kebijakan retry kecil biasanya cukup:
- Tandai error sebagai retryable atau bukan (misalnya bungkus dengan helper
Retryable(err)). - Tetapkan jumlah maksimum percobaan (sering 3 sampai 5). Setelah itu biasanya hanya membuang waktu.
- Gunakan exponential backoff dengan jitter agar job tidak retry bersamaan.
- Batasi delay (misalnya jangan tidur lebih dari 30 detik).
- Log retry dengan nomor percobaan, delay berikutnya, dan ID job.
Backoff tidak perlu rumit. Bentuk umum: delay = min(base * 2^(attempt-1), max), lalu tambahkan jitter (acak +/- 20%). Jitter penting karena kalau tidak, banyak worker gagal bersamaan lalu retry bersamaan.
Di mana delay ini berada? Untuk sistem kecil, tidur di dalam worker cukup, tapi itu mengikat slot worker. Jika retry jarang, itu bisa diterima. Jika retry sering atau delay panjang, pertimbangkan untuk meng-enqueue ulang job dengan timestamp “run after” sehingga worker tetap sibuk dengan pekerjaan lain.
Saat kegagalan akhir, bersikaplah eksplisit. Simpan job yang gagal (dan error terakhir) untuk ditinjau, log konteks yang cukup untuk replay, atau dorong ke daftar mati yang Anda periksa secara berkala. Hindari drop senyap. Pool yang menyembunyikan kegagalan lebih buruk daripada tidak punya retry.
Pembatalan dan timeout yang benar-benar menghentikan pekerjaan
Rencanakan kebijakan retry Anda
Peta aturan retry dan backoff dulu, lalu biarkan Koder.ai membangunnya ke runner job Anda.
Worker pool terasa aman ketika Anda bisa menghentikannya. Aturan paling sederhana: teruskan context.Context melalui setiap lapisan yang bisa memblok. Itu berarti submission, eksekusi, dan pembersihan.
Setup praktis menggunakan dua batas waktu:
- Timeout per-job sehingga satu tugas tidak bisa mengikat worker selamanya.
- Timeout shutdown supaya proses bisa keluar meski beberapa job tidak kooperatif.
Gunakan context dari ujung ke ujung
Beri setiap job context sendiri yang diturunkan dari context worker. Lalu setiap panggilan lambat (database, HTTP, antrean, I/O file) harus menggunakan context itu agar bisa kembali lebih awal.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Jika Run memanggil DB atau API Anda, sambungkan context ke panggilan-panggilan itu (misalnya QueryContext, NewRequestWithContext, atau metode klien yang menerima context). Jika Anda mengabaikannya di satu tempat, pembatalan menjadi "best effort" dan biasanya gagal saat Anda paling membutuhkannya.
Pekerjaan parsial dan langkah "aman untuk di-retry"
Pembatalan bisa terjadi di tengah job, jadi anggaplah pekerjaan parsial itu normal. Tujuannya adalah membuat langkah-langkah idempoten sehingga rerun tidak menghasilkan duplikasi. Pendekatan umum termasuk menggunakan kunci unik untuk insert (atau upsert), menulis penanda progres (started/done), menyimpan hasil sebelum melanjutkan, dan memeriksa ctx.Err() di antara langkah.
Perlakukan shutdown seperti deadline: berhenti menerima job baru, batalkan context worker, dan tunggu hanya sampai timeout shutdown untuk job yang sedang berjalan keluar.
Shutdown bersih: apa yang dilakukan saat proses harus keluar
Shutdown bersih punya satu tujuan: berhenti mengambil pekerjaan baru, beri tahu pekerjaan yang sedang berjalan untuk berhenti, dan keluar tanpa meninggalkan sistem dalam keadaan aneh.
Mulai dengan sinyal. Di sebagian besar deployment Anda akan melihat SIGINT secara lokal dan SIGTERM dari process manager atau container runtime. Gunakan context shutdown yang dibatalkan saat sinyal datang, dan teruskan ke pool serta handler job Anda.
Selanjutnya, berhenti menerima job baru. Jangan biarkan pemanggil terblok selamanya mencoba submit ke channel yang tak lagi dibaca. Taruh submission di balik satu fungsi yang memeriksa flag closed atau memilih pada context shutdown sebelum mengirim.
Lalu putuskan apa yang terjadi pada pekerjaan yang ada di antrean:
- Drain: selesaikan yang sudah antre, tapi tolak submission baru.
- Drop: buang apa pun yang belum dimulai.
Draining lebih aman untuk hal seperti pembayaran dan email. Dropping cocok untuk tugas "bagus kalau ada" seperti recomputasi cache.
Urutan shutdown praktis:
- Tangkap SIGINT/SIGTERM dan batalkan context bersama.
- Berhenti menerima submission (tutup jalur submit, tidak selalu channel pekerjaan).
- Biarkan worker selesai atau abort berdasarkan context.
- Tunggu worker dengan WaitGroup.
- Terapkan deadline, lalu keluar.
Deadline penting. Misalnya, beri job in-flight 10 detik untuk berhenti. Setelah itu, log apa yang masih berjalan dan keluar. Itu menjaga deploy tetap dapat diprediksi dan menghindari proses yang macet.
Logging dan metrik sederhana untuk worker pool
Snapshot sebelum Anda mengubah concurrency
Simpan snapshot sebelum mengubah retry atau logika shutdown, lalu rollback dengan aman.
Saat worker pool bermasalah, jarang gagal secara keras. Job melambat, retry menumpuk, dan seseorang melapor bahwa "tidak ada yang terjadi." Logging dan beberapa counter dasar mengubah itu menjadi cerita yang jelas.
Beri setiap job ID stabil (atau buat saat submit) dan sertakan di setiap baris log. Jaga konsistensi log: satu baris saat job mulai, satu saat selesai, dan satu saat gagal. Jika Anda retry, log nomor percobaan dan delay berikutnya.
Bentuk log sederhana:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metrik bisa tetap minimal dan tetap berguna. Lacak panjang antrean, job in-flight, total sukses dan gagal, serta latensi job (setidaknya rata-rata dan maksimum). Jika panjang antrean terus naik dan in-flight tetap di angka worker count, Anda jenuh. Jika submitter terblok mengirim ke channel jobs, backpressure mencapai pemanggil. Itu tidak selalu buruk, tapi harus disengaja.
Saat "job macet", periksa apakah proses masih menerima job, apakah panjang antrean tumbuh, apakah worker hidup, dan job mana yang berjalan paling lama. Runtime panjang biasanya menunjukkan timeout yang hilang, dependensi lambat, atau loop retry yang tak berhenti.
Contoh realistis: antrean latar belakang SaaS kecil
Bayangkan SaaS kecil di mana order berubah menjadi PAID. Setelah pembayaran, Anda perlu mengirim PDF faktur, mengirim email ke pelanggan, dan memberi tahu tim internal. Anda tidak ingin pekerjaan itu memblok request web. Ini cocok untuk worker pool karena pekerjaan ini nyata, tapi sistem masih kecil.
Payload job bisa minimal: cukup untuk mengambil sisanya dari database. Handler API menulis baris seperti jobs(status='queued', type='send_invoice', payload, attempts=0) dalam transaksi yang sama dengan update order, lalu loop latar belakang polling job yang queued dan mendorongnya ke channel worker.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Saat worker mengambilnya, jalur bahagia sederhana: muat order, buat invoice, panggil provider email, lalu tandai job selesai.
Retry adalah tempat ini menjadi nyata. Jika provider email Anda mengalami gangguan sementara, Anda tidak ingin 1.000 job gagal selamanya atau membombardir provider setiap detik. Pendekatan praktis:
- Anggap error jaringan dan respons 5xx sebagai retryable.
- Gunakan exponential backoff dengan delay maksimal (misalnya 5s, 15s, 45s, 2m).
- Batasi attempt (misalnya 10) lalu tandai job gagal.
- Simpan error terakhir agar tim support bisa melihat apa yang terjadi.
Selama gangguan, job bergerak dari queued ke in_progress, lalu kembali ke queued dengan waktu run di masa depan. Saat provider pulih, worker akan menguras backlog itu.
Bayangkan deploy. Anda kirim SIGTERM. Proses harus berhenti mengambil pekerjaan baru tapi menyelesaikan yang sedang berjalan. Hentikan polling, hentikan mengisi channel worker, dan tunggu worker dengan deadline. Job yang selesai ditandai done. Job yang masih berjalan saat deadline harus dikembalikan ke queued (atau dibiarkan in_progress dengan watchdog) agar bisa diambil ulang setelah versi baru mulai.
Kesalahan umum dan jebakan
Sebagian besar bug dalam pemrosesan latar belakang bukan pada logika job. Mereka muncul dari kesalahan koordinasi yang hanya terlihat saat beban tinggi atau saat shutdown.
Satu jebakan klasik adalah menutup channel dari lebih dari satu tempat. Hasilnya panic yang sulit direproduksi. Pilih satu pemilik untuk setiap channel (biasanya producer), dan jadikan itu satu-satunya tempat memanggil close(jobs).
Retry adalah area lain di mana niat baik menyebabkan outage. Jika Anda me-retry semuanya, Anda akan me-retry kegagalan permanen juga. Itu membuang-buang waktu, menambah beban, dan bisa mengubah masalah kecil menjadi insiden. Klasifikasikan error dan batasi retry dengan kebijakan yang jelas.
Duplikasi akan terjadi bahkan dengan desain hati-hati. Worker bisa crash di tengah job, timeout bisa terjadi setelah pekerjaan selesai, atau Anda bisa enqueue ulang saat deployment. Jika job tidak idempoten, duplikat bisa menyebabkan kerusakan nyata: dua faktur, dua email sambutan, dua refund.
Kesalahan yang paling sering muncul:
- Menutup channel yang sama dari banyak goroutine.
- Me-retry kegagalan permanen alih-alih menampilkannya.
- Tidak ada kunci idempoten, sehingga duplikat menyebabkan efek samping ganda.
- Antrean in-memory tak terbatas yang tumbuh sampai memori melonjak.
- Mengabaikan
context.Context, sehingga pekerjaan terus berjalan setelah shutdown dimulai.
Antrean tak terbatas sangat licik. Lonjakan pekerjaan bisa menumpuk diam-diam di RAM. Lebih baik gunakan buffer channel terbatas dan putuskan apa yang terjadi saat penuh: blok, drop, atau kembalikan error.
Daftar periksa cepat sebelum rilis
Bangun shutdown bersih di Go
Buat penangan sinyal dan timeout context dalam hitungan menit dari prompt chat.
Sebelum Anda merilis worker pool ke produksi, Anda harus bisa menjelaskan siklus hidup job itu dengan jelas. Jika seseorang bertanya "di mana job ini sekarang?", jawabannya tidak boleh menebak.
Daftar periksa pra-terbang praktis:
- Anda bisa menamai setiap status dan transisinya: queued, picked up, running, finished, failed (dan apa yang memindahkannya).
- Konkurensi adalah satu kenop (mis.
workerCount), dan mengubahnya tidak perlu menulis ulang kode. - Retry dibatasi: max attempt jelas, backoff bertambah, dan kegagalan permanen pergi ke tempat yang sengaja.
- Perilaku shutdown terbukti: Anda berhenti intake, biarkan job in-flight selesai, dan tetap punya timeout kaku.
- Log menjawab dasar: job ID, nomor attempt, durasi, dan alasan error.
Lakukan satu drill realistis sebelum rilis: enqueue 100 job "kirim email tanda terima", paksa 20 gagal, lalu restart service saat berjalan. Anda harus melihat retry berjalan sesuai harapan, tidak ada efek samping ganda, dan pembatalan benar-benar menghentikan pekerjaan saat deadline tercapai.
Jika ada item yang samar, perbaiki sekarang. Perbaikan kecil di sini menghemat hari kemudian.
Langkah berikutnya: kapan menambah infrastruktur lebih berat (dan kapan tidak)
Worker in-process sederhana sering cukup saat produk masih muda. Jika job Anda "bagus jika ada" (kirim email, refresh cache, buat laporan) dan Anda bisa menjalankannya ulang, worker pool membuat sistem mudah dipahami.
Tanda Anda sudah melewati batas worker in-process
Perhatikan titik tekanan ini:
- Anda menjalankan banyak instance aplikasi dan perlu hanya salah satunya yang mengambil job.
- Anda membutuhkan durability (job harus bertahan setelah crash dan deploy).
- Anda membutuhkan jejak audit: siapa yang enqueue, kapan dijalankan, dan hasil pastinya.
- Anda membutuhkan kontrol backpressure antar layanan, bukan hanya di dalam satu proses.
- Anda membutuhkan penjadwalan ketat atau delay panjang (jam atau hari) dengan bangun yang andal.
Jika tidak ada yang di atas benar, alat yang lebih berat bisa menambah lebih banyak bagian yang bergerak daripada manfaat.
Migrasi bertahap tanpa rewrite
Hedge terbaik adalah antarmuka job yang stabil: tipe payload kecil, ID, dan handler yang mengembalikan hasil yang jelas. Kemudian Anda bisa menukar backend antrean nanti (dari channel in-memory ke tabel database, lalu ke antrean khusus) tanpa mengubah kode bisnis.
Langkah tengah praktis adalah layanan Go kecil yang membaca job dari PostgreSQL, mengklaim dengan lock, dan memperbarui status. Anda dapat durability dan audit dasar sambil mempertahankan logika worker yang sama.
Jika ingin prototype cepat, Koder.ai (koder.ai) dapat menghasilkan starter Go + PostgreSQL dari prompt chat, termasuk tabel job latar belakang dan loop worker, serta snapshot dan rollback yang membantu saat Anda menyetel retry dan perilaku shutdown.