12 Jun 2025·8 menit
Dari User Stories ke Skema Database: Metode Berpanduan AI
Pelajari metode praktis mengubah user stories, entitas, dan alur kerja menjadi skema database yang jelas, serta bagaimana penalaran AI membantu mengecek celah dan aturan.
Pelajari metode praktis mengubah user stories, entitas, dan alur kerja menjadi skema database yang jelas, serta bagaimana penalaran AI membantu mengecek celah dan aturan.
Sebuah skema database adalah rencana bagaimana aplikasi Anda akan menyimpan hal-hal. Secara praktis, itu adalah:
Ketika skema cocok dengan pekerjaan nyata, ia mencerminkan apa yang orang sebenarnya lakukan—membuat, meninjau, menyetujui, menjadwalkan, menugaskan, membatalkan—bukan hanya apa yang terdengar rapi di papan tulis.
User stories dan acceptance criteria menjelaskan kebutuhan nyata dengan bahasa biasa: siapa melakukan apa, dan apa arti “selesai”. Jika Anda menggunakan itu sebagai sumber, skema cenderung tidak melewatkan detail penting (mis. “kita harus melacak siapa yang menyetujui pengembalian dana” atau “sebuah booking bisa dijadwal ulang beberapa kali”).
Mulai dari stories juga membuat Anda jujur tentang lingkup. Jika itu tidak ada di stories (atau workflow), perlakukan sebagai opsional daripada diam-diam membuat model rumit “untuk berjaga-jaga.”
AI bisa membantu Anda bergerak lebih cepat dengan:
AI tidak dapat diandalkan untuk:
Anggap AI sebagai asisten yang kuat, bukan pengambil keputusan.
Jika Anda ingin mengubah asisten itu menjadi momentum, platform vibe-coding seperti Koder.ai bisa membantu Anda beralih dari keputusan skema ke aplikasi React + Go + PostgreSQL yang bekerja lebih cepat—sambil tetap menjaga Anda mengontrol model, constraint, dan migrasi.
Desain skema adalah loop: draft → uji terhadap stories → temukan data yang hilang → perbaiki. Tujuan bukan keluaran sempurna pertama; melainkan model yang bisa Anda lacak kembali ke setiap user story dan dengan yakin mengatakan: “Ya, kita bisa menyimpan semua yang dibutuhkan workflow ini—dan kita bisa jelaskan kenapa setiap tabel ada.”
Sebelum Anda mengubah requirement menjadi tabel, pastikan jelas apa yang Anda modelkan. Skema yang baik jarang mulai dari kertas kosong—ia mulai dari pekerjaan konkret yang orang lakukan dan bukti yang Anda perlukan nanti (layar, output, dan edge case).
User stories adalah judul, tapi tidak cukup sendirian. Kumpulkan:
Jika Anda menggunakan AI, input-input ini menjaga model tetap relevan. AI bisa mengusulkan entitas dan kolom dengan cepat, tapi ia butuh artefak nyata agar tidak menciptakan struktur yang tidak cocok dengan produk Anda.
Acceptance criteria sering mengandung aturan database paling penting, bahkan ketika tidak menyebut data secara eksplisit. Cari pernyataan seperti:
Story yang kabur (“Sebagai user, saya bisa mengelola projects”) menyembunyikan banyak entitas dan workflow. Kesenjangan lain yang sering muncul adalah edge case yang hilang seperti pembatalan, retry, refund parsial, atau reasignment.
Sebelum berpikir tentang tabel atau diagram, baca user stories dan sorot kata benda. Dalam penulisan requirements, kata benda biasanya menunjuk ke “hal” yang harus diingat sistem—ini sering menjadi entitas dalam skema Anda.
Model mental cepat: kata benda menjadi entitas, sedangkan kata kerja menjadi aksi atau workflow. Jika story mengatakan “Seorang manager menugaskan teknisi pada sebuah job,” entitas yang mungkin adalah manager, technician, dan job—dan “menugaskan” menunjukkan relasi yang akan Anda modelkan nanti.
Tidak setiap kata benda pantas jadi tabel. Sebuah kata benda adalah kandidat kuat entitas ketika:
Jika sebuah kata benda muncul hanya sekali, atau hanya menjelaskan sesuatu lain (“tombol merah”, “Jumat”), mungkin bukan entitas.
Kesalahan umum adalah mengubah setiap detail menjadi tabel. Gunakan aturan praktis ini:
Dua contoh klasik:
AI bisa mempercepat penemuan entitas dengan memindai stories dan mengembalikan daftar draf kata benda yang dikelompokkan berdasarkan tema (orang, item kerja, dokumen, lokasi). Prompt berguna: “Ekstrak kata benda yang mewakili data yang harus disimpan, dan grupkan sinonim/duplikat.”
Anggap output sebagai titik awal, bukan jawaban final. Ajukan follow-up seperti:
Tujuan Langkah 1 adalah daftar entitas pendek dan bersih yang bisa Anda pertahankan dengan menunjuk kembali ke stories nyata.
Setelah menamai entitas (seperti Order, Customer, Ticket), pekerjaan berikutnya adalah menangkap detail yang akan Anda butuhkan nanti. Di database, detail itu adalah kolom (juga disebut atribut)—pengingat yang tidak boleh sistem lupa.
Mulailah dari user story, lalu baca acceptance criteria seperti daftar cek apa yang harus disimpan.
Jika requirement mengatakan “Pengguna bisa memfilter order berdasarkan tanggal pengiriman,” maka delivery_date bukan opsional—ia harus ada sebagai kolom (atau bisa diturunkan dengan andal dari data lain). Jika dikatakan “Tunjukkan siapa yang menyetujui permintaan dan kapan,” Anda kemungkinan perlu approved_by dan approved_at.
Tes praktis: Apakah seseorang akan membutuhkan ini untuk menampilkan, mencari, mengurutkan, mengaudit, atau menghitung sesuatu? Jika ya, kemungkinan besar itu kolom.
Banyak story menyebut kata seperti “status,” “type,” atau “priority.” Perlakukan ini sebagai kosakata terkontrol—set nilai yang dibatasi.
Jika set kecil dan stabil, enum sederhana bisa bekerja. Jika bisa berkembang, perlu label, atau butuh permissions (mis. dikelola admin), gunakan tabel lookup terpisah (mis. status_codes) dan simpan referensinya.
Ini cara stories berubah menjadi kolom yang dapat dipercaya—dapat dicari, dilaporkan, dan sulit salah masuk.
Setelah Anda mendaftar entitas (User, Order, Invoice, Comment, dll.) dan mendraf kolomnya, langkah berikut adalah menghubungkannya. Relasi adalah lapisan “bagaimana hal-hal ini berinteraksi” yang diimplikasikan oleh stories Anda.
Satu-ke-satu (1:1) berarti “satu hal punya tepat satu hal lain.”
User ↔ Profile (sering kali Anda bisa gabungkan kecuali ada alasan memisahkan).Satu-ke-banyak (1:N) berarti “satu hal bisa punya banyak hal lain.” Ini paling umum.
User → Order (simpan user_id di Order).Banyak-ke-banyak (M:N) berarti “banyak hal bisa berhubungan dengan banyak hal.” Ini perlu tabel tambahan.
Database tidak menyukai menyimpan “daftar product ID” di Order tanpa masalah ke depan (pencarian, pembaruan, pelaporan). Sebaiknya buat tabel join yang mewakili relasi itu.
Contoh:
OrderProductOrderItem (tabel join)OrderItem biasanya berisi:
order_idproduct_idquantity, unit_price, discountPerhatikan bagaimana detail story (mis. “quantity”) sering kali milik relasi, bukan entitas manapun.
Stories juga memberitahu apakah koneksi itu wajib atau kadang tidak ada.
Order butuh user_id (jangan biarkan kosong).phone bisa kosong.shipping_address_id mungkin kosong untuk order digital.Pengecekan cepat: jika story memberi kesan Anda tidak bisa membuat record tanpa link, perlakukan sebagai wajib. Jika story mengatakan “bisa”, “mungkin”, atau memberi pengecualian, perlakukan sebagai opsional.
Saat membaca story, tulis ulang sebagai pasangan sederhana:
User 1:N CommentComment N:1 UserLakukan ini untuk setiap interaksi dalam stories. Pada akhirnya, Anda akan punya model terhubung yang mencerminkan bagaimana pekerjaan terjadi—sebelum membuka alat diagram ER.
User stories memberi tahu apa yang diinginkan orang. Workflow menunjukkan bagaimana pekerjaan bergerak, langkah demi langkah. Menerjemahkan workflow ke data adalah salah satu cara tercepat untuk menangkap masalah "kita lupa menyimpan itu"—sebelum membangun apa pun.
Tulis alur kerja sebagai urutan aksi dan perubahan status. Misalnya:
Kata-kata yang diberi tebal itu sering menjadi field status (atau tabel kecil “state”), dengan nilai yang jelas diizinkan.
Saat Anda melangkah melalui tiap langkah, tanya: “Apa yang perlu kita ketahui nanti?” Workflow biasanya mengungkap kolom seperti:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequence untuk proses multi-langkahJika workflow termasuk menunggu, eskalasi, atau serah-terima, biasanya Anda butuh setidaknya satu timestamp dan satu kolom “siapa yang pegang sekarang”.
Beberapa langkah workflow bukan hanya kolom—mereka struktur data terpisah:
Berikan AI kedua hal: (1) user stories + acceptance criteria, dan (2) langkah-langkah workflow. Minta AI mencantumkan setiap langkah dan mengidentifikasi data yang diperlukan untuk tiap langkah (state, aktor, timestamp, output), lalu soroti persyaratan yang tidak didukung oleh kolom/tabel saat ini.
Di platform seperti Koder.ai, "cek celah" ini jadi praktis karena Anda bisa iterasi cepat: sesuaikan asumsi skema, regenerasi scaffolding, dan terus bergerak tanpa harus melalui boilerplate manual panjang.
Saat Anda mengubah user stories menjadi tabel, Anda tidak hanya mendaftar kolom—Anda juga memutuskan bagaimana data tetap teridentifikasi dan konsisten dari waktu ke waktu.
Primary key mengidentifikasi unik satu record—anggap sebagai kartu ID permanen baris.
Kenapa setiap baris butuh satu: stories mengimplikasikan update, referensi, dan history. Jika sebuah story mengatakan “Support bisa melihat order dan mengeluarkan refund,” Anda perlu cara stabil menunjuk order itu—meski customer ganti email, alamat diedit, atau status order berubah.
Dalam praktik, ini biasanya id internal (angka atau UUID) yang tak berubah.
Foreign key adalah cara satu tabel menunjuk aman ke tabel lain. Jika orders.customer_id merefer customers.id, database bisa menegakkan bahwa setiap order punya customer yang nyata.
Ini cocok dengan story seperti “Sebagai user, saya bisa melihat invoice saya.” Invoice tidak mengambang; ia terikat ke customer (dan sering ke order atau subscription).
User stories sering menyembunyikan aturan keunikan:
Aturan ini mencegah duplikat membingungkan yang muncul nanti sebagai “bug data.”
Index mempercepat pencarian seperti “temukan customer berdasarkan email” atau “daftar orders per customer.” Mulailah dengan index yang sesuai query paling umum dan aturan keunikan.
Yang ditunda: indexing berat untuk laporan jarang atau filter spekulatif. Tangkap kebutuhan itu di stories, validasi skema dulu, lalu optimalkan berdasarkan penggunaan nyata dan bukti slow-query.
Normalisasi punya satu tujuan sederhana: mencegah duplikasi yang bertentangan. Jika fakta yang sama bisa disimpan di dua tempat, nanti akan berbeda (dua ejaan, dua harga, dua alamat “terkini”). Skema ternormal menyimpan setiap fakta sekali, lalu mereferensikannya.
1) Waspadai grup berulang
Jika Anda melihat pola seperti “Phone1, Phone2, Phone3” atau “ItemA, ItemB, ItemC”, itu sinyal untuk tabel terpisah (mis. CustomerPhones, OrderItems). Grup berulang menyulitkan pencarian, validasi, dan skala.
2) Jangan salin nama/detail yang sama ke banyak tabel
Jika CustomerName muncul di Orders, Invoices, dan Shipments, Anda punya banyak sumber kebenaran. Simpan detail customer di Customers, dan simpan hanya customer_id di tempat lain.
3) Hindari “banyak kolom untuk hal yang sama”
Kolom seperti billing_address, shipping_address, home_address bisa wajar jika memang konsep berbeda. Tapi jika sebenarnya Anda memodelkan “banyak alamat dengan tipe berbeda”, gunakan tabel Addresses dengan field type.
4) Pisahkan lookup dari teks bebas
Jika pengguna memilih dari set yang diketahui (status, kategori, role), modelkan secara konsisten: enum terbatas atau tabel lookup. Ini mencegah perbedaan seperti “Pending” vs “pending” vs “PENDING.”
5) Periksa bahwa setiap kolom non-ID bergantung pada hal yang tepat
Pengecekan intuitif: dalam sebuah tabel, jika sebuah kolom menjelaskan sesuatu selain entitas utama tabel, kemungkinan besar kolom itu harus berada di tempat lain. Contoh: Orders tidak seharusnya menyimpan product_price kecuali maksudnya “harga saat order” (snapshot historis).
Kadang Anda memang menyimpan duplikat dengan sengaja:
Intinya membuatnya disengaja: dokumentasikan field mana sumber kebenaran dan bagaimana salinan diperbarui.
AI bisa menandai duplikasi mencurigakan (kolom berulang, nama kolom mirip, field status yang tidak konsisten) dan menyarankan pemisahan menjadi tabel. Manusia tetap memilih trade-off—kesederhanaan vs fleksibilitas vs performa—berdasarkan bagaimana produk benar-benar digunakan.
Aturan berguna: simpan fakta yang tidak bisa Anda buat ulang dengan andal nanti; hitung sisanya.
Data tersimpan adalah sumber kebenaran: line items, timestamp event, perubahan status, siapa melakukan apa. Data dihitung dihasilkan dari fakta itu: total, counter, flag seperti “is overdue”, dan rollup seperti “inventory saat ini”.
Jika dua nilai bisa dihitung dari fakta yang sama, sebaiknya simpan faktanya dan hitung sisanya untuk menghindari kontradiksi.
Nilai turunan berubah saat inputnya berubah. Jika Anda menyimpan input dan hasil turunan, Anda harus menjaga keduanya sinkron di seluruh workflow dan edge case (edit, refund, partial shipment, perubahan bertanggal mundur). Satu pembaruan yang terlewatkan, dan database mulai menceritakan dua kisah berbeda.
Contoh: menyimpan order_total sekaligus menyimpan order_items. Jika seseorang mengubah quantity atau memberikan diskon dan total tidak diperbarui dengan sempurna, finance melihat angka satu sementara keranjang menunjukkan angka lain.
Workflow memperlihatkan kapan Anda butuh kebenaran historis, bukan hanya “kebenaran sekarang”. Jika pengguna perlu tahu nilai pada saat itu, simpan snapshot.
Untuk sebuah order, Anda mungkin menyimpan:
order_total yang di-capture saat checkout (snapshot), karena pajak, diskon, dan aturan harga bisa berubah nantiUntuk inventory, “level inventory” sering dihitung dari pergerakan (penerimaan, penjualan, penyesuaian). Tetapi jika Anda butuh jejak audit, simpan pergerakan dan opsional simpan snapshot periodik untuk kecepatan laporan.
Untuk tracking login, simpan last_login_at sebagai fakta (timestamp event). “Aktif dalam 30 hari terakhir?” tetap dihitung.
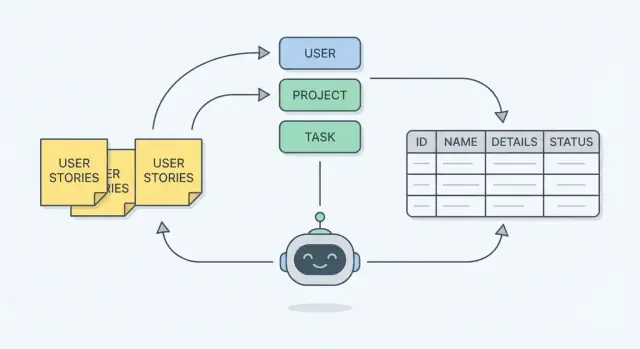
Mari gunakan aplikasi support ticket yang familiar. Kita akan mulai dari lima user stories ke model ER sederhana (entitas + kolom + relasi), lalu memeriksanya terhadap satu workflow.
Dari kata benda itu, kita dapat entitas inti:
Sebelum (keliru umum): Ticket punya assignee_id, tapi kita lupa memastikan hanya agent yang bisa jadi assignee.
Sesudah: AI menandai dan Anda menambahkan aturan praktis: assignee harus User dengan role = “agent” (diimplementasikan lewat validasi aplikasi atau constraint/policy database, tergantung stack Anda). Ini mencegah “ditugaskan ke customer” yang merusak laporan nanti.
Skema dianggap “selesai” ketika setiap user story bisa dijawab dengan data yang benar-benar bisa Anda simpan dan query. Langkah validasi paling sederhana adalah ambil tiap story dan tanyakan: “Bisakah kita menjawab pertanyaan ini dari database, andal, untuk setiap kasus?” Jika jawabannya “mungkin”, model Anda punya celah.
Tulis ulang tiap user story menjadi satu atau lebih pertanyaan uji—hal yang Anda harapkan laporan, layar, atau API tanyakan. Contoh:
Jika Anda tidak bisa mengekspresikan story sebagai pertanyaan jelas, story itu tidak jelas. Jika Anda bisa mengekspresikannya—tapi tidak bisa menjawabnya dengan skema—maka Anda kekurangan kolom, relasi, status/event, atau constraint.
Buat dataset kecil (5–20 baris per tabel kunci) yang mencakup kasus normal dan yang canggung (duplikat, nilai hilang, pembatalan). Kemudian “mainkan” stories menggunakan data itu. Anda akan cepat menemukan masalah seperti “kita tidak bisa tahu alamat mana yang dipakai saat pembelian” atau “tidak ada tempat untuk menyimpan siapa yang menyetujui perubahan.”
Minta AI menghasilkan pertanyaan validasi per story (termasuk edge case dan skenario penghapusan), dan mencantumkan data apa yang diperlukan untuk menjawabnya. Bandingkan daftar itu dengan skema Anda: setiap mismatch menjadi item tindakan konkret, bukan perasaan samar bahwa “ada yang salah.”
AI bisa mempercepat pemodelan data, tapi juga meningkatkan risiko bocornya data sensitif atau hard-coding asumsi buruk. Perlakukan sebagai asisten cepat: berguna, tapi perlu pembatasan.
Bagikan input yang realistis untuk dimodelkan, tapi disanitasi cukup untuk aman:
invoice_total: 129.50, status: "paid")Hindari apa pun yang bisa mengidentifikasi orang atau mengungkap operasi rahasia:
Jika perlu realisme, buat sampel sintetis yang sesuai format dan rentang—jangan menyalin baris produksi.
Skema sering gagal karena “semua orang mengasumsikan” hal berbeda. Di samping model ER (atau di repo yang sama), simpan log keputusan singkat:
Ini mengubah output AI menjadi pengetahuan tim alih-alih artefak satu kali.
Skema Anda akan berkembang dengan stories baru. Jaga aman dengan:
Jika Anda menggunakan platform seperti Koder.ai, manfaatkan guardrail seperti snapshot dan rollback ketika iterasi skema, dan ekspor kode sumber saat perlu kustomisasi lebih dalam atau review tradisional.
Mulailah dari stories dan tandai kata benda yang mewakili hal-hal yang sistem harus ingat (mis. Ticket, User, Category).
Kenaikkan sebuah kata benda menjadi entitas ketika:
Simpan daftar singkat yang bisa Anda jelaskan dengan menunjuk kalimat spesifik dari story.
Gunakan tes “atribut vs entitas”:
customer.phone_number).Petunjuk cepat: jika Anda perlu “banyak dari ini”, besar kemungkinan butuh tabel lain.
Perlakukan acceptance criteria sebagai daftar cek penyimpanan. Jika sebuah persyaratan mengatakan Anda harus memfilter/menampilkan/mencatat sesuatu, Anda harus menyimpannya (atau bisa menurunkannya dengan andal).
Contoh:
approved_by, approved_atUbah kalimat story menjadi kalimat relasi:
customer_id pada orders)order_items)Jika relasi itu sendiri punya data (quantity, price, role), data itu harus ada di tabel join.
Modelkan M:N dengan tabel join yang menyimpan kedua foreign key plus kolom spesifik relasi.
Pola umum:
ordersproductsJalani alur kerja langkah demi langkah dan tanyakan: “Apa yang perlu kita buktikan nanti?”
Tambahan umum:
submitted_at, closed_atMulai dengan:
id)orders.customer_id → customers.id)Lalu tambahkan index untuk lookup yang paling sering (mis. , , ). Tunda indexing spekulatif sampai Anda lihat pola query nyata.
Lakukan pemeriksaan konsistensi cepat:
Phone1/Phone2, pecah jadi tabel anak.Denormalisasi boleh dilakukan nanti dengan alasan jelas (performansi, reporting, snapshot audit) dan dokumentasikan sumber kebenaran.
Simpan fakta yang tidak bisa dibuat ulang dengan andal nanti; hitung sisanya.
Baik disimpan:
Baik dihitung:
Jika Anda menyimpan nilai terderived (mis. ), tentukan bagaimana sinkronisasinya dan uji kasus tepi (refund, edit, pengiriman parsial).
Gunakan AI untuk draf, lalu verifikasi terhadap artefak Anda.
Prompt praktis:
Pembatasan:
delivery_dateemailorder_items dengan order_id, product_id, quantity, unit_priceHindari menyimpan “daftar ID” dalam satu kolom — querying, update, dan integritas jadi sulit.
created_by, assigned_to, closed_byrejection_reasonJika Anda perlu tahu “siapa mengubah apa kapan”, tambahkan tabel event/audit daripada menimpa satu kolom.
emailcustomer_idstatus + created_atorder_total