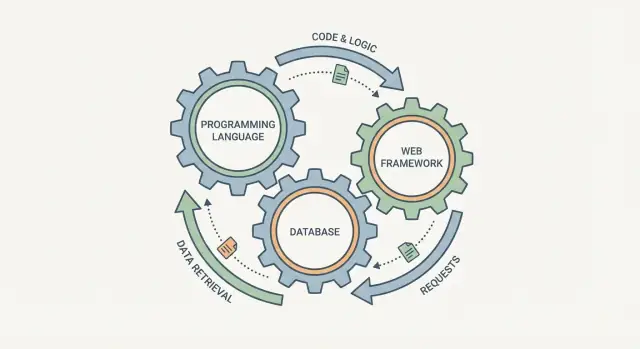
Kenapa Ini Bukan Pilihan Terpisah
Mudah tergoda untuk memilih bahasa pemrograman, basis data, dan framework web sebagai tiga kotak pilihan terpisah. Pada praktiknya, mereka lebih seperti roda gigi yang saling terhubung: ubah satu, dan yang lainnya merasakannya.
Sebuah framework web membentuk cara permintaan ditangani, bagaimana data divalidasi, dan bagaimana error ditampilkan. Basis data membentuk apa yang terlihat “mudah disimpan”, bagaimana Anda mengkueri informasi, dan jaminan apa yang Anda dapatkan ketika banyak pengguna bertindak bersamaan. Bahasa pemrograman berada di tengah: menentukan seberapa aman Anda bisa mengekspresikan aturan, bagaimana Anda mengelola konkurensi, dan pustaka serta tooling mana yang bisa diandalkan.
Apa arti “satu sistem”
Memperlakukan stack sebagai satu sistem berarti Anda tidak mengoptimalkan setiap bagian secara terpisah. Anda memilih kombinasi yang:
- Mewakili data Anda secara alami (agar Anda tidak terus-menerus melawan konversi)
- Mendukung kebutuhan konsistensi Anda (agar bug tidak bersembunyi di kasus tepi)
- Cocok dengan alur kerja tim Anda (agar pengiriman dan pemeliharaan dapat diprediksi)
Artikel ini tetap praktis dan sengaja tidak terlalu teknis. Anda tidak perlu menghafal teori basis data atau internal bahasa—cukup lihat bagaimana pilihan bergema ke seluruh aplikasi.
Contoh cepat: menggunakan basis data tanpa skema untuk data bisnis yang sangat terstruktur dan berat laporan sering berujung pada aturan yang tersebar di kode aplikasi dan analitik yang membingungkan nanti. Pasangan yang lebih baik adalah memadukan domain yang sama dengan basis data relasional dan framework yang mendorong validasi konsisten serta migrasi, sehingga data Anda tetap koheren seiring produk berkembang.
Ketika Anda merencanakan stack bersama-sama, Anda mendesain satu set tradeoff—bukan tiga taruhan terpisah.
Model Mental Sederhana: Request Masuk, Data Keluar
Cara membantu memikirkan “stack” adalah sebagai satu pipeline: sebuah permintaan pengguna masuk ke sistem Anda, dan sebuah respons (plus data yang disimpan) keluar. Bahasa pemrograman, framework web, dan basis data bukan pilihan independen—mereka tiga bagian dari perjalanan yang sama.
Perjalanan satu permintaan
Bayangkan seorang pelanggan memperbarui alamat pengiriman mereka.
- Request masuk: Framework menerima HTTP request. Routing memutuskan handler mana yang berjalan (mis.
/account/address). Validasi memeriksa input lengkap dan masuk akal.
- Kerja berlangsung: Kode aplikasi Anda (ditulis dalam bahasa pilihan) menjalankan aturan bisnis: “Apakah pengguna sudah login?”, “Apakah format alamat ini dapat diterima?”, “Haruskah kita menandai pesanan ini untuk pemeriksaan ulang?”
- Data keluar: Lapisan basis data membaca dan menulis record—sering kali dalam sebuah transaksi—sehingga pembaruan diterapkan sepenuhnya atau tidak sama sekali.
- Respons keluar: Framework memformat hasil (HTML/JSON), mengatur kode status, dan mengembalikannya ke pengguna.
- Sesudahnya: Pekerjaan latar belakang mungkin berjalan (kirim email konfirmasi, perbarui indeks pencarian, beri tahu gudang).
Tanggung jawab masing-masing pilihan
- Bahasa: Bagaimana kode berjalan (runtime/model konkurensi), seberapa mudah menguji dan men-debug, serta apakah keterampilan tim dan tool membuat perubahan aman dan cepat.
- Framework: “Pengaturan lalu lintas” untuk permintaan—routing, validasi, hook otentikasi, penanganan error, dan pola bawaan untuk pekerjaan latar belakang.
- Basis data: Bagaimana data disimpan dan di-query, constraint apa yang mencegah data buruk, dan bagaimana transaksi menjaga pembaruan terkait tetap konsisten.
Saat ketiganya selaras, sebuah request mengalir dengan bersih. Saat tidak, Anda mendapat gesekan: akses data yang canggung, validasi yang bocor, dan bug konsistensi yang halus.
Model Data Dulu: Penggerak Tersembunyi Kecocokan Stack
Sebagian besar perdebatan “stack” dimulai dari merek bahasa atau basis data. Titik awal yang lebih baik adalah model data Anda—karena itu diam-diam menentukan apa yang akan terasa alami (atau menyakitkan) di mana-mana: validasi, kueri, API, migrasi, dan bahkan alur kerja tim.
Bentuk data: objek, baris, dokumen, event
Aplikasi biasanya menjuggling empat bentuk sekaligus:
- Objek dalam kode (kelas, struct, record bertipe)
- Baris dalam tabel relasional
- Dokumen dalam penyimpanan bergaya JSON atau API
- Event dalam log/stream (“OrderPlaced”, “EmailSent”)
Kecocokan yang baik adalah ketika Anda tidak menghabiskan hari menerjemahkan antar bentuk. Jika data inti Anda sangat terhubung (users ↔ orders ↔ products), baris dan join dapat menjaga logika tetap sederhana. Jika data Anda sebagian besar “satu blob per entitas” dengan field yang variabel, dokumen dapat mengurangi ritual—hingga Anda membutuhkan pelaporan lintas-entitas.
Skema vs struktur fleksibel (dan di mana aturan berada)
Ketika basis data memiliki skema yang kuat, banyak aturan dapat hidup dekat dengan data: tipe, constraint, foreign key, uniqueness. Itu sering mengurangi pemeriksaan duplikat di berbagai layanan.
Dengan struktur fleksibel, aturan bergeser ke atas ke aplikasi: kode validasi, payload berversi, backfill, dan logika pembacaan yang hati-hati (“jika field ada, maka…”). Ini bisa bekerja baik saat kebutuhan produk berubah mingguan, tapi meningkatkan beban pada framework dan pengujian.
Bagaimana pilihan pemodelan memengaruhi kompleksitas kode
Model Anda menentukan apakah kode Anda sebagian besar:
- Melakukan query dan join (berat relasional)
- Mengubah JSON bersarang (berat dokumen)
- Memutar ulang dan mengagregasi event (berat event)
Itu pada gilirannya memengaruhi kebutuhan bahasa dan framework: tipe kuat dapat mencegah drift halus pada field JSON, sementara tooling migrasi matang lebih penting ketika skema berubah sering.
Contoh: profil pengguna, pesanan, log audit
- Profil pengguna: seringkali mirip dokumen (preferensi, field opsional) tetapi mendapat manfaat dari constraint relasional untuk identitas dan keunikan.
- Pesanan: biasanya relasional (line items, total, status) karena konsistensi dan pelaporan penting.
- Log audit: secara alami berbentuk event—catatan append-only yang jarang diubah, dioptimalkan untuk kueri berdasarkan waktu, pelaku, atau entitas.
Pilih model dulu; pilihan framework dan basis data yang “tepat” biasanya menjadi lebih jelas setelah itu.
Transaksi dan Konsistensi: Di Sini Bug Sering Dimulai
Transaksi adalah jaminan “semua-atau-tidak sama sekali” yang tanpa sadar diandalkan aplikasi Anda. Saat checkout berhasil, Anda mengharapkan record pesanan, status pembayaran, dan pembaruan inventori semua terjadi—atau tidak sama sekali. Tanpa janji itu, Anda mendapat bug paling sulit: langka, mahal, dan sulit direproduksi.
Apa yang dilakukan transaksi sebenarnya
Sebuah transaksi mengelompokkan beberapa operasi basis data menjadi satu unit kerja. Jika sesuatu gagal di tengah jalan (error validasi, timeout, proses crash), basis data bisa rollback ke keadaan aman sebelumnya.
Ini penting di luar aliran uang: pembuatan akun (user row + profile row), publikasi konten (post + tags + pointer indeks pencarian), atau alur kerja apa pun yang menyentuh lebih dari satu tabel.
Konsistensi vs kecepatan (dalam istilah sederhana)
Konsistensi berarti “bacaan sesuai kenyataan.” Kecepatan berarti “mengembalikan sesuatu dengan cepat.” Banyak sistem membuat tradeoff di sini:
- Konsistensi kuat: pengguna melihat data yang paling baru dikomit, lebih sedikit kejutan, seringkali biaya koordinasi lebih tinggi.
- Konsistensi eventual: pembaruan menyebar seiring waktu, biasanya lebih cepat dan lebih mudah diskalakan, tetapi aplikasi Anda harus menangani ketidaksesuaian sementara.
Polanya yang sering gagal adalah memilih setup eventual consistency, lalu menulis kode seolah-olah konsistensinya kuat.
Bagaimana framework dan ORM memengaruhi hasil
Framework dan ORM tidak otomatis membuat transaksi hanya karena Anda memanggil beberapa metode “save”. Beberapa membutuhkan blok transaksi eksplisit; yang lain memulai transaksi per request, yang bisa menyembunyikan masalah performa.
Retry juga rumit: ORM mungkin retry pada deadlock atau kegagalan sementara, tapi kode Anda harus aman dijalankan dua kali.
Perangkap umum
Penulisan parsial terjadi ketika Anda memperbarui A, lalu gagal sebelum memperbarui B. Tindakan duplikat terjadi ketika sebuah request di-retry setelah timeout—terutama jika Anda memungut kartu atau mengirim email sebelum transaksi dikomit.
Aturan sederhana membantu: lakukan efek samping (email, webhook) setelah commit basis data, dan buat aksi idempotent (aman diulang) dengan menggunakan constraint unik atau idempotency key.
Lapisan Akses Basis Data: ORM, Query, dan Migrasi
Ini adalah “lapisan terjemahan” antara kode aplikasi dan basis data Anda. Pilihan di sini sering lebih berpengaruh sehari-hari daripada merek basis data itu sendiri.
ORM vs query builder vs SQL mentah (dalam istilah sederhana)
Sebuah ORM (Object-Relational Mapper) memungkinkan Anda memperlakukan tabel seperti objek: buat User, perbarui Post, dan ORM menggenerasikan SQL di balik layar. Itu produktif karena menstandarkan tugas umum dan menyembunyikan plumbing berulang.
Query builder lebih eksplisit: Anda membangun kueri mirip SQL menggunakan kode (chain atau fungsi). Anda masih berpikir dalam “join, filter, group,” tetapi mendapatkan keamanan parameter dan komposabilitas.
SQL mentah adalah menulis SQL sebenarnya sendiri. Ini paling langsung dan sering paling jelas untuk kueri pelaporan kompleks—dengan biaya pekerjaan dan konvensi manual lebih banyak.
Bagaimana fitur bahasa membentuk pola akses
Bahasa dengan tipe kuat (TypeScript, Kotlin, Rust) cenderung mendorong Anda ke alat yang bisa memvalidasi kueri dan bentuk hasil lebih awal. Itu mengurangi kejutan runtime, tapi juga menekan tim untuk memusatkan akses data agar tipe tidak melenceng.
Bahasa dengan metaprogramming yang fleksibel (Ruby, Python) sering membuat ORM terasa alami dan cepat untuk iterasi—sampai kueri tersembunyi atau perilaku implisit menjadi sulit dipahami.
Migrasi: menjaga kode dan skema tetap sinkron
Migrasi adalah skrip perubahan versi untuk skema Anda: tambah kolom, buat indeks, backfill data. Tujuannya sederhana: siapa pun bisa deploy aplikasi dan mendapatkan struktur basis data yang sama. Perlakukan migrasi seperti kode yang Anda review, uji, dan rollback bila perlu.
Ketika abstraksi “mudah” malah merugikan
ORM dapat diam-diam menghasilkan N+1 queries, mengambil baris besar yang tidak Anda butuhkan, atau membuat join menjadi canggung. Query builder bisa berubah menjadi rantai yang tidak terbaca. SQL mentah bisa terduplikasi dan tidak konsisten.
Aturan bagus: gunakan alat paling sederhana yang membuat maksud jelas—dan untuk jalur kritis, periksa SQL yang benar-benar dijalankan.
Kinerja adalah Properti Sistem, Bukan Properti Basis Data
Hubungkan UI dan API
Jalankan frontend React yang terhubung ke endpoint nyata agar alur permintaan jelas.
Orang sering menyalahkan “basis data” ketika sebuah halaman terasa lambat. Tetapi kebanyakan latensi yang terlihat pengguna adalah jumlah dari banyak tunggu kecil di seluruh lintasan request.
Dari mana latensi sebenarnya berasal
Satu request biasanya membayar untuk:
- Waktu jaringan (client → load balancer → app → database dan kembali)
- Waktu kueri (SQL lambat, indeks yang hilang, terlalu banyak round trip)
- Serialisasi/deserialisasi (encoding JSON, pemetaan objek ORM, kompresi)
- Logika aplikasi (validasi, permission, rendering template, panggilan API eksternal)
Bahkan jika basis data bisa menjawab dalam 5 ms, aplikasi yang membuat 20 kueri per request, blocking I/O, dan menghabiskan 30 ms untuk serialisasi respons besar tetap akan terasa lambat.
Membuka koneksi basis data baru itu mahal dan dapat membanjiri basis data saat beban tinggi. Sebuah connection pool menggunakan kembali koneksi yang ada sehingga request tidak membayar biaya setup berulang.
Tangkapannya: ukuran pool “yang tepat” bergantung pada model runtime Anda. Server async dengan konkurensi tinggi bisa menciptakan permintaan simultan besar; tanpa batas pool, Anda akan mengalami antrean, timeout, dan kegagalan berisik. Dengan batas pool yang terlalu ketat, aplikasi menjadi bottleneck.
Caching: apa yang diperbaiki—dan apa yang tidak
Caching bisa ditempatkan di browser, CDN, cache in-process, atau cache bersama (seperti Redis). Ini membantu ketika banyak request membutuhkan hasil yang sama.
Namun caching tidak akan menyelamatkan:
- Jalur tulis yang tidak efisien
- Respons yang sangat dipersonalisasi
- Endpoint lambat yang didominasi oleh panggilan API eksternal
Runtime penting: thread vs async
Runtime bahasa pemrograman Anda membentuk throughput. Model thread-per-request bisa membuang sumber daya saat menunggu I/O; model async bisa meningkatkan konkurensi, tetapi juga membuat backpressure (seperti batas pool) menjadi penting. Itulah mengapa tuning performa adalah keputusan stack, bukan hanya keputusan basis data.
Keamanan dan Keandalan: Tanggung Jawab Bersama di Seluruh Stack
Keamanan bukan sesuatu yang Anda “tambahkan” dengan plugin framework atau pengaturan basis data. Ini adalah kesepakatan antara bahasa/runtime Anda, framework web, dan basis data tentang apa yang harus selalu benar—bahkan ketika seorang pengembang melakukan kesalahan atau endpoint baru ditambahkan.
Otentikasi vs Otorisasi: Lapisan berbeda, hasil yang sama
Otentikasi (siapa ini?) biasanya hidup di tepi framework: session, JWT, callback OAuth, middleware. Otorisasi (apa yang boleh mereka lakukan?) harus ditegakkan secara konsisten di logika aplikasi dan aturan data.
Pola umum: aplikasi menentukan intent (“pengguna bisa mengedit proyek ini”), dan basis data menegakkan batasan (tenant ID, constraint kepemilikan, dan—jika masuk akal—kebijakan level baris). Jika otorisasi hanya ada di controller, pekerjaan latar belakang dan skrip internal bisa tidak sengaja melewatinya.
Validasi: Framework, basis data, atau keduanya?
Validasi framework memberikan umpan balik cepat dan pesan error yang baik. Constraint basis data memberikan jaring pengaman terakhir.
Gunakan keduanya saat penting:
- Framework: field wajib, format, pesan ramah.
- Basis data: uniqueness, foreign keys, CHECK constraint, NOT NULL.
Ini mengurangi “status yang mustahil” yang muncul ketika dua request bersaing atau layanan baru menulis data berbeda.
Rahasia, enkripsi, dan auditing
Rahasia harus ditangani oleh runtime dan workflow deployment (env vars, secret manager), bukan hardcoded di kode atau migrasi. Enkripsi bisa terjadi di aplikasi (enkripsi per-field) dan/atau di basis data (enkripsi at-rest, managed KMS), tetapi Anda perlu kejelasan siapa yang merotasi kunci dan bagaimana recovery bekerja.
Auditing juga bersifat bersama: aplikasi harus memancarkan event yang bermakna; basis data harus menyimpan log yang tidak dapat diubah bila perlu (mis. tabel audit append-only dengan akses terbatas).
Mode kegagalan tipikal
Terlalu percaya pada logika aplikasi adalah klasik: constraint hilang, null diam-diam diterima, flag “admin” disimpan tanpa pemeriksaan. Perbaikannya sederhana: asumsikan bug akan terjadi, dan desain stack sehingga basis data dapat menolak penulisan yang tidak aman—bahkan dari kode internal Anda sendiri.
Jalur-Skalasi: Apa yang Dibuka atau Diblokir Setiap Pilihan
Buat satu potongan vertikal
Jelaskan alur kerja dan model data lewat chat, dapatkan UI, API, dan database dasar.
Skalasi jarang gagal karena “basis data tidak mampu.” Ia gagal karena seluruh stack bereaksi buruk saat bentuk beban berubah: satu endpoint menjadi populer, satu kueri menjadi panas, satu workflow mulai retry.
Saat trafik tumbuh, rasa sakit muncul di tempat spesifik
Sebagian besar tim menemui bottleneck awal yang sama:
- Kueri panas: satu kueri “halaman utama” atau dashboard berjalan terus dan mendominasi CPU/IO.
- Kekontenan lock: update menumpuk di belakang beberapa baris (counter inventori, “last_seen”, tabel antrean), memperlambat semuanya.
- Tekanan koneksi: worker aplikasi membuka terlalu banyak koneksi DB; basis data menghabiskan waktu mengelola session daripada bekerja.
Seberapa cepat Anda bisa merespons tergantung pada seberapa baik framework dan tooling basis data mengekspos rencana kueri, migrasi, connection pooling, dan pola caching yang aman.
Read replicas, sharding, dan antrean: kapan muncul
Langkah skalasi umum cenderung muncul dalam urutan:
- Read replicas saat pembacaan jauh lebih banyak dari penulisan dan Anda bisa mentolerir data agak usang. ORM/framework Anda harus mendukung pemisahan baca/tulis (atau memudahkan routing kueri).
- Queues/background jobs ketika pekerjaan “segera lakukan” mulai merugikan latensi request (email, export, panggilan billing). Di sinilah retry dan deduplikasi menjadi kebutuhan nyata.
- Sharding/partitioning ketika satu primary tidak mampu menangani throughput tulis atau pertumbuhan penyimpanan. Ini menuntut pemodelan data yang hati-hati: shard key, kueri lintas-shard, dan batasan transaksi.
Pekerjaan latar belakang dan idempotensi adalah fitur framework, bukan pemikiran di akhir
Stack yang bisa diskalakan membutuhkan dukungan first-class untuk tugas latar belakang, penjadwalan, dan retry yang aman.
Jika sistem job Anda tidak bisa menegakkan idempotensi (pekerjaan sama dijalankan dua kali tanpa double-charging atau double-sending), Anda akan “menskalakan” ke korupsi data. Pilihan awal—seperti mengandalkan transaksi implisit, constraint keunikan yang lemah, atau perilaku ORM yang opak—bisa menghalangi pengenalan pola antrean, outbox, atau workflow hampir-sekali-saja di kemudian hari.
Keselarasan awal membayar: pilih basis data yang cocok dengan kebutuhan konsistensi Anda, dan ekosistem framework yang membuat langkah skalasi berikutnya (replica, antrean, partisi) menjadi jalur yang didukung, bukan rewrite.
Pengalaman Pengembang dan Operasi: Satu Alur Kerja
Stack terasa “mudah” ketika pengembangan dan operasi berbagi asumsi yang sama: bagaimana Anda memulai aplikasi, bagaimana data berubah, bagaimana tes dijalankan, dan bagaimana Anda tahu apa yang terjadi ketika sesuatu rusak. Jika bagian-bagian itu tidak sinkron, tim membuang waktu pada glue code, skrip rapuh, dan runbook manual.
Kecepatan pengembangan lokal
Setup lokal yang cepat adalah sebuah fitur. Pilih alur kerja di mana rekan baru bisa clone, install, jalankan migrasi, dan memiliki data uji realistis dalam hitungan menit—bukan jam.
Itu biasanya berarti:
- Satu perintah untuk menjalankan aplikasi dan dependensi (sering via container).
- Migrasi yang berjalan andal di setiap mesin.
- Seed data yang mencerminkan bentuk produksi (bukan hanya baris “hello world”).
Jika tooling migrasi framework Anda melawan pilihan basis data, setiap perubahan skema menjadi proyek kecil.
Piramida pengujian yang cocok dengan stack Anda
Stack Anda harus membuatnya alami untuk menulis:
- Unit tests yang tidak memerlukan basis data.
- Integration tests yang menyentuh skema dan kueri basis data nyata.
- End-to-end tests yang menguji jalur permintaan penuh.
Mode gagal umum: tim mengandalkan unit test karena integration test lambat atau menyulitkan. Itu sering merupakan mismatch stack/ops—provisioning basis data test, migrasi, dan fixture tidak disederhanakan.
Observabilitas antar aplikasi dan basis data
Saat latensi melonjak, Anda perlu mengikuti satu request melalui framework dan ke basis data.
Cari structured logs, metrik dasar (rate request, error, DB time), dan traces yang menyertakan waktu kueri. Bahkan correlation ID sederhana yang muncul di log aplikasi dan log basis data dapat mengubah “menebak” menjadi “menemukan.”
Kesesuaian operasional: perubahan aman dan pemulihan
Operasi bukan terpisah dari pengembangan; itu kelanjutan darinya.
Pilih tooling yang mendukung:
- Backup dan restore yang sudah Anda uji (bukan hanya dikonfigurasi).
- Perubahan skema yang bisa dijalankan maju dengan aman (dan kadang-kadang rollback).
- Jalur yang jelas untuk “apa yang terjadi saat deploy” sehingga rilis tidak bergantung pada pengetahuan tribal.
Jika Anda tidak bisa melakukan rehearsal restore atau migrasi secara lokal dengan percaya diri, Anda tidak akan melakukannya dengan baik di bawah tekanan.
Checklist Praktis untuk Memilih Stack yang Koheren
Memilih stack kurang tentang memilih alat “terbaik” dan lebih tentang memilih alat yang saling cocok di bawah kendala nyata Anda. Gunakan checklist ini untuk memaksa keselarasan sejak awal.
1) Checklist cepat (fit sebelum fitur)
- Keterampilan tim: Apa yang tim Anda bisa kirimkan dan pelihara dengan percaya diri selama 12–24 bulan?
- Bentuk domain: Sebagian besar workflow dan record, atau aturan kompleks, atau pelaporan berat?
- Kebutuhan data: Integritas relasional, dokumen fleksibel, time-series, full-text search, analytics?
- Keterbatasan: Kepatuhan, target latensi, model deployment, anggaran, infrastruktur yang sudah ada.
- Toleransi kegagalan: Bisakah menerima eventual consistency, atau butuh transaksi ketat?
2) Petakan produk Anda ke pola umum
- Aplikasi CRUD-heavy (internal tools, back office, early SaaS): Framework web konvensional + DB relasional biasanya jalur tercepat karena migrasi, transaksi, dan workflow admin sederhana.
- Analytics-heavy (dashboard, event tracking): Rencanakan store OLAP atau data warehouse sejak awal; mencoba “menjadikan Postgres sistem BI” dapat memperlambat kueri dan pekerjaan produk.
- Real-time (chat, kolaborasi, streaming): Prioritaskan dukungan WebSocket, pub/sub, dan konkurensi yang dapat diprediksi. Pilihan bahasa/runtime memengaruhi seberapa menyakitkan ini.
- SaaS multi-tenant: Putuskan di awal: database terpisah, skema terpisah, atau tenancy per-baris. Pilihan ini merambat ke auth, migrasi, dan operasi dukungan.
3) Jalankan bukti konsep kecil (tanpa overbuild)
Time-box ke 2–5 hari. Bangun satu slice vertikal tipis: satu workflow inti, satu job latar belakang, satu kueri seperti laporan, dan otentikasi dasar. Ukur gesekan pengembang, ergonomi migrasi, kejelasan kueri, dan seberapa mudah menguji.
Jika ingin mempercepat langkah ini, alat vibe-coding seperti Koder.ai bisa berguna untuk cepat menghasilkan slice vertikal bekerja (UI, API, dan basis data) dari spesifikasi berbasis chat—lalu iterasi dengan snapshot/rollback dan ekspor kode sumber ketika siap commit arah.
4) Tulis satu halaman catatan keputusan
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
Mismatch Umum (dan Cara Menghindarinya)
Permudah review
Bagikan aplikasi nyata dengan tim dan pemangku kepentingan menggunakan domain kustom.
Bahkan tim kuat berakhir dengan mismatch stack—pilihan yang tampak baik secara terpisah tetapi menciptakan gesekan setelah sistem dibangun. Kabar baik: kebanyakan dapat diprediksi, dan Anda bisa menghindarinya dengan beberapa pemeriksaan.
Bau yang perlu diwaspadai
Bau klasik adalah memilih basis data atau framework karena sedang tren sementara model data Anda masih kabur. Lainnya adalah scaling prematur: mengoptimalkan untuk jutaan pengguna sebelum bisa menangani ratusan dengan andal, yang sering berujung pada infrastruktur ekstra dan lebih banyak mode kegagalan.
Perhatikan juga stack di mana tim tidak bisa menjelaskan mengapa setiap bagian besar ada. Jika jawabannya kebanyakan “semua orang menggunakannya,” Anda mengumpulkan risiko.
Risiko integrasi yang menyengat nanti
Banyak masalah muncul di sambungan:
- Driver dan fitur yang tidak cocok: driver bahasa Anda tidak mendukung fitur DB yang Anda anggap ada (tipe, streaming, retry).
- Migrasi lemah: perubahan skema dikelola manual, atau tooling migrasi tidak cocok dengan evolusi aplikasi, menyebabkan drift antar lingkungan.
- Connection pooling buruk: framework membuka terlalu banyak koneksi, atau deployment menggandakan pool di proses/container, menyebabkan timeout saat beban.
Ini bukan masalah “basis data” atau “framework”—ini masalah sistem.
Cara menyederhanakan (dan mengurangi risiko)
Prefer lebih sedikit bagian yang bergerak dan satu jalur jelas untuk tugas umum: satu pendekatan migrasi, satu gaya kueri untuk sebagian besar fitur, dan konvensi konsisten across services. Jika framework Anda mendorong pola (lifecycle request, dependency injection, pipeline job), manfaatkan itu daripada mencampur gaya.
Kapan meninjau kembali keputusan—dan mengganti dengan aman
Tinjau kembali saat Anda melihat insiden produksi berulang, gesekan pengembang yang persisten, atau ketika kebutuhan produk secara fundamental mengubah pola akses data Anda.
Ganti dengan aman dengan mengisolasi sambungan: perkenalkan lapisan adapter, migrasikan secara bertahap (dual-write atau backfill bila perlu), dan buktikan kesetaraan dengan tes otomatis sebelum mengalihkan traffic.
Penutup: Perlakukan Stack sebagai Satu Sistem
Memilih bahasa pemrograman, framework web, dan basis data bukan tiga keputusan independen—itu satu keputusan desain sistem yang diekspresikan di tiga tempat. Opsi “terbaik” adalah kombinasi yang selaras dengan bentuk data inti Anda, kebutuhan konsistensi, alur kerja tim, dan cara Anda mengharapkan produk tumbuh.
Yang perlu diingat
- Pilih stack di sekitar model data inti Anda dan operasi yang paling sering Anda lakukan.
- Konsistensi dan transaksi juga merupakan perhatian aplikasi—rancang secara end-to-end, bukan hanya di sisi basis data.
- Bottleneck kinerja biasanya melintasi batas (skema, kueri, caching, serialisasi, antrean).
- Keamanan dan keandalan adalah tanggung jawab bersama di kode, konfigurasi, dan operasi.
- Pengalaman pengembang penting karena menentukan seberapa cepat Anda bisa mengirim dengan aman.
Dokumentasikan asumsi (sebelum menjadi batasan)
Tuliskan alasan di balik pilihan Anda: pola trafik yang diharapkan, latensi yang dapat diterima, aturan retensi data, mode kegagalan yang dapat ditoleransi, dan apa yang secara eksplisit tidak Anda optimalkan saat ini. Ini membuat tradeoff terlihat, membantu anggota tim di masa depan memahami “mengapa,” dan mencegah drift arsitektur saat kebutuhan berubah.
Langkah berikutnya
Jalankan setup Anda saat ini melalui bagian checklist dan catat di mana keputusan tidak selaras (mis. skema yang melawan ORM, atau framework yang membuat pekerjaan latar belakang canggung).
Jika Anda sedang menjajaki arah baru, alat seperti Koder.ai juga bisa membantu membandingkan asumsi stack dengan cepat dengan menghasilkan aplikasi dasar (umumnya React di web, layanan Go dengan PostgreSQL, dan Flutter untuk mobile) yang dapat Anda inspeksi, ekspor, dan kembangkan—tanpa berkomitmen pada siklus build panjang terlebih dahulu.
Untuk tindak lanjut lebih mendalam, jelajahi panduan terkait di /blog, lihat detail implementasi di /docs, atau bandingkan opsi dukungan dan deployment di /pricing.