29 Des 2025·8 menit
Alat admin yang mencegah kehilangan data: aksi massal yang lebih aman
Alat admin yang mencegah kehilangan data memakai aksi massal yang lebih aman, konfirmasi jelas, soft delete, log audit, dan pembatasan peran agar operator menghindari kesalahan mahal.
Tempat kehilangan data terjadi di alat admin
Alat admin internal terasa lebih aman karena “hanya staf” yang bisa menggunakannya. Justru kepercayaan itu yang membuatnya berisiko tinggi. Orang yang menggunakannya punya wewenang, bekerja cepat, dan sering mengulang aksi yang sama berulang kali setiap hari. Satu slip bisa menyentuh ribuan record.
Sebagian besar kecelakaan bukan karena niat jahat. Mereka muncul dari momen “ups”: filter yang terlalu luas, kata pencarian yang mencocokkan lebih banyak dari yang diharapkan, atau dropdown yang tetap berada pada tenant yang salah. Klasik lain adalah lingkungan yang keliru: seseorang mengira sedang di staging, padahal melihat produksi karena UI hampir sama.
Kecepatan dan pengulangan memperburuk ini. Ketika alat dibuat untuk bergerak cepat, pengguna belajar memori otot: klik, konfirmasi, lanjut. Jika layar lag, mereka mengklik dua kali. Jika aksi massal butuh waktu, mereka membuka tab kedua. Kebiasaan ini normal, tapi menciptakan kondisi untuk kesalahan.
"Menghancurkan data" bukan hanya menekan tombol hapus. Dalam praktiknya bisa berarti:
- Menghapus record (termasuk delete bersarang/cascading)
- Menimpa field (mis. mengubah status menjadi “closed” untuk set yang salah)
- Memutus relasi (menghapus tautan pengguna dari akun, mencabut izin)
- Menghapus riwayat (mengosongkan log, menghapus pesan, mem-truncate tabel)
- Ekspor atau sinkronisasi yang tidak dapat dikembalikan (mendorong data yang salah ke sistem lain)
Bagi tim yang membangun alat admin untuk mencegah kehilangan data, “cukup aman” sebaiknya menjadi kesepakatan yang jelas, bukan suasana. Definisi sederhana: operator yang terburu-buru harus bisa pulihkan dari kesalahan umum tanpa bantuan engineering, dan aksi yang jarang tapi tidak dapat dibalik harus memerlukan friksi ekstra, bukti niat yang jelas, dan catatan yang bisa diaudit nanti.
Bahkan jika Anda membangun aplikasi dengan cepat menggunakan platform seperti Koder.ai, risikonya tetap sama. Bedanya adalah apakah Anda merancang pembatas sejak hari pertama atau menunggu insiden pertama untuk mengajarkan pelajaran.
Mulai dengan peta risiko sederhana
Sebelum mengubah UI apa pun, jelas-kan apa yang sebenarnya bisa salah. Peta risiko adalah daftar singkat aksi yang bisa menyebabkan kerugian nyata, plus aturan yang harus mengelilinginya. Langkah ini memisahkan alat admin yang benar-benar mencegah kehilangan data dari yang hanya terlihat hati-hati.
Mulailah dengan menulis aksi paling berbahaya. Biasanya bukan edit sehari-hari. Mereka adalah operasi yang mengubah banyak record dengan cepat atau menyentuh data sensitif.
Contoh awal yang berguna:
- Hapus, gabung, tutup, atau nonaktifkan akun sepenuhnya
- Menetapkan ulang kepemilikan (pelanggan, faktur, tiket, lead)
- Impor dan pembaruan massal (CSV, job API, migrasi)
- Aksi penagihan (refund, kredit, pembatalan)
- Perubahan izin (peran, akses ke PII)
Selanjutnya, tandai setiap aksi sebagai reversible atau irreversible. Bersikap ketat. Jika Anda hanya bisa membaliknya dengan merestore dari backup, anggap itu irreversible untuk operator yang sedang bekerja.
Kemudian putuskan apa yang harus dilindungi oleh kebijakan, bukan hanya desain. Aturan hukum dan privasi sering berlaku untuk PII (nama, email, alamat), catatan penagihan, dan log audit. Meski alat secara teknis bisa menghapus sesuatu, kebijakan Anda mungkin mengharuskan retensi atau review dua orang.
Pisahkan operasi rutin dari operasi luar biasa. Pekerjaan rutin harus cepat dan aman (perubahan kecil, undo jelas). Pekerjaan luar biasa harus sengaja lebih lambat (cek ekstra, persetujuan, batas lebih ketat).
Akhirnya, sepakati istilah “radius ledakan” sederhana supaya semua orang berbicara dengan bahasa yang sama: satu record, banyak record, semua record. Misalnya, “tetapkan ulang satu pelanggan ini” berbeda dari “tetapkan ulang semua pelanggan dari sales rep ini.” Label itu nantinya akan mengarahkan default, konfirmasi, dan batas peran Anda.
Contoh: di proyek vibe-coding di Koder.ai, Anda bisa memberi tag “impor massal pengguna” sebagai many-records, hanya reversible jika setiap ID yang dibuat dicatat, dan dilindungi kebijakan karena menyentuh PII.
Pola untuk aksi massal yang lebih aman
Aksi massal adalah tempat di mana alat admin yang baik bisa berubah jadi berisiko. Jika Anda membangun alat admin untuk mencegah kehilangan data, perlakukan setiap tombol “apply to many” seperti alat listrik berdaya tinggi: berguna, tapi dirancang untuk menghindari slip.
Default yang kuat adalah preview dulu, lalu jalankan. Alih-alih mengeksekusi langsung, tunjukkan apa yang akan berubah dan biarkan operator mengonfirmasi hanya setelah mereka melihat cakupan.
Jelaskan cakupan secara eksplisit dan jangan biarkan ambigu. Jangan terima “semua” sebagai gagasan yang samar. Paksa operator untuk mendefinisikan filter seperti tenant, status, dan rentang tanggal, lalu tunjukkan jumlah pasti record yang cocok. Daftar sampel kecil (bahkan 10 item) membantu orang melihat kesalahan seperti “region yang salah” atau “termasuk arsip.”
Pola praktis yang bekerja baik:
- Mulai dengan layar dry run yang menunjukkan hitungan, filter, dan sampel singkat record yang terdampak
- Wajibkan pilihan cakupan yang eksplisit (mis. “Hanya pelanggan Aktif di Tenant A, dibuat sebelum 2024-01-01”)
- Batasi tiap run (mis. 1.000 record) dan minta dijalankan lagi untuk batch berikutnya
- Atur throttle sehingga satu klik buruk tidak membebani database atau sistem downstream
- Jalankan sebagai job antrian dengan progress, log, dan opsi batal yang jelas
Job antrian lebih baik daripada “fire-and-forget” karena mereka membuat jejak kertas dan memberi kesempatan operator menghentikan aksi saat menyadari sesuatu yang salah pada 5% selesai.
Contoh: operator ingin menonaktifkan akun pengguna massal setelah lonjakan kecurangan. Preview menunjukkan 842 akun, namun sampel termasuk pelanggan VIP. Petunjuk kecil itu sering mencegah kesalahan nyata: filter yang terlepas seperti “fraud_flag = true.”
Jika Anda merakit konsol internal dengan cepat (bahkan dengan platform build-by-chat seperti Koder.ai), tanamkan pola ini sejak awal. Mereka menghemat lebih banyak waktu daripada yang mereka tambahkan.
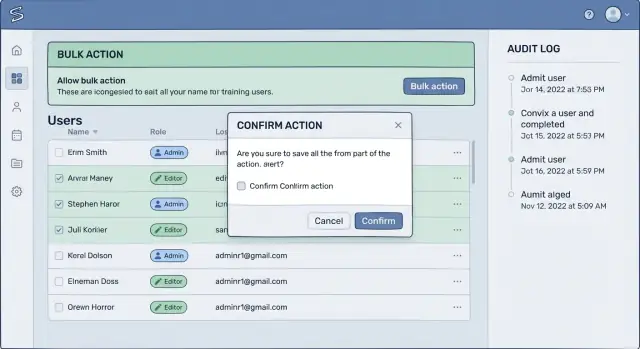
Alur konfirmasi yang benar-benar dibaca orang
Sebagian besar konfirmasi gagal karena terlalu generik. Jika layar hanya menulis “Apa Anda yakin?”, orang mengklik lewat secara otomatis. Konfirmasi yang efektif menggunakan kata-kata yang sama yang akan dipakai pengguna untuk menjelaskan hasilnya ke rekan.
Ganti label samar seperti “Delete” atau “Apply” dengan dampak nyata: “Nonaktifkan 38 akun”, “Cabut akses untuk tenant ini”, atau “Batalkan 12 faktur”. Ini salah satu perbaikan paling sederhana untuk alat admin yang mencegah kehilangan data karena mengubah klik refleks menjadi momen pengenalan.
Buat pengguna mengonfirmasi cakupan
Alur yang baik memaksa pengecekan cepat di kepala: “Apakah ini hal yang tepat, pada set record yang tepat?” Letakkan cakupan di konfirmasi, bukan hanya di halaman di belakangnya. Sertakan nama tenant atau workspace, jumlah record, dan filter seperti rentang tanggal atau status.
Contoh: “Tutup akun untuk Tenant: Acme Retail. Jumlah: 38. Filter: last login sebelum 2024-01-01.” Jika salah satu nilai terlihat aneh, pengguna akan menangkapnya sebelum kerusakan terjadi.
Saat aksi benar-benar destruktif, minta tindakan kecil yang disengaja. Konfirmasi yang diketik bekerja baik ketika biaya kesalahan tinggi.
- Minta frasa singkat seperti HAPUS 38 AKUN
- Atau minta ketik nama tenant persis
- Atau minta mereka memasukkan kembali jumlah yang ditampilkan di layar
Gunakan dua langkah hanya saat dampak tinggi
Konfirmasi dua langkah sebaiknya jarang, atau pengguna akan mengabaikannya. Simpan itu untuk aksi yang sulit dipulihkan, lintas-tenant, atau yang mempengaruhi uang. Langkah pertama mengonfirmasi niat dan cakupan. Langkah kedua mengonfirmasi waktu, seperti “Jalankan sekarang” vs “Jadwalkan”, atau memerlukan persetujuan dengan izin lebih tinggi.
Akhirnya, hindari “OK/Cancel”. Tombol harus mengatakan apa yang terjadi: “Nonaktifkan akun” dan “Kembali”. Ini mengurangi klik yang salah dan membuat keputusan terasa nyata.
Soft delete, restore, dan aturan retensi
Rilis konsol admin
Ubah risk map Anda menjadi halaman untuk audit, restore, dan job antrian di satu tempat.
Soft delete adalah default paling aman untuk banyak record yang terlihat pengguna: akun, pesanan, tiket, posting, bahkan payout. Alih-alih menghapus baris, tandai sebagai terhapus dan sembunyikan dari tampilan normal. Ini salah satu pola paling sederhana di balik alat admin yang mencegah kehilangan data karena kesalahan menjadi bisa dibalik.
Kebijakan soft delete perlu jendela retensi yang jelas dan kepemilikan yang jelas. Putuskan berapa lama item yang dihapus bisa dipulihkan (mis. 30 atau 90 hari), dan siapa yang boleh mengembalikannya. Kaitkan hak restore ke peran, bukan individu, dan anggap restore sebagai perubahan produksi.
Buat restore terlihat (dan tercatat)
Restore harus mudah ditemukan ketika seseorang melihat record yang dihapus, bukan terkubur di layar terpisah. Tambahkan status terlihat seperti “Deleted”, tunjukkan kapan itu terjadi, dan siapa yang melakukannya. Saat restore terjadi, catat sebagai event sendiri, bukan sebagai edit pada penghapusan asli.
Cara cepat menentukan aturan retensi adalah menjawab pertanyaan ini:
- Berapa periode retensi default per tipe objek?
- Peran mana yang bisa merestore, dan apakah mereka perlu alasan?
- Apa yang terjadi setelah periode retensi berakhir?
- Siapa yang bisa memperpanjang retensi untuk kasus hukum atau penagihan?
- Bagaimana Anda menangani permintaan “hapus data saya”?
Kasus tepi yang memecah restore
Soft delete terdengar mudah sampai Anda merestore ke dunia yang sudah berubah. Constraint unik bisa bertabrakan (nama pengguna digunakan ulang), referensi bisa hilang (parent record dihapus), dan riwayat penagihan harus tetap konsisten meski pengguna “hilang.” Pendekatan praktis adalah menyimpan ledger immutable (faktur, event pembayaran) terpisah dari data profil pengguna, dan merestore relasi secara hati-hati, dengan peringatan jelas ketika restore penuh tidak mungkin.
Hard delete sebaiknya jarang dan eksplisit. Jika Anda mengizinkannya, buat terasa sebagai pengecualian, dengan jalur persetujuan singkat:
- Memerlukan peran lebih tinggi daripada soft delete
- Minta konfirmasi yang diketik dan alasan
- Antrian delete dengan delay singkat (mis. 24 jam)
- Beri notifikasi ke owner atau channel on-call
- Simpan catatan audit akhir bahkan setelah penghapusan
Jika Anda membangun admin di platform seperti Koder.ai, definisikan soft delete, restore, dan retensi sebagai tindakan kelas-satu sejak awal, supaya konsisten di setiap layar dan workflow yang dihasilkan.
Auditability: buat aksi bisa dijelaskan nanti
Kecelakaan terjadi di panel admin, tapi kerusakan nyata sering muncul kemudian: tidak ada yang bisa menjawab apa yang berubah, siapa yang melakukannya, dan kenapa. Jika Anda ingin alat admin yang mencegah kehilangan data, anggap log audit sebagai bagian produk, bukan sekadar afterthought debugging.
Mulai dengan mencatat aksi dengan cara yang mudah dibaca manusia. "User 183 updated record 992" tidak cukup ketika seorang pelanggan marah dan orang on-call mencoba memperbaikinya cepat. Log yang baik menangkap identitas, waktu, cakupan, dan niat, plus detail yang cukup untuk mengembalikan atau setidaknya memahami dampak.
Apa yang direkam (supaya berguna nanti)
Baseline praktis:
- Siapa yang melakukannya (user, peran, dan info impersonasi jika dipakai)
- Apa dan dimana (nama aksi, tenant/akun, dan tipe objek yang terdampak)
- Kapan dan dari mana (timestamp, zona waktu, IP atau ID session/device)
- Apa yang berubah (before/after untuk field kunci, atau diff untuk objek besar)
- Kenapa itu terjadi (alasan teks bebas dan ID tiket/referensi opsional)
Aksi massal pantas mendapat perlakuan khusus. Catat mereka sebagai satu “job” dengan ringkasan jelas (berapa yang dipilih, berapa yang sukses, berapa yang gagal), dan juga simpan hasil per-item. Ini memudahkan menjawab, “Apakah kita mengembalikan 200 order atau hanya 173?” tanpa menggali tumpukan log.
Buat log mudah dicari: berdasarkan admin user, tenant, tipe aksi, dan rentang waktu. Sertakan filter untuk “hanya job massal” dan “aksi berisiko tinggi” agar reviewer bisa melihat pola.
Jangan paksa birokrasi. Kolom "alasan" singkat yang mendukung template ("Permintaan pelanggan untuk penutupan", "Investigasi kecurangan") lebih sering diisi daripada form panjang. Jika ada tiket support, biarkan orang menempelkan ID-nya.
Akhirnya, rencanakan akses baca. Banyak pengguna internal perlu melihat log, tapi hanya kelompok kecil yang harus melihat field sensitif (seperti nilai before/after penuh). Pisahkan "bisa melihat ringkasan audit" dari "bisa melihat detail" untuk mengurangi eksposur.
Batas berbasis peran dan guardrail
Sebagian besar kecelakaan terjadi karena izin terlalu luas. Jika semua orang pada dasarnya admin, operator yang lelah bisa menyebabkan kerusakan permanen dengan satu klik. Tujuannya sederhana: jadikan jalur yang aman sebagai default, dan buat aksi berisiko membutuhkan niat ekstra.
Rancang peran berdasarkan pekerjaan nyata, bukan jabatan. Agen support yang menjawab tiket tidak perlu akses yang sama dengan orang yang mengelola aturan billing.
Bangun peran di sekitar tugas
Mulai dengan memisahkan apa yang orang lihat dari apa yang bisa mereka ubah. Set praktis peran internal yang praktis bisa seperti:
- Read-only: lihat pengguna, pesanan, dan log
- Operator: edit profil dan reset kata sandi
- Billing operator: keluarkan refund dalam batas cap
- Data steward: gabung record dan jalankan perbaikan massal
- Security admin: nonaktifkan akun dan kelola peran
Ini menjaga "hapus" keluar dari pekerjaan sehari-hari dan mengurangi radius ledakan saat seseorang berbuat salah.
Untuk aksi paling berbahaya, tambahkan mode elevated. Pikirkan seperti kunci waktu-terbatas. Untuk masuk mode elevated, minta langkah lebih kuat (re-auth, persetujuan manager, atau orang kedua) dan otomatis keluar setelah 10–30 menit.
Guardrail lingkungan juga menyelamatkan tim. UI harus membuat sulit membingungkan staging dengan produksi. Gunakan tanda visual mencolok, tunjukkan nama environment di setiap header, dan nonaktifkan aksi destruktif di non-produksi kecuali Anda mengaktifkannya secara eksplisit.
Akhirnya, lindungi tenant satu sama lain. Di sistem multi-tenant, perubahan lintas-tenant diblokir secara default dan hanya diaktifkan untuk peran spesifik dengan switch tenant eksplisit dan konfirmasi jelas di layar.
Jika Anda membangun di platform seperti Koder.ai, anggap guardrail ini sebagai fitur produk, bukan pikiran belakangan. Alat admin yang mencegah kehilangan data seringkali hanyalah desain izin yang baik plus beberapa speed bump yang ditempatkan dengan baik.
Skenario realistis: refund massal dan penutupan akun
Buat penghapusan dapat dibalik
Implementasikan soft delete dan restore dengan jendela retensi yang jelas untuk operasi yang lebih aman.
Seorang agen support perlu menangani gangguan pembayaran. Rencananya sederhana: refund order yang terdampak, lalu tutup akun yang meminta pembatalan. Di sinilah alat admin yang mencegah kehilangan data benar-benar berguna, karena agen akan menjalankan dua aksi massal berdampak besar berturut-turut.
Risiko muncul dalam satu detail kecil: filter. Agen memilih “Orders dibuat 24 jam terakhir” bukannya “Orders yang dibayar selama jendela outage.” Di hari sibuk, itu bisa menarik ribuan pelanggan normal, memicu refund yang tidak mereka minta. Jika langkah berikutnya adalah “Tutup akun untuk order yang direfund,” kerusakan menyebar cepat.
Sebelum alat mengeksekusi apa pun, UI harus memaksa jeda dengan preview yang jelas dan cocok dengan bagaimana orang berpikir, bukan bagaimana database berpikir. Misalnya, harus menampilkan:
- Total akun yang akan ditutup (dan berapa yang sudah ditutup)
- Total jumlah refund, plus ukuran refund min/maks
- Sampel kecil yang bisa di-scroll dari pelanggan terdampak (nama, email, ID order)
- Pengecualian dan skip (pembayaran gagal, sudah direfund, order yang diperdebatkan)
- Ringkasan filter tepat dalam bahasa biasa, dengan tombol "Edit filter" yang jelas
Kemudian tambahkan konfirmasi kedua, terpisah, untuk penutupan akun—karena itu jenis kerugian berbeda. Pola bagus adalah meminta mengetik frasa singkat seperti "TUTUP 127 AKUN" supaya agen menyadari jika angkanya salah.
Jika “tutup akun” adalah soft delete, pemulihan realistis. Anda bisa merestore akun, tetap memblokir login, dan menetapkan aturan retensi (mis. auto-purge setelah 30 hari) sehingga tidak menjadi sampah permanen.
Log audit adalah yang membuat pembersihan dan investigasi mungkin nanti. Manager harus melihat siapa yang menjalankan, filter tepat, preview totals yang ditampilkan saat itu, dan daftar record yang terdampak. Batas peran juga penting: agen bisa memberi refund sampai cap harian, tapi hanya manager yang bisa menutup akun, atau menyetujui penutupan di atas ambang tertentu.
Jika Anda membangun konsol semacam ini di Koder.ai, fitur seperti snapshot dan rollback berguna sebagai guardrail tambahan, tapi garis pertahanan pertama tetap preview, konfirmasi, dan peran.
Langkah demi langkah: retrofit keamanan ke admin yang sudah ada
Retrofitting keamanan bekerja terbaik bila Anda memperlakukan admin seperti produk, bukan kumpulan halaman internal. Pilih satu workflow berisiko tinggi dulu (mis. nonaktifkan pengguna massal), lalu bergerak langkah demi langkah.
Rencana retrofit praktis
Mulai dengan membuat daftar layar dan endpoint yang bisa menghapus, menimpa, atau memicu perpindahan uang. Sertakan risiko "tersembunyi" seperti impor CSV, edit massal, dan skrip yang dijalankan operator dari UI.
Lalu buat aksi massal lebih aman dengan memaksa cakupan dan preview. Tunjukkan persis record mana yang cocok filter, berapa banyak yang akan berubah, dan sampel ID sebelum aksi dijalankan.
Selanjutnya, ganti hard delete dengan soft delete bila memungkinkan. Simpan flag deleted, siapa yang melakukannya, dan kapan. Tambahkan jalur restore yang sama mudahnya dengan delete, plus aturan retensi yang jelas (mis. "dapat dipulihkan selama 30 hari").
Setelah itu, tambahkan log audit dan duduk bersama operator untuk meninjau entri nyata. Jika satu baris log tidak bisa menjawab "apa yang berubah, dari apa ke apa, dan kenapa", itu tidak akan membantu saat insiden.
Terakhir, perketat peran dan tambahkan persetujuan untuk aksi berdampak tinggi. Misalnya, izinkan support mengeluarkan refund sampai batas kecil, tapi minta orang kedua untuk jumlah besar atau untuk penutupan akun. Begitulah alat admin yang mencegah kehilangan data tetap bisa digunakan tanpa menakut-nakuti.
Contoh cepat
Seorang operator perlu menutup 200 akun tidak aktif. Sebelum perubahan, mereka klik "Delete" dan berharap filter benar. Setelah retrofit, mereka harus mengonfirmasi query tepat ("status=inactive, last_login\u003e365d"), meninjau hitungan dan daftar sampel, memilih "Close (restorable)" daripada delete, dan memasukkan alasan.
Standar "done" yang baik adalah:
- Anda bisa mempreview dan mengekspor set yang terdampak sebelum mengeksekusi.
- Anda bisa meng-undo (restore atau rollback) dalam jendela yang ditentukan.
- Setiap aksi dapat ditelusuri ke orang dan alasan.
- Aksi berdampak tinggi dibatasi oleh peran atau memerlukan persetujuan.
Jika Anda membangun tooling internal di platform chat-driven seperti Koder.ai, tambahkan guardrail ini sebagai komponen yang dapat digunakan ulang sehingga halaman admin baru mewarisi default yang lebih aman.
Kesalahan umum yang masih menyebabkan kecelakaan
Kunci izin
Definisikan akses berbasis tugas sehingga aksi berisiko membutuhkan niat yang lebih kuat dan ruang lingkup yang lebih ketat.
Banyak tim merancang alat admin yang mencegah kehilangan data secara teori, lalu kehilangan data dalam praktik karena fitur keselamatan mudah diabaikan atau sulit dipakai.
Perangkap paling umum adalah konfirmasi satu-ukuran-untuk-semua. Jika setiap aksi menampilkan pesan "Apa Anda yakin?" yang sama, orang berhenti membacanya. Lebih buruk lagi, tim sering menambahkan lebih banyak konfirmasi untuk "memperbaiki" kesalahan, yang melatih operator mengklik lebih cepat.
Masalah lain adalah konteks yang hilang pada saat yang penting. Aksi destruktif harus jelas menunjukkan tenant atau workspace yang sedang aktif, apakah ini produksi atau tes, dan berapa banyak record yang akan tersentuh. Ketika informasi itu terkubur di layar lain, alat diam-diam meminta hari yang buruk.
Aksi massal juga berbahaya ketika berjalan instan tanpa pelacakan. Operator perlu catatan job yang jelas: apa yang dijalankan, filter apa yang dipakai, siapa memulainya, dan apa yang sistem lakukan saat menemui error. Tanpa itu, Anda tidak bisa menjeda, membatalkan, atau bahkan menjelaskan apa yang terjadi.
Berikut kesalahan yang sering muncul berulang:
- Menggunakan teks konfirmasi yang sama untuk delete, refund, dan perubahan izin
- Menambahkan konfirmasi terlalu sering sehingga orang klik lewat secara otomatis
- Tidak menampilkan hitungan record, tenant, dan environment di layar konfirmasi
- Menjalankan aksi massal segera tanpa preview, tanpa halaman job, dan tanpa cara menghentikan
- Menyimpan log audit, tetapi tidak membuatnya dapat dicari berdasarkan user, record, atau waktu
Contoh cepat: operator bermaksud menonaktifkan 12 akun di tenant sandbox, tetapi alat default ke tenant yang terakhir dipakai dan menyembunyikannya di header. Mereka menjalankan aksi massal, itu dieksekusi langsung, dan satu-satunya "log" adalah entri samar seperti "bulk update completed." Saat orang menyadari, Anda tidak bisa dengan mudah tahu apa yang berubah atau mengembalikannya.
Keamanan yang baik bukan popup lebih banyak. Itu konteks yang jelas, konfirmasi bermakna, dan aksi yang bisa Anda lacak serta balikkan.
Daftar periksa cepat dan langkah selanjutnya
Sebelum Anda merilis aksi destruktif, lakukan satu pemeriksaan lagi dengan mata segar. Sebagian besar insiden admin terjadi saat alat membiarkan seseorang bertindak pada cakupan yang salah, menyembunyikan dampak nyata, atau tidak menawarkan jalan kembali.
Berikut daftar periksa pra-penerbangan singkat untuk alat admin yang mencegah kehilangan data:
- Scope + preview: tampilkan persis apa yang akan berubah (siapa, apa, di mana). Sertakan preview yang terbaca dan sampel record.
- Hitungan + batas: tampilkan jumlah total item dan terapkan batas wajar (dan rate limit) sehingga satu klik tidak bisa menyentuh "semuanya."
- Pemeriksaan konteks: minta operator mengonfirmasi tenant/akun, environment (prod vs test), dan tambahkan alasan singkat yang akan muncul di log.
- Jalur pemulihan: utamakan soft delete bila memungkinkan, pastikan alur restore berfungsi, dan tetapkan retensi (berapa lama pemulihan mungkin).
- Akuntabilitas: catat siapa melakukan apa, kapan, dari mana, dan dengan filter apa. Buat log dapat dicari, dan pastikan peran sesuai tanggung jawab nyata.
Jika Anda operator, jeda sepuluh detik dan baca kembali alatnya sendiri: "Saya bertindak pada tenant X, mengubah N record, di produksi, untuk alasan Y." Jika ada bagian yang tidak jelas, hentikan dan minta UI yang lebih aman sebelum menjalankan aksi.
Langkah selanjutnya: prototipe alur yang lebih aman dengan cepat di Koder.ai menggunakan Planning Mode untuk membuat sketsa layar dan guardrail terlebih dahulu. Saat pengujian, gunakan snapshot dan rollback sehingga Anda bisa mencoba kasus tepi dunia nyata tanpa takut. Setelah alur terasa solid, ekspor kode sumber dan deploy saat Anda siap.