22 de ago. de 2025·8 min
Transações Postgres para fluxos multietapa: padrões práticos
Aprenda transações Postgres para fluxos multietapa: como agrupar atualizações com segurança, evitar gravações parciais, tratar retries e manter os dados consistentes.
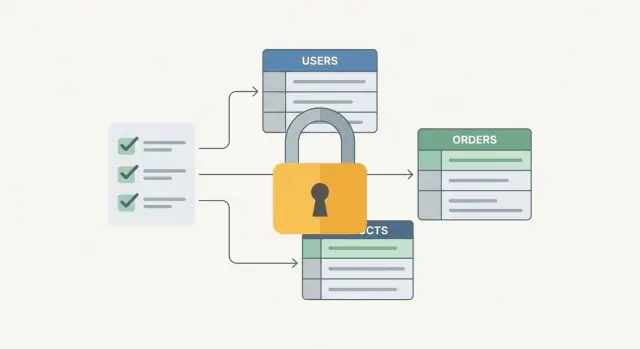
Por que atualizações multietapa acabam inconsistentes\n\nA maioria das funcionalidades reais não é uma única atualização no banco de dados. É uma pequena cadeia: inserir uma linha, atualizar um saldo, marcar um status, gravar um registro de auditoria, talvez enfileirar um job. Uma gravação parcial acontece quando apenas alguns desses passos chegam ao banco.\n\nIsso aparece quando algo interrompe a cadeia: um erro no servidor, um timeout entre sua aplicação e o Postgres, uma queda depois do passo 2, ou um retry que reexecuta o passo 1. Cada instrução está ok por si só. O fluxo quebra quando para no meio.\n\nNormalmente dá para identificar rápido:\n\n- Uma linha existe, mas uma linha relacionada está faltando (pedido criado, sem itens)\n- Dinheiro movimentado, mas o status não mudou (pago, ainda marcado como não pago)\n- Dois registros que deveriam ser um (assinaturas duplicadas após um retry)\n- Flags que discordam (usuário "ativo" mas sem plano)\n- Estados que aparecem só sob carga ou falhas\n\nUm exemplo concreto: um upgrade de plano atualiza o plano do cliente, adiciona um registro de pagamento e aumenta créditos disponíveis. Se a aplicação cair depois de salvar o pagamento, mas antes de adicionar os créditos, o suporte vê "pago" em uma tabela e "sem créditos" em outra. Se o cliente reenviar, você pode até registrar o pagamento duas vezes.\n\nO objetivo é simples: trate o fluxo como um único interruptor. Ou todo passo tem sucesso, ou nenhum tem, para nunca armazenar trabalho meio feito.\n\n## Transações, em termos simples\n\nUma transação é a maneira do banco dizer: trate esses passos como uma unidade de trabalho. Ou toda alteração acontece, ou nada acontece. Isso importa sempre que seu fluxo precisa de mais de uma atualização, como criar uma linha, atualizar um saldo e gravar um registro de auditoria.\n\nPense em transferir dinheiro entre duas contas. Você precisa debitar a Conta A e creditar a Conta B. Se a app cair depois do primeiro passo, você não quer que o sistema "lembre" apenas do débito.\n\n### Commit vs rollback\n\nQuando você , diz ao Postgres: mantenha tudo o que eu fiz nesta transação. Todas as alterações ficam permanentes e visíveis para outras sessões.\n\nQuando você , diz ao Postgres: esqueça tudo o que eu fiz nesta transação. O Postgres desfaz as alterações como se a transação nunca tivesse acontecido.\n\n### O que o Postgres garante (e o que não garante)\n\nDentro de uma transação, o Postgres garante que você não vai expor resultados pela metade para outras sessões antes do commit. Se algo falhar e você fizer rollback, o banco limpa as escritas daquela transação.\n\nUma transação não corrige um desenho ruim do fluxo. Se você debitar o valor errado, usar o ID de usuário errado ou pular uma checagem necessária, o Postgres vai dar commit fielmente do resultado errado. Transações também não evitam automaticamente todos os conflitos de negócio (como vender estoque em excesso) a menos que você use constraints, locks ou o nível de isolamento corretos.\n\n## Fluxos que devem ser agrupados\n\nSempre que você atualiza mais de uma tabela (ou mais de uma linha) para completar uma única ação do mundo real, tem um candidato a transação. O ponto permanece: ou tudo é feito, ou nada é.\n\nUm fluxo de pedido é o caso clássico. Você pode criar a linha do pedido, reservar inventário, cobrar o pagamento e então marcar o pedido como pago. Se o pagamento ocorre mas a atualização do status falha, você tem dinheiro capturado com um pedido que ainda parece não pago. Se a linha do pedido é criada mas o estoque não é reservado, você pode vender itens que na verdade não tem.\n\nO onboarding do usuário falha silenciosamente da mesma forma. Criar o usuário, inserir um registro de perfil, atribuir papéis e registrar que um email de boas-vindas deve ser enviado são uma ação lógica. Sem agrupamento você pode acabar com um usuário que consegue entrar mas não tem permissões, ou um perfil que existe sem usuário.\n\nAções de back-office frequentemente precisam de comportamento estrito de "trilha + mudança de estado". Aprovar um pedido, escrever um registro de auditoria e atualizar um saldo devem ocorrer juntos. Se o saldo muda mas o log de auditoria sumiu, você perde evidência de quem mudou o quê e por quê.\n\nJobs em background também se beneficiam, especialmente quando você processa um item de trabalho com múltiplos passos: claim do item para que dois workers não o processem, aplicar a atualização de negócio, gravar um resultado para relatórios e retries, e então marcar o item como feito (ou falhado com motivo). Se esses passos se separarem, retries e concorrência viram bagunça.\n\n## Projete o fluxo antes de escrever SQL\n\nFuncionalidades multietapa quebram quando você as trata como um monte de atualizações independentes. Antes de abrir um cliente de banco, escreva o fluxo como uma história curta com uma linha de chegada clara: o que exatamente conta como "feito" para o usuário?\n\nComece listando os passos em linguagem simples, depois defina uma condição única de sucesso. Por exemplo: "Pedido criado, estoque reservado e o usuário vê um número de confirmação do pedido." Qualquer coisa abaixo disso não é sucesso, mesmo que algumas tabelas tenham sido atualizadas.\n\nEm seguida, trace uma linha rígida entre trabalho de banco e trabalho externo. Passos de banco são os que você pode proteger com transações. Chamadas externas como pagamentos com cartão, envio de emails ou APIs de terceiros podem falhar de formas lentas e imprevisíveis, e normalmente você não pode revertê-las.\n\nUma abordagem simples de planejamento: separe passos em (1) precisa ser tudo-ou-nada, (2) pode acontecer depois do commit.\n\n### Decida o que pertence dentro da transação\n\nDentro da transação, mantenha apenas os passos que devem permanecer consistentes juntos:\n\n- Criar ou atualizar linhas centrais (pedido, fatura, saldo da conta)\n- Reservar recursos compartilhados (estoque, assentos, cota)\n- Registrar um evento durável de "o que fazer a seguir" (tabela outbox)\n- Aplicar regras com constraints (chaves únicas, foreign keys)\n\nMova efeitos colaterais para fora. Por exemplo, faça commit do pedido primeiro e então envie o email de confirmação com base em um registro de outbox.\n\n### Escreva expectativas de rollback por passo\n\nPara cada passo, escreva o que deve acontecer se o próximo passo falhar. "Rollback" pode significar rollback de banco, ou uma ação compensatória.\n\nExemplo: se o pagamento suceder mas a reserva de estoque falhar, decida de antemão se você reembolsa imediatamente, ou marca o pedido como "pagamento capturado, aguardando estoque" e resolve isso assincronamente.\n\n## Passo a passo: envolver um fluxo em uma transação\n\nUma transação diz ao Postgres: trate esses passos como uma unidade. Ou todos acontecem, ou nenhum acontece. Essa é a forma mais simples de evitar gravações parciais.\n\n### O fluxo básico\n\nUse uma conexão de banco (uma sessão) do começo ao fim. Se você espalhar passos por conexões diferentes, o Postgres não pode garantir o resultado tudo-ou-nada.\n\nA sequência é direta: begin, execute as leituras e gravações necessárias, commit se tudo der certo, caso contrário rollback e retorne um erro claro.\n\nAqui está um exemplo mínimo em SQL:\n\n\n\n### Mantenha curto (e passível de depuração)\n\nTransações seguram locks enquanto rodam. Quanto mais tempo abertas, mais você bloqueia outros trabalhos e maior a chance de timeouts ou deadlocks. Faça o essencial dentro da transação e mova tarefas lentas (enviar emails, chamar provedores de pagamento, gerar PDFs) para fora.\n\nQuando algo falha, registre contexto suficiente para reproduzir o problema sem vazar dados sensíveis: nome do fluxo, order_id ou user_id, parâmetros chaves (valor, moeda) e o código de erro do Postgres. Evite logar payloads completos, dados de cartão ou informações pessoais.\n\n## Noções básicas de concorrência: locks e isolamento sem jargão\n\nConcorrência é só duas coisas acontecendo ao mesmo tempo. Imagine dois clientes tentando comprar o último ingresso. Ambas telas mostram "1 restante", ambos clicam em Pagar, e agora sua app tem que decidir quem fica com ele.\n\nSem proteção, ambos requests podem ler o mesmo valor antigo e ambos escrever uma atualização. É assim que você acaba com estoque negativo, reservas duplicadas ou um pagamento sem pedido.\n\nLocks em linha são a proteção mais simples. Você bloqueia a linha específica que vai mudar, faz suas checagens e então atualiza. Outras transações que tocam a mesma linha precisam esperar até você commitar ou dar rollback, o que evita duplicações.\n\nUm padrão comum: iniciar a transação, selecionar a linha de inventário com , verificar se há estoque, decrementar e então inserir o pedido. Isso "segura a porta" enquanto você termina os passos críticos.\n\nNíveis de isolamento controlam o quanto de comportamento estranho você permite de transações concorrentes. O trade-off é geralmente segurança vs velocidade:\n\n- Read Committed (padrão): rápido, mas você pode ver mudanças cometidas por outros entre declarações.\n- Repeatable Read: sua transação vê um snapshot estável, bom para leituras consistentes, pode causar mais retries.\n- Serializable: segurança máxima, o Postgres pode abortar uma transação para manter resultados como se tivessem rodado uma a uma.\n\nMantenha locks curtos. Se uma transação ficar aberta enquanto você chama uma API externa ou espera ação do usuário, você vai criar esperas longas e timeouts. Prefira um caminho de falha claro: defina um lock timeout, capture o erro e retorne "por favor, tente novamente" em vez de deixar requests pendurados.\n\nSe você precisa fazer trabalho fora do banco (como cobrar um cartão), divida o fluxo: reserve rápido, commit, depois faça a parte lenta e finalize com outra transação curta.\n\n## Retries que não criam duplicatas\n\nRetries são normais em apps que usam Postgres. Um request pode falhar mesmo quando seu código está correto: deadlocks, statement timeouts, quedas de rede breves ou erro de serialização sob níveis de isolamento mais altos. Se você simplesmente reexecutar o mesmo handler, corre o risco de criar um segundo pedido, cobrar duas vezes ou inserir linhas de "evento" duplicadas.\n\nA solução é idempotência: a operação deve ser segura para rodar duas vezes com a mesma entrada. O banco deve conseguir reconhecer "isso é o mesmo request" e responder de forma consistente.\n\nUm padrão prático é anexar uma chave de idempotência (frequentemente um request_id gerado pelo cliente) a cada fluxo multietapa e armazená-la no registro principal, então adicionar uma constraint única nessa chave.\n\nPor exemplo: no checkout, gere request_id quando o usuário clicar em Pagar, então insira o pedido com esse request_id. Se houver um retry, a segunda tentativa esbarra na constraint única e você retorna o pedido existente em vez de criar outro.\n\nO que geralmente importa:\n\n- Use uma constraint única em (request_id) ou (user_id, request_id) para bloquear duplicatas.\n- Quando a constraint for violada, busque a linha existente e retorne o mesmo resultado.\n- Faça efeitos colaterais seguirem a mesma regra: apenas uma payment intent por pedido, apenas um evento "pedido confirmado" por pedido.\n- Logue o request_id para que o suporte consiga rastrear o que aconteceu.\n\nMantenha o loop de retry fora da transação. Cada tentativa deve começar uma nova transação e reexecutar a unidade de trabalho do topo. Repetir dentro de uma transação abortada não ajuda porque o Postgres marca a transação como abortada.\n\nUm pequeno exemplo: sua app tenta criar um pedido e reservar estoque, mas dá timeout logo após o COMMIT. O cliente reenvia. Com uma chave de idempotência, a segunda requisição retorna o pedido já criado e pula a segunda reserva em vez de duplicar o trabalho.\n\n## Use o banco para aplicar regras, não só seu código\n\nTransações mantêm um fluxo multietapa junto, mas não fazem os dados estarem corretos automaticamente. Uma forma forte de evitar estados parcialmente gravados é tornar estados "errados" difíceis ou impossíveis no banco, mesmo se um bug passar no código da aplicação.\n\nComece com trilhos básicos de segurança. Foreign keys garantem que referências são reais (uma linha de item não pode apontar para um pedido inexistente). NOT NULL evita linhas pela metade. CHECK constraints detectam valores sem sentido (por exemplo, quantity > 0, total_cents >= 0). Essas regras rodam em toda escrita, não importa qual serviço ou script mexa no banco.\n\nPara fluxos mais longos, modele mudanças de estado explicitamente. Em vez de muitas flags booleanas, use uma coluna de status única (pending, paid, shipped, canceled) e permita só transições válidas. Você pode aplicar isso com constraints ou triggers para que o banco recuse saltos ilegais como shipped -> pending.\n\nUnicidade é outra forma de correção. Adicione constraints únicas onde duplicatas quebrariam seu fluxo: order_number, invoice_number ou uma idempotency_key usada para retries. Aí, se sua app reenviar o mesmo request, o Postgres vai bloquear a segunda inserção e você pode retornar "já processado" em vez de criar outro pedido.\n\nQuando precisar de rastreabilidade, armazene isso explicitamente. Uma tabela de auditoria (ou history) que registra quem mudou o quê e quando transforma "updates misteriosos" em fatos que você pode consultar durante incidentes.\n\n## Erros comuns que causam gravações parciais\n\nA maioria das gravações parciais não vem de "SQL ruim." Vem de decisões de fluxo que facilitam o commit de apenas metade da história.\n\n### As armadilhas que aparecem em apps reais\n\n- Chamar um provedor de pagamento, enviar email ou fazer upload dentro da transação segura locks por mais tempo que o necessário. Se a API estiver lenta ou der timeout, outros usuários ficam na fila atrás da sua transação aberta.\n- Exemplo: você busca o saldo do usuário, mostra na tela e depois debita com base naquele valor antigo. Outra sessão pode ter alterado o saldo nesse meio tempo.\n- Um padrão comum é "tentar passo 1, tentar passo 2, logar o erro, retornar sucesso mesmo assim." Se o código chegar ao COMMIT após uma falha, você acabou de deixar o banco inconsistente de propósito.\n- Se um request atualiza depois , mas outro faz depois , você aumenta a chance de deadlocks sob carga.\n- Transações longas podem bloquear escritas, atrasar limpeza do vacuum e criar timeouts confusos.\n\nUm exemplo concreto: no checkout, você reserva estoque, cria um pedido e então cobra o cartão. Se você cobrar dentro da mesma transação, pode segurar um lock de inventário enquanto espera a rede. Se a cobrança tiver sucesso mas sua transação depois der rollback, você cobrou o cliente sem criar um pedido.\n\nUm padrão mais seguro é: mantenha a transação focada no estado do banco (reservar estoque, criar pedido, registrar pagamento pendente), commit, depois chame a API externa, e então grave o resultado em uma nova transação curta. Muitas equipes implementam isso com um status pendente e um job em background.\n\n## Checklist rápido para operações tudo-ou-nada\n\nQuando um fluxo tem múltiplos passos (inserir, atualizar, cobrar, enviar), o objetivo é simples: ou tudo é registrado, ou nada é.\n\n### Limites de transação\n\nMantenha todas as escritas de banco necessárias dentro de uma transação. Se um passo falhar, faça rollback e deixe os dados exatamente como estavam.\n\nTorne a condição de sucesso explícita. Por exemplo: "Pedido criado, estoque reservado e status de pagamento registrado." Qualquer outra coisa é caminho de falha que deve abortar a transação.\n\n- Todas as escritas necessárias acontecem dentro de um único bloco .\n- Existe um estado final claro no banco (não só na memória da app).\n- Qualquer erro leva a e o chamador recebe um resultado de falha claro.\n\n### Trilhos de segurança (para que retries não prejudiquem)\n\nPressuponha que o mesmo request pode ser reenviado. O banco deve ajudar a aplicar regras de apenas-uma-vez.\n\n- Proteja ações únicas com constraints únicas (uma linha de pagamento por pedido, ou uma reserva por item por pedido).\n- Faça retries seguros e repetíveis (mesma entrada produz o mesmo estado final, sem duplicatas).\n\n### Mantenha transações curtas\n\nFaça o mínimo necessário dentro da transação e evite esperar por chamadas de rede enquanto segura locks.\n\n- Mantenha transações curtas e defina timeout para que não fiquem penduradas.\n- Faça trabalho lento (como chamar um provedor de pagamento) fora da transação e depois registre o resultado em uma nova transação curta.\n\n### Observe falhas\n\nSe você não consegue ver onde quebra, vai continuar chutando.\n\n- Registre o passo do fluxo e um request id para cada falha.\n- Monitore taxas de rollback e timeouts de lock para detectar riscos de gravação parcial cedo.\n\n## Exemplo: um fluxo de checkout que se mantém consistente sob falhas\n\nUm checkout tem vários passos que devem avançar juntos: criar o pedido, reservar estoque, registrar a tentativa de pagamento e então marcar o status do pedido.\n\nImagine um usuário clica em Comprar para 1 item.\n\n### Um fluxo seguro (trabalho DB como uma unidade)\n\nDentro de uma transação, faça apenas mudanças no banco:\n\n- Insira uma linha em com status .\n- Reserve estoque (por exemplo, decremente ou crie uma linha em ).\n- Insira uma linha em com um fornecido pelo cliente (único).\n- Insira uma linha em como "order_created".\n\nSe qualquer instrução falhar (sem estoque, erro de constraint, queda), o Postgres faz rollback de toda a transação. Você não fica com um pedido sem reserva, ou uma reserva sem pedido.\n\n### E se o pagamento falhar no meio do caminho?\n\nO provedor de pagamento está fora do seu banco, então trate como passo separado.\n\nSe a chamada ao provedor falhar antes do commit, aborte a transação e nada é gravado. Se a chamada falhar depois do commit, rode uma nova transação que marca a tentativa de pagamento como falhada, libera a reserva e define o status do pedido como cancelado.\n\n### Retry sem criar um segundo pedido\n\nPeça ao cliente para enviar um por tentativa de checkout. Enforce isso com um índice único em (ou em , se preferir). No retry, seu código busca as linhas existentes e continua em vez de inserir um novo pedido.\n\n### Emails e notificações\n\nNão envie emails dentro da transação. Grave um registro de outbox na mesma transação e deixe um worker em background enviar o email após o commit. Assim você nunca envia email por um pedido que foi rollbackado.\n\n## Próximos passos: aplique isso a um fluxo esta semana\n\nEscolha um fluxo que toque mais de uma tabela: cadastro + enfileiramento de email de boas-vindas, checkout + inventário, fatura + lançamento no razão, ou criar projeto + configurações padrão.\n\nEscreva os passos primeiro, depois as regras que devem ser sempre verdade (seus invariantes). Exemplo: "Um pedido ou está totalmente pago e reservado, ou não está pago e não está reservado. Nunca meio-reservado." Transforme essas regras em uma unidade tudo-ou-nada.\n\nUm plano simples:\n\n- Liste as operações SQL exatas na ordem (leitura, inserts, updates, deletes).\n- Adicione as constraints de banco que faltam primeiro (chaves únicas, foreign keys, check constraints).\n- Acrescente uma chave de idempotência para a requisição para que retries não criem duplicatas.\n- Envolva os passos em uma transação e torne o ponto de sucesso explícito (commit apenas quando todas as checagens passarem).\n- Decida como é um retry seguro (mesma idempotency key, mesmo resultado).\n\nDepois teste os casos feios de propósito. Simule uma queda depois do passo 2, um timeout bem antes do commit e um duplo envio da UI. O objetivo é resultados sem surpresas: sem linhas órfãs, sem cobranças duplas, sem pendências eternas.\n\nSe você está prototipando rápido, ajuda esboçar o fluxo em uma ferramenta de planejamento antes de gerar handlers e esquema. Por exemplo, Koder.ai tem um Modo de Planejamento e suporta snapshots e rollback, o que pode ser útil enquanto você itera sobre limites de transação e constraints.\n\nFaça isso para um fluxo esta semana. O segundo será muito mais rápido.