18 de ago. de 2025·8 min
Exclusão suave vs exclusão permanente: decisões que importam em apps reais
Exclusão suave vs exclusão permanente: entenda os compromissos reais para análise, suporte, exclusão no estilo GDPR e complexidade de consultas, além de padrões seguros de restauração.
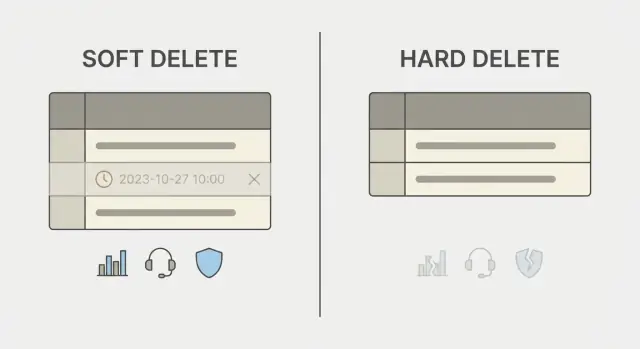
O que exclusões suaves e permanentes realmente significam
Um botão de apagar pode significar duas coisas bem diferentes em um banco de dados.
Uma exclusão permanente remove a linha. Depois disso, o registro some, a não ser que você tenha backups, logs ou réplicas que ainda o contenham. É simples de raciocinar, mas é definitivo.
Uma exclusão suave mantém a linha, mas marca ela como excluída, geralmente com um campo como deleted_at ou is_deleted. A aplicação então trata linhas marcadas como invisíveis. Você preserva dados relacionados, mantém histórico e às vezes pode restaurar o registro.
Essa escolha aparece no dia a dia mais do que as pessoas esperam. Ela afeta como você responde perguntas como: “Por que a receita caiu mês passado?”, “Dá para recuperar meu projeto excluído?” ou “Recebemos uma solicitação de exclusão GDPR — estamos realmente apagando os dados pessoais?” Também molda o que “excluído” significa na interface. Usuários costumam presumir que podem desfazer, até descobrirem que não podem.
Uma regra prática:
- Use soft delete quando os usuários esperam poder desfazer, quando o suporte precisa recuperar erros ou quando você precisa de uma trilha de auditoria.
- Use hard delete quando manter os dados gera risco legal, risco de segurança ou custos claros de armazenamento sem valor real.
- Use ambos quando quiser um período de “lixeira”: soft delete primeiro e depois purga permanente.
Exemplo: um cliente exclui um workspace e depois percebe que havia faturas necessárias para contabilidade. Com soft delete, o suporte pode restaurá‑lo (se sua aplicação foi construída para restaurar com segurança). Com hard delete, você provavelmente terá que explicar backups, atrasos ou “não é possível”.
Nenhuma abordagem é “melhor” em todos os casos. A opção menos dolorosa depende do que você precisa proteger: confiança do usuário, precisão de relatórios ou conformidade com privacidade.
Compromissos em analytics: precisão vs manter histórico
As escolhas de exclusão aparecem rápido em analytics. No dia em que você começa a medir usuários ativos, conversão ou receita, “excluído” deixa de ser um estado simples e vira uma decisão de reporte.
Se você faz hard delete, muitas métricas ficam limpas porque registros removidos desaparecem das consultas. Mas você perde contexto: assinaturas passadas, tamanho anterior do time ou como um funil era no mês passado. Um cliente excluído pode fazer gráficos históricos mudarem quando você reexecuta relatórios, o que assusta finanças e revisão de growth.
Se você faz soft delete, mantém histórico, mas pode inflar números por acidente. Um simples “COUNT users” pode incluir pessoas que saíram. Um gráfico de churn pode contar duas vezes se, em um relatório, você tratar deleted_at como churn e em outro ignorá‑lo. Até receita fica complicada se faturas ficam e a conta é marcada como excluída.
O que costuma funcionar é escolher um padrão de reporte consistente e segui‑lo:
- Filtre registros excluídos em métricas de “estado atual” (usuários ativos, MRR atual).
- Use tabelas de snapshot para dashboards temporais para que o histórico não mude quando entidades são excluídas depois.
- Separe fatos de entidades: mantenha linhas imutáveis de eventos (pagamentos, logins) mesmo que o usuário seja ocultado.
- Trate “excluído” como um estado de ciclo de vida com data própria e reporte explicitamente (criado, ativado, excluído).
- Defina janelas de retenção: quando dados soft-deleted se tornam realmente removidos.
A chave é documentação para que analistas não adivinhem. Escreva o que “ativo” significa, se usuários soft-deleted são incluídos e como a receita é atribuída se uma conta for excluída depois.
Exemplo concreto: um workspace é excluído por engano e depois restaurado. Se seu dashboard conta workspaces sem filtro, você mostrará uma queda e recuperação súbitas que nunca ocorreram no uso real. Com snapshots, o gráfico histórico permanece estável enquanto as vistas do produto podem ocultar workspaces excluídos.
Suporte e trilha de auditoria: o que você pode recuperar depois
A maioria dos chamados de suporte sobre exclusão soa igual: “Apaguei sem querer” ou “Onde foi meu registro?” Sua estratégia de exclusão decide se o suporte consegue responder em minutos ou se a única resposta honesta é “Sumiu”.
Com soft deletes, geralmente você pode verificar o que aconteceu e desfazer. Com hard deletes, o suporte costuma depender de backups (se houver), e isso pode ser lento, incompleto ou impossível para um único item. Por isso a escolha não é só um detalhe de banco de dados — ela molda o quão “útil” seu produto pode ser quando algo dá errado.
Uma trilha de auditoria simples (o que armazenar)
Se você espera suporte real, adicione alguns campos que expliquem eventos de exclusão:
deleted_at(timestamp)deleted_by(id do usuário ou sistema)delete_reason(opcional, texto curto)deleted_from_ipoudeleted_from_device(opcional)restored_aterestored_by(se você suporta restauração)
Mesmo sem um log de atividade completo, esses detalhes permitem que o suporte responda: quem deletou, quando e se foi acidente ou limpeza automatizada.
O que hard deletes significam para o suporte
Hard deletes podem ser adequados para dados temporários, mas para registros voltados ao usuário alteram o que o suporte pode fazer.
O suporte não consegue restaurar um único registro a menos que você tenha uma lixeira em outro lugar. Pode ser necessário restaurar um backup completo, o que afeta outros dados. Também não há como provar facilmente o que aconteceu, o que gera longas trocas de mensagens.
Recursos de restauração mudam a carga de trabalho também. Se usuários podem se auto‑restaurar dentro de um período, os tickets caem. Se a restauração requer ação manual do suporte, os tickets podem aumentar, mas se tornam rápidos e repetíveis em vez de investigações pontuais.
Exclusão estilo GDPR: soft delete não é apagamento completo
O “direito ao esquecimento” geralmente exige que você pare de processar dados pessoais e os remova de lugares onde ainda são utilizáveis. Nem sempre significa apagar todos os agregados históricos imediatamente, mas significa que você não deve manter dados identificáveis “só por precaução” se não houver base legal para isso.
É aí que a escolha soft vs hard passa de decisão de produto para requisito de conformidade. Um soft delete (como definir deleted_at) muitas vezes apenas oculta o registro no app. Os dados ainda estão no banco, acessíveis por admins e frequentemente presentes em exportações, índices de busca e tabelas de analytics. Para muitas solicitações de exclusão GDPR, isso não é eliminação.
Você ainda precisa de uma purga quando:
- Um usuário pede exclusão e você não tem motivo de retenção válido (por exemplo, regras de faturamento).
- Você armazenou dados de categorias especiais e sua política exige remoção.
- O registro aparece em exportações visíveis ao usuário ou pode ser recuperado pelo suporte.
- Um processador terceirizado (email, analytics, ferramentas de suporte) ainda o mantém.
Backups e logs são a parte que equipes esquecem. Você pode não conseguir apagar uma única linha de um backup criptografado, mas pode definir uma regra: backups expiram rapidamente e backups restaurados devem reaplicar eventos de exclusão antes de o sistema voltar ao ar. Logs devem evitar armazenar dados pessoais brutos quando possível e ter limites de retenção claros.
Uma política prática e simples é a exclusão em dois passos:
- Soft delete imediato (para que o produto se comporte corretamente, contas sejam desativadas e “restaurar registros” funcione para erros).
- Iniciar um timer de retenção (por exemplo, 7 a 30 dias) e agendar um job que purgue permanentemente ou anonimiza campos pessoais.
- Registrar o que aconteceu em uma trilha de auditoria usando marcadores não identificáveis (timestamps, códigos de motivo) para que o suporte possa explicar ações sem manter os dados.
Se sua plataforma suporta exportação de código-fonte ou exportação de dados, trate arquivos exportados como repositórios de dados também: defina onde ficam, quem pode acessar e quando são excluídos.
Complexidade de consultas e comportamento do produto: o custo oculto
Teste casos de borda de exclusão
Teste janelas de desfazer e colisões de campos únicos antes de fixar o esquema.
Soft deletes parece simples: adicione deleted_at (ou is_deleted) e oculte a linha. O custo oculto é que todo lugar que lê dados agora precisa lembrar desse flag. Ignore‑o uma vez e você terá bugs estranhos: totais incluindo itens excluídos, buscas mostrando resultados “fantasmas” ou um usuário vendo algo que achava ter sido removido.
Casos de canto na UI/UX aparecem rápido. Imagine que um time exclui um projeto chamado “Roadmap” e depois tenta criar outro “Roadmap”. Se o banco tem uma restrição única no nome, a criação pode falhar porque a linha excluída ainda existe. A pesquisa também pode confundir pessoas: se você oculta itens excluídos em listas mas não na busca global, usuários pensarão que o app está quebrado.
Filtros de soft delete costumam faltar em:
- Dashboards administrativos e ferramentas de suporte
- Jobs em background (emails, lembretes, limpezas)
- Consultas e exportações de analytics
- Checagens de permissão (“esse registro existe?”)
- Autocomplete e busca
Performance geralmente vai bem no começo, mas a condição extra adiciona trabalho. Se a maioria das linhas está ativa, filtrar deleted_at IS NULL é barato. Se muitas linhas estão excluídas, o banco precisa pular mais registros a menos que você adicione o índice certo. Em termos simples: é como procurar documentos atuais em uma gaveta que também contém muitos antigos.
Uma área separada de “Arquivo” pode reduzir confusão. Faça a vista padrão mostrar apenas registros ativos, e coloque itens excluídos em um lugar com rótulos claros e janela de tempo. Em ferramentas construídas rapidamente (por exemplo, apps internos feitos no Koder.ai), essa decisão de produto costuma prevenir mais tickets de suporte do que qualquer truque de consulta.
Modelos de dados comuns para soft delete
Soft delete não é uma única funcionalidade. É uma escolha de modelo de dados, e o modelo que você escolher vai moldar tudo que vem depois: regras de consulta, comportamento de restauração e o que “excluído” significa para o produto.
Modelo 1: deleted_at mais deleted_by
O padrão mais comum é um timestamp anulável. Quando um registro é excluído, define‑se deleted_at (e frequentemente deleted_by com o id do usuário). Registros “ativos” são aqueles onde deleted_at é null.
Isso funciona bem quando você precisa de uma restauração limpa: restaurar é simplesmente limpar deleted_at e deleted_by. Também dá ao suporte um sinal de auditoria simples.
Modelo 2: estados explícitos
Em vez de um timestamp, algumas equipes usam um campo status com estados claros como active, archived e deleted. Isso é útil quando “arquivado” é um estado real do produto (oculto da maioria das telas, mas ainda contado na cobrança, por exemplo).
O custo são regras. Você precisa definir o que cada estado significa em todo lugar: busca, notificações, exportações e analytics.
Modelo 3: armazenamento separado para registros de alto valor
Para objetos sensíveis ou de alto valor, você pode mover linhas excluídas para uma tabela separada ou registrar um evento em um log append-only.
- Soft delete por timestamp:
deleted_at,deleted_by - Máquina de estados:
statuscom estados nomeados - Tabela separada para excluídos: a tabela “ativa” fica pequena
- Log de eventos: mantenha “quem fez o quê” sem manter linhas completas para sempre
Isso é usado quando restaurações precisam ser controladas, ou quando você quer uma trilha de auditoria sem misturar dados excluídos nas consultas do dia a dia.
Registros filhos também precisam de regra intencional. Se um workspace é excluído, o que acontece com projetos, arquivos e memberships?
- Cascade: marcar filhos como excluídos também
- Restrict: bloquear exclusão até que filhos sejam tratados
- Archive: converter filhos para
archived(não deletado) - Detach: remover relacionamentos mas manter o filho
Escolha uma regra por relacionamento, documente e mantenha consistente. A maior parte dos bugs de “restauração deu errado” vem de pais e filhos usando significados diferentes para "excluído".
Como implementar um recurso de restauração seguro (passo a passo)
Um botão de restauração parece simples, mas pode quebrar permissões, ressuscitar dados antigos no lugar errado ou confundir usuários se “restaurado” não significar o que eles esperam. Comece escrevendo a promessa exata que seu produto faz.
Um fluxo prático de restauração
Use uma sequência pequena e rígida para que a restauração seja previsível e auditável.
- Defina o que “restaurar” significa. O registro manterá o mesmo ID? Deve voltar para o mesmo pai (workspace, projeto) e manter as mesmas relações? Decida o que acontece com memberships, papéis e visibilidade.
- Peça confirmação e capture um motivo. Mostre o que será restaurado (nome, proprietário, data da última modificação) e exija uma confirmação clara. Para times de suporte, um campo de motivo curto (“apagado por engano”, “fechando ticket”) costuma ser suficiente.
- Cheque conflitos antes de mudar qualquer coisa. Problemas comuns: o nome antigo foi reutilizado, o usuário não tem mais permissão ou registros relacionados foram hard-deleted. Escolha uma regra: bloquear a restauração com uma mensagem clara ou restaurar para um estado seguro “precisa revisão”.
- Registre a ação de restauração. Anote quem restaurou, quando, de onde (UI, API) e o que mudou. Isso ajuda em auditorias e suporte, e é essencial quando alguém pergunta “Por que isso voltou?”.
- Adicione limite de tempo quando fizer sentido. Muitos apps permitem restauração por 30 ou 90 dias e depois exigem outro processo ou tratam como permanente.
Se você constrói apps rapidamente em uma ferramenta guiada por chat como Koder.ai, mantenha essas checagens como parte do fluxo gerado para que cada tela e endpoint sigam as mesmas regras.
Erros comuns e armadilhas a evitar
Entregue ferramentas administrativas para suporte
Crie telas internas para encontrar, restaurar e revisar itens excluídos com segurança.
A maior dor com soft deletes não é a exclusão em si, mas todos os lugares que esquecem que o registro está “invisível”. Muitas equipes escolhem soft delete por segurança e depois mostram itens excluídos em resultados de busca, badges ou totais. Usuários percebem rápido quando um dashboard diz “12 projetos” mas só 11 aparecem na lista.
Em segundo lugar vem controle de acesso. Se um usuário, time ou workspace está soft-deleted, ele não deveria conseguir logar, chamar a API ou receber notificações. Isso costuma falhar quando o check de login busca por email, encontra a linha e não verifica o flag de exclusão.
Armadilhas comuns que geram tickets depois:
- Esquecer o filtro de excluídos em um caminho de leitura (vistas admin, exportações, busca, jobs em background).
- Restaurar registros que colidem com campos únicos (email, username, slug, número de fatura).
- Deletar um pai deixando filhos “ativos” (ou deletar filhos enquanto o pai ainda parece vivo).
- Contar linhas excluídas em analytics, cotas ou cálculo de cobrança.
- Enviar dados excluídos para terceiros porque integrações e jobs de sync não entendem “excluído”.
Colisões de unicidade são especialmente desagradáveis durante restauração. Se alguém cria uma nova conta com o mesmo email enquanto a antiga está soft-deleted, restaurar pode falhar ou sobrescrever a identidade errada. Decida sua regra antes: bloquear reutilização até a purga, permitir reutilização mas impedir restauração, ou restaurar com um novo identificador.
Um cenário comum: um agente de suporte restaura um workspace soft-deleted. O workspace volta, mas os membros permanecem deletados, e uma integração retoma a sincronização de registros antigos para uma ferramenta parceira. Do ponto de vista do usuário, a restauração “funcionou pela metade” e causou um novo problema.
Antes de liberar restauração, deixe explícito:
- O que “excluído” significa para login, acesso à API e notificações
- Como a restauração lida com campos únicos e propriedade
- Como registros relacionados seguem o pai (tudo ou nada evita surpresas)
- Como exportações e integrações tratam dados excluídos (excluir, marcar ou enviar tombstones)
Exemplo realista: um workspace excluído por engano
Um time de SaaS B2B tem um botão “Delete workspace”. Uma sexta‑feira, um admin faz uma limpeza e remove 40 workspaces que pareciam inativos. Na segunda, três clientes reclamam que seus projetos sumiram e pedem restauração imediata.
A equipe achou que a decisão seria simples. Não foi.
Primeiro problema: suporte não consegue restaurar o que foi realmente deletado. Se a linha do workspace foi hard-deleted e cascata removeu projetos, arquivos e memberships, a única opção é backups. Isso significa tempo, risco e uma resposta constrangedora ao cliente.
Segundo problema: analytics parece quebrado. O dashboard conta “workspaces ativos” consultando apenas linhas onde deleted_at IS NULL. A exclusão acidental gera uma queda nos gráficos. Pior: um relatório semanal compara com a semana anterior e sinaliza um pico falso de churn. Os dados não foram perdidos, mas foram excluídos nos lugares errados.
Terceiro problema: chega uma solicitação de privacidade para um dos usuários afetados. Ele pede exclusão de dados pessoais. Um soft delete puro não satisfaz isso. A equipe precisa de um plano para purgar campos pessoais (nome, email, logs de IP) mantendo agregados não pessoais como totais de cobrança e números de fatura.
Quarto problema: todos perguntam “Quem clicou em excluir?” Se não há trilha, o suporte não consegue explicar.
Um padrão mais seguro é tratar a exclusão como um evento com metadados claros:
- Marcar o workspace como excluído (e ocultá-lo no produto)
- Registrar
deleted_by,deleted_ate um motivo ou id de ticket - Logar o que será afetado (contagem de projetos, assentos, armazenamento)
- Permitir restauração dentro de uma janela e depois purgar campos pessoais quando requerido
Esse tipo de fluxo é o que times frequentemente montam rápido em plataformas como Koder.ai e depois percebem que a política de exclusão precisa tanto design quanto as funcionalidades ao redor.
Checklist rápido para escolher a estratégia certa de exclusão
Evite registros fantasmas
Construa visualizações de lista, pesquisa e exportação que filtrem consistentemente dados excluídos.
Escolher entre soft deletes e hard deletes é menos uma preferência e mais sobre o que seu app deve garantir depois que um registro “sumiu”. Faça essas perguntas antes de escrever uma consulta.
- Você precisa de apagamento real? Se precisa atender a pedidos legais ou de privacidade, planeje exclusão verdadeira (e backups, exportações e caches também). Um flag de soft delete sozinho não é suficiente.
- Você precisa de um botão de restaurar, e por quanto tempo? Se “desfazer” importa, decida a janela de restauração (7 dias, 30 dias, para sempre) e o que ocorre quando expira.
- Os relatórios vão precisar dos dados antigos após a exclusão? Alguns times querem gráficos que reflitam o que os usuários veem hoje; outros precisam de contagens históricas para finanças. Sua escolha de exclusão muda o significado de “usuários ativos” e “receita total”.
- O suporte consegue explicar o que aconteceu sem investigação? Se você espera chamados como “meu projeto sumiu”, precisa de uma trilha clara: quem deletou, quando e de onde, além de dados suficientes para investigar.
- Sua equipe consegue manter comportamento consistente em todos os lugares? Soft deletes frequentemente criam regras ocultas: toda consulta deve filtrar registros excluídos, todo join deve se comportar e toda tela deve concordar sobre o que “excluído” significa.
Uma forma simples de checar a decisão é pegar um incidente realista e simular: alguém apaga um workspace por engano na sexta à noite. Na segunda, o suporte precisa ver o evento de exclusão, restaurar com segurança e evitar reviver dados relacionados que deveriam permanecer removidos. Se você está construindo em uma plataforma como Koder.ai, defina essas regras cedo para que o backend e a UI gerados sigam uma política única em vez de espalhar casos especiais pelo código.
Próximos passos: escolha uma política e implemente seguramente
Escolha sua abordagem escrevendo uma política simples que você possa compartilhar com equipe e suporte. Se não estiver documentada, ela vai derivar e os usuários sentirão a inconsistência.
Comece com um conjunto claro de regras:
- O que é soft-deleted (e por quanto tempo permanece restaurável)
- O que é hard-deleted imediatamente (e por quê)
- Quando dados soft-deleted são purgados (por exemplo após X dias)
- Quem pode restaurar e que prova ou aprovação é necessária
- Como solicitações de exclusão por privacidade são tratadas de ponta a ponta
Depois construa dois caminhos claros que nunca se misturem: um caminho de “restauração administrativa” para erros e um caminho de “purga por privacidade” para exclusão real. O caminho de restauração deve ser reversível e logado. O caminho de purga deve ser final e remover ou anonimizar todo dado que possa identificar uma pessoa, incluindo backups ou exportações se a política exigir.
Adicione guardrails para que dados excluídos não vazem de volta ao produto. A maneira mais fácil é tratar “excluído” como um estado de primeira classe em testes. Adicione checkpoints de revisão para qualquer nova consulta, página de listagem, busca, exportação e job de analytics. Uma boa regra: se uma tela mostra dados visíveis ao usuário, ela deve ter uma decisão explícita sobre registros excluídos (ocultar, mostrar com rótulo ou somente admin).
Se você está no início do produto, prototipe ambos os fluxos antes de fixar o esquema. No Koder.ai, você pode desenhar a política de exclusão no modo de planejamento, gerar o CRUD básico e rapidamente testar cenários de restauração e purga, ajustando o modelo de dados antes de confirmar.