17 de dez. de 2025·7 min
Pooling de conexões PostgreSQL: pool no app vs PgBouncer
Pooling de conexões PostgreSQL: compare pools no app e PgBouncer para backends Go, métricas a monitorar e configurações erradas que geram picos de latência.
Pooling de conexões PostgreSQL: compare pools no app e PgBouncer para backends Go, métricas a monitorar e configurações erradas que geram picos de latência.
Uma conexão com o banco é como uma linha telefônica entre seu app e o Postgres. Abrir uma custa tempo e trabalho em ambos os lados: setup de TCP/TLS, autenticação, uso de memória e um processo backend no lado do Postgres. Um pool de conexões mantém um pequeno conjunto dessas “linhas” abertas para que seu app possa reutilizá-las em vez de discar toda vez.
Quando o pooling está desligado ou dimensionado de forma errada, raramente você vê um erro limpo primeiro. Você vê lentidão aleatória. Requisições que normalmente levam 20–50 ms de repente levam 500 ms ou 5 segundos, e o p95 dispara. Depois aparecem timeouts, “too many connections”, ou uma fila dentro do app enquanto ele espera por uma conexão livre.
Limites de conexão importam mesmo para apps pequenos porque o tráfego é irregular. Um email de marketing, um cron job ou alguns endpoints lentos podem fazer dezenas de requisições baterem no banco ao mesmo tempo. Se cada requisição abre uma conexão nova, o Postgres pode gastar muito de sua capacidade apenas aceitando e gerenciando conexões em vez de executar queries. Se você já tem um pool, mas ele é grande demais, pode sobrecarregar o Postgres com muitos backends ativos e causar troca de contexto e pressão de memória.
Fique atento a sintomas iniciais como:
Pooling reduz churn de conexão e ajuda o Postgres a lidar com picos. Não corrige SQL lento. Se uma query faz full table scan ou espera por locks, o pooling muda principalmente como o sistema falha (enfileiramento mais cedo, timeouts mais tarde), não se fica mais rápido.
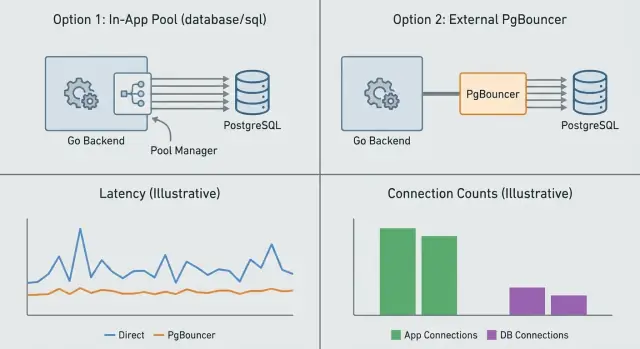
Pooling de conexões trata de controlar quantas conexões existem ao mesmo tempo e como elas são reutilizadas. Você pode fazer isso dentro do app (pool no nível do app) ou com um serviço separado na frente do Postgres (PgBouncer). Eles resolvem problemas relacionados, mas diferentes.
O pooling no app (em Go, normalmente o database/sql) gerencia conexões por processo. Ele decide quando abrir uma nova conexão, quando reutilizar uma e quando fechar inativas. Isso evita pagar o custo de setup em toda requisição. O que ele não faz é coordenar entre múltiplas instâncias do app. Se você roda 10 réplicas, você tem efetivamente 10 pools separados.
O PgBouncer fica entre seu app e o Postgres e faz pooling em nome de muitos clientes. É mais útil quando você tem muitas requisições de curta duração, muitas instâncias do app ou tráfego em rajadas. Ele limita o número de conexões servidor para o Postgres mesmo que centenas de conexões cliente cheguem ao mesmo tempo.
Uma divisão simples de responsabilidades:
Eles podem trabalhar juntos sem “double pooling” se cada camada tiver um propósito claro: um database/sql com limites razoáveis por processo Go, mais PgBouncer para impor um orçamento global de conexões.
Uma confusão comum é pensar “mais pools = mais capacidade.” Normalmente é o oposto. Se cada serviço, worker e réplica tem seu próprio pool grande, o número total de conexões pode explodir e causar enfileiramento, troca de contexto e picos de latência repentinos.
database/sql em Go realmente se comportaEm Go, sql.DB é um gerenciador de pool de conexões, não uma única conexão. Quando você chama db.Query ou db.Exec, o database/sql tenta reutilizar uma conexão ociosa. Se não conseguir, pode abrir uma nova (até seu limite) ou fazer a requisição esperar.
Essa espera é de onde vem muita “latência misteriosa”. Quando o pool está saturado, requisições enfileiram dentro do app. Do lado de fora, parece que o Postgres ficou lento, mas o tempo é gasto esperando uma conexão livre.
A maior parte do tuning se resume a quatro configurações:
MaxOpenConns: limite rígido de conexões abertas (ociosas + em uso). Quando atinge, as chamadas bloqueiam.MaxIdleConns: quantas conexões podem ficar prontas para reutilização. Muito baixo causa reconexões frequentes.ConnMaxLifetime: força reciclagem periódica de conexões. Útil para balanceadores e timeouts de NAT, mas muito baixo causa churn.ConnMaxIdleTime: fecha conexões que ficam sem uso por muito tempo.A reutilização de conexões normalmente reduz latência e CPU do banco porque evita setup repetido (TCP/TLS, auth, inicialização de sessão). Mas um pool superdimensionado pode fazer o contrário: permitir mais consultas concorrentes do que o Postgres lida bem, aumentando contenção e overhead.
Pense em totais, não por processo. Se cada instância Go permite 50 conexões abertas e você escala para 20 instâncias, você efetivamente permitiu 1.000 conexões. Compare esse número com o que seu servidor Postgres consegue rodar de forma estável.
Um ponto de partida prático é ligar MaxOpenConns à concorrência esperada por instância, depois validar com métricas do pool (in-use, idle e wait time) antes de aumentar.
PgBouncer é um pequeno proxy entre seu app e o PostgreSQL. Seu serviço se conecta ao PgBouncer, e o PgBouncer mantém um número limitado de conexões reais ao Postgres. Durante picos, o PgBouncer enfileira trabalho cliente em vez de criar mais backends no Postgres imediatamente. Essa fila pode ser a diferença entre uma desaceleração controlada e um banco que tomba.
O PgBouncer tem três modos de pooling:
O session pooling se comporta mais como conexões diretas ao Postgres. É o menos surpreendente, mas economiza menos conexões servidor durante cargas com picos.
Para APIs HTTP típicas em Go, o transaction pooling costuma ser um bom padrão. A maioria das requisições faz uma query pequena ou uma transação curta e pronto. O transaction pooling permite que muitas conexões cliente compartilhem um orçamento menor de conexões Postgres.
A troca é o estado de sessão. No modo transaction, qualquer coisa que assuma que uma conexão servidor única permanece pode quebrar ou se comportar de forma estranha, incluindo:
SET, SET ROLE, search_path)Se seu app depende desse tipo de estado, o session pooling é mais seguro. O statement pooling é o mais restritivo e raramente serve para web apps.
Uma regra útil: se cada requisição consegue configurar o que precisa dentro de uma única transação, o transaction pooling tende a manter a latência mais estável sob carga. Se você precisa de comportamento de sessão de longa duração, use session pooling e foque em limites mais restritos no app.
Se você roda um serviço Go com database/sql, já tem pooling no app. Para muitas equipes isso basta: poucas instâncias, tráfego estável e queries que não são extremamente voláteis. Nesse cenário, a escolha mais simples e segura é ajustar o pool do Go, manter o limite do banco realista e parar por aí.
O PgBouncer ajuda mais quando o banco está sendo atingido por muitas conexões cliente ao mesmo tempo. Isso aparece com muitas instâncias do app (ou escala serverless), tráfego em rajadas e muitas queries curtas.
O PgBouncer também pode atrapalhar se usado no modo errado. Se seu código depende de estado de sessão (tabelas temporárias, prepared statements mantidos entre requisições, advisory locks ou configurações de sessão), o transaction pooling pode causar falhas confusas. Se você realmente precisa de comportamento de sessão, use session pooling ou evite o PgBouncer e dimensione os pools do app com cuidado.
Use esta regra prática:
max open connections poderia exceder o que o Postgres aguenta, adicione PgBouncer.Limites de conexão são um orçamento. Se você gastar tudo de uma vez, cada nova requisição espera e a latência das caudas salta. O objetivo é limitar a concorrência de forma controlada enquanto mantém o throughput.
Meça os picos de hoje e a latência das caudas. Grave conexões ativas no pico (não médias), além de p50/p95/p99 para requisições e queries-chave. Anote erros de conexão ou timeouts.
Defina um orçamento seguro de conexões Postgres para o app. Comece a partir de max_connections e reserve espaço para acesso admin, migrações, jobs em background e picos. Se vários serviços compartilham o banco, divida o orçamento intencionalmente.
Mapeie o orçamento para limites Go por instância. Divida o orçamento do app pelo número de instâncias e ajuste MaxOpenConns para esse valor (ou um pouco menor). Configure MaxIdleConns alto o suficiente para evitar reconnects constantes e defina lifetimes para que conexões se reciclem ocasionalmente sem churn.
Adicione PgBouncer só se precisar e escolha um modo. Use session pooling se precisar de estado de sessão. Use transaction pooling quando quiser a maior redução de conexões servidor e seu app for compatível.
Faça rollout gradualmente e compare antes/depois. Mude uma coisa por vez, canarize, e compare latência das caudas, tempo de espera no pool e CPU do banco.
Exemplo: se o Postgres pode dar seguramente 200 conexões ao seu serviço e você roda 10 instâncias Go, comece com MaxOpenConns=15–18 por instância. Isso deixa folga para rajadas e reduz a chance de todas as instâncias baterem no teto ao mesmo tempo.
Problemas de pooling raramente aparecem primeiro como “muitas conexões”. Mais frequentemente você vê uma subida lenta no tempo de espera e depois um salto repentino no p95 e p99.
Comece com o que seu app Go reporta. Com database/sql, monitore conexões abertas, em uso, ociosas, wait count e wait time. Se o wait count sobe enquanto o tráfego está estável, seu pool está subdimensionado ou conexões estão sendo seguradas por muito tempo.
No banco, acompanhe conexões ativas vs max, CPU e atividade de locks. Se a CPU está baixa mas a latência alta, muitas vezes é enfileiramento ou locks, não computação bruta.
Se você roda PgBouncer, adicione uma terceira visão: conexões cliente, conexões servidor ao Postgres e profundidade da fila. Uma fila crescendo com conexões servidor estáveis é sinal claro de orçamento saturado.
Sinais de alerta úteis:
Problemas de pooling costumam aparecer durante rajadas: requisições se acumulam esperando por uma conexão e depois tudo volta ao normal. A causa raiz costuma ser uma configuração razoável em uma instância, mas perigosa quando você roda muitas cópias do serviço.
Causas comuns:
MaxOpenConns definido por instância sem um orçamento global. 100 conexões por instância em 20 instâncias = 2.000 conexões potenciais.ConnMaxLifetime / ConnMaxIdleTime muito baixos. Isso pode disparar tempestades de reconexão quando muitas conexões reciclam ao mesmo tempo.Uma forma simples de reduzir picos é tratar pooling como um limite compartilhado, não um padrão local do app: limite conexões totais entre instâncias, mantenha um pool ocioso modesto e use lifetimes longos o suficiente para evitar reconnects sincronizados.
Quando o tráfego sobe, normalmente você vê três resultados: requisições enfileiram esperando uma conexão livre, requisições dão timeout, ou tudo fica tão lento que retries se acumulam.
O enfileiramento é o sneaky. Seu handler continua rodando, mas está parado esperando uma conexão. Essa espera entra no tempo de resposta, então um pool pequeno pode transformar uma query de 50 ms em um endpoint de vários segundos sob carga.
Um modelo mental útil: se seu pool tem 30 conexões utilizáveis e de repente chegam 300 requisições concorrentes que todas precisam do banco, 270 delas terão de esperar. Se cada requisição segura uma conexão por 100 ms, a latência das caudas rapidamente vai para segundos.
Defina um orçamento de timeout claro e cumpra-o. O timeout do app deve ser um pouco menor que o timeout do banco para que você falhe rápido e reduza pressão em vez de deixar trabalho preso.
statement_timeout para que uma query ruim não segure conexões para sempreDepois, acrescente backpressure para não sobrecarregar o pool. Escolha um ou dois mecanismos previsíveis, como limitar concorrência por endpoint, rejeitar carga com erros claros (429) ou separar jobs em background do tráfego de usuários.
Por fim, corrija queries lentas primeiro. Sob pressão de pooling, queries lentas seguram conexões por mais tempo, o que aumenta esperas, timeouts e retries. Esse loop é como “um pouco lento” vira “tudo está lento”.
Trate testes de carga como uma forma de validar seu orçamento de conexões, não só throughput. O objetivo é confirmar que o pooling se comporta sob pressão como no staging.
Teste com tráfego realista: mesma mistura de endpoints, padrões de rajada e mesmo número de instâncias que você usa em produção. Benchmarks de “um endpoint” frequentemente escondem problemas de pool até o dia do lançamento.
Inclua um aquecimento para não medir caches frios e efeitos de ramp-up. Deixe os pools atingirem o tamanho normal e então comece a coletar números.
Se você estiver comparando estratégias, mantenha a carga idêntica e execute:
database/sql ajustado, sem PgBouncer)Após cada execução, registre um pequeno scorecard que você possa reutilizar depois de cada release:
Com o tempo, isso transforma planejamento de capacidade em algo repetível em vez de palpite.
Antes de mexer nos tamanhos de pool, escreva um número: seu orçamento de conexões. Esse é o número máximo seguro de conexões ativas do Postgres para esse ambiente (dev, staging, prod), incluindo jobs em background e acesso admin. Se você não consegue nomeá-lo, está chutando.
Checklist rápido:
MaxOpenConns) caiba no orçamento (ou no cap do PgBouncer).max_connections e quaisquer conexões reservadas batem com seu plano.Plano de rollout que facilita rollback:
Se você está desenvolvendo e hospedando um app Go + PostgreSQL no Koder.ai (koder.ai), o Planning Mode pode ajudar a mapear a mudança e o que você vai medir, e snapshots + rollback facilitam reverter caso a latência das caudas piore.
Próximo passo: adicione uma métrica antes da próxima grande variação de tráfego. “Tempo gasto esperando por uma conexão” no app costuma ser a mais útil, porque mostra pressão no pooling antes dos usuários sentirem.
Um pool mantém um pequeno conjunto de conexões PostgreSQL abertas e as reutiliza entre requisições. Isso evita pagar o custo de criação repetida (TCP/TLS, autenticação, criação do backend), o que ajuda a manter a latência das caudas estável durante picos.
Quando o pool está saturado, as requisições ficam esperando dentro do app por uma conexão livre, e esse tempo de espera aparece como respostas lentas. Isso costuma parecer “lentidão aleatória”, porque as médias podem continuar normais enquanto p95/p99 disparam durante picos de tráfego.
Não. Pooling muda principalmente o comportamento sob carga, reduzindo churn de reconexão e controlando concorrência. Se uma query é lenta por varreduras, locks ou indexação ruim, pooling não a deixa mais rápida; só limita quantas queries lentas podem rodar ao mesmo tempo.
O pooling no app gerencia conexões por processo, então cada instância do app tem seu próprio pool e limites. O PgBouncer fica na frente do Postgres e aplica um orçamento global de conexões entre muitos clientes — útil quando há muitas réplicas ou tráfego em rajadas.
Se você roda poucas instâncias e o total de conexões abertas fica bem abaixo do limite do banco, ajustar o pool do database/sql geralmente basta. Adicione o PgBouncer quando muitas instâncias, autoscaling ou picos de tráfego puderem empurrar as conexões totais além do que o Postgres suporta.
Uma boa prática é definir um orçamento total de conexões para o serviço, dividir pelo número de instâncias e configurar MaxOpenConns um pouco abaixo desse valor por instância. Comece pequeno, monitore tempo de espera e p95/p99, e só aumente se houver certeza de que o banco tem capacidade.
Para APIs HTTP em Go, o pooling por transação costuma ser um bom padrão porque permite que muitas conexões cliente compartilhem menos conexões servidor e se mantém estável durante picos. Use session pooling se seu código depende de estado de sessão persistente entre statements.
Prepared statements reaproveitados, tabelas temporárias, advisory locks e configurações de sessão podem se comportar diferente porque o cliente pode não pegar a mesma conexão servidor na próxima vez. Se você precisa desses recursos, garanta que tudo aconteça dentro de uma única transação ou use session pooling.
Monitore p95/p99 junto com o tempo de espera do pool no app — o tempo de espera costuma subir antes que os usuários reclamem. No Postgres, acompanhe conexões ativas, CPU e locks; no PgBouncer, acompanhe conexões cliente, conexões servidor e profundidade da fila para ver se o orçamento está saturado.
Primeiro, pare espera ilimitada definindo deadlines nas requisições e um statement_timeout no DB para evitar que uma query lenta segure conexões pra sempre. Depois, aplique backpressure limitando concorrência em endpoints pesados, rejeitando carga com 429 quando necessário, e evite ciclos de reconexão curtos que causam tempestades de reconnect.