27 de ago. de 2025·8 min
Pools de workers em Go para tarefas em segundo plano: retentativas, cancelamento e desligamento
Pools de workers em Go ajudam times pequenos a rodar tarefas em segundo plano com retentativas, cancelamento e desligamento limpo usando padrões simples antes de adicionar infraestrutura pesada.
Por que tarefas em segundo plano viram bagunça rápido
Em um serviço Go pequeno, o trabalho em background geralmente começa com um objetivo simples: retornar a resposta HTTP rapidamente e depois fazer o trabalho lento. Isso pode ser enviar e-mails, redimensionar imagens, sincronizar com outra API, reconstruir índices de busca ou gerar relatórios noturnos.
O problema é que essas tarefas são trabalho de produção de verdade, só que sem as proteções que você tem naturalmente no tratamento de requisições. Uma goroutine iniciada a partir de um handler HTTP parece ok até que um deploy aconteça no meio da execução, uma API upstream fique lenta ou a mesma requisição seja re-enviada e dispare o job duas vezes.
Os primeiros pontos de dor são previsíveis:
- Jobs travados: uma chamada fica pendurada e os workers deixam de progredir.
- Trabalho duplicado: retry na camada HTTP reexecuta o mesmo job.
- Sem plano de desligamento: o processo sai e o trabalho é perdido ou fica pela metade.
- Falhas silenciosas: erros são logados uma vez (ou não) e desaparecem.
- Tempestade de retries: jobs falhando re-tentam instantaneamente e sobrecarregam dependências.
É aí que um padrão pequeno e explícito como um pool de workers em Go ajuda. Ele transforma concorrência em uma escolha (N workers), converte “faça depois” em um tipo de job claro e te dá um único lugar para lidar com retentativas, timeouts e cancelamento.
Exemplo: um app SaaS precisa enviar faturas. Você não quer 500 envios simultâneos após uma importação em lote, nem quer reenviar a mesma fatura porque a requisição foi re-tentada. Um worker pool permite limitar throughput e tratar “enviar fatura #123” como uma unidade de trabalho rastreada.
Um worker pool não é a ferramenta certa quando você precisa de garantias duráveis entre processos. Se jobs devem sobreviver a crashes, ser agendados para o futuro ou processados por múltiplos serviços, você provavelmente vai precisar de uma fila real mais armazenamento persistente para estado dos jobs.
O modelo do worker pool em linguagem simples
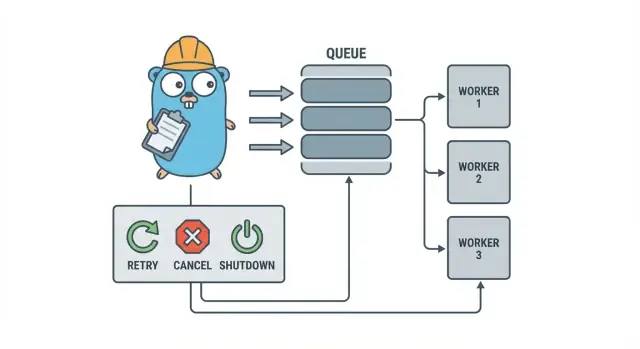
Um worker pool em Go é propositalmente sem glamour: coloque trabalho numa fila, tenha um conjunto fixo de workers que puxam dela e garanta que tudo possa parar de forma limpa.
Os termos básicos:
- Job: uma unidade de trabalho, como “redimensionar essa imagem” ou “enviar este e-mail de fatura”.
- Fila (queue): onde os jobs aguardam.
- Worker: uma goroutine que repetidamente pega um job e o executa.
- Dispatcher: a parte que aceita jobs e os empurra para a fila.
Em muitos designs in-process, um channel em Go é a fila. Um channel bufferizado pode conter um número limitado de jobs antes dos produtores bloquearem. Esse bloqueio é backpressure, e frequentemente é isso que impede seu serviço de aceitar trabalho ilimitado e ficar sem memória quando o tráfego sobe.
O tamanho do buffer muda a sensação do sistema. Um buffer pequeno torna a pressão visível rapidamente (chamadores esperam mais cedo). Um buffer maior suaviza picos curtos, mas pode esconder sobrecarga até depois. Não existe número perfeito, apenas um número que combine com quanto tempo de espera você tolera.
Você também decide se o tamanho do pool é fixo ou pode variar. Pools fixos são mais fáceis de raciocinar e mantêm o uso de recursos previsível. Autoescalar workers pode ajudar com carga irregular, mas adiciona decisões a manter (quando escalar, quanto, e quando reduzir).
Por fim, “ack” em um pool in-process normalmente significa apenas “o worker terminou o job e retornou sem erro.” Não há um broker externo confirmando entrega, então seu código define o que “feito” significa e o que acontece quando um job falha ou é cancelado.
Objetivos de design: retentativas, cancelamento e desligamento limpo
Um worker pool é simples mecanicamente: rode um número fixo de workers, alimente-os com jobs e processe. O valor está no controle: concorrência previsível, tratamento de falhas claro e um caminho de desligamento que não deixe trabalho pela metade.
Três objetivos mantêm times pequenos são:
- Limitar a concorrência para que um pico não queime o banco ou uma API externa.
- Evitar perda de trabalho (ou ao menos saber exatamente o que foi descartado e por quê).
- Manter debugabilidade: todo job deve ser rastreável por logs e alguns contadores.
A maioria das falhas é chata, mas você ainda quer tratá-las de forma diferente:
- Erros transitórios (problemas de rede, limites de taxa) que valem a pena retentar.
- Erros permanentes (input inválido, registro faltando) que não devem ser retentados.
- Timeouts (uma dependência trava) que precisam ser interrompidos para que workers não fiquem entupidos.
Cancelamento não é o mesmo que “erro”. É uma decisão: um usuário cancelou, um deploy substituiu seu processo ou seu serviço está desligando. Em Go, trate cancelamento como um sinal de primeira classe usando context cancellation, e garanta que cada job verifique isso antes de começar trabalho caro e em alguns pontos seguros durante a execução.
Desligamento limpo é onde muitos pools quebram. Decida cedo o que “seguro” significa para seus jobs: você finaliza o trabalho em voo ou para rapidamente e reexecuta depois? Um fluxo prático é:
- Pare de aceitar novos jobs.
- Diga aos workers para parar após o job atual (ou pare imediatamente).
- Espere até um prazo, então force a saída.
Se você definir essas regras cedo, retentativas, cancelamento e shutdown permanecem pequenos e previsíveis em vez de virar um framework caseiro.
Passo a passo: construir um pool básico
Um worker pool é só um grupo de goroutines puxando jobs de um channel e executando. A parte importante é tornar o básico previsível: como é um job, como os workers param e como saber quando todo o trabalho terminou.
Comece com um tipo simples Job. Dê a ele um ID (para logs), um payload (o que processar), um contador de tentativas (útil depois para retentativas), timestamps e um lugar para guardar dados de contexto por job.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Algumas escolhas práticas que você fará imediatamente:
- Escolha o tamanho do buffer com base em quanto espera tolerar de espera.
- Decida o que backpressure significa para os chamadores: bloquear, retornar erro ou descartar.
- Mantenha
Stop()eWait()separados para que você possa parar a entrada primeiro e depois esperar o trabalho em voo terminar.
Adicionando retentativas sem transformar em um framework
Retentativas são úteis, mas também é onde pools de workers complicam. Mantenha o objetivo estreito: re-tente apenas quando outra tentativa tiver chance real de sucesso e pare rápido quando não tiver.
Comece decidindo o que é retryable. Problemas temporários (hics de rede, timeouts, respostas “tente novamente mais tarde”) geralmente valem a pena re-tentar. Permanentes (input inválido, registro faltando, permissão negada) não.
Uma política de retries pequena costuma ser suficiente:
- Marque erros como retryable ou não (por exemplo, envelopando com um helper
Retryable(err)). - Defina um número máximo de tentativas (frequentemente 3 a 5). Além disso, normalmente você só está gastando tempo.
- Use backoff exponencial com jitter para que jobs não re-tentem sincronizados.
- Tenha um limite no delay (por exemplo, nunca durma mais de 30s).
- Logue retentativas com número da tentativa, próximo delay e ID do job.
Backoff não precisa ser complicado. Uma forma comum é: delay = min(base * 2^(attempt-1), max), então adicione jitter (aleatorize +/- 20%). Jitter importa porque, sem ele, muitos workers falham juntos e re-tentam juntos.
Onde deve viver o sleep? Para sistemas pequenos, dormir dentro do worker é aceitável, mas ocupa a vaga do worker. Se retentativas são raras, tudo bem. Se forem comuns ou delays longos, considere re-enfileirar o job com um timestamp de “rodar depois” para que os workers fiquem ocupados com outro trabalho.
Na falha final, seja explícito. Armazene o job falhado (e o último erro) para revisão, logue contexto suficiente para replays ou empurre para uma dead list que você verifica regularmente. Evite descartes silenciosos. Um pool que esconde falhas é pior do que não ter retentativas.
Cancelamento e timeouts que realmente param o trabalho
Deploy your background worker
Faça o deploy da sua aplicação Go com suporte de hosting quando estiver pronto para rodar.
Pools de workers só parecem seguros quando você pode pará-los. A regra mais simples é: passe um context.Context por toda camada que pode bloquear. Isso inclui submissão, execução e cleanup.
Uma configuração prática usa dois limites de tempo:
- Um timeout por job para que uma tarefa não ocupe um worker para sempre.
- Um timeout de shutdown para que o processo possa sair mesmo se alguns jobs não colaborarem.
Use context de ponta a ponta
Dê a cada job seu próprio contexto derivado do contexto do worker. Então toda chamada lenta (DB, HTTP, queues, I/O de arquivo) deve usar esse contexto para que possa retornar cedo.
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Se Run chama seu DB ou uma API, passe o context para essas chamadas (por exemplo, QueryContext, NewRequestWithContext ou métodos de cliente que aceitem context). Se você ignorar isso em algum lugar, cancelamento vira “melhor esforço” e normalmente falha quando você mais precisa.
Trabalho parcial e passos “seguros para re-tentar”
Cancelamento pode acontecer no meio do job, então assuma que trabalho parcial é normal. Mire em passos idempotentes para que re-execuções não criem duplicatas. Abordagens comuns incluem usar chaves únicas para inserts (ou upserts), escrever marcadores de progresso (started/done), persistir resultados antes de continuar e checar ctx.Err() entre passos.
Trate shutdown como um deadline: pare de aceitar novos jobs, cancele contextos dos workers e espere apenas até o timeout de shutdown para que os jobs em voo terminem.
Desligamento limpo: o que fazer quando o processo precisa sair
Um desligamento limpo tem um objetivo: parar de aceitar trabalho, avisar o trabalho em voo para parar e sair sem deixar o sistema em um estado estranho.
Comece com sinais. Na maioria dos deployments você verá SIGINT localmente e SIGTERM do gerenciador de processos ou runtime de container. Use um contexto de shutdown que seja cancelado quando um sinal chegar e passe isso para seu pool e handlers.
Em seguida, pare de aceitar novos jobs. Não deixe chamadores bloquearem para sempre tentando submeter em um channel que ninguém lê mais. Mantenha submissões por trás de uma função única que checa uma flag fechada ou faz select no contexto de shutdown antes de enviar.
Então decida o que acontece com o trabalho enfileirado:
- Drain (esvaziar): finalize o que já está na fila, mas rejeite novas submissões.
- Drop (descartar): descarte tudo que ainda não começou.
Esvaziar é mais seguro para coisas como pagamentos e e-mails. Descartar é aceitável para tarefas “bacanas de ter” como recomputar cache.
Uma sequência prática de shutdown:
- Capture SIGINT/SIGTERM e cancele um contexto compartilhado.
- Pare as submissões (feche a rota de envio, não necessariamente o channel de trabalho).
- Deixe os workers finalizar ou abortar dependendo do contexto.
- Espere pelos workers com um WaitGroup.
- Aplique um deadline, então saia.
O deadline importa. Por exemplo, dê 10 segundos para jobs em voo pararem. Depois disso, logue o que ainda estava rodando e saia. Isso mantém deploys previsíveis e evita processos travados.
Logs e métricas simples para pools de workers
Prototype an invoice job pipeline
Gere a pipeline do pagamento ao invoice e o loop de worker a partir de uma única especificação.
Quando um worker pool quebra, raramente falha de forma barulhenta. Jobs ficam lentos, retentativas acumulam e alguém diz que “nada está acontecendo.” Logs e alguns contadores básicos transformam isso em uma história clara.
Dê a cada job um ID estável (ou gere um na submissão) e inclua em todas as linhas de log. Mantenha logs consistentes: uma linha quando um job inicia, uma quando termina e uma quando falha. Se você re-tentar, registre o número da tentativa e o próximo delay.
Uma forma simples de log:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Métricas podem ser mínimas e ainda assim úteis. Monitore comprimento da fila, jobs em voo, totais de sucessos e falhas e latência dos jobs (pelo menos média e máximo). Se o comprimento da fila continuar subindo e o in-flight ficar no máximo pelo número de workers, você está saturado. Se os submitters bloqueiam ao enviar no channel, o backpressure atingiu o chamador. Nem sempre é ruim, mas deve ser deliberado.
Quando “jobs estão travados”, verifique se o processo ainda está recebendo jobs, se a fila cresce, se os workers estão vivos e quais jobs estão rodando há mais tempo. Tempos de execução longos normalmente indicam timeouts ausentes, dependências lentas ou um loop de retentativa que nunca para.
Um exemplo realista: uma fila de background em um SaaS pequeno
Imagine um SaaS pequeno onde um pedido muda para PAID. Logo após o pagamento, você precisa gerar o PDF da fatura, enviar por e-mail ao cliente e notificar o time interno. Você não quer que esse trabalho bloqueie a requisição web. Isso é um bom fit para um worker pool porque o trabalho é real, mas o sistema ainda é pequeno.
O payload do job pode ser mínimo: o suficiente para buscar o resto no banco. O handler da API grava uma linha tipo jobs(status='queued', type='send_invoice', payload, attempts=0) na mesma transação que a atualização do pedido, então um loop em background consulta jobs em fila e os empurra para o channel do worker.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Quando um worker pega esse job, o caminho feliz é direto: carregue o pedido, gere a fatura, chame o provedor de e-mail e então marque o job como feito.
As retentativas é onde isso fica real. Se seu provedor de e-mail estiver com queda temporária, você não quer que 1.000 jobs falhem para sempre ou que martelarem o provedor a cada segundo. Uma abordagem prática é:
- Tratar erros de rede e respostas 5xx como retryable.
- Usar backoff exponencial com um delay máximo (por exemplo, 5s, 15s, 45s, 2m).
- Limitar tentativas (por exemplo, 10) e então marcar o job como falhado.
- Registrar o último erro para que o suporte veja o que aconteceu.
Durante a queda, jobs movem de queued para in_progress e depois voltam para queued com um tempo futuro de execução. Quando o provedor recuperar, os workers naturalmente drenam o backlog.
Agora imagine um deploy. Você envia SIGTERM. O processo deve parar de aceitar trabalho novo, mas finalizar o que está em voo. Pare o polling, pare de alimentar o channel de workers e espere pelos workers com um deadline. Jobs que terminarem são marcados como feitos. Jobs que ainda estiverem rodando quando o deadline chegar devem ser marcados de volta como queued (ou deixados em in_progress com um watchdog) para que sejam reprocessados quando a nova versão subir.
Erros comuns e armadilhas
A maioria dos bugs em processamento em background não está na lógica do job. Vêm de erros de coordenação que só aparecem sob carga ou durante shutdown.
Uma armadilha clássica é fechar um channel de mais de um lugar. O resultado é um panic difícil de reproduzir. Escolha um dono para cada channel (geralmente o produtor) e faça dele o único que chama close(jobs).
Retentativas são outra área onde boas intenções causam outages. Se você re-tentar tudo, vai re-tentar falhas permanentes também. Isso desperdiça tempo, aumenta carga e pode transformar um problema pequeno em um incidente. Classifique erros e limite retentativas com uma política clara.
Duplicatas vão acontecer mesmo com design cuidadoso. Workers podem cair no meio do job, um timeout pode disparar depois do trabalho terminado ou você pode re-enfileirar durante o deploy. Se o job não for idempotente, duplicatas causam danos reais: duas faturas, dois e-mails de boas-vindas, dois reembolsos.
Os erros que aparecem com mais frequência:
- Fechar o mesmo channel de múltiplas goroutines.
- Retentar falhas permanentes em vez de expô-las.
- Sem chave de idempotência, então duplicatas causam efeitos colaterais duplicados.
- Filas em memória sem limite que crescem até estourar memória.
- Ignorar
context.Context, então o trabalho continua depois do início do shutdown.
Filas sem limite são especialmente sorrateiras. Um pico de trabalho pode empilhar silenciosamente na RAM. Prefira um channel com buffer limitado e decida o que acontece quando ele enche: bloquear, dropar ou retornar erro.
Checklist rápido antes de colocar em produção
Build clean shutdown in Go
Crie tratamento de sinais e timeouts de context em minutos a partir de um prompt de chat.
Antes de enviar um worker pool para produção, você deve conseguir descrever o ciclo de vida do job em voz alta. Se alguém perguntar “onde está esse job agora?”, a resposta não deve ser um palpite.
Uma checklist prática antes do voo:
- Você consegue nomear cada estado e transição: queued, picked up, running, finished, failed (e o que move entre eles).
- Concorrência é um único knob (como
workerCount), e mudá-lo não exige reescrever código. - Retentativas são limitadas: max attempts claros, backoff cresce e falha permanente vai para algum lugar intencional.
- Comportamento de shutdown é testado: você para intake, deixa jobs em voo terminar e ainda tem um timeout rígido.
- Logs respondem o básico: job ID, número da tentativa, duração e motivo do erro.
Faça um exercício realista antes do lançamento: enfileire 100 jobs “send receipt email”, force 20 a falhar e então reinicie o serviço no meio da execução. Você deve ver retentativas se comportando como esperado, sem efeitos colaterais duplicados e cancelamento realmente parando trabalho quando o deadline é atingido.
Se algum item estiver nebuloso, ajuste agora. Pequenas correções aqui salvam dias depois.
Próximos passos: quando adicionar infraestrutura mais pesada (e quando não)
Um pool simples in-process costuma bastar enquanto o produto é jovem. Se seus jobs são “bacanas de ter” (enviar e-mails, atualizar caches, gerar relatórios) e você pode re-executá-los, um worker pool mantém o sistema fácil de entender.
Sinais de que você superou um pool in-process
Fique de olho nestes pontos de pressão:
- Você roda várias instâncias da aplicação e precisa que apenas uma as pegue.
- Você precisa de durabilidade (jobs devem sobreviver a crashes e deploys).
- Você precisa de trilha de auditoria: quem enfileirou o quê, quando rodou e o resultado exato.
- Você precisa de controles de backpressure entre serviços, não apenas dentro de um processo.
- Você precisa de agendamento estrito ou atrasos longos (horas ou dias) com wake-up confiável.
Se nada disso for verdade, ferramentas mais pesadas podem acrescentar mais complexidade que valor.
Migrar gradualmente sem reescrever
A melhor proteção é uma interface de job estável: um payload pequeno, um ID e um handler que retorna um resultado claro. Assim você pode trocar o backend da fila depois (de um channel em memória para uma tabela no banco, e só então para uma fila dedicada) sem alterar a lógica de negócio.
Um passo intermediário prático é um serviço Go pequeno que lê jobs do PostgreSQL, os “claim” com um lock e atualiza status. Você ganha durabilidade e auditoria básica mantendo a mesma lógica de worker.
Se quiser prototipar rápido, Koder.ai (koder.ai) pode gerar um starter Go + PostgreSQL a partir de um prompt de chat, incluindo uma tabela de background jobs e o loop de worker, e seus snapshots e rollback podem ajudar enquanto você ajusta retentativas e comportamento de shutdown.