Quando o banco de dados está estressado, o que quebra primeiro
Quando seu banco de dados está sobrecarregado, os usuários raramente veem uma mensagem limpa de "offline". Eles veem timeouts, páginas que carregam pela metade, botões que ficam girando para sempre e ações que às vezes funcionam e às vezes falham. Um salvamento pode dar certo uma vez e dar erro na próxima com "Algo deu errado." Essa incerteza é o que torna os incidentes caóticos.
As primeiras coisas a quebrar costumam ser os caminhos pesados de escrita: edição de registros, fluxos de checkout, envios de formulários, atualizações em background e qualquer coisa que precise de transação e locks. Sob estresse, as gravações ficam mais lentas, bloqueiam umas às outras e também podem desacelerar as leituras ao segurar locks e forçar mais trabalho.
Erros aleatórios parecem piores do que uma limitação controlada porque os usuários não sabem o que fazer em seguida. Eles tentam de novo, atualizam a página, clicam outra vez e criam ainda mais carga. Chamados de suporte disparam porque o sistema parece "meio funcionando", mas ninguém confia nele.
O objetivo do modo somente leitura durante incidentes não é perfeição. É manter as partes mais importantes utilizáveis: visualizar registros-chave, pesquisar, checar status e baixar o que as pessoas precisam para continuar o trabalho. Você para ou atrasa intencionalmente as ações arriscadas (gravações) para que o banco possa se recuperar e as leituras restantes permaneçam responsivas.
Defina expectativas com clareza. Isso é um limite temporário e não significa que dados estão sendo deletados. Na maioria dos casos, os dados existentes do usuário ainda estão lá e seguros — o sistema está apenas pausando mudanças até que o banco volte a ficar saudável.
O que o modo somente leitura realmente significa
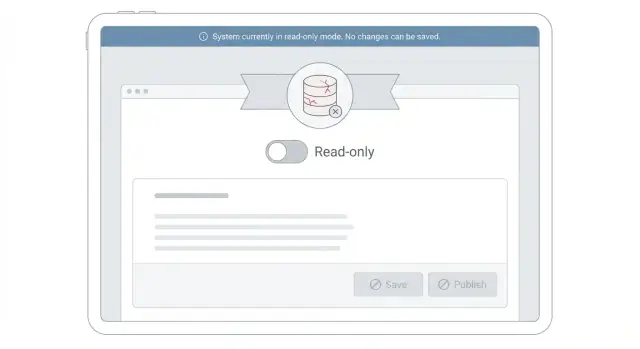
Modo somente leitura durante incidentes é um estado temporário em que seu produto continua utilizável para visualização, mas recusa qualquer operação que altere dados. O objetivo é simples: manter o serviço útil enquanto você protege o banco de dados de trabalho extra.
Em termos práticos, as pessoas ainda podem procurar coisas, mas não podem fazer mudanças que disparem gravações. Normalmente isso significa que navegar por páginas, pesquisar, filtrar e abrir registros ainda funcionam. Salvar formulários, editar configurações, postar comentários, enviar arquivos ou criar novas contas são bloqueados.
Uma forma prática de pensar é: se uma ação atualiza uma linha, cria uma linha, exclui uma linha ou escreve em uma fila, ela não é permitida. Muitas equipes também bloqueiam "gravações ocultas" como eventos de analytics armazenados no banco principal, logs de auditoria escritos de forma síncrona e timestamps de "última visita".
Modo somente leitura é a escolha certa quando as leituras ainda estão funcionando na maior parte, mas a latência de gravação está subindo, a contenção de locks está crescendo ou um acúmulo de trabalho pesado de escrita está deixando tudo mais lento.
Vá totalmente offline quando até leituras básicas começarem a dar timeout, seu cache não conseguir servir o essencial ou o sistema não puder dizer de forma confiável ao usuário o que é seguro tentar.
Por que isso ajuda: gravações costumam custar muito mais que uma leitura simples. Uma gravação pode acionar índices, constraints, locks e consultas subsequentes. Bloquear gravações também evita tempestades de retry, onde clientes continuam reenviando salvamentos falhos e multiplicam o dano.
Exemplo: durante um incidente em um CRM, os usuários ainda podem pesquisar contas, abrir detalhes de contato e ver negócios recentes, mas as ações Editar, Criar e Importar são desabilitadas e qualquer requisição de salvamento é rejeitada imediatamente com uma mensagem clara.
Escolha as leituras que precisa manter e as gravações a parar
Quando você entra em modo somente leitura durante incidentes, o objetivo não é "tudo funciona." O objetivo é que as telas mais importantes ainda carreguem, enquanto qualquer coisa que crie mais pressão no banco pare de forma rápida e segura.
Comece nomeando as poucas ações do usuário que devem continuar funcionando mesmo em um dia ruim. Normalmente são leituras pequenas que desbloqueiam decisões: ver o registro mais recente, checar um status, pesquisar uma lista curta ou baixar um relatório já em cache.
Depois decida o que pode pausar sem causar grande prejuízo. A maioria dos caminhos de escrita entra em "bom ter" durante um incidente: edições, atualizações em massa, importações, comentários, anexos, eventos de analytics e qualquer coisa que dispare consultas extras.
Uma maneira simples de decidir é ordenar ações em três categorias:
- Deve manter: leituras pequenas e rápidas que desbloqueiam usuários agora
- Pode pausar: gravações e leituras pesadas que adicionam carga ou travam linhas
- Pode degradar: funcionalidades que podem mostrar dados em cache ou uma visão parcial
Também defina um horizonte de tempo. Se você espera minutos, pode ser rigoroso e bloquear quase todas as gravações. Se espera horas, considere permitir um conjunto muito limitado de gravações seguras (como reset de senha ou updates críticos de status) e enfileirar o resto.
Concorde com a prioridade cedo: segurança acima de completude. É melhor mostrar uma mensagem clara "alterações estão pausadas" do que permitir uma gravação que meia-sucesso e deixe os dados inconsistentes.
Como decidir quando ativar
Ativar o modo somente leitura é uma troca: menos recursos agora, mas um produto utilizável e um banco mais saudável. O objetivo é agir antes que os usuários acionem um ciclo de retries, timeouts e conexões travadas.
Observe um pequeno conjunto de sinais que você pode explicar em uma frase. Se dois ou mais aparecerem ao mesmo tempo, trate como alerta inicial:
- Requisições dando timeout ou cruzando um limiar claro de latência (por exemplo, p95 sobe de 300 ms para 3 s)
- CPU do banco de dados no máximo por vários minutos, não só um pico curto
- Esgotamento do pool de conexões (requisições enfileirando porque não há conexões disponíveis)
- Log de queries lentas preenchendo de repente com as mesmas poucas consultas
- Aumento na taxa de erros devido a waits de lock, deadlocks ou transações falhas
Métricas sozinhas não devem ser o único gatilho. Adicione uma decisão humana: a pessoa on-call declara o estado de incidente e ativa o modo somente leitura. Isso evita debates sob pressão e torna a ação auditável.
Torne os limites fáceis de lembrar e de comunicar. "As gravações estão pausadas porque o banco está sobrecarregado" é mais claro que "atingimos saturação." Também defina quem pode acionar o interruptor e onde ele é controlado.
Evite flutuação entre modos. Adicione histerese simples: depois de entrar em somente leitura, permaneça nesse modo por uma janela mínima (como 10 a 15 minutos) e só volte depois que os sinais-chave estiverem normais por um tempo. Isso impede que usuários vejam formulários que funcionam um minuto e falham no seguinte.
Trate o modo somente leitura durante incidentes como uma mudança controlada, não um improviso. O objetivo é proteger o banco de dados interrompendo gravações, enquanto mantém as leituras mais valiosas funcionando.
Uma sequência de rollout segura
Se puder, implemente a via de código antes de acionar o interruptor. Assim, ativar o modo somente leitura é apenas um toggle, não uma edição ao vivo.
- Crie um único toggle de incidente (feature flag ou configuração) que todo o sistema leia. Mantenha-o global e simples:
READ_ONLY=true. Evite múltiplas flags que possam divergir.
- Atualize a UI para prevenir tentativas de escrita. Desabilite botões Salvar, esconda formulários de edição e transforme campos em texto simples. Ainda mostre os dados para que as pessoas possam continuar trabalhando (visualizar, pesquisar, exportar).
- Faça a aplicação no servidor, não apenas na UI. Bloqueie gravações em um único ponto (middleware, guard de controller ou camada de serviço) para cobrir todos os clientes, incluindo apps móveis, usuários da API e automações.
- Retorne um erro claro e consistente para gravações bloqueadas. Use um código de status e mensagem dedicados, por exemplo: "Edição temporariamente desabilitada enquanto estabilizamos o sistema. Seus dados estão seguros. Tente novamente mais tarde." Não retorne um 500 genérico que pareça perda de dados.
- Registre toda tentativa de gravação bloqueada. Capture usuário, endpoint e tipo de ação. Mantenha o payload mínimo para evitar dados sensíveis nos logs. Esses registros ajudam a corrigir lacunas de UX e a reproduzir ações críticas depois, se necessário.
Um detalhe pequeno que previne reincidências
Quando o modo somente leitura está ativo, falhe rápido antes de atingir o banco. Não rode queries de validação e depois bloqueie a escrita. A requisição bloqueada mais rápida é aquela que nunca toca seu banco sobrecarregado.
Mensagens na UI que reduzem confusão e chamados
Enviar Mensagens Calmas para Incidentes
Crie banners claros e mensagens de bloqueio de escrita que correspondam ao comportamento do seu backend.
Quando você habilita o modo somente leitura durante incidentes, a UI faz parte da solução. Se as pessoas continuarem clicando em Salvar e recebendo erros vagos, elas vão tentar de novo, atualizar e abrir tickets. Mensagens claras reduzem carga e frustração.
Um padrão bom é um banner visível e persistente no topo do app. Mantenha curto e factual: o que está acontecendo, o que os usuários devem esperar e o que podem fazer agora. Não esconda isso em um toast que some.
Diga o que funciona, o que está pausado e o que vem a seguir
Os usuários querem saber se conseguem continuar trabalhando. Escreva em linguagem simples. Para a maioria dos produtos, isso significa:
- Ainda funciona: visualizar registros, pesquisar, baixar, ler dashboards
- Pausado: criar, editar, excluir, uploads, pagamentos, envio de mensagens
- Faça em vez disso: copie informações importantes, exporte uma visão, tente novamente mais tarde
- Atualizações: "Postaremos uma atualização aqui em 15 minutos."
Um rótulo de status simples também ajuda as pessoas a entenderem o progresso sem adivinhação. "Investigando" significa que ainda estão procurando a causa. "Estabilizando" quer dizer que estão reduzindo a carga e protegendo os dados. "Recuperando" indica que as gravações voltarão em breve, mas podem estar lentas.
Mantenha o tom calmo e específico
Evite textos que culpem ou sejam vagos, como "Algo deu errado" ou "Você não tem permissão." Se um botão está desabilitado, rotule-o: "A edição está temporariamente pausada enquanto estabilizamos o sistema."
Um pequeno exemplo: em um CRM, mantenha páginas de contato e negócio legíveis, mas desabilite Editar, Adicionar nota e Novo negócio. Se alguém tentar mesmo assim, mostre um diálogo curto: "As alterações estão pausadas no momento. Você pode copiar este registro ou exportar a lista e tentar novamente depois."
Preservar leituras chave sem aumentar a carga
Quando você entra em modo somente leitura durante incidentes, o objetivo não é "manter tudo visível." É "manter as poucas páginas de que as pessoas dependem" sem adicionar mais pressão ao banco.
Comece reduzindo as telas mais pesadas. Tabelas longas com muitos filtros, buscas por texto livre em vários campos e ordenações complexas normalmente disparam consultas lentas. Em somente leitura, torne essas telas mais simples: menos opções de filtro, uma ordenação padrão segura e um intervalo de datas limitado.
Prefira visualizações em cache ou tabelas sumarizadas para as páginas mais importantes. Um simples "resumo da conta" que lê de um cache ou tabela resumida costuma ser mais seguro do que carregar logs brutos de eventos ou juntar muitas tabelas.
Maneiras práticas de manter leituras vivas sem piorar a carga:
- Use tamanhos de página menores e remova o "mostrar tudo"
- Substitua ordenações complexas por uma ordem padrão (por exemplo, "mais recentes primeiro")
- Adie leituras não essenciais como analytics, recomendações e gráficos de atividade
- Prefira resumos em cache a históricos brutos
- Aceite dados levemente desatualizados se isso mantiver páginas centrais responsivas
Um exemplo concreto: em um incidente de CRM, mantenha Ver contato, Ver status do negócio e Ver última nota funcionando. Oculte temporariamente Busca Avançada, Gráfico de Receita e Timeline completa de e-mails, e mostre uma nota avisando que os dados podem ter alguns minutos de atraso.
Crie um Interruptor Global
Gere um app em Go e PostgreSQL e adicione um único switch global READ_ONLY.
Quando você entra em modo somente leitura durante incidentes, a maior surpresa muitas vezes não é a UI. São os escritores invisíveis: jobs em background, sincronizações agendadas, ações administrativas em massa e integrações de terceiros que continuam batendo no banco.
Comece parando trabalhos em background que criam ou atualizam registros. Culpados comuns são importações, syncs noturnos, envio de e-mails que gravam logs de entrega, rollups de analytics e loops de retry que tentam repetir a mesma atualização falha. Pausar isso reduz a pressão rapidamente e evita uma segunda onda de carga.
Um padrão seguro é pausar ou limitar jobs pesados de escrita e quaisquer consumidores de filas que persistam resultados, desabilitar ações administrativas em massa (atualizações massivas, exclusões em lote, reindexações grandes) e falhar rápido em endpoints de escrita com uma resposta temporária clara em vez de timeout.
Para webhooks e integrações, clareza vence otimismo. Se você aceita um webhook mas não consegue processá-lo, você criará desencontros e churn de suporte. Quando gravações estão pausadas, retorne uma falha temporária que diga ao remetente para tentar depois e garanta que sua mensagem na UI combine com o que acontece nos bastidores.
Cuidado com o "enfileirar para depois". Parece amigável, mas pode criar um backlog que inunda o sistema quando você reativa as gravações. Só bufferize gravações de usuário se você puder garantir idempotência, limite o tamanho da fila e mostre ao usuário o estado verdadeiro (pendente vs salvo).
Por fim, audite escritores em massa ocultos no seu próprio produto. Se uma automação pode atualizar milhares de linhas, ela deve ser forçada a desligar no modo somente leitura, mesmo que o resto do app ainda carregue.
Erros comuns que pioram incidentes
A forma mais rápida de agravar um incidente é tratar o modo somente leitura como uma mudança cosmética. Se você apenas desabilitar botões na UI, pessoas ainda vão escrever via APIs, abas antigas, apps móveis e jobs em background. O banco continua sob pressão, e você ainda perde confiança porque usuários veem "salvo" em um lugar e mudanças faltando em outro.
Um modo somente leitura real precisa de uma regra clara: o servidor recusa gravações, sempre, para todo cliente.
Erros para evitar
Esses padrões aparecem frequentemente durante sobrecarga do banco:
- Bloquear edições só na UI enquanto o backend ainda aceita POST, PUT, PATCH e DELETE
- Esquecer caminhos ocultos: painéis admin, ferramentas internas, endpoints de importação e APIs públicas usadas por integrações
- Deixar o sistema oscilar entre normal e somente leitura a cada minuto
- Mostrar mensagens vagas como "Algo deu errado"
- Permitir gravações parciais que deixam dados inconsistentes
Como evitá-los
Faça o sistema se comportar de forma previsível. Aplique um único interruptor server-side que rejeite gravações com uma resposta clara. Adicione um cooldown para que, depois de entrar em somente leitura, você permaneça por um tempo definido (por exemplo, 10 a 15 minutos) a menos que um operador mude isso.
Seja rigoroso com integridade de dados. Se uma gravação não puder completar totalmente, falhe a operação inteira e diga ao usuário o que fazer a seguir. Uma mensagem simples como "Modo somente leitura: visualização funciona, alterações estão pausadas. Tente novamente mais tarde." reduz tentativas repetidas.
Verificações rápidas antes e durante um incidente
O modo somente leitura durante incidentes só ajuda se for fácil de ativar e se comportar igual em todo lugar. Antes de surgir problema, certifique-se de que existe um único toggle (feature flag, config, switch admin) que o on-call pode habilitar em segundos, sem deploy.
Quando suspeitar de sobrecarga do banco, faça uma checagem rápida que confirme o básico:
- Acione o toggle em um ambiente seguro e confirme que tem efeito imediato
- Execute algumas ações de escrita (salvar, excluir, importar) e confirme que todo endpoint de gravação retorna a mesma resposta bloqueada e código de status
- Verifique se o texto do banner está pronto, curto e visível nas telas que as pessoas mais usam
- Carregue suas 3 páginas principais (por exemplo: login, dashboard, visualização de registro) e confirme que ainda rendem sob estresse
- Garanta que o suporte tem um roteiro de um parágrafo explicando o que funciona, o que está pausado e onde acompanhar atualizações
Durante o incidente, mantenha uma pessoa focada em verificar a experiência do usuário, não só dashboards. Uma checagem rápida em uma janela anônima detecta problemas como banners ocultos, formulários quebrados ou spinners infinitos que geram tráfego de refresh extra.
Planeje a saída antes de ligar. Decida o que significa "saudável" (latência, taxa de erros, lag de replicação) e faça uma verificação curta após reativar: crie um registro de teste, edite-o e confirme que contagens e atividade recente estão corretas.
Exemplo de incidente: manter um CRM utilizável enquanto bloqueia edições
Gerar UI e Guardas de Backend
Descreva suas regras de somente leitura no chat e gere a interface e as proteções do servidor juntas.
São 10:20. Seu CRM está lento e a CPU do banco está no máximo. Chamados de suporte começam a chegar: usuários não conseguem salvar edições em contatos e negócios. Mas a equipe ainda precisa consultar telefones, ver estágios de negócio e ler as últimas notas antes de ligações.
Você escolhe uma regra simples: congelar tudo que escreve, manter as leituras mais valiosas. Na prática, pesquisa de contatos, página de detalhe de contato e visão do pipeline de negócios ficam disponíveis. Editar um contato, criar um novo negócio, adicionar notas e importações em massa são bloqueados.
Na UI, a mudança deve ser óbvia e calma. Nas telas de edição, o botão Salvar é desabilitado e o formulário fica visível para que as pessoas possam copiar o que digitavam. Um banner no topo diz: "O modo somente leitura está ativado devido a alta carga. Visualização disponível. Alterações estão pausadas. Por favor, tente novamente mais tarde." Se um usuário ainda disparar uma gravação (por exemplo via API), retorne uma mensagem clara e evite retries automáticos que ataquem o banco.
Operacionalmente, mantenha o fluxo curto e repetível. Ative o modo somente leitura e verifique que todos os endpoints de gravação o respeitam. Pause jobs em background que escrevem (syncs, importações, logs de e-mail, backfills de analytics). Regule ou pause webhooks e integrações que criam atualizações. Monitore carga do banco, taxa de erros e consultas lentas. Publique uma atualização de status com o que está afetado (edições) e o que ainda funciona (pesquisa e visualizações).
A recuperação não é só desativar o interruptor. Reative gravações gradualmente, verifique logs de erro por salvamentos falhos e fique atento a uma tempestade de gravações vindas de jobs enfileirados. Depois comunique claramente: "O modo somente leitura foi desativado. Salvamentos foram restaurados. Se você tentou salvar entre 10:20 e 10:55, por favor verifique suas últimas alterações."
Próximos passos: torne o modo somente leitura parte do seu playbook
O modo somente leitura durante incidentes funciona melhor quando é chato e repetível. O objetivo é seguir um roteiro curto com donos e verificações claras.
Construa um playbook pequeno e utilizável
Mantenha em uma página. Inclua seus gatilhos (os poucos sinais que justificam mudar para somente leitura), o interruptor exato que você aciona e como confirmar que gravações estão bloqueadas, uma lista curta de leituras chave que devem continuar funcionando, papéis claros (quem aciona, quem monitora métricas, quem lida com suporte) e critérios de saída (o que deve ser verdade antes de reativar gravações e como drenar backlogs).
Prepare o texto da UI antes de precisar
Escreva e aprove o texto agora para não discutir a redação durante um outage. Um conjunto simples geralmente cobre a maioria dos casos:
- Banner: "Estamos em modo somente leitura enquanto restauramos o desempenho. Você pode ver dados, mas mudanças estão temporariamente desabilitadas."
- Em ações bloqueadas: "O salvamento está pausado no momento. Suas alterações não foram aplicadas. Por favor, tente novamente em alguns minutos."
- Detalhe de status: "Última atualização às HH:MM. Próxima atualização em 10 minutos."
Pratique a alternância em staging e cronometre-a. Garanta que suporte e on-call encontrem o toggle rapidamente e que os logs mostrem claramente gravações bloqueadas. Após cada incidente, reveja quais leituras foram realmente críticas, quais eram opcionais e quais criaram carga acidentalmente, então atualize a checklist.
Se você constrói produtos com Koder.ai (koder.ai), pode ser útil tratar o modo somente leitura como um toggle de primeira classe na sua app gerada, assim a UI e as proteções server-side permanecem consistentes quando você mais precisa delas.