Por que IDs de correlação importam para o suporte
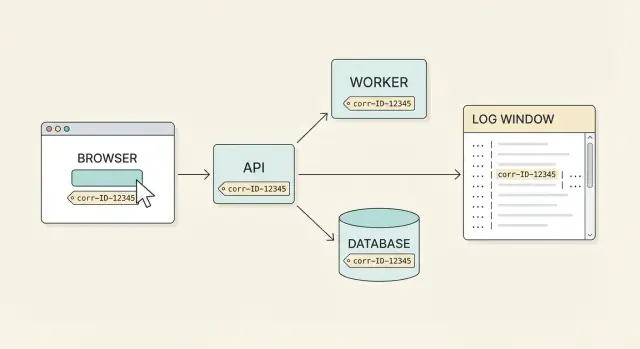
O suporte quase nunca recebe um relato de bug limpo. Um usuário diz: "Cliquei em Pagar e falhou", mas esse único clique pode envolver o navegador, um gateway de API, um serviço de pagamentos, um banco de dados e um job em background. Cada parte registra sua própria fatia da história em momentos diferentes, em máquinas diferentes. Sem um rótulo compartilhado, você acaba adivinhando quais linhas de log pertencem juntas.
Um ID de correlação é esse rótulo compartilhado. É um único ID anexado a uma ação do usuário (ou a um fluxo lógico) e carregado por toda requisição, retry e salto entre serviços. Com cobertura ponta a ponta, você pode começar por uma reclamação do usuário e puxar a linha do tempo completa entre sistemas.
As pessoas frequentemente confundem alguns IDs parecidos. Aqui está a separação limpa:
- Correlation ID: agrupa tudo relacionado a uma ação (por exemplo, "Salvar configurações").
- Request ID: identifica uma única requisição HTTP. Retries criam novos request IDs.
- Trace ID: usado por ferramentas de tracing distribuído; objetivo similar, geralmente gerado por bibliotecas de tracing.
- Session ID: identifica uma sessão do usuário ao longo de muitas ações; é amplo demais para depurar um único incidente.
O que funciona bem é simples: um usuário reporta um problema, você pede o correlation ID mostrado na UI (ou encontrado numa tela de suporte), e qualquer pessoa da equipe consegue achar a história completa em minutos. Você vê a requisição do frontend, a resposta da API, os passos do backend e o resultado do banco de dados, tudo conectado.
Decida suas convenções de correlation ID
Antes de gerar qualquer coisa, concorde com algumas regras. Se cada time escolhe um nome de header ou campo de log diferente, o suporte ainda ficará adivinhando.
Comece com um nome canônico e use-o em todo lugar. Uma escolha comum é um cabeçalho HTTP como X-Correlation-Id, mais um campo de log estruturado como correlation_id. Escolha uma grafia e capitalização, documente e garanta que seu reverse proxy ou gateway não renomeie nem descarte o cabeçalho.
Escolha um formato fácil de criar e seguro para compartilhar em tickets e chats. UUIDs funcionam bem porque são únicos e sem graça. Mantenha o ID curto o suficiente para copiar, mas não tão curto que corra risco de colisões. Consistência vence esperteza.
Decida também onde o ID precisa aparecer para que humanos realmente possam usá‑lo. Na prática, isso significa que ele deve estar presente em requisições, logs e saídas de erro, e ser pesquisável na ferramenta que sua equipe usa.
Defina quanto tempo um ID deve durar. Um bom padrão é uma ação do usuário, tipo "clicou em Pagar" ou "salvou perfil". Para workflows mais longos que atravessam serviços e filas, mantenha o mesmo ID até o fim do fluxo, então comece um novo para a próxima ação. Evite "um ID para a sessão inteira", porque as buscas ficam barulhentas rapidamente.
Uma regra rígida: nunca coloque dados pessoais no ID. Nada de emails, telefones, IDs de usuário ou números de pedido. Se precisar desse contexto, registre em campos separados com os controles de privacidade adequados.
Gere o ID no frontend (abordagem prática)
O lugar mais fácil para iniciar um correlation ID é no momento em que o usuário começa a ação que você quer rastrear: clicar em "Salvar", enviar um formulário ou acionar um fluxo que dispare múltiplas requisições. Se você esperar o backend gerá‑lo, frequentemente perde a primeira parte da história (erros de UI, retries, requisições canceladas).
Use um formato aleatório e único. UUID v4 é uma escolha comum porque é fácil de gerar e improvável de colidir. Mantenha‑o opaco (sem nomes de usuário, emails ou timestamps) para não vazar dados pessoais em headers e logs.
Crie e mantenha o ID durante um workflow
Trate um "workflow" como uma ação do usuário que pode disparar múltiplas requisições: validar, subir arquivo, criar registro e então atualizar listas. Crie um ID quando o workflow começa e mantenha‑o até o fim (sucesso, falha ou cancelamento pelo usuário). Um padrão simples é armazená‑lo no estado do componente ou em um objeto de contexto leve para requisições.
Se o usuário iniciar a mesma ação duas vezes, gere um novo correlation ID para a segunda tentativa. Isso permite que o suporte distinga "mesmo clique com retry" de "duas submissões separadas".
Anexe em toda requisição desse workflow
Adicione o ID a cada chamada de API disparada pelo workflow, normalmente via um header como X-Correlation-ID. Se você usa um cliente de API compartilhado (wrapper do fetch, instância Axios, etc.), passe o ID uma vez e deixe o cliente injetá‑lo em todas as chamadas.
const correlationId = crypto.randomUUID();
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
Se sua UI faz requisições de background não relacionadas à ação (polling, analytics, auto-refresh), não reutilize o workflow ID para essas. Mantenha os IDs de correlação focados para que um ID conte uma história só.
Uma vez que você gera o correlation ID no browser, o trabalho é simples: ele deve sair do frontend em toda requisição e chegar inalterado em cada fronteira de API. É aí que mais falha quando times adicionam novos endpoints, novos clientes ou middleware.
O padrão mais seguro é um cabeçalho HTTP em cada chamada (por exemplo, X-Correlation-Id). Cabeçalhos são fáceis de adicionar num único ponto (wrapper do fetch, interceptor do Axios, camada de rede mobile) e não exigem mudar payloads.
Se você tiver requisições cross-origin, garanta que sua API permita esse cabeçalho. Caso contrário, o navegador pode bloqueá‑lo silenciosamente e você vai achar que está enviando quando não está.
Se for preciso enviar o ID na query string ou no corpo da requisição (algumas ferramentas de terceiros ou uploads forçam isso), mantenha a consistência e documente. Escolha um nome de campo e use‑o sempre. Não misture correlationId, requestId e cid dependendo do endpoint.
Retries são outra armadilha comum. Um retry deve manter o mesmo correlation ID se for a mesma ação do usuário. Exemplo: o usuário clica em "Salvar", a rede cai, seu cliente tenta o POST de novo. O suporte deve ver uma trilha conectada, não três trilhas desconexas. Um novo clique do usuário (ou um novo job de background) deve ganhar um novo ID.
Para WebSockets, inclua o ID no envelope da mensagem, não só no handshake inicial. Uma conexão pode transportar muitas ações do usuário.
Se quiser um check rápido de confiabilidade, mantenha simples:
- Um helper cliente compartilha adiciona o header em cada requisição.
- Retries reutilizam o mesmo ID para a mesma ação.
- Qualquer fallback por body/query usa um nome de campo documentado.
- Mensagens WebSocket incluem um campo
correlationId explícito.
Configure o comportamento no entrypoint da API
Rastreie fluxos de trabalho entre serviços
Projete a propagação para APIs, workers e filas sem quebrar a cadeia de correlação.
Sua borda de API (gateway, load balancer ou o primeiro serviço que recebe tráfego) é onde os correlation IDs ou se tornam confiáveis ou viram adivinhação. Trate esse ponto como fonte da verdade.
Aceite um ID recebido se o cliente enviar, mas não presuma que ele sempre estará presente. Se estiver faltando, gere um novo imediatamente e use‑o pelo resto da requisição. Isso mantém as coisas funcionando mesmo quando alguns clientes são antigos ou mal configurados.
Faça validação leve para que valores ruins não poluam seus logs. Seja permissivo: verifique tamanho e caracteres permitidos, mas evite formatos rígidos que rejeitem tráfego real. Por exemplo, permita 16–64 caracteres e letras, números, traço e underscore. Se o valor falhar na validação, substitua por um ID novo e continue.
Torne o ID visível ao chamador. Sempre retorne no header da resposta e inclua no corpo de erros. Assim um usuário pode copiá‑lo da UI, ou um agente de suporte pode pedi‑lo e encontrar a trilha exata de logs.
Uma política prática na borda é:
- Leia
X-Correlation-ID (ou o header escolhido) da requisição.
- Se ausente ou inválido, crie um novo ID e anexe ao contexto da requisição.
- Adicione
X-Correlation-ID a todas as respostas, inclusive erros.
- Ao retornar erros em JSON, repita o ID no payload.
Exemplo de payload de erro (o que suporte deve ver em tickets e screenshots):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
Propague o ID pelos serviços backend
Depois que uma requisição chega ao backend, trate o correlation ID como parte do contexto da requisição, não algo guardado numa variável global. Globais quebram quando você atende duas requisições ao mesmo tempo, ou quando trabalho assíncrono continua após a resposta.
Uma regra que escala: toda função que pode logar ou chamar outro serviço deve receber o contexto que contém o ID. Em serviços Go, isso normalmente significa passar context.Context por handlers, lógica de negócio e código cliente.
Quando o Serviço A chama o Serviço B, copie o mesmo ID na requisição de saída. Não gere um novo no meio do caminho a menos que você também guarde o original como um campo separado (por exemplo parent_correlation_id). Se você mudar IDs, o suporte perde o fio único que conecta a história.
A propagação costuma ser esquecida em alguns lugares previsíveis: jobs em background iniciados durante a requisição, retries dentro de bibliotecas cliente, webhooks acionados depois e chamadas fan‑out. Qualquer mensagem assíncrona (fila/job) deve carregar o ID, e qualquer lógica de retry deve preservá‑lo.
Os logs devem ser estruturados com um nome de campo estável como correlation_id. Escolha uma grafia e mantenha em todo lugar. Evite misturar requestId, req_id e traceId a menos que você defina um mapeamento claro.
Se possível, inclua o ID também na visibilidade do banco de dados. Uma abordagem prática é adicioná‑lo em comentários de query ou metadata de sessão para que logs de queries lentas o mostrem. Quando alguém relata "o botão Salvar travou por 10 segundos", o suporte pode buscar correlation_id=abc123 e ver o log da API, a chamada ao serviço a jusante e a única declaração SQL lenta que causou o atraso.
Inclua o ID em logs que humanos possam usar
Um ID de correlação só ajuda se as pessoas conseguirem encontrá‑lo e segui‑lo. Faça dele um campo de log de primeira classe (não enterrado dentro de uma string de mensagem) e mantenha o restante da entrada de log consistente entre serviços.
Campos de log que tornam o ID utilizável
Associe o correlation ID a um pequeno conjunto de campos que respondam: quando, onde, o quê e quem (de forma segura para o usuário). Para a maioria das equipes, isso significa:
timestamp (com fuso horário)service e env (api, worker, prod, staging)route (ou nome da operação) e methodstatus e duration_ms- um identificador seguro do usuário (por exemplo
account_id ou um id hash, não um email)
Com isso, o suporte pode buscar por ID, confirmar que está olhando a requisição certa e ver qual serviço a tratou.
O que logar no início, sucesso e falha
Mire em algumas breadcrumbs fortes por requisição, não numa transcrição completa.
- Start: correlation ID, rota, identificador seguro do usuário e entradas chave (resumidas).
- Success: correlation ID, status, duração e um resultado curto (por exemplo
rows=12).
- Failure: correlation ID, tipo de erro, contexto seguro e onde aconteceu (handler, dependência).
Para evitar logs barulhentos, mantenha detalhes de debug desligados por padrão e promova apenas eventos que ajudam a responder "Onde falhou?". Se uma linha não ajuda a localizar o problema ou medir impacto, provavelmente não deveria estar em info-level.
Redação e redaction são tão importantes quanto a estrutura. Nunca coloque PII no correlation ID ou nos logs: sem emails, nomes, telefones, endereços completos ou tokens brutos. Se precisar identificar um usuário, registre um ID interno ou um hash unidirecional.
Exemplo: rastreando um relato do usuário da UI ao banco
Defina uma política confiável no entrypoint da API
Gere lógica no gateway que aceite, valide e ecoe automaticamente X-Correlation-ID.
Um usuário manda mensagem ao suporte: "A finalização falhou quando cliquei em Pagar." A melhor pergunta de seguimento é simples: "Você pode colar o correlation ID mostrado na tela de erro?" Eles respondem com cid=9f3c2b1f6a7a4c2f.
O suporte agora tem um identificador que conecta UI, API e trabalho no banco. O objetivo é que cada linha de log daquela ação carregue o mesmo ID.
O suporte busca logs por 9f3c2b1f6a7a4c2f e vê o fluxo:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
Daí, um engenheiro segue o mesmo ID para o próximo salto. O importante é que chamadas de serviço backend (e qualquer job em fila) também encaminhem o ID.
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
Agora o problema é concreto: o serviço de pagamentos expirou após 3 segundos e um registro de falha foi escrito. O engenheiro pode checar deploys recentes, confirmar se as configurações de timeout mudaram e ver se estão ocorrendo retries.
Para fechar o ciclo, faça quatro checagens:
- Corrija a causa (por exemplo, ajuste timeout e adicione um retry seguro).
- Garanta que erros visíveis ao usuário incluam o correlation ID.
- Observe novos logs com o mesmo padrão de erro e IDs diferentes.
- Confirme que o ID sobreviveu a todos os saltos (incluindo workers e mensagens em filas).
Erros comuns e como evitá‑los
A forma mais rápida de tornar IDs de correlação inúteis é quebrar a cadeia. A maioria das falhas vem de pequenas decisões que parecem inofensivas durante o desenvolvimento, mas atrapalham quando o suporte precisa de respostas.
Um erro clássico é gerar um ID novo em cada salto. Se o browser envia um ID, seu gateway de API deve mantê‑lo, não substituí‑lo. Se você precisa mesmo de um ID interno (para uma mensagem em fila ou job em background), mantenha o original como um campo parent para que a história ainda se conecte.
Outra lacuna comum é logging parcial. Equipes adicionam o ID na primeira API, mas esquecem em processos worker, jobs agendados ou na camada de acesso ao banco. O resultado é um beco sem saída: você vê a requisição entrando no sistema, mas não para onde ela foi.
Evite o problema da “confusão de nomes”
Mesmo quando o ID existe em todo lugar, pode ser difícil buscar se cada serviço usa um nome de campo ou formato diferente. Escolha um nome e mantenha‑o em frontend, APIs e logs (por exemplo, correlation_id). Também escolha um formato (frequentemente um UUID) e trate‑o como case‑sensitive para que copiar e colar funcione.
Não perca o ID quando algo der errado. Se uma API retornar 500 ou um erro de validação, inclua o correlation ID na resposta de erro (e idealmente num header de resposta também). Assim um usuário pode colar no chat de suporte e sua equipe rastrear o caminho completo imediatamente.
Um teste rápido: um membro do suporte pode começar com um ID e segui‑lo por todas as linhas de log envolvidas, incluindo falhas?
Checklist rápido para verificar cobertura ponta a ponta
Prototipe um fluxo de checkout com segurança
Modele retries e timeouts mantendo um ID por ação do usuário.
Use isto como um sanity check antes de dizer ao suporte para "apenas buscar nos logs". Isso só funciona quando cada salto segue as mesmas regras.
Verificações obrigatórias
- Você tem um formato de ID e um nome de header únicos, usados em todo lugar (frontend, gateway, APIs, workers).
- O frontend cria (ou recebe) o ID no início da ação do usuário e o mantém estável até o fim dessa ação.
- O ponto de entrada da API cria um ID se estiver faltando e sempre o retorna em headers de resposta.
- Cada serviço backend inclui
correlation_id nos logs relacionados a requisições como campo estruturado.
- O on‑call consegue colar um ID na busca de logs e ver o caminho completo em minutos: requisição de borda, auth, chamadas de serviço, operação no banco e retries.
Se alguma verificação falhar, conserte assim
Escolha a menor mudança que mantenha a cadeia ininterrupta.
- Se IDs mudam no meio do caminho, pare de gerar novos IDs dentro de serviços internos. Mantenha o
correlation_id original e adicione um span_id separado se precisar de mais detalhes.
- Se faltam campos nos logs, adicione middleware de logging para que engenheiros não tenham que lembrar de incluí‑lo.
- Se o suporte não consegue obter o ID, garanta que a UI o mostre nas telas de erro e que o gateway o ecoe em todas as respostas.
Um teste rápido que pega lacunas: abra devtools, acione uma ação, copie o correlation ID da primeira requisição, e então confirme que você vê o mesmo valor em cada requisição da API relacionada e em cada linha de log correspondente.
Próximos passos: incorpore no seu processo de build
IDs de correlação só ajudam quando todo mundo os usa do mesmo jeito, sempre. Trate o comportamento do correlation ID como parte obrigatória do que se entrega, não como um ajuste de logging opcional.
Adicione um pequeno passo de rastreabilidade à sua definição de pronto para qualquer endpoint ou ação de UI nova. Cubra como o ID é criado (ou reutilizado), onde vive durante o fluxo, qual header o carrega e o que cada serviço faz quando o header está ausente.
Uma checklist leve normalmente é suficiente:
- Frontend: gere ou reutilize um ID por ação do usuário e anexe a cada chamada de API dessa ação.
- API entrypoint: aceite o header, valide ou gere, então o ecoe na resposta.
- Backend: passe para serviços e jobs a jusante e inclua nos logs.
- Logging: mantenha o nome do campo consistente (por exemplo,
correlation_id) entre apps e serviços.
- Revisões: rejeite PRs que adicionem endpoints sem testes provando que o ID aparece nos logs.
O suporte também precisa de um script simples para que o debug seja rápido e repetível. Decida onde o ID aparece para os usuários (por exemplo, um botão "Copiar ID de debug" em diálogos de erro) e escreva o que o suporte deve pedir e onde pesquisar.
Antes de depender disso em produção, execute um fluxo em staging que reproduza o uso real: clique num botão, cause um erro de validação e então complete a ação. Confirme que você consegue seguir o mesmo ID da requisição do navegador, pelos logs da API, em qualquer worker em background e até os logs de chamadas ao banco se você os gravar.
Se você está construindo apps no Koder.ai, ajuda registrar o header do correlation ID e convenções de logging no Planning Mode para que frontends React gerados e serviços Go comecem consistentes por padrão.