16 de jan. de 2026·8 min
Fluxos centrados em documentos: modelo de dados e padrões de UI
Fluxos de trabalho centrados em documentos com modelos de dados e padrões de UI práticos para versões, pré-visualizações, metadados e estados de status claros.
Fluxos de trabalho centrados em documentos com modelos de dados e padrões de UI práticos para versões, pré-visualizações, metadados e estados de status claros.
Um app é centrado em documento quando o próprio documento é o produto que os usuários criam, revisam e utilizam. A experiência é construída em torno de arquivos como PDFs, imagens, digitalizações e recibos, não em torno de um formulário onde o arquivo é apenas um anexo.
Em fluxos centrados em documento, as pessoas fazem trabalho real dentro do documento: abrem, verificam o que mudou, adicionam contexto e decidem os próximos passos. Se o documento não for confiável, o app deixa de ser útil.
A maioria dos apps centrados em documento precisa de algumas telas essenciais desde o início:
Os problemas aparecem rápido. Usuários fazem upload do mesmo recibo duas vezes. Alguém edita um PDF e reenvia sem explicar por quê. Uma digitalização não tem data, fornecedor ou dono. Semanas depois, ninguém sabe qual versão foi aprovada ou em que decisão ela se baseou.
Um bom app centrado em documento parece rápido e confiável. Os usuários devem conseguir responder a estas perguntas em segundos:
Essa clareza vem de definições. Antes de construir telas, decida o que “versão”, “pré-visualização”, “metadados” e “status” significam no seu app. Se esses termos estiverem vagos, você terá duplicatas, histórico confuso e fluxos de revisão que não refletem o trabalho real.
A UI costuma parecer simples (uma lista, um visualizador, alguns botões), mas o modelo de dados carrega o peso. Se os objetos centrais estiverem corretos, histórico de auditoria, pré-visualizações rápidas e aprovações confiáveis ficam muito mais fáceis.
Comece separando o “registro do documento” do “conteúdo do arquivo”. O registro é sobre o que os usuários falam (Fatura da ACME, recibo de táxi). O conteúdo são os bytes (PDF, JPG) que podem ser substituídos, reprocessados ou movidos sem mudar o significado do documento dentro do app.
Um conjunto prático de objetos para modelar:
Decida o que recebe um ID que nunca muda. Uma regra útil é: o ID do Documento vive para sempre, enquanto Files e Previews podem ser regenerados. Versões também precisam de IDs estáveis, porque as pessoas referenciam “como estava ontem” e você precisará de um rastro de auditoria.
Modele as relações explicitamente. Um Documento tem muitas Versões. Cada Versão pode ter múltiplos Previews (diferentes tamanhos ou formatos). Isso mantém as telas de lista rápidas porque elas podem carregar dados leves de preview, enquanto as telas de detalhe carregam o arquivo completo só quando necessário.
Exemplo: um usuário faz upload de uma foto amarrotada de um recibo. Você cria um Documento, armazena o File original, gera um Preview em thumbnail e cria a Versão 1. Depois, o usuário envia uma digitalização mais nítida. Isso vira a Versão 2, sem quebrar comentários, aprovações ou buscas vinculadas ao Documento.
As pessoas esperam que um documento mude ao longo do tempo sem “se transformar” em outro item. A forma mais simples de entregar isso é separar identidade (Documento) de conteúdo (Version e Files).
Comece com um document_id estável que nunca muda. Mesmo que o usuário reenvie o mesmo PDF, substitua uma foto borrada ou envie uma digitalização corrigida, deve continuar sendo o mesmo registro de documento. Comentários, atribuições e logs de auditoria se ligam bem a um ID duradouro.
Trate toda mudança significativa como uma nova linha version. Cada versão deve capturar quem a criou e quando, além de ponteiros de armazenamento (chave do arquivo, checksum, tamanho, número de páginas) e artefatos derivados (texto OCR, imagens de preview) ligados exatamente àquele arquivo. Evite “editar no lugar”. Isso parece mais simples no começo, mas quebra a rastreabilidade e torna bugs difíceis de desfazer.
Para leituras rápidas, mantenha um current_version_id no documento. A maioria das telas só precisa “da mais recente”, assim você não precisa ordenar versões a cada carregamento. Quando precisar do histórico, carregue as versões separadamente e mostre uma linha do tempo limpa.
Rollbacks são apenas uma mudança de ponteiro. Em vez de excluir qualquer coisa, defina current_version_id de volta para uma versão anterior. É rápido, seguro e mantém o rastro de auditoria intacto.
Para manter o histórico compreensível, registre por que cada versão existe. Um pequeno campo consistente reason (mais uma nota opcional) evita uma linha do tempo cheia de atualizações misteriosas. Razões comuns incluem substituição por re-upload, limpeza de scan, correção de OCR, redação e edição por aprovação.
Exemplo: a equipe financeira envia uma foto do recibo, substitui por uma digitalização mais nítida e depois corrige o OCR para que o total fique legível. Cada etapa vira uma nova versão, mas o documento continua sendo um único item na caixa de entrada. Se a correção do OCR estiver errada, o rollback é um clique porque você só troca o current_version_id.
Em fluxos centrados em documento, a pré-visualização é frequentemente o principal ponto de interação. Se as pré-visualizações forem lentas ou instáveis, o app inteiro parece quebrado.
Trate a geração de preview como um job separado, não algo que a tela de upload espere terminar. Salve primeiro o arquivo original, devolva o controle ao usuário e então gere os previews em background. Isso mantém a UI responsiva e torna as tentativas de novo seguras.
Armazene múltiplos tamanhos de preview. Um único tamanho nunca serve para todas as telas: um thumbnail pequeno para listas, uma imagem média para visões divididas e imagens de página inteira para revisão detalhada (página a página para PDFs).
Acompanhe o estado do preview explicitamente para que a UI saiba sempre o que mostrar: pendente, pronto, falhou e precisa_retentativa. Mantenha os rótulos amigáveis ao usuário na interface, mas deixe os estados claros nos dados.
Para manter a renderização rápida, faça cache de valores derivados junto ao registro de preview em vez de recalculá-los a cada visualização. Campos comuns incluem contagem de páginas, largura/altura do preview, rotação (0/90/180/270) e uma “melhor página para thumbnail”.
Projete para arquivos lentos e bagunçados. Um PDF escaneado de 200 páginas ou uma foto de recibo amassada pode levar tempo para processar. Use carregamento progressivo: mostre a primeira página pronta assim que existir e preencha o resto depois.
Exemplo: um usuário faz upload de 30 fotos de recibos. A lista mostra thumbnails como “pendente” e cada cartão troca para “pronto” conforme o preview fica pronto. Se alguns falharem por imagem corrompida, eles permanecem visíveis com uma ação clara de tentar novamente em vez de desaparecerem ou bloquear todo o lote.
Metadados transformam um monte de arquivos em algo que você pode buscar, ordenar, revisar e aprovar. Eles ajudam a responder perguntas simples rápido: O que é isto? De quem veio? É válido? O que deve acontecer em seguida?
Uma forma prática de manter metadados limpos é separá-los pela origem:
Esses blocos evitam discussões futuras. Se um valor de total estiver errado, você consegue ver se veio do OCR ou de uma edição humana.
Para recibos e faturas, um pequeno conjunto de campos compensa se você os usar de forma consistente (mesmo nome, mesmos formatos). Campos âncora comuns são fornecedor, data, total, moeda e document_number. Mantenha-os opcionais a princípio. Pessoas enviam scans parciais e fotos borradas, e bloquear o progresso porque um campo falta atrasa todo o fluxo.
Trate valores desconhecidos como cidadãos de primeira classe. Use estados explícitos como null/unknown, além de um motivo quando útil (página faltando, ilegível, não aplicável). Isso permite que o documento avance enquanto mostra aos revisores o que precisa de atenção.
Também armazene proveniência e confiança para campos extraídos. A fonte pode ser usuário, OCR, importação ou API. A confiança pode ser um score 0-1 ou uma categoria como alta/média/baixa. Se o OCR leu “$18.70” com baixa confiança porque o último dígito está borrado, a UI pode destacar e pedir confirmação rápida.
Documentos multi-página precisam de uma decisão extra: o que pertence ao documento inteiro versus a uma única página. Totais e fornecedor geralmente pertencem ao documento. Notas por página, redações, rotação e classificação por página costumam pertencer ao nível da página.
Status responde a uma pergunta: “Em que etapa está este documento no processo?” Mantenha-os pequenos e sem firulas. Se você adicionar um novo status cada vez que alguém pedir, vai acabar com filtros que ninguém confia.
Um conjunto prático de estados de negócio que mapeia decisões reais:
Mantenha “processando” fora do status de negócio. OCR em execução e geração de preview descrevem o que o sistema está fazendo, não o que uma pessoa deve fazer em seguida. Armazene esses estados como estados de processamento separados.
Separe também atribuição de status (assignee_id, team_id, due_date). Um documento pode estar Aprovado e ainda assim atribuído para acompanhamento, ou Precisa de revisão sem dono ainda.
Registre histórico de status, não apenas o valor atual. Um log simples como (from_status, to_status, changed_at, changed_by, reason) ajuda muito quando alguém pergunta “Quem rejeitou este recibo e por quê?”.
Por fim, decida quais ações são permitidas em cada status. Mantenha as regras simples: Importado pode passar para Precisa de revisão; Aprovado é somente leitura a menos que uma nova versão seja criada; Rejeitado pode ser reaberto mas deve manter o motivo anterior.
A maior parte do tempo é gasta examinando uma lista, abrindo um item, corrigindo alguns campos e seguindo em frente. Uma boa UI torna esses passos rápidos e previsíveis.
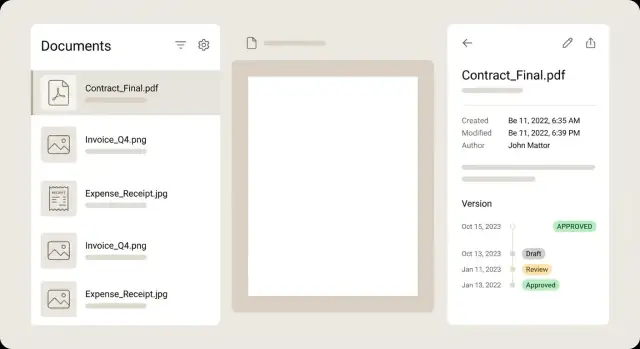
Para a lista de documentos, trate cada linha como um resumo para que o usuário decida sem abrir todos os arquivos. Uma linha forte mostra uma miniatura pequena, um título claro, alguns campos-chave (fornecedor, data, total), um badge de status e um aviso sutil quando algo precisa de atenção.
Mantenha a visualização de detalhe calma e escaneável. Um layout comum é pré-visualização à esquerda e metadados à direita, com controles de edição ao lado de cada campo. Usuários devem conseguir dar zoom, rodar e navegar páginas sem perder a posição no formulário. Se um campo foi extraído por OCR, mostre uma pequena dica de confiança e, idealmente, destaque a área de origem na pré-visualização quando o campo estiver em foco.
Versões funcionam melhor como uma linha do tempo, não um dropdown. Mostre quem mudou o quê e quando, e permita abrir qualquer versão antiga em modo somente leitura. Se oferecer comparação, foque em diferenças de metadados (valor alterado, fornecedor corrigido) em vez de forçar uma comparação pixel-a-pixel do PDF.
O modo de revisão deve otimizar velocidade. Um fluxo de triagem orientado por teclado costuma ser suficiente: ações rápidas de aprovar/rejeitar, correções rápidas para campos comuns e uma caixa de comentário curta para rejeições.
Estados vazios importam porque documentos frequentemente estão em processamento. Em vez de uma caixa em branco, explique o que está acontecendo: “Pré-visualização sendo gerada”, “OCR em execução” ou “Este tipo de arquivo não tem pré-visualização ainda.”
Um fluxo simples parece com “upload, checar, aprovar”. Por baixo, funciona melhor quando você separa o arquivo em si (versões e previews) do significado de negócio (metadados e status).
O usuário faz upload de um PDF, foto ou digitalização de recibo e o vê imediatamente em uma lista de inbox. Não espere o processamento terminar. Mostre nome do arquivo, hora do upload e um badge claro como “Processando”. Se você já souber a origem (importação por e-mail, câmera do celular, arrastar e soltar), mostre também.
No upload, crie um registro de Documento (a entidade de longa vida) e um registro de Versão (esse arquivo específico). Defina current_version_id para a nova versão. Salve preview_state = pending e extraction_state = pending para que a UI possa ser honesta sobre o que está pronto.
A visualização de detalhe deve abrir imediatamente, mas mostrar um visualizador placeholder e uma mensagem clara “Preparando pré-visualização” em vez de um frame quebrado.
Um job em background cria thumbnails e uma pré-visualização (imagens de página para PDFs, imagens redimensionadas para fotos). Outro job extrai metadados (fornecedor, data, total, moeda, tipo de documento). Quando cada job termina, atualize apenas seu estado e timestamps para que você possa tentar novamente falhas sem tocar em todo o resto.
Mantenha a UI compacta: mostre estado do preview, estado dos dados e destaque campos com baixa confiança.
Quando o preview estiver pronto, revisores corrigem campos, adicionam notas e movem o documento por estados de negócio como Importado -> Precisa de revisão -> Aprovado (ou Rejeitado). Registre quem mudou o quê e quando.
Se um revisor enviar um arquivo corrigido, ele vira uma nova Versão e o documento volta automaticamente para Precisa de revisão.
Exportações, sincronização contábil ou relatórios internos devem ler a partir de current_version_id e do snapshot de metadados aprovado, não da “última extração”. Isso evita que um re-upload meio processado altere números.
Fluxos centrados em documento falham por motivos entediantes: atalhos iniciais viram dor diária quando pessoas fazem uploads duplicados, corrigem erros ou perguntam “Quem alterou isto e quando?”
Tratar o nome do arquivo como identidade do documento é um erro clássico. Nomes mudam, usuários reenviarem, e câmeras geram duplicatas como IMG_0001. Dê a cada documento um ID estável e trate o nome do arquivo como um rótulo.
Sobrescrever o arquivo original quando alguém envia um substituto também causa problemas. Parece mais simples, mas você perde o rastro de auditoria e não consegue responder perguntas básicas depois (o que foi aprovado, o que foi editado, o que foi enviado). Mantenha o arquivo binário imutável e adicione um novo registro de versão.
Confusão de status cria bugs sutis. “OCR em execução” não é a mesma coisa que “Precisa de revisão”. Estados de processamento descrevem o que o sistema faz; status de negócio descrevem o que uma pessoa deve fazer a seguir. Quando esses conceitos se misturam, documentos acabam no bucket errado.
Decisões de UI também podem criar atrito. Se você bloquear a tela até que previews sejam gerados, pessoas percebem o app como lento mesmo quando o upload teve sucesso. Mostre o documento na hora com um placeholder claro e troque pelas thumbnails quando prontas.
Por fim, metadados se tornam não confiáveis quando você armazena valores sem proveniência. Se o total veio do OCR, diga isso. Mantenha timestamps.
Um checklist rápido:
Exemplo: em um app de recibos, um usuário reenvia uma foto mais nítida. Se você versionar, mantenha a imagem antiga, marque o OCR como reprocessando e mantenha Precisa de revisão até que um humano confirme o valor.
Fluxos centrados em documento parecem “prontos” só quando as pessoas confiam no que veem e conseguem se recuperar quando algo dá errado. Antes do lançamento, teste com documentos bagunçados e reais (recibos borrados, PDFs rotacionados, uploads repetidos).
Cinco checagens que pegam a maioria das surpresas:
Um teste de realidade: peça para alguém revisar três recibos semelhantes e faça com que uma mudança errada seja feita intencionalmente. Se ele conseguir identificar a versão atual, entender o status e corrigir o erro em menos de um minuto, você está perto.
O reembolso mensal de recibos é um exemplo claro de trabalho centrado em documento. Um funcionário envia recibos, depois dois revisores checam: um gerente e depois o financeiro. O recibo é o produto, então seu app vive ou morre pelo versionamento, previews, metadados e status claros.
Jamie envia uma foto de um recibo de táxi. Seu sistema cria o Documento #1842 com a Versão v1 (o arquivo original), um thumbnail e preview, e metadados como merchant, data, moeda, total e uma pontuação de confiança OCR. O documento começa como Importado e passa para Precisa de revisão quando preview e extração estiverem prontos.
Mais tarde, Jamie envia o mesmo recibo de novo por engano. Uma verificação de duplicatas (hash do arquivo mais comparação de merchant/data/total) pode mostrar uma escolha simples: “Parece duplicata do #1842. Anexar mesmo assim ou descartar?” Se ele anexar, armazene como outro File vinculado ao mesmo Documento para manter um único fio de revisão e um único status.
Durante a revisão, o gerente vê o preview, campos-chave e avisos. O OCR chutou o total como $18.00, mas a imagem mostra claramente $13.00. Jamie corrige o total. Não apague o histórico. Crie a Versão v2 com os campos atualizados, mantenha v1 inalterada e registre “Total corrigido por Jamie.”
Se quiser construir esse tipo de fluxo rapidamente, Koder.ai (koder.ai) pode ajudar a gerar a primeira versão do app a partir de um plano por chat, mas a mesma regra vale: defina os objetos e estados primeiro e deixe as telas seguirem.
Próximos passos práticos:
Um app centrado em documento trata o documento como o elemento principal com o qual os usuários trabalham, não como um anexo lateral. As pessoas precisam abri-lo, confiar no que veem, entender o que mudou e decidir os próximos passos com base nesse documento.
Comece com uma caixa de entrada/lista, uma visualização de detalhe do documento com pré-visualização rápida, uma área simples de ações de revisão (aprovar/rejeitar/solicitar alterações) e uma forma de exportar ou compartilhar. Essas quatro telas cobrem o ciclo comum de encontrar, abrir, decidir e repassar.
Modele um registro Document estável que nunca muda e armazene os bytes reais como objetos File separados. Depois, adicione Version como o snapshot que vincula um documento a um arquivo específico (e seus derivados). Essa separação mantém comentários, atribuições e histórico intactos mesmo quando o arquivo é substituído.
Trate cada mudança significativa como uma nova versão em vez de editar no lugar. Mantenha um current_version_id no documento para leituras rápidas do “último”, e registre a linha do tempo de versões antigas para auditoria e rollback. Isso evita confusão sobre o que foi aprovado e por quê.
Gere previews de forma assíncrona após salvar o arquivo original, para que uploads pareçam instantâneos e reprocessamentos sejam seguros. Acompanhe o estado do preview como pending/ready/failed para que a UI mostre o que está pronto, e armazene múltiplos tamanhos para que listas fiquem leves e as visões de detalhe nítidas.
Armazene metadados em três categorias: sistema (tamanho do arquivo, tipo), extraído (campos OCR e confiança) e inserido pelo usuário. Registre a proveniência para saber se um valor veio do OCR ou de uma pessoa, e evite bloquear o fluxo obrigando a preencher todos os campos.
Use um pequeno conjunto de statuses de negócio que descrevam o próximo passo humano, como Importado, Precisa de revisão, Aprovado, Rejeitado e Arquivado. Acompanhe processamento separadamente (preview/OCR em execução) para que documentos não fiquem “presos” em um status que mistura trabalho humano e máquina.
Guarde checksums de arquivo imutáveis e compare-os no upload; em seguida, faça uma segunda verificação usando campos-chave como fornecedor/data/total quando disponíveis. Quando suspeitar de duplicata, ofereça a opção clara de anexar ao mesmo thread do documento ou descartar, para não dividir o histórico de revisão.
Mantenha um log de histórico de status com quem mudou, quando e por quê, e mantenha versões acessíveis via uma linha do tempo. O rollback deve ser a alteração de um ponteiro para uma versão antiga, não uma exclusão, para recuperar rápido sem perder o rastro de auditoria.
Defina os objetos e estados primeiro, depois deixe a UI seguir essas definições. Se usar Koder.ai para gerar um app a partir de um plano por chat, seja explícito sobre Document/Version/File, estados de preview e extração, e regras de status, para que as telas geradas mapeiem corretamente para o comportamento real do fluxo.