29 de dez. de 2025·8 min
Ferramentas administrativas que evitam perda de dados: ações em lote mais seguras
Ferramentas administrativas que evitam perda de dados usam ações em lote seguras, confirmações claras, soft deletes, logs de auditoria e limites por função para evitar erros caros.
Onde a perda de dados acontece em ferramentas administrativas
Ferramentas internas de administração passam uma sensação de segurança porque “só a equipe” pode usá‑las. Essa confiança é justamente o que as torna de alto risco. As pessoas que as usam têm poder, trabalham rápido e frequentemente repetem a mesma ação várias vezes por dia. Um deslize pode afetar milhares de registros.
A maioria dos acidentes não vem de má intenção. São momentos de “ops”: um filtro amplo demais, um termo de busca que casou com mais itens do que o esperado, ou um menu que ficou no tenant errado. Outro clássico é o ambiente errado: alguém pensa que está em staging, mas está vendo produção porque a interface é quase igual.
Velocidade e repetição pioram a situação. Quando uma ferramenta é feita para mover rápido, os usuários desenvolvem memória muscular: clicar, confirmar, próximo. Se a tela demora, clicam duas vezes. Se uma ação em lote demora, abrem outra aba. Esses hábitos são normais, mas criam as condições para erros.
“Destruir dados” não é só apertar um botão de excluir. Na prática pode significar:
- Excluir registros (incluindo exclusões em cascata)
- Sobrescrever campos (por exemplo, definir status como “fechado” para o conjunto errado)
- Desvincular relacionamentos (desvincular um usuário de uma conta, remover permissões)
- Purgar histórico (limpar logs, apagar mensagens, truncar tabelas)
- Exportações ou sincronizações irreversíveis (enviar dados errados para outro sistema)
Para equipes que constroem ferramentas administrativas que evitam perda de dados, “suficientemente seguro” deve ser um acordo claro, não uma sensação. Uma definição simples: um operador apressado deve conseguir recuperar-se de um erro comum sem ajuda de engenharia, e uma ação raramente irreversível deve exigir atrito extra, prova clara de intenção e um registro que possa ser auditado depois.
Mesmo se você construir apps rapidamente em uma plataforma como Koder.ai, esses riscos continuam os mesmos. A diferença é se você projeta os guardrails desde o primeiro dia ou espera o primeiro incidente para aprender.
Comece com um mapa de riscos simples
Antes de mudar qualquer UI, fique claro sobre o que realmente pode dar errado. Um mapa de riscos é uma lista curta de ações que podem causar dano real, mais as regras que devem cercá‑las. Essa etapa é o que separa ferramentas administrativas que evitam perda de dados das que só parecem cuidadosas.
Comece escrevendo suas ações mais perigosas. Normalmente não são as edições do dia a dia. São operações que mudam muitos registros rápido ou que tocam dados sensíveis.
Um primeiro rascunho útil é:
- Excluir, mesclar, fechar ou desativar contas permanentemente
- Reatribuir propriedade (clientes, faturas, tickets, leads)
- Importações e atualizações em massa (CSV, jobs de API, migrações)
- Ações de cobrança (reembolsos, créditos, cancelamentos)
- Mudanças de permissão (papéis, acesso a PII)
Em seguida, marque cada ação como reversível ou irreversível. Seja rigoroso. Se só for possível reverter a partir de um backup, trate como irreversível para o operador que está fazendo o trabalho.
Depois decida o que deve ser protegido por política, não apenas por design. Regras legais e de privacidade frequentemente se aplicam a PII (nomes, e‑mails, endereços), registros de cobrança e logs de auditoria. Mesmo que a ferramenta possa tecnicamente apagar algo, sua política pode exigir retenção ou revisão por duas pessoas.
Separe operações rotineiras de operações excepcionais. Trabalho rotineiro deve ser rápido e seguro (pequenas mudanças, undo claro). Trabalho excepcional deve ser mais lento de propósito (checks extras, aprovações, limites mais rígidos).
Por fim, concordem em termos simples de “blast radius” para que todos falem a mesma língua: um registro, muitos registros, todos os registros. Por exemplo, “reatribuir este cliente” é diferente de “reatribuir todos os clientes deste vendedor”. Esse rótulo guiará defaults, confirmações e limites de função.
Exemplo: em um projeto de vibe‑coding no Koder.ai, você pode marcar “importação em massa de usuários” como muitos‑registros, reversível somente se você registrar todo ID criado, e protegido por política porque toca PII.
Padrões para ações em lote mais seguras
Ações em lote são onde boas ferramentas administrativas viram riscos. Se você está construindo ferramentas administrativas que evitam perda de dados, trate todo botão “aplicar em muitos” como uma ferramenta potente: útil, mas projetada para evitar deslizes.
Um bom default é: pré‑visualizar primeiro, executar depois. Em vez de executar na hora, mostre o que mudaria e deixe o operador confirmar apenas depois de ver o escopo.
Deixe o escopo explícito e difícil de ser entendido erroneamente. Não aceite “todos” como uma ideia vaga. Force o operador a definir filtros como tenant, status e um intervalo de datas, e então mostre o número exato de registros que batem. Uma pequena lista de amostra (mesmo 10 itens) ajuda as pessoas a notar erros como “região errada” ou “arquivados incluídos”.
Um padrão prático que funciona bem:
- Comece com uma tela de dry run que mostre contagem, filtros e uma amostra curta de registros afetados
- Exija uma escolha explícita de escopo (por exemplo: “Apenas clientes Ativos no Tenant A, criados antes de 2024-01-01”)
- Limite cada execução (por exemplo 1.000 registros) e peça para rodar novamente para o próximo lote
- Throttle as mudanças para que um clique errado não sobrecarregue o banco de dados ou sistemas a jusante
- Execute como um job enfileirado com progresso, logs e uma opção clara de cancelamento
Jobs enfileirados vencem o “disparar e esquecer” porque criam trilha, e dão ao operador chance de parar a ação quando notar algo errado aos 5% completados.
Exemplo: um operador quer desativar em massa contas de usuário após um pico de fraude. A pré‑visualização mostra 842 contas, mas a amostra inclui clientes VIP. Essa pista pequena frequentemente evita o erro real: um filtro faltando “fraud_flag = true”.
Se você está montando um console interno rápido (mesmo com uma plataforma de build‑by‑chat como Koder.ai), incorpore esses padrões cedo. Eles economizam mais tempo do que adicionam.
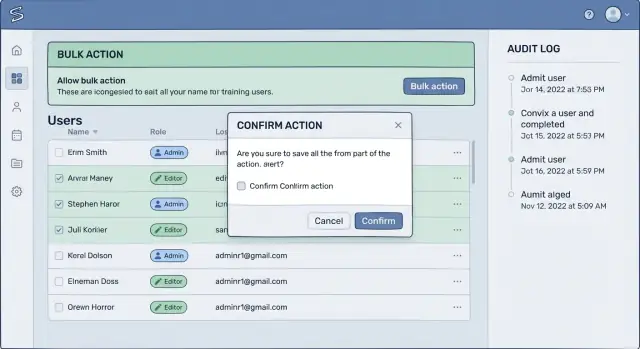
Fluxos de confirmação que as pessoas realmente leem
A maioria das confirmações falha porque é genérica demais. Se a tela diz “Tem certeza?”, as pessoas clicam no piloto automático. Uma confirmação que funciona usa as mesmas palavras que seu usuário usaria para explicar o resultado a um colega.
Substitua rótulos vagos como “Excluir” ou “Aplicar” pelo impacto real: “Desativar 38 contas”, “Remover acesso deste tenant” ou “Anular 12 faturas”. Essa é uma das melhorias mais simples em ferramentas administrativas que evitam perda de dados, porque transforma um clique reflexo em um momento de reconhecimento.
Faça o usuário confirmar o escopo
Um bom fluxo força uma checagem mental rápida: “É isso que eu quero, no conjunto certo de registros?” Coloque o escopo na confirmação, não apenas na página atrás dela. Inclua o nome do tenant ou workspace, a contagem de registros e quaisquer filtros como intervalo de datas ou status.
Por exemplo: “Fechar contas do Tenant: Acme Retail. Contagem: 38. Filtro: último login antes de 2024-01-01.” Se algum desses valores parecer errado, o usuário percebe antes do dano.
Quando a ação é realmente destrutiva, exija um ato pequeno e deliberado. Confirmações digitadas funcionam bem quando o custo de um erro é alto.
- Peça uma frase curta como DELETE 38 ACCOUNTS
- Ou peça para digitar o nome do tenant exatamente
- Ou exija reentrada da contagem mostrada na tela
Use dois passos apenas quando o impacto for alto
Confirmações em dois passos devem ser raras, senão os usuários passam a ignorá‑las. Reserve‑as para ações difíceis de recuperar, que cruzam tenants ou que envolvem dinheiro. O passo um confirma intenção e escopo. O passo dois confirma o momento, como “Executar agora” vs “Agendar”, ou exige uma aprovação de permissão superior.
Finalmente, evite “OK/Cancelar”. Botões devem dizer o que acontece: “Desativar contas” e “Voltar”. Isso reduz cliques errados e torna a decisão mais concreta.
Soft deletes, restaurações e regras de retenção
Preview before you run
Add a dry-run step that shows filters, record counts, and a sample before execution.
Soft delete é o padrão mais seguro para a maioria dos registros visíveis ao usuário: contas, pedidos, tickets, posts e até pagamentos. Em vez de remover a linha, marque como deletado e oculte das vistas normais. Esse é um dos padrões mais simples por trás de ferramentas administrativas que evitam perda de dados, porque erros tornam‑se reversíveis.
Uma política de soft delete precisa de uma janela de retenção clara e de propriedade definida. Decida por quanto tempo itens deletados ficam restauráveis (por exemplo, 30 ou 90 dias) e quem pode trazê‑los de volta. Vincule direitos de restauração a papéis, não a indivíduos, e trate restaurações como mudanças em produção.
Torne a restauração óbvia (e registrada)
Restaurar deve ser fácil de encontrar quando alguém olha para um registro deletado, não enterrado numa tela separada. Adicione um status visível como “Deletado”, mostre quando aconteceu e quem fez. Quando uma restauração ocorrer, registre‑a como um evento próprio, não como uma edição do delete original.
Uma forma rápida de definir suas regras de retenção é responder a estas perguntas:
- Qual é o período de retenção padrão por tipo de objeto?
- Qual papel pode restaurar, e eles precisam justificar a ação?
- O que acontece depois que o período de retenção expira?
- Quem pode estender a retenção por casos legais ou de cobrança?
- Como você trata pedidos de “apague meus dados”?
Casos extremos que quebram restaurações
Soft delete soa simples até que você restaure para um mundo que seguiu adiante. Restrições de unicidade podem colidir (um nome de usuário foi reutilizado), referências podem estar faltando (um registro pai foi excluído) e o histórico de cobrança precisa permanecer consistente mesmo se o usuário “sumiu”. Uma abordagem prática é manter livros-razão imutáveis (faturas, eventos de pagamento) separados dos dados de perfil do usuário, e restaurar relacionamentos com cautela, avisando claramente quando uma restauração completa não for possível.
Hard delete deve ser raro e explícito. Se permitir, faça parecer uma exceção, com um caminho de aprovação curto:
- Exigir um papel mais alto que o do soft delete
- Pedir confirmação digitada e uma justificativa
- Enfileirar a exclusão com um atraso (por exemplo, 24 horas)
- Notificar um responsável ou canal on‑call
- Manter um registro final de auditoria mesmo após remoção
Se você está construindo seu admin numa plataforma como Koder.ai, defina soft delete, restauração e retenção como ações de primeira classe desde o começo, para que sejam consistentes em todas as telas e fluxos gerados.
Auditabilidade: faça ações explicáveis depois
Acidentes acontecem em painéis administrativos, mas o dano real muitas vezes vem mais tarde: ninguém consegue responder o que mudou, quem fez e por quê. Se você quer ferramentas administrativas que evitam perda de dados, trate logs de auditoria como parte do produto, não como um apêndice para debugging.
Comece registrando ações de modo que um humano consiga ler. “Usuário 183 atualizou registro 992” não é suficiente quando um cliente está insatisfeito e a pessoa de plantão precisa consertar rápido. Bons logs capturam identidade, momento, escopo e intenção, além de detalhe suficiente para restaurar ou ao menos entender o impacto.
O que registrar (para ser útil depois)
Uma linha de base prática é:
- Quem fez (usuário, papel e info de impersonação se usada)
- O quê e onde (nome da ação, tenant/conta e tipos de objeto afetados)
- Quando e de onde (timestamp, fuso, IP ou ID de sessão/dispositivo)
- O que mudou (antes/depois para campos-chave, ou um diff para objetos maiores)
- Por que aconteceu (motivo em texto livre e um ID de ticket opcional)
Ações em massa merecem tratamento especial. Logue‑as como um único “job” com um resumo claro (quantos selecionados, quantos tiveram sucesso, quantos falharam) e também armazene resultados por item. Isso facilita responder “Reembolsamos 200 pedidos ou só 173?” sem cavar em mil entradas.
Torne logs fáceis de buscar: por usuário admin, tenant, tipo de ação e intervalo de tempo. Inclua filtros para “apenas jobs em lote” e “ações de alto risco” para que revisores detectem padrões.
Não force burocracia. Um campo de “motivo” curto que suporte templates (“Cliente solicitou fechamento”, “Investigação de fraude”) é preenchido com mais frequência que um formulário longo. Se houver um ticket de suporte, permita colar o ID.
Por fim, planeje acesso de leitura. Muitos usuários internos precisam ver logs, mas apenas um grupo pequeno deve ver campos sensíveis (como valores completos antes/depois). Separe “pode ver resumo de auditoria” de “pode ver detalhes” para reduzir exposição.
Limites e guardrails baseados em papéis
A maioria dos acidentes acontece porque permissões são amplas demais. Se todo mundo é efetivamente admin, um operador cansado pode causar dano permanente com um único clique. O objetivo é simples: tornar o caminho seguro o padrão, e fazer ações arriscadas exigirem intenção extra.
Projete papéis em torno de trabalhos reais, não de títulos. Um agente de suporte que responde tickets não precisa do mesmo acesso que alguém que gerencia regras de cobrança.
Construa papéis em torno de tarefas
Comece separando o que as pessoas podem ver do que podem mudar. Um conjunto prático de papéis internos poderia ser:
- Somente leitura: ver usuários, pedidos e logs
- Operador: editar perfis e resetar senhas
- Operador de cobrança: emitir reembolsos dentro de um limite
- Administrador de dados: mesclar registros e rodar correções em lote
- Admin de segurança: desativar contas e gerenciar papéis
Isso mantém o “excluir” fora do trabalho cotidiano e reduz o blast radius quando alguém erra.
Para as ações mais perigosas, adicione um modo elevado. Pense nisso como uma chave com tempo limitado. Para entrar no modo elevado, exija um passo mais forte (reautenticação, aprovação de gerente ou uma segunda pessoa) e faça a sessão cair automaticamente após 10 a 30 minutos.
Guardrails de ambiente também salvam equipes. A UI deve dificultar confundir staging com produção. Use pistas visuais chamativas, mostre o nome do ambiente em todos os cabeçalhos e desative ações destrutivas em não‑produção, a menos que você explicitamente as ative.
Finalmente, proteja tenants entre si. Em sistemas multitenant, mudanças cross‑tenant devem ser bloqueadas por padrão e só habilitadas para papéis específicos com uma troca explícita de tenant e confirmação clara na tela.
Se você está construindo sobre uma plataforma como Koder.ai, trate esses guardrails como recursos do produto, não como detalhes deixados por último. Ferramentas administrativas que evitam perda de dados são frequentemente apenas bom design de permissões mais alguns limitadores bem posicionados.
Um cenário realista: reembolsos em lote e fechamento de contas
Go live confidently
Deploy your internal tool when ready, with hosting and custom domains supported.
Um agente de suporte precisa lidar com uma falha de pagamento. O plano é simples: reembolsar pedidos afetados e depois fechar as contas que solicitaram cancelamento. É exatamente aí que ferramentas administrativas que evitam perda de dados justificam seu valor, porque o agente está prestes a rodar duas ações em lote de alto impacto em sequência.
O risco aparece num detalhe pequeno: o filtro. O agente seleciona “Pedidos criados nas últimas 24 horas” em vez de “Pedidos pagos durante a janela de falha”. Num dia movimentado isso pode puxar milhares de clientes normais, gerando reembolsos que eles não pediram. Se o próximo passo for “Fechar contas para pedidos reembolsados”, o dano se espalha rápido.
Antes da ferramenta executar qualquer coisa, a UI deve forçar uma pausa com uma pré‑visualização clara que combine com a forma como as pessoas pensam, não como o banco de dados pensa. Por exemplo, deve mostrar:
- Total de contas que serão fechadas (e quantas já estão fechadas)
- Valor total de reembolso, mais valores mínimos/máximos por reembolso
- Uma pequena amostra rolável de clientes afetados (nomes, e‑mails, IDs de pedido)
- Exceções e pulos (pagamentos falhados, já reembolsados, pedidos em disputa)
- O resumo exato do filtro em linguagem clara, com um botão óbvio “Editar filtro”
Depois adicione uma segunda confirmação separada para o fechamento de contas, porque é outro tipo de dano. Um bom padrão é exigir digitar uma frase curta como “CLOSE 127 ACCOUNTS” para que o agente perceba se o número estiver errado.
Se “fechar conta” for soft delete, a recuperação é realista. Você pode restaurar contas, manter logins bloqueados e definir uma regra de retenção (por exemplo, purge automático após 30 dias) para que não vire lixo permanente.
Logs de auditoria são o que tornam possível a limpeza e investigação depois. O gerente deve ver quem rodou, o filtro exato, os totais da pré‑visualização mostrados na hora e a lista de registros afetados. Limites de papel também importam: agentes podem emitir reembolsos até um teto diário, mas só um gerente pode fechar contas ou aprovar fechamentos acima de um limite.
Se você construir esse tipo de console no Koder.ai, recursos como snapshots e rollback são guardrails extras úteis, mas a primeira linha de defesa ainda é a pré‑visualização, as confirmações e os papéis.
Passo a passo: retrofitar segurança num admin existente
Retrofitar segurança funciona melhor quando você trata seu admin como um produto, não como um amontoado de páginas internas. Escolha um fluxo de alto risco primeiro (como desativações em massa de usuários), e então avance passo a passo.
Um plano de retrofit prático
Comece listando telas e endpoints que podem excluir, sobrescrever ou movimentar dinheiro. Inclua riscos “escondidos” como importações CSV, edições em lote e scripts que operadores rodam pela UI.
Então torne ações em lote mais seguras forçando escopo e pré‑visualização. Mostre exatamente quais registros batem nos filtros, quantos mudarão e uma pequena amostra de IDs antes de rodar.
Em seguida, substitua hard deletes por soft delete onde puder. Armazene uma flag de deletado, quem fez e quando. Adicione um caminho de restauração tão fácil quanto o delete, mais regras de retenção claras (por exemplo, “restaurável por 30 dias”).
Depois disso, adicione um log de auditoria e sente‑se com operadores para revisar entradas reais. Se uma linha de log não responde “o que mudou, de que para que, e por quê”, ela não vai ajudar em incidentes.
Finalmente, aperte papéis e acrescente aprovações para ações de alto impacto. Por exemplo, permita que suporte emita reembolsos até um limite pequeno, mas exija segunda pessoa para valores grandes ou fechamento de contas. Assim ferramentas administrativas que evitam perda de dados permanecem usáveis sem serem assustadoras.
Exemplo rápido
Um operador precisa fechar 200 contas inativas. Antes da mudança, ele clica em “Excluir” e torce para que os filtros estejam corretos. Depois do retrofit, ele deve confirmar a query exata (“status=inactive, last_login>365d”), revisar a contagem e a lista de amostra, escolher “Fechar (restaurável)” em vez de excluir, e inserir um motivo.
Um bom padrão “done” é:
- Você pode pré‑visualizar e exportar o conjunto afetado antes de executar.
- Você pode desfazer (restaurar ou rollback) dentro de uma janela definida.
- Toda ação é atribuível a uma pessoa e a um motivo.
- Ações de alto impacto são limitadas por papel ou exigem aprovação.
Se você está construindo ferramentas internas em uma plataforma orientada por chat como Koder.ai, adicione esses guardrails como componentes reutilizáveis para que novas páginas admin herdem defaults mais seguros.
Erros comuns que ainda levam a acidentes
Add auditability
Create searchable audit trails that record who changed what, where, and why.
Muitas equipes constroem teoricamente ferramentas administrativas que evitam perda de dados e mesmo assim perdem dados na prática porque as medidas de segurança são fáceis de ignorar ou difíceis de usar.
A armadilha mais comum é a confirmação única para tudo. Se toda ação mostra a mesma mensagem “Tem certeza?”, as pessoas param de ler. Pior, equipes muitas vezes adicionam mais confirmações para “consertar” erros, o que treina operadores a clicar mais rápido.
Outro problema é falta de contexto no momento que importa. Uma ação destrutiva deve mostrar claramente em qual tenant ou workspace você está, se é produção ou teste, e quantos registros serão afetados. Quando essa informação está escondida em outra tela, a ferramenta está pedindo por um dia ruim.
Ações em lote também são perigosas quando rodam instantaneamente sem rastreamento. Operadores precisam de um registro claro do job: o que rodou, qual filtro, quem iniciou e o que o sistema fez ao encontrar erro. Sem isso, você não pode pausar, desfazer ou sequer explicar o que aconteceu.
Aqui estão erros que aparecem com frequência:
- Usar o mesmo texto de confirmação para exclusões, reembolsos e mudanças de permissão
- Adicionar confirmações com tanta frequência que as pessoas clicam no piloto automático
- Não mostrar contagem, tenant e ambiente na tela de confirmação
- Rodar ações em lote imediatamente sem pré‑visualização, sem página de job e sem como parar
- Manter logs de auditoria, mas não torná‑los pesquisáveis por usuário, registro ou tempo
Um exemplo rápido: um operador pretende desativar 12 contas num tenant sandbox, mas a ferramenta padronizou para o tenant usado por último e esconde isso no cabeçalho. Ele roda uma ação em lote, ela executa instantaneamente, e o único “log” é uma entrada vaga como “bulk update completed.” Quando alguém percebe, não dá para dizer facilmente o que mudou nem restaurar.
Boa segurança não é mais popups. É contexto claro, confirmações significativas e ações que você pode rastrear e reverter.
Checklist rápido e próximos passos
Antes de lançar uma ação destrutiva, faça uma checagem final com olhos frescos. A maioria dos incidentes acontece quando uma ferramenta deixa alguém agir no escopo errado, esconde o impacto real ou não oferece um caminho claro de volta.
Aqui está um checklist pré‑voo para ferramentas administrativas que evitam perda de dados:
- Escopo + pré‑visualização: mostre exatamente o que mudará (quem, o quê, onde). Inclua pré‑visualização legível e uma amostra de registros afetados.
- Contagens + limites: exiba o número total de itens e aplique limites sensatos (e rate limits) para que um clique não possa tocar “tudo”.
- Checagens de contexto: faça o operador confirmar tenant/conta, ambiente (prod vs test) e adicione um motivo curto que aparecerá nos logs.
- Caminho de recuperação: prefira soft delete quando possível, confirme que o fluxo de restauração funciona e defina retenção (por quanto tempo a recuperação é possível).
- Responsabilização: registre quem fez o quê, quando, de onde e com quais filtros. Torne logs pesquisáveis e garanta que papéis reflitam responsabilidades reais.
Se você é operador, pause por dez segundos e leia a ferramenta de volta para si: “Estou agindo no tenant X, mudando N registros, em produção, por motivo Y.” Se algo estiver confuso, pare e peça uma UI mais segura antes de rodar.
Próximos passos: prototipe fluxos mais seguros rapidamente no Koder.ai usando o Planning Mode para desenhar telas e guardrails primeiro. Enquanto testa, use snapshots e rollback para experimentar cenários do mundo real sem medo. Quando o fluxo estiver sólido, exporte o código‑fonte e faça o deploy quando estiver pronto.