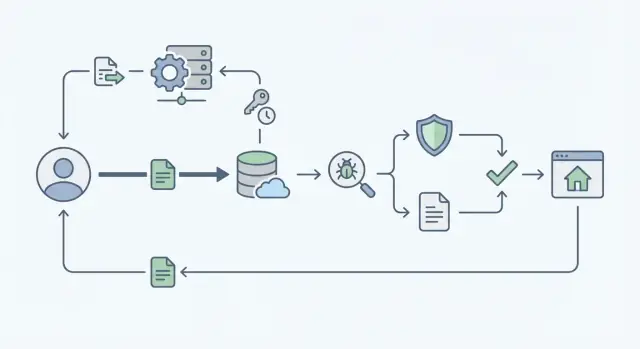
O que torna uploads de arquivos difíceis em escala
Uploads parecem simples até aparecerem usuários reais. Uma pessoa faz upload de uma foto de perfil. Depois dez mil pessoas enviam PDFs, vídeos e planilhas ao mesmo tempo. De repente o app fica lento, custos de armazenamento sobem e tickets de suporte se acumulam.
Falhas comuns são previsíveis. Páginas de upload travam ou dão timeout quando seu servidor tenta processar o arquivo inteiro em vez de deixar o object storage fazer o trabalho pesado. Permissões escorregam, então alguém adivinha uma URL de arquivo e vê algo que não deveria. Arquivos "inofensivos" chegam com malware, ou com formatos complexos que quebram ferramentas a jusante. E os logs ficam incompletos, então você não consegue responder perguntas básicas como quem enviou o quê e quando.
O que você quer é chato e confiável: uploads rápidos, regras claras (tipos e tamanhos permitidos) e uma trilha de auditoria que torne incidentes fáceis de investigar.
O maior tradeoff é velocidade vs segurança. Se você rodar todas as verificações antes do usuário terminar, ele espera e tenta novamente, o que aumenta a carga. Se você adiar checagens demais, arquivos inseguros ou não autorizados podem se espalhar antes que você os detecte. Uma abordagem prática é separar o upload das verificações e manter cada etapa rápida e mensurável.
Seja específico sobre “escala”. Anote seus números: arquivos por dia, uploads máximos por minuto, tamanho máximo de arquivo e onde seus usuários estão localizados. Regiões importam para latência e regras de privacidade.
Se você está construindo um app numa plataforma como Koder.ai, ajuda decidir esses limites cedo, porque eles moldam permissões, armazenamento e o fluxo de varredura em background.
Um modelo de ameaça simples para uploads
Antes de escolher ferramentas, fique claro sobre o que pode dar errado. Um modelo de ameaça não precisa ser um documento grande. É um entendimento curto e compartilhado do que você deve evitar, o que pode ser detectado depois e quais tradeoffs você aceita.
Atacantes costumam tentar em pontos previsíveis: o cliente (mudando metadados ou falsificando MIME type), a borda da rede (replays e abuso de rate limit), o storage (adivinhando nomes de objetos, sobrescrevendo) e o download/preview (disparando renderizações arriscadas ou roubando arquivos via acesso compartilhado).
A partir daí, mapeie ameaças para controles simples:
Arquivos com tamanho excessivo são o abuso mais fácil. Eles podem aumentar custos e deixar usuários reais lentos. Pare-os cedo com limites rígidos de bytes e rejeição rápida.
Tipos falsos vêm em seguida. Um arquivo chamado invoice.pdf pode ser outra coisa. Não confie em extensões ou checagens na UI. Verifique pelos bytes reais após o upload.
Malware é diferente. Geralmente você não consegue escanear tudo antes do upload completar sem prejudicar a experiência. O padrão comum é detectar assincronamente, colocar itens suspeitos em quarentena e bloquear acesso até o scan passar.
Acesso não autorizado costuma ser o mais danoso. Trate cada upload e cada download como uma decisão de permissão. Um usuário só deve fazer upload em um local que ele possua (ou onde tenha permissão de escrita) e só baixar arquivos que esteja autorizado a ver.
Para muitos apps, uma política v1 sólida é:
- Aplicar tamanho máximo e categorias permitidas (imagens, PDFs, etc.)
- Verificar o tipo real do arquivo no servidor após o upload
- Escanear assincronamente e colocar em quarentena até estar limpo
- Exigir autorização explícita para upload e download
- Logar e alertar sobre falhas repetidas (tamanho, tipo, auth)
Uma arquitetura de upload prática que permanece rápida
A forma mais rápida de lidar com uploads é manter seu servidor fora do “negócio dos bytes.” Em vez de enviar todo arquivo pelo backend, deixe o cliente fazer upload direto para o object storage usando uma URL assinada de curta duração. Seu backend permanece focado em decisões e registros, não em empurrar gigabytes.
A separação é simples: o backend responde “quem pode enviar o quê, e onde”, enquanto o storage recebe os dados do arquivo. Isso remove um gargalo comum: servidores de app fazendo trabalho duplo (auth mais proxy do arquivo) e ficando sem CPU, memória ou rede sob carga.
As partes mínimas necessárias
Mantenha um pequeno registro de upload no seu banco (por exemplo, PostgreSQL) para que cada arquivo tenha um dono claro e um ciclo de vida definido. Crie esse registro antes do upload começar e atualize conforme eventos acontecem.
Campos que costumam valer a pena: identificador do owner e tenant/workspace, a chave do objeto no storage, um status, tamanho e MIME type alegados, e um checksum que você possa verificar.
Planeje estados de upload antecipadamente
Trate uploads como uma máquina de estados para que checagens de permissão permaneçam corretas mesmo quando ocorrem retries.
Um conjunto prático de estados é:
- requested
- uploaded
- scanned
- approved
- rejected
Só permita que o cliente use a URL assinada depois que o backend criar um registro requested. Após o storage confirmar o upload, passe para uploaded, dispare o scan de malware em background e só exponha o arquivo quando estiver approved.
Comece quando o usuário clica em Upload. Seu app chama o backend para iniciar um upload com detalhes básicos como nome do arquivo, tamanho e uso pretendido (avatar, invoice, anexo). O backend checa permissão para aquele destino específico, cria um registro de upload e retorna uma URL assinada de curta duração.
A URL assinada deve ser de escopo restrito. Idealmente, ela permite um único upload para uma chave exata de objeto, com expiração curta e condições claras (limite de tamanho, tipo de conteúdo permitido, checksum opcional).
O navegador faz o upload direto para o storage usando essa URL. Quando termina, o navegador chama o backend novamente para finalizar. Ao finalizar, revalide permissão (usuários podem perder acesso) e verifique o que realmente foi gravado no storage: tamanho, tipo de conteúdo detectado e checksum se você usar um. Faça o finalize idempotente para que retries não criem duplicatas.
Então marque o registro como uploaded e dispare o scan em background (fila/job). A UI pode mostrar “Processando” enquanto o scan roda.
Validação de tipo e tamanho em que você pode confiar
Da checklist à implementação
Transforme sua checklist de upload em um plano concreto e passos de construção no Koder.ai.
O que validar e onde
Confiar em uma extensão é como invoice.pdf.exe acabar no seu bucket. Trate a validação como um conjunto repetível de checagens que acontecem em mais de um lugar.
Comece com limites de tamanho. Coloque o tamanho máximo na política da URL assinada (ou nas condições do pre-signed POST) para que o storage rejeite uploads maiores cedo. Aplique o mesmo limite novamente quando seu backend registrar metadados, porque clientes ainda podem tentar burlar a UI.
Checagens de tipo devem basear-se no conteúdo, não no nome do arquivo. Inspecione os primeiros bytes do arquivo (magic bytes) para confirmar que bate com o esperado. Um PDF real começa com %PDF, e PNGs começam com uma assinatura fixa. Se o conteúdo não corresponder à sua allowlist, rejeite mesmo que a extensão pareça correta.
Mantenha allowlists específicas por funcionalidade. Um upload de avatar pode permitir apenas JPEG e PNG. Uma funcionalidade de documentos pode permitir PDF e DOCX. Isso reduz risco e torna suas regras mais fáceis de explicar.
Checksums e nomes de arquivos
Nunca confie no nome original como chave de storage. Normalize-o para exibição (remova caracteres estranhos, limite comprimento), mas armazene sua própria chave segura, como um UUID mais uma extensão que você atribui após detectar o tipo.
Armazene um checksum (por exemplo, SHA-256) no banco e compare mais tarde durante processamento ou scan. Isso ajuda a detectar corrupção, uploads parciais ou adulteração, especialmente quando uploads são re-tentados sob carga.
Scan de malware que não faz usuários esperarem
Scan de malware importa, mas não deve ficar no caminho crítico. Aceite o upload rapidamente e trate o arquivo como bloqueado até que passe no scan.
O padrão assíncrono
Crie um registro de upload com um status como pending_scan. A UI pode mostrar o arquivo, mas ele não deve ser utilizável ainda.
O scan é tipicamente disparado por um evento de storage quando o objeto é criado, publicando um job em uma fila logo após a conclusão do upload, ou fazendo ambas as coisas (fila mais evento de storage como redundância).
O worker de scan baixa ou streama o objeto, roda scanners e grava o resultado de volta no banco. Mantenha o essencial: status do scan, versão do scanner, timestamps e quem solicitou o upload. Essa trilha de auditoria facilita muito o suporte quando alguém pergunta “Por que meu arquivo foi bloqueado?”
O que acontece quando um arquivo falha
Não deixe arquivos falhos misturados com os limpos. Escolha uma política e aplique-a consistentemente: quarentena e remoção de acesso, ou exclusão se você não precisar para investigação.
Seja qual for a escolha, mantenha a comunicação com o usuário calma e específica. Diga o que ocorreu e o que fazer em seguida (reenviar, contatar suporte). Alerta sua equipe se muitas falhas ocorrerem em pouco tempo.
Mais importante: estabeleça uma regra rígida para downloads e previews: só arquivos marcados como approved podem ser servidos. Todo o resto deve retornar uma resposta segura como “Arquivo ainda está sendo verificado.”
Checagens de permissão que permanecem corretas sob carga
Uploads rápidos são ótimos, mas se a pessoa errada puder anexar um arquivo ao workspace errado, você tem um problema maior que requisições lentas. A regra mais simples e forte: cada registro de arquivo pertence a um único tenant (workspace/org/projeto) e tem um dono claro.
Faça checagens de permissão duas vezes: ao emitir a URL assinada e de novo quando alguém tenta baixar ou visualizar o arquivo. A primeira checagem impede uploads não autorizados. A segunda protege caso o acesso seja revogado, uma URL vaze ou o papel do usuário mude após o upload.
Princípio do menor privilégio mantém segurança e desempenho previsíveis. Em vez de uma permissão ampla “arquivos”, separe papéis como “pode enviar”, “pode ver” e “pode gerenciar (deletar/compartilhar)”. Muitas requisições então se tornam buscas rápidas (usuário, tenant, ação) ao invés de lógica customizada cara.
Para evitar adivinhação de IDs, evite IDs sequenciais em URLs e APIs. Use identificadores opacos e mantenha chaves de storage inguessáveis. URLs assinadas são transporte, não seu sistema de permissões.
Arquivos compartilhados são onde sistemas ficam lentos e confusos. Trate compartilhamento como dados explícitos, não acesso implícito. Uma abordagem simples é um registro de compartilhamento separado que concede a um usuário ou grupo permissão a um arquivo, opcionalmente com expiração.
Manter uploads rápidos à medida que tráfego e tamanho crescem
Implemente permissões multi-tenant
Gere regras claras de autorização de upload e download por workspace ou tenant.
Quando falam em escalar uploads seguros, muitos focam em checagens de segurança e esquecem o básico: mover bytes é a parte lenta. O objetivo é manter tráfego de arquivos grandes fora dos app servers, controlar retries e evitar transformar checagens de segurança em uma fila sem controle.
Torne arquivos grandes previsíveis
Para arquivos grandes, use uploads multipart ou chunked para que uma conexão instável não force o usuário a recomeçar do zero. Chunks também ajudam a impor limites claros: tamanho total máximo, tamanho máximo de chunk e tempo máximo de upload.
Defina timeouts e retries no cliente de forma intencional. Alguns retries salvam usuários reais; retries ilimitados podem explodir custos, especialmente em redes móveis. Mire em timeouts curtos por chunk, um pequeno limite de retries e um prazo final para o upload inteiro.
Controle o passo “criar upload”
URLs assinadas mantêm o caminho pesado de dados rápido, mas a requisição que as cria ainda é um ponto quente. Proteja-a para que permaneça responsiva:
- Rate-limit em “criar upload” por usuário e por IP
- Aplique limites de tamanho antes de emitir a URL assinada
- Use TTL curto para que URLs não usadas expirem rapidamente
- Rastreie uploads em progresso para evitar que um usuário inicie centenas ao mesmo tempo
- Use chaves de idempotência para que refreshes não criem uploads duplicados
Latência também depende de geografia. Mantenha app, storage e workers de scan na mesma região quando possível. Se precisar de hospedagem por país por compliance, planeje roteamento cedo para que uploads não viagem entre continentes. Plataformas que rodam na AWS globalmente (como Koder.ai) podem colocar workloads mais perto dos usuários quando residência de dados importa.
Por fim, planeje downloads, não apenas uploads. Sirva arquivos com URLs de download assinadas e defina regras de cache conforme tipo e nível de privacidade. Assets públicos podem ser cacheados por mais tempo; recibos privados devem usar URLs de curta duração e checagens de permissão.
Cenário de exemplo: faturas e recibos em um app multiusuário
Imagine um app de pequenas empresas onde funcionários enviam faturas e fotos de recibos, e um gerente aprova para reembolso. Aqui o design de upload deixa de ser acadêmico: você tem muitos usuários, imagens grandes e dinheiro real em jogo.
Um bom fluxo usa statuses claros para que todos saibam o que acontece e você possa automatizar tarefas chatas: o arquivo cai no object storage e você salva um registro ligado ao usuário/workspace/expense; um job em background escaneia o arquivo e extrai metadados básicos (como MIME type real); então o item é aprovado e fica utilizável em relatórios, ou rejeitado e bloqueado.
Usuários precisam de feedback rápido e específico. Se o arquivo for grande demais, mostre o limite e o tamanho atual (por exemplo: “Arquivo tem 18 MB. Máx é 10 MB.”). Se o tipo estiver errado, diga o que é permitido (“Envie um PDF, JPG ou PNG”). Se o scan falhar, mantenha a mensagem calma e acionável (“Este arquivo pode ser inseguro. Por favor envie uma nova cópia.”).
Equipes de suporte precisam de uma trilha que as ajude a depurar sem abrir o arquivo: upload ID, user ID, workspace ID, timestamps de created/uploaded/scan started/scan finished, códigos de resultado (muito grande, tipo incompatível, scan falhou, permissão negada), além da chave de storage e checksum.
Re-uploads e substituições são comuns. Trate-os como novos uploads, anexe-os à mesma despesa como uma nova versão, mantenha histórico (quem substituiu e quando) e marque como ativa apenas a versão mais recente. Se você está construindo esse app no Koder.ai, isso mapeia bem para uma tabela uploads mais uma tabela expense_attachments com campo de versão.
Erros comuns e correções fáceis
Implemente mais perto dos usuários
Lance em regiões AWS que atendam latência e requisitos de residência de dados.
A maioria dos bugs de upload não é um hack complexo. São atalhos pequenos que viram riscos reais quando o tráfego cresce.
Os cinco erros que mais aparecem
- Confiar apenas em checagens no cliente. Correção: valide de novo no servidor usando bytes reais (magic bytes) e imponha limites de tamanho usando metadados do storage, não só o relatório do navegador.
- Fazer URLs assinadas de longa duração. Correção: mantenha curtas (minutos), de propósito único e escopadas a uma chave de objeto. Roteie credenciais e logue cada emissão.
- Permitir downloads antes do scan terminar. Correção: faça upload em local de quarentena, escaneie assincronamente e promova/serva após resultado limpo.
- Usar nomes ou caminhos fornecidos pelo usuário como chaves. Correção: gere suas próprias chaves de objeto (UUIDs) e armazene o nome original como metadado de exibição.
- Pular checagens de permissão no download. Correção: trate o download como decisão separada e revalide propriedade, participação no workspace e regras de compartilhamento toda vez que gerar uma URL de download.
Correções fáceis que previnem gargalos
Mais checagens não precisam deixar uploads lentos. Separe o caminho rápido do caminho pesado.
Faça checagens rápidas de forma síncrona (auth, tamanho, tipo permitido, rate limits) e delegue scan e inspeção profunda para um worker em background. Usuários podem continuar trabalhando enquanto o arquivo vai de “uploaded” para “ready”. Se você constrói com um builder baseado em chat como Koder.ai, mantenha a mesma mentalidade: torne o endpoint de upload pequeno e estrito, e empurre scan e pós-processamento para jobs.
Checklist rápido e próximos passos
Antes de lançar uploads, defina o que “suficientemente seguro para v1” significa. Times costumam se meter em problemas misturando regras rígidas (que bloqueiam usuários reais) com regras ausentes (que convidam abuso). Comece pequeno, mas garanta que todo upload tenha um caminho claro de “recebido” até “liberado para download”.
Uma checklist de pré-lançamento:
- Aplique um limite rígido de tamanho cedo (antes que custos de storage cresçam)
- Use uma allowlist de tipos validada por conteúdo (magic bytes), não só pelo nome do arquivo
- Bloqueie acesso até o scan: não sirva arquivos para terceiros até o scan terminar
- Exija checagens de autorização no download toda vez
- Mantenha logs de auditoria para upload, resultado do scan e tentativas de download
Se precisar de uma política mínima viável, mantenha simples: limite de tamanho, allowlist estreita de tipos, upload com URL assinada e “quarentena até o scan passar”. Adicione recursos depois (previews, mais tipos, reprocessamento em background) quando o caminho básico estiver estável.
Monitoramento é o que evita que “rápido” vire “misteriosamente lento” conforme você cresce. Acompanhe taxa de falha de upload (cliente vs servidor/storage), taxa e latência de scan, tempo médio de upload por faixa de tamanho, negações de autorização em download e padrões de egress de storage.
Faça um pequeno teste de carga com tamanhos realistas e redes do mundo real (dados móveis se comportam diferente de Wi-Fi de escritório). Corrija timeouts e retries antes do lançamento.
Se você está implementando isso no Koder.ai (koder.ai), o Planning Mode é um lugar prático para mapear seus estados de upload e endpoints primeiro, e depois gerar o backend e a UI em torno desse fluxo. Snapshots e rollback também ajudam quando você estiver ajustando limites ou regras de scan.