Por que mudanças no esquema causam interrupções
Tempo de indisponibilidade causado por uma mudança no banco nem sempre é um erro óbvio. Para os usuários pode parecer uma página que carrega para sempre, um checkout que falha ou um app que de repente mostra "algo deu errado." Para as equipes aparece como alertas, aumento de taxa de erros e um acúmulo de gravações falhas que precisam ser limpas.
Mudanças de esquema são arriscadas porque o banco de dados é compartilhado por todas as versões ativas do seu app. Durante um release você frequentemente tem código antigo e novo ao mesmo tempo (deploys graduais, múltiplas instâncias, jobs em background). Uma migração que parece correta pode ainda quebrar uma daquelas versões.
Modos comuns de falha incluem:
- Código novo grava em uma coluna que ainda não existe, causando erros imediatos.
- Código antigo lê uma coluna ou tabela que a migração renomeou ou removeu, causando crashes após o deploy.
- Um backfill ou a construção de um índice dispara CPU ou trava linhas, tornando requisições normais lentas ou com timeout.
- Uma mudança “rápida” de restrição (como NOT NULL) bloqueia gravações enquanto a tabela é verificada.
Mesmo quando o código está certo, releases são bloqueados porque o problema real é o tempo e a compatibilidade entre versões.
Alterações de esquema sem interrupção resumem-se a uma regra: todo estado intermediário deve ser seguro tanto para o código antigo quanto para o novo. Você altera o banco sem quebrar leituras e gravações existentes, envia código que lida com ambas as formas e só remove o caminho antigo quando nada mais depende dele.
Esse esforço extra vale a pena quando você tem tráfego real, SLAs rigorosos ou muitas instâncias e workers. Para uma ferramenta interna pequena com pouco uso, uma janela de manutenção planejada pode ser mais simples.
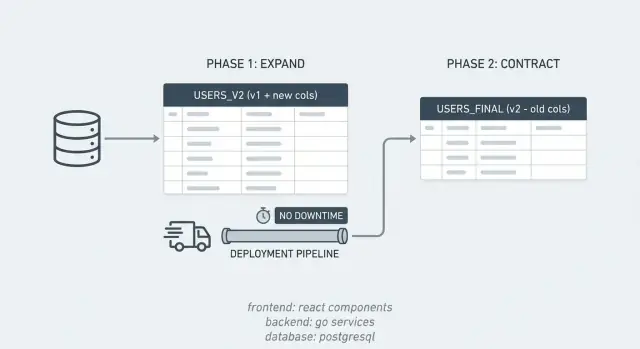
Expandir/contrair em termos simples
A maioria dos incidentes por mudanças no banco acontece porque o app espera que a mudança no banco seja instantânea, enquanto a mudança leva tempo. O padrão expandir/contrair evita isso ao dividir uma mudança arriscada em passos menores e seguros.
Por um curto período, seu sistema passa a suportar duas “dialetos” ao mesmo tempo. Você introduz a nova estrutura primeiro, mantém a antiga funcionando, move dados gradualmente e depois limpa.
O padrão é simples:
- Expandir: adicione o que precisa (colunas, tabelas, índices) sem quebrar o app atual.
- Rodar ambos caminhos: envie código que funcione com estruturas antigas e novas para que versões mistas continuem funcionando.
- Contrair: quando tudo usar a nova estrutura, remova o esquema antigo e o código legado.
Isso funciona bem com deploys graduais. Se você atualiza 10 servidores um a um, haverá um breve período com código antigo e novo juntos. Expandir/contrair mantém ambos compatíveis com o mesmo banco durante essa sobreposição.
Também deixa rollbacks menos assustadores. Se uma release tiver bug, você pode reverter o app sem reverter o banco, porque as estruturas antigas ainda existem durante a janela de expand.
Exemplo: você quer dividir uma coluna PostgreSQL full_name em first_name e last_name. Você adiciona as novas colunas (expandir), envia código que pode ler e escrever ambos os formatos, preenche linhas antigas, e então derruba full_name quando tiver certeza de que nada mais a usa (contrair).
O que “expandir” geralmente inclui
A fase de expandir é sobre adicionar novas opções, não remover as antigas.
Um movimento comum é adicionar uma nova coluna. No PostgreSQL, costuma ser mais seguro adicioná-la como nullable e sem default. Adicionar uma coluna não-nula com default pode forçar reescrita da tabela ou locks maiores, dependendo da versão do Postgres. Uma sequência mais segura é: adicionar nullable, enviar código tolerante, backfill, e só depois aplicar NOT NULL.
Índices também precisam de cuidado. Criar um índice normal pode bloquear gravações por mais tempo do que você espera. Quando possível, use criação de índice em modo concorrente para manter leituras e gravações fluindo. Leva mais tempo, mas evita locks que paralisam o release.
Expandir também pode significar adicionar tabelas novas. Se você está indo de uma coluna única para um relacionamento muitos-para-muitos, pode adicionar uma tabela de junção enquanto mantém a coluna antiga. O caminho antigo continua funcional enquanto a nova estrutura começa a coletar dados.
Na prática, expandir frequentemente inclui:
- Adicionar colunas nullable ou tabelas novas juntamente com as existentes
- Adicionar índices de forma não bloqueante quando possível
- Usar feature flags para controlar quando novas leituras/escritas entram em vigor
- Escrever tanto no campo antigo quanto no novo (dual-write) quando necessário
- Manter leituras compatíveis (antigo, novo ou fallback)
Após a fase de expandir, versões antigas e novas do app devem rodar ao mesmo tempo sem surpresas.
Enviando código que continua compatível
A maior parte da dor durante releases acontece no meio: alguns servidores rodam código novo, outros ainda rodam código antigo, enquanto o banco já está mudando. Seu objetivo é simples: qualquer versão durante o rollout deve funcionar com o esquema antigo e com o expandido.
Uma abordagem comum é o dual-write. Se você adiciona uma nova coluna, o app novo escreve tanto na coluna antiga quanto na nova. Versões antigas continuam escrevendo apenas na antiga, o que é seguro porque ela ainda existe. Mantenha a coluna nova opcional no começo e adie restrições rígidas até que todos os gravadores tenham sido atualizados.
Leituras normalmente mudam com mais cuidado do que gravações. Por um tempo, mantenha leituras na coluna antiga (a que você sabe estar totalmente populada). Depois do backfill e da verificação, mude as leituras para preferir a coluna nova, com fallback para a antiga caso a nova esteja ausente.
Também mantenha a saída da sua API estável enquanto o banco muda por baixo. Mesmo que você introduza um campo interno novo, evite mudar formatos de resposta até que todos os consumidores estejam prontos (web, mobile, integrações).
Um rollout amigável ao rollback geralmente parece com isto:
- Release 1: adicione a nova coluna e envie código que leia os dados antigos e escreva em ambas as colunas.
- Release 2: backfill das linhas existentes e depois envie código que prefere ler a coluna nova, mas ainda faz fallback.
- Release 3: pare de escrever na coluna antiga (mas mantenha-a presente).
- Release 4: remova leituras antigas e então remova a coluna antiga.
A ideia chave é que o primeiro passo irreversível é descartar a estrutura antiga, então você o deixa para o final.
Backfill seguro (sem sobrecarregar o banco)
Backfills são onde muitas "migrações sem downtime" dão errado. Você quer preencher a nova coluna para linhas existentes sem locks longos, consultas lentas ou picos de carga.
Lotes importam. Mire em batches que terminem rápido (segundos, não minutos). Se cada lote for pequeno, você pode pausar, retomar e ajustar o job sem travar releases.
Para acompanhar o progresso, use um cursor estável. No PostgreSQL isso costuma ser a chave primária. Processe linhas em ordem e armazene o último id completado, ou trabalhe em faixas de id. Isso evita scans caros de tabela inteira quando o job reinicia.
Aqui está um padrão simples:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
Torne o update condicional (por exemplo, WHERE new_col IS NULL) para que o job seja idempotente. Reruns só tocam linhas que ainda precisam, reduzindo gravações desnecessárias.
Planeje para novos dados chegando durante o backfill. A ordem usual é:
- Atualize o código da aplicação primeiro para que novas escritas também popularem o campo novo.
- Backfill das linhas históricas em lotes.
- Rode um loop de catch-up curto que rechecque linhas recentes.
- Se necessário, adicione um guardrail (como um trigger ou default) para evitar novos NULLs.
Um bom backfill é entediante: constante, mensurável e fácil de pausar se o banco aquecer.
Verificando que a migração realmente terminou
O momento mais arriscado não é adicionar a nova coluna. É decidir que você já pode contar com ela.
Antes de passar para o contract, prove duas coisas: os dados novos estão completos e a produção está lendo-os com segurança.
Comece com checagens de completude rápidas e repetíveis:
- Confirme que a nova coluna não tem NULLs inesperados.
- Compare quantas linhas eram elegíveis versus quantas foram preenchidas.
- Faça checagens pontuais de alguns IDs e compare os valores antigos e novos.
- Teste casos de borda (strings vazias, zero, registros muito antigos).
- Rode as mesmas checagens depois para garantir que nada mudou.
Se você faz dual-write, acrescente uma checagem de consistência para capturar bugs silenciosos. Por exemplo, rode uma query horária que encontre linhas onde old_value <> new_value e alerte se não for zero. Isso é muitas vezes a forma mais rápida de descobrir que um gravador ainda atualiza apenas a coluna antiga.
Observe sinais básicos de produção enquanto a migração roda. Se tempo de consulta ou esperas por locks subirem, até suas queries de verificação “seguras” podem estar adicionando carga. Monitore taxas de erro para qualquer caminho de código que leia a coluna nova, especialmente logo após deploys.
Por quanto tempo manter ambos os caminhos? Tempo suficiente para sobreviver a pelo menos um ciclo completo de release e uma rerun do backfill. Muitas equipes usam 1–2 semanas, ou até terem certeza de que nenhuma versão antiga ainda está rodando.
Fase de contract: remover o caminho antigo
Contract é onde equipes ficam nervosas porque parece o ponto sem volta. Se o expand foi feito certo, contract é maiormente limpeza, e você ainda pode fazê-lo em passos pequenos e de baixo risco.
Escolha o momento com cuidado. Não drope nada imediatamente após terminar um backfill. Dê pelo menos um ciclo completo de release para que jobs atrasados e casos de borda apareçam.
Uma sequência segura de contract geralmente é:
- Pare o dual-write e confirme que novas gravações caem apenas na(s) coluna(s) nova(s).
- Remova leituras antigas na aplicação para que o fallback desapareça.
- Delete caminhos de código mortos, feature flags e jobs que referenciam o esquema antigo.
- Remova triggers temporários, jobs de sincronização ou views de compatibilidade.
- Drop nos índices e constraints antigos e, por fim, drop na coluna antiga.
Se possível, divida o contract em duas releases: uma que remove referências no código (com logging extra) e outra posterior que remove objetos do banco. Essa separação facilita rollback e troubleshooting.
Especificidades do PostgreSQL importam aqui. Dropar uma coluna é na maior parte uma mudança de metadados, mas ainda exige um lock ACCESS EXCLUSIVE por um breve período. Planeje para um momento mais calmo e mantenha a migração rápida. Se você criou índices extras, prefira removê-los com DROP INDEX CONCURRENTLY para evitar bloquear gravações (isso não pode rodar dentro de um bloco de transação, então sua ferramenta de migração precisa dar suporte).
Erros comuns e armadilhas
Migrações sem downtime falham quando o banco e o app deixam de concordar sobre o que é permitido. O padrão só funciona se todo estado intermediário for seguro para o código antigo e o novo.
Armadilhas que quebram a produção
Erros que aparecem com frequência:
- Colocar NOT NULL cedo demais, enquanto uma versão antiga ainda grava sem o novo campo.
- Backfill de uma tabela gigante em uma única transação, gerando locks, bloat e timeouts.
- Assumir que um default é “de graça”. No PostgreSQL, alguns defaults disparam reescrita da tabela.
- Mudar leituras para a coluna nova antes das escritas estarem populando-a de forma confiável.
- Esquecer outros escritores e leitores (cron jobs, workers, exports, queries de relatório).
Um cenário realista: você começa a gravar full_name pela API, mas um job em background que cria usuários continua setando apenas first_name e last_name. Ele roda à noite, insere linhas com full_name = NULL e, depois, código assume que full_name sempre estará presente.
Como evitar ficar preso no meio da migração
Trate cada passo como um release que pode durar dias:
- Mantenha a nova coluna nullable durante a transição e aplique "obrigatoriedade" primeiro no código.
- Backfill em pequenos lotes com pausas e monitore a carga do banco.
- Faça o código tolerante: leia ambos os caminhos, escreva em ambos quando preciso, trate valores ausentes.
- Audite todo lugar que toca a tabela, incluindo workers e rotinas de relatório.
Checklist rápido antes de cada release
Um checklist repetível impede que você envie código que só funciona em um estado do banco.
Antes de deploy, confirme que o banco já tem os pedaços expandidos no lugar (novas colunas/tabelas, índices criados de forma de baixo lock). Depois confirme que o app é tolerante: deve funcionar contra o esquema antigo, o expandido e um estado meio-backfilled.
Mantenha o checklist curto:
- Expansão presente: objetos de esquema novos existem e foram adicionados com baixo impacto de locks.
- Compatibilidade real: o app funciona com esquema antigo e expandido, incluindo workers e caminhos administrativos.
- Backfill controlado: batches pequenos, pausáveis, com métricas básicas de progresso.
- Troca de leitura planejada: você sabe exatamente quando as leituras mudam e como reverter se os resultados estiverem errados.
- Contract adiado: espere pelo menos um ou dois ciclos de release antes de dropar objetos antigos.
Uma migração só termina quando leituras usam os dados novos, gravações não mantêm mais os dados antigos, e você verificou o backfill com ao menos uma checagem simples (contagens ou amostragem).
Um exemplo realista: substituir uma coluna sem downtime
Suponha que há uma tabela PostgreSQL customers com uma coluna phone que armazena valores inconsistentes. Você quer substituí-la por phone_e164, mas não pode bloquear releases nem tirar o app do ar.
Uma sequência limpa expand/contract é:
- Expandir: adicione
phone_e164 como nullable, sem default e sem constraints pesadas ainda.
- Deploy compatível: atualize o código para escrever tanto
phone quanto phone_e164, mas mantenha leituras em phone para que nada mude para os usuários.
- Backfill: converta linhas existentes em pequenos lotes (por exemplo, 1.000 por vez).
- Trocar leituras: envie código que leia
phone_e164 primeiro e faça fallback para phone se estiver NULL.
- Contract: quando tudo estiver usando
phone_e164, remova o fallback, drope phone e então adicione constraints mais rígidas, se necessário.
O rollback permanece simples quando cada passo é compatível com versões anteriores. Se a troca de leitura causar problemas, reverta o app e o banco ainda terá ambas as colunas. Se o backfill causar picos de carga, pause o job, reduza o batch e continue depois.
Se quiser que a equipe permaneça alinhada, documente o plano em um lugar só: o SQL exato, qual release troca as leituras, como medir conclusão (porcentagem de phone_e164 não-NULL) e quem é dono de cada passo.
Próximos passos: torne isso repetível
Expand/contract funciona melhor quando vira rotina. Escreva um runbook curto que sua equipe possa reaproveitar em toda mudança de esquema, idealmente uma página e específico o suficiente para que um colega novo consiga seguir.
Um template prático cobre:
- Expand (migrations exatas)
- Mudanças de código (o que deve permanecer compatível e onde usar dual-read ou dual-write)
- Backfill (tamanho de lote, limites de taxa, pausar/retomar)
- Verificação (queries e métricas que provam correção)
- Contract (o que será removido e quando)
Decida ownership desde o começo. “Todo mundo achou que alguém faria o contract” é como colunas antigas e feature flags ficam meses sem remoção.
Mesmo que o backfill rode online, escolha momentos de menor tráfego. É mais fácil manter batches pequenos, observar carga do banco e parar rapidamente se a latência subir.
Se você está construindo e fazendo deploy com Koder.ai (koder.ai), o Planning Mode pode ser uma forma útil de mapear fases e checkpoints antes de tocar a produção. As mesmas regras de compatibilidade valem, mas ter os passos escritos dificulta pular as partes chatas que evitam outages.