২৩ ডিসে, ২০২৫·7 মিনিট
SaaS API রেট-লিমিটিং: প্রতি-ব্যবহারকারী, সংস্থা ও IP প্যাটার্ন
per-user, per-org, এবং per-IP লিমিটসহ SaaS API রেট-লিমিটিং প্যাটার্ন—স্পষ্ট হেডার, ত্রুটি বডি এবং রোলআউট টিপস যাতে গ্রাহকরা বুঝতে পারে।
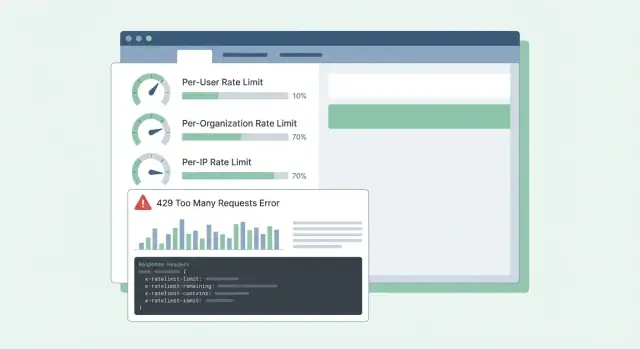
per-user, per-org, এবং per-IP লিমিটসহ SaaS API রেট-লিমিটিং প্যাটার্ন—স্পষ্ট হেডার, ত্রুটি বডি এবং রোলআউট টিপস যাতে গ্রাহকরা বুঝতে পারে।
রেট লিমিট এবং কোটা শব্দগুলো একই রকম শোনালেও মানুষ এগুলোকে প্রায়শই এক মনে করে। রেট লিমিট হলো আপনি কত দ্রুত একটি API কল করতে পারবেন (প্রতি সেকেন্ড বা প্রতি মিনিটে অনুরোধের সংখ্যা)। কোটা হলো আপনি দীর্ঘ সময়কালে কতটা ব্যবহার করতে পারবেন (প্রতি দিন, প্রতি মাস বা বিলিং সাইকেল)। উভয়ই স্বাভাবিক, কিন্তু যখন নিয়মগুলো দৃশ্যমান থাকে না তখন এগুলো অনিয়মিত মনে হয়।
ক্লাসিক অভিযোগটি হলো: “গতকাল কাজ করছিল।” ব্যবহার প্রায়শই স্থির থাকে না। একটি ছোট স্পাইক কারোকে লাইন পার করবে এমনকি যদি তাদের দৈনিক মোট ঠিকঠাক দেখায়। কল্পনা করুন এমন একজন গ্রাহক যে প্রতিদিন একবার রিপোর্ট চালায়, কিন্তু আজ কাজটি টাইমআউটের পরে রিট্রাই করে এবং 2 মিনিটে 10 গুণ বেশি কল করে। API তাদের ব্লক করে, এবং তারা কেবল এক মুহূর্তে ব্যর্থতা দেখে।
ভুল বোঝাবুঝি আরও বাড়ে যখন ত্রুটি অস্পষ্ট হয়। যদি API 500 ফেরত দেয় বা একটি সাধারণ বার্তা দেয়, গ্রাহকরা মনে করে আপনার সার্ভিস ডাউন, লিমিট হিট হয়নি। তারা জরুরি টিকিট খুলে, ওয়ার্কঅ্যারাউন্ড তৈরি করে বা সরবরাহকারী পরিবর্তন করে। এমনকি 429 Too Many Requests-ও হতাশাজনক হতে পারে যদি সেখানে পরবর্তী করণীয় বলা না থাকে।
অধিকাংশ SaaS API ট্রাফিক সীমিত করে দুইটি কারণে:
এই দুটি উদ্দেশ্য মিশিয়ে দিলে খারাপ ডিজাইন হয়। অ্যাবিউজ কন্ট্রোল প্রায়শই per-IP বা per-token ভিত্তিক এবং কড়া হতে পারে। স্বাভাবিক ব্যবহার সাজানো সাধারণত per-user বা per-organization ভিত্তিক এবং এর সাথে স্পষ্ট নির্দেশনা থাকা উচিত: কোন লিমিট হিট হয়েছে, কখন রিসেট হবে, এবং কীভাবে তা এড়ানো যায়।
যখন গ্রাহকরা লিমিট পূর্বাভাস করতে পারে, তারা তার ওপর পরিকল্পনা করে। যখন পারবে না, প্রতিটি স্পাইকই ভাঙা API মনে হবে।
রেট লিমিটগুলো শুধু থ্রোটল নয়। এগুলো একটি সেফটি সিস্টেম। সংখ্যাগুলি নির্ধারণ করার আগে, স্পষ্ট করুন আপনি কী রক্ষা করতে চাইছেন, কারণ প্রতিটি লক্ষ্য বিভিন্ন লিমিট ও প্রত্যাশা নিয়ে আসে।
উপলব্ধি সাধারণত প্রথমে আসে। যদি কয়েকটি ক্লায়েন্ট ট্র্যাফিক স্পাইক করে এবং আপনার API টাইমআউটে ঠেলে দেয়, সবাই ভোগে। এমন ন্যুম্বার বেছে নিন যা বёрস্তের সময় সার্ভারগুলোকে সাড়া দিতে রাখে এবং অনুরোধগুলো জমে না যেতে দেয়।
খরচ অনেক API-র পিছনে নীরব চালক। কিছু অনুরোধ সস্তা, কিছু ব্যয়বহুল (LLM কল, ফাইল প্রসেসিং, স্টোরেজ লেখালেখি, পেইড থার্ড-পার্টি লুকআপ)। উদাহরণস্বরূপ, Koder.ai প্ল্যাটফরমে একটি ব্যবহারকারী চ্যাট-ভিত্তিক অ্যাপ জেনারেশনের মাধ্যমে অনেক মডেল কল ট্রিগার করতে পারে। ব্যয়বান অ্যাকশন ট্র্যাক করা লিমিটগুলি অপ্রত্যাশিত বিল প্রতিরোধ করে।
অ্যাবিউজের চিত্র উচ্চ বৈধ ব্যবহারের থেকে ভিন্ন। ক্রেডেনশিয়াল স্টাফিং, টোকেন গুছানো এবং স্ক্র্যাপিং প্রায়শই ছোট ছোট অনুরোধের বেশিরভাগ দেখা দেয় একটি সংকীর্ণ IP বা অ্যাকাউন্ট সেট থেকে। এখানে আপনি কড়া সীমা ও দ্রুত ব্লকিং চান।
মাল্টি-টেন্যান্ট সিস্টেমে ন্যায্যতাও গুরুত্বপূর্ণ। এক উচক গ্রাহক অন্য সবাইকে খারাপভাবে প্রভাবিত করতে পারবে না। বাস্তবে, এতে স্তরভিত্তিক কন্ট্রোল থাকে: মিনিট-থেকে-মিনিট API সুস্থ রাখতে একটি বর্ষ গার্ড, ব্যয়বহুল এন্ডপয়েন্ট বা অ্যাকশনের জন্য একটি কস্ট গার্ড, অঅথেন্টিক বা সন্দেহভাজন প্যাটার্নের উপর ফোকাস করা একটি অ্যাবিউজ গার্ড, এবং যাতে একটি অর্গ অন্যদের ছাপিয়ে ওঠে না সেই জন্য ফেয়ারনেস গার্ড।
একটি সহজ টেস্ট সাহায্য করে: একটি এন্ডপয়েন্ট বেছে নিন এবং প্রশ্ন করুন, “যদি এই অনুরোধ 10× বাড়ে, প্রথমে কি ভাঙবে?” উত্তরটি আপনাকে বলে কোন সুরক্ষা লক্ষ্যটি অগ্রাধান্য পাবে এবং কোন ডাইমেনশন (user, org, IP) লিমিট বহন করবে।
অধিকাংশ দল একটি লিমিট দিয়ে শুরু করে এবং পরে আবিষ্কার করে এটি ভুল লোককে ক্ষতিগ্রস্ত করছে। লক্ষ্য হল এমন ডাইমেনশন বেছে নেওয়া যা বাস্তব ব্যবহারের সাথে মেলে: কে কল করছে, কে পে করছে, এবং কী দেখতে অভব্য।
SaaS-এ সাধারণ ডাইমেনশনগুলো দেখতে এইরকম:
Per-user সীমা টেন্যান্টের ভিতরে ন্যায্যতার ব্যাপার। যদি একজন ব্যক্তি বড় একটি এক্সপোর্ট চালায়, তাদের ধীর হওয়া বাকি দলের তুলনায় বেশি অনুভূত হওয়া উচিত।
Per-org সীমা বাজেট ও ক্যাপাসিটির ব্যাপার। যদি দশজন ব্যবহারকারী একসঙ্গে কাজ চালায়, সংস্থাটি এমন এক স্তরে স্পাইক করা উচিত না যা আপনার সার্ভিস বা মূল্য-অনুমান ভাঙে।
Per-IP সীমা নিরাপত্তা নেট হিসেবে বিবেচনা করা ভালো, বিলিং টুল হিসেবে নয়। IP ভাগ করা হতে পারে (অফিস NAT, মোবাইল ক্যারিয়ার), তাই এই সীমাগুলো উদার রাখুন এবং এগুলোকে প্রধানত স্পষ্ট অ্যাবিউজ থামাতে ব্যবহার করুন।
আপনি যখন ডাইমেনশনগুলো মিলিয়ে ব্যবহার করবেন, সিদ্ধান্ত নিন কোনটি “উইন” করবে যখন একাধিক লিমিট প্রযোজ্য। একটি ব্যবহারিক নিয়ম হল: যদি কোনো প্রাসঙ্গিক লিমিট অতিক্রম হয়, অনুরোধ বাতিল করুন এবং সবচেয়ে কার্যকরীয় কারণটি ফেরত দিন। যদি একটি ওয়ার্কস্পেস তার অর্গ কোটা ছাড়িয়ে যায়, ব্যবহারকারী বা IP-কে দোষারোপ করবেন না।
উদাহরণ: একটি Koder.ai ওয়ার্কস্পেস প্রো প্ল্যানে প্রতি-অর্গ ধারা অনুমতি পেতে পারে নির্মাণ অনুরোধের জন্য, একই সময়ে একটি ব্যবহারকারীকে মিনিটে শত শত অনুরোধ করা থেকে সীমাবদ্ধ করা হতে পারে। যদি একটি পার্টনার ইন্টিগ্রেশন একটি শেয়ার করা টোকেন ব্যবহার করে, একটি per-token সীমা এটিকে ইন্টারঅ্যাকটিভ ব্যবহারকারীদের দমিয়ে দেওয়া থেকে রোধ করতে পারে।
অধিকাংশ রেট লিমিটিং সমস্যা গণিতে নয়। এগুলো এমন আচরণ বেছে নেওয়া নিয়ে যা গ্রাহকরা কীভাবে API কল করে তার সাথে মেলে, তারপর লোডের অধীনে সেটা পূর্বানুমানযোগ্য রাখা।
Token bucket একটি সাধারণ ডিফল্ট কারণ এটি সংক্ষিপ্ত বর্শকে অনুমতি দেয় এবং দীর্ঘমেয়াদে একটি ধারাবাহিক গড় বজায় রাখে। একজন ব্যবহারকারী যে ড্যাশবোর্ড রিফ্রেশ করে 10 দ্রুত অনুরোধ ট্রিগার করতে পারে। টোকেন বাকেট এটা হলে সম্ভব করে যদি তাদের কাছে টোকেন জমে থাকে, তারপর ধীরে ধীরে তাদের ধীরা করে।
Leaky bucket আরও কড়া। এটি ট্র্যাফিককে একটি ধ্রুব প্রবাহে মসৃণ করে, যা তখন সাহায্য করে যখন আপনার ব্যাকএন্ড স্পাইক সহ্য করতে পারে না (উদাহরণ: ব্যয়বহুল রিপোর্ট জেনারেশন)। ফলাফল হলো গ্রাহকরা দ্রুত অনুভব করে কারণ বর্শগুলো কিউইং বা প্রত্যাখ্যানে পরিণত হয়।
উইন্ডো-ভিত্তিক কাউন্টারগুলো সহজ, কিন্তু ডিটেইলস গুরুত্বপূর্ণ। স্থির উইন্ডো গড় প্রান্ত তৈরি করে (একই ব্যবহারকারী 12:00:59-এ এবং 12:01:00-এ বর্শ করতে পারে)। স্লাইডিং উইন্ডো ন্যায্য মনে হয় এবং বর্ডার স্পাইক কমায়, কিন্তু বেশি স্টেট বা উন্নত ডাটা স্ট্রাকচার দরকার।
আরেকটি ক্লাস হল concurrency (ইন-ফ্লাইট অনুরোধ) সীমা। এটি ধীর ক্লায়েন্ট কানেকশন বা দীর্ঘ-চলমান এন্ডপয়েন্ট থেকে আপনাকে রক্ষা করে। একজন গ্রাহক সম্ভবত 60 অনুরোধ/মিনিটের মধ্যে থাকলেও 200 অনুরোধ একসাথে ওপেন রেখে আপনাকে ওভারলোড করে ফেলতে পারে।
বাস্তব সিস্টেমে, দলগুলো সাধারণত একটি ছোট সেট কন্ট্রোল মিলিয়ে ব্যবহার করে: সাধারণ রিকোয়েস্ট রেটের জন্য টোকেন-বাকেট, ধীর বা ভারী এন্ডপয়েন্টের জন্য concurrency ক্যাপ, এবং এন্ডপয়েন্ট গ্রুপ (সস্তা রিড বনাম ব্যয়বহুল এক্সপোর্ট) জন্য আলাদা বাজেট। যদি আপনি কেবল অনুরোধ গণনাই সীমাবদ্ধ করেন, একটি ব্যয়বহুল এন্ডপয়েন্ট সবকিছুকেই ঝেরিয়ে দিতে পারে এবং API র্যান্ডমভাবে ভাঙা মনে হতে পারে।
ভালো কোটা ন্যায্য ও পূর্বানুমানযোগ্য মনে হয়। গ্রাহকরা কেবল ব্লক হয়ে জান্লে নিয়ম আবিষ্কার করা উচিত নয়।
স্পষ্ট আলাদা রাখুন:
অনেক SaaS দল উভয় ব্যবহার করে: স্পাইক থামানোর জন্য একটি স্বল্প রেট লিমিট এবং মূল্য-ভিত্তিক মাসিক কোটা।
হার্ড বনাম সফট লিমিট প্রধানত সাপোর্ট পছন্দ। হার্ড লিমিট তাৎক্ষণিকভাবে ব্লক করে। সফট লিমিট প্রথমে সতর্ক করে, পরে ব্লক করে। সফট লিমিট রাগান্বিত টিকিট কমায় কারণ মানুষকে বাগ ঠিক করার বা আপগ্রেড করার সুযোগ দেয়।
যখন কেউ অতিরিক্ত ব্যবহার করে, আচরণটি এমন হওয়া উচিত যা আপনি রক্ষা করছেন। যদি অতিরিক্ত ব্যবহারে অন্য টেন্যান্ট ক্ষতিগ্রস্ত হয় বা খরচ বিস্ফোরিত হবে, তখন ব্লকিং কাজ করে। ধীর করা (প্রক্রিয়াকরণ ধীর করা বা নিম্ন অগ্রাধিকার) কাজে লাগে যখন আপনি চাইবেন কাজগুলো চলতে থাকুক। "পরে বিল করা" কাজ করতে পারে যখন ব্যবহার পূর্বানুমানযোগ্য এবং আপনার কাছে ইতিমধ্যে বিলিং ফ্লো আছে।
টিয়ার-ভিত্তিক সীমা সবচেয়ে ভাল কাজ করে যখন প্রতিটি টিয়ারের একটি স্পষ্ট “প্রত্যাশিত ব্যবহার আকৃতি” থাকে। ফ্রি টিয়ারে ছোট মাসিক কোটা এবং কম বর্শ-রেট থাকতে পারে, যখন বিজনেস ও এন্টারপ্রাইজ টিয়ারগুলো উচ্চ কোটা ও উচ্চ বর্শ সীমা পায় যাতে ব্যাকগ্রাউন্ড কাজ দ্রুত শেষ হতে পারে। এটা Koder.ai-এর ফ্রি, প্রো, বিজনেস ও এন্টারপ্রাইজ টিয়ারগুলোর ধারণার সঙ্গে অনুরূপ।
এন্টারপ্রাইজের জন্য কাস্টম লিমিট শুরুর দিকেই সমর্থন করা মূল্যবান। পরিষ্কার পদ্ধতি হলো "প্ল্যান অনুযায়ী ডিফল্ট, কাস্টমার অনুযায়ী ওভাররাইড"। প্রতিটি অর্গের (কখনও কখনও প্রতিটি এন্ডপয়েন্টের) জন্য অ্যাডমিন-সেট ওভাররাইড স্টোর করুন এবং নিশ্চিত করুন এটা প্ল্যান চেঞ্জকে টিকিয়ে রাখে। এছাড়া ঠিক করুন কে পরিবর্তন অনুরোধ করতে পারে এবং কত দ্রুত সেটা কার্যকর হবে।
উদাহরণ: একটি গ্রাহক মাসের শেষ দিনে 50,000 রেকর্ড ইমপোর্ট করে। যদি তাদের মাসিক কোটা প্রায় শেষ, 80–90% এ একটি সফট ওয়ার্ন তাদের থামার আগে সময় দেয়। প্রতি সেকেন্ডের স্বল্প রেট লিমিট ইমপোর্টকে API বানচাল করা থেকে রোধ করে। অনুমোদিত অর্গ ওভাররাইড (অস্থায়ী বা স্থায়ী) ব্যবসা চালু রাখতে সহায়তা করে।
আপনি কী গণনা করবেন ও সেটা কার সঙ্গে সম্পর্কিত তা লেখে শুরু করুন। বেশিরভাগ দল তিনটি আইডেনটিটি সহ শেষ হয়: সাইন-ইন করা ব্যবহারকারী, কাস্টমার অর্গ (বা ওয়ার্কস্পেস), এবং ক্লায়েন্ট IP।
একটি ব্যবহারিক প্ল্যান:
আপনি যখন লিমিট সেট করেন, টিয়ার ও এন্ডপয়েন্ট গ্রুপে ভাবুন, একটি গ্লোবাল সংখ্যার ওপর না। একটি সাধারণ ব্যর্থতা হল বহু অ্যাপ সার্ভারের ওপর ইন-মেমরি কাউন্টার নির্ভর করা। কাউন্টারগুলোর সাথে অসঙ্গতি দেখা দেয়, এবং ব্যবহারকারীরা “র্যান্ডম” 429 দেখে। Redis-এর মত শেয়ারড স্টোর লিমিটগুলো ইনস্ট্যান্টে স্থিতিশীল রাখে, এবং TTLs ডেটা ছোট রাখে।
রোলআউট গুরুত্বপূর্ণ। প্রথমে “report only” মোডে শুরু করুন (যা ব্লক হত তা লগ করুন), তারপর একটি এন্ডপয়েন্ট গ্রুপে প্রয়োগ করুন, তারপর বিস্তার করুন। এভাবে আপনি একটি সাপোর্ট টিকিট প্রাচীর এড়াতে পারেন।
যখন গ্রাহক একটি লিমিট হিট করে, সবচেয়ে খারাপ ফলাফল হলো বিভ্রান্তি: “আপনার API ডাউন নাকি আমি কিছু ভুল করছি?” স্পষ্ট, ধারাবাহিক রেসপন্স সাপোর্ট টিকিট কমায় এবং মানুষকে ক্লায়েন্ট আচরণ ঠিক করতে সাহায্য করে।
আপনি যখন সক্রিয়ভাবে কল ব্লক করছেন তখন HTTP 429 Too Many Requests ব্যবহার করুন। রেসপন্স বডি এমন রাখুন যাতে SDK ও ড্যাশবোর্ড সেটা পড়তে পারে।
নিচে একটি সরল JSON শেপ আছে যা per-user, per-org, এবং per-IP লিমিটগুলোর জন্য ভালো কাজ করে:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
হেডারগুলো বর্তমান উইন্ডো ও ক্লায়েন্টের পরবর্তী করণীয় ব্যাখ্যা করা উচিত। যদি আপনি শুধুমাত্র কয়েকটি যোগ করবেন, প্রথমে এইগুলো যোগ করুন: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, এবং X-Request-Id।
উদাহরণ: একজন গ্রাহকের ক্রন জব প্রতি মিনিটে চলে এবং হঠাৎ ব্যর্থ হতে শুরু করে। 429 প্লাস RateLimit-Remaining: 0 এবং Retry-After: 20 থাকলে তাঁরা তৎক্ষণাত বুঝবে এটি একটি লিমিট, সার্ভিস আউটেজ নয়, এবং তারা 20 সেকেন্ড পরে রিট্রাই করে দিতে পারে। যদি তারা X-Request-Id সাপোর্টে শেয়ার করে, আপনি দ্রুত ইভেন্টটি খুঁজে পাবেন।
আরেকটি ছোট নোং: সফল অনুরোধগুলিতেও একই হেডার ফেরত দিন। গ্রাহকরা ব্লক হওয়ার আগে দেখতে পায় তারা কতটা কাছে পৌঁছেছে।
ভালো ক্লায়েন্ট লিমিটকে ন্যায্য মনে করায়। খারাপ ক্লায়েন্ট একটি সাময়িক লিমিটকে আউটেজে পরিণত করে কারণ তারা আরও কঠোরভাবে হামলা চালায়।
যখন আপনি 429 পান, সেটাকে স্লো-ডাউন করার সিগন্যাল বিবেচনা করুন। যদি রেসপন্স আপনারকে কবে আবার চেষ্টা করতে হবে বলে (উদাহরণ: Retry-After হেডার), অন্তত সেই সময় অপেক্ষা করুন। না থাকলে exponential backoff ব্যবহার করুন এবং jitter যোগ করুন যাতে এক হাজার ক্লায়েন্ট একই মুহূর্তে রিট্রাই না করে।
রিট্রাই সীমাবদ্ধ রাখুন: চেষ্টা করার মধ্যে বিলম্বকে ক্যাপ করুন (উদাহরণ: 30–60 সেকেন্ড) এবং মোট রিট্রাই সময় ক্যাপ রাখুন (উদাহরণ: 2 মিনিট পরে থামুন এবং একটি ত্রুটি দেখান)। এছাড়াও ঘটনাটি লগ করুন যাতে ডেভেলপাররা পরে টিউন করতে পারে।
সবকিছু রিট্রাই করবেন না। অনেক ত্রুটি পরিবর্তন ছাড়া সফল হবে না: 400 ভ্যালিডেশন ত্রুটি, 401/403 অথেনটিকেশন ত্রুটি, 404 না পাওয়া, এবং 409 কনফ্লিক্টস—এসব ব্যবসায়িক নিয়মের প্রতিফলন।
রাইট এন্ডপয়েন্টে রিট্রাই ঝুঁকিপূর্ণ (create, charge, send email)। যদি টাইমআউট ঘটে এবং ক্লায়েন্ট রিট্রাই করে, আপনি ডুপ্লিকেট তৈরি করতে পারেন। idempotency কীগুলি ব্যবহার করুন: ক্লায়েন্ট প্রতিটি লজিক্যাল অ্যাকশনের জন্য একটি ইউনিক কী পাঠায়, এবং সার্ভার একই কী-র পুনরাবৃত্তির জন্য একই ফলাফল ফেরত দেয়।
ভালো SDK গুলো এটি সহজ করে দিতে পারে: তারা ডেভেলপারদের বলতে পারে স্ট্যাটাস (429), কতোক্ষণ অপেক্ষা করতে হবে, অনুরোধটি নিরাপদে রিট্রাই করা যাবে কি না, এবং একটি বার্তা যেমন “Rate limit exceeded for org. Retry after 8s or reduce concurrency.”
ফল্টির বেশিরভাগ সাপোর্ট টিকিট লিমিট নিয়ে নয়—এগুলো বিস্ময়ের কারণে হয়। যদি ব্যবহারকারীরা জানে না পরবর্তী কী হবে, তারা ধরে নেয় API ভাঙা বা অন্যায় হচ্ছে।
শুধুমাত্র IP-ভিত্তিক লিমিট ব্যবহার করা একটি সাধারণ ভুল। অনেক দল একই পাবলিক IP-র পেছনে থাকে (অফিস Wi‑Fi, মোবাইল ক্যারিয়ার, ক্লাউড NAT)। যদি আপনি IP দিয়ে ক্যাপ করেন, একটি ব্যস্ত গ্রাহক একই নেটওয়ার্কের সবাইকে ব্লক করতে পারে। Per-user এবং per-org সীমাকে অগ্রাধিকার দিন, এবং per-IP কে প্রধানত অ্যাবিউজ সেফটি নেট হিসেবে ব্যবহার করুন।
আরেকটি সমস্যা সব এন্ডপয়েন্টকে সমান ধরা। একটি সস্তা GET এবং একটি ভারী এক্সপোর্ট জব একই বাজেট শেয়ার করা উচিত নয়। নইলে গ্রাহকরা সাধারণ ব্রাউজিং করে তাদের অ্যালৌয়ে শেষ করে ফেলে, তারপর বড় কাজের চেষ্টা করলে ব্লক পায়। এন্ডপয়েন্ট গ্রুপ অনুযায়ী পৃথক বালতিগুলো রাখুন বা অনুরোধগুলোকে খরচ অনুযায়ী ওজন দিন।
রিসেট টাইমিংও স্পষ্ট করা দরকার। "প্রতি দিন রিসেট হয়" যথেষ্ট নয়। কোন টাইমজোন? রোলিং উইন্ডো না মিদনাইট রিসেট? যদি আপনি ক্যালেন্ডার রিসেট করেন, টাইমজোন বলুন। যদি রোলিং উইন্ডো করেন, উইন্ডোর দৈর্ঘ্য বলুন।
শেষে, অস্পষ্ট ত্রুটি বিশৃঙ্খলা সৃষ্টি করে। 500 বা সাধারণ JSON ফেরত দিলে মানুষ অধিক রিট্রাই করে। 429 ব্যবহার করুন এবং RateLimit হেডার যোগ করুন যাতে ক্লায়েন্ট বুদ্ধিমত্তার সঙ্গে ব্যাকঅফ নেয়।
উদাহরণ: একটি দল যদি Koder.ai এর জন্য একটি ইন্টিগ্রেশন শেয়ার করা কর্পোরেট নেটওয়ার্ক থেকে তৈরি করে, IP-একটিমাত্র ক্যাপ তাদের পুরো ওয়ার্কস্পেসকে ব্লক করতে পারে এবং র্যান্ডম আউটেজ মনে হবে। স্পষ্ট ডাইমেনশন ও স্পষ্ট 429 রেসপন্স এড়িয়ে দেয় এই সমস্যা।
আপনি সবার জন্য লিমিট চালু করার আগে, পূর্বানুমানযোগ্যতায় ফোকাস করে একটি চূড়ান্ত যাচাই করুণ:
Retry-After এবং RateLimit হেডার (Limit, Remaining, Reset) যুক্ত করুন। JSON বডিতে একটি সংক্ষিপ্ত বার্তা, কোন লিমিট হিট হয়েছে, এবং কখন রিট্রাই করতে হবে তা দিন।একটি গাট চেক: যদি আপনার প্রোডাক্টে Free, Pro, Business, Enterprise টিয়ার থাকে (যেমন Koder.ai), আপনি সোজাসুজি বলতে পারেন প্রতি মিনিটে ও প্রতি দিনে সাধারণ গ্রাহক কতটা করতে পারবে, এবং কোন এন্ডপয়েন্টগুলো আলাদা আচরণ করে।
যদি আপনি একটি 429 পরিষ্কারভাবে ব্যাখ্যা করতে না পারেন, গ্রাহকরা ধরে নেবে API ভাঙা, সার্ভিস সুরক্ষিত নয়।
কল্পনা করুন একটি B2B SaaS যেখানে মানুষ একটি ওয়ার্কস্পেসে (অর্গ) কাজ করে। কিছু পাওয়ার ইউজার ভারী এক্সপোর্ট চালায়, এবং অনেক কর্মচারী একটি শেয়ার করা অফিস IP-র পেছনে বসে। শুধুমাত্র IP দ্বারা লিমিট করলে আপনি পুরো কোম্পানিকে ব্লক করবেন। শুধুমাত্র ইউজার-ভিত্তিক লিমিট করলে একটি স্ক্রিপ্ট এখনও পুরো ওয়ার্কস্পেসকে ক্ষতিগ্রস্ত করতে পারে।
একটি ব্যবহারিক মিশ্রণ হলো:
যখন কেউ লিমিট হিট করে, আপনার মেসেজ তাঁদের বলবে কি ঘটেছে, কী করা দরকার, এবং কখন রিট্রাই করতে হবে। সাপোর্ট এইভাবে এমন শব্দভঙ্গি বলতে পারবে:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
ঐ বার্তাটির সঙ্গে Retry-After এবং ধারাবাহিক RateLimit হেডার জোড়া দিন যাতে গ্রাহকরা অনুমান করতে না বাধ্য হন।
একটি আচরণ যা বিস্ময় এড়ায়: প্রথমে observe-only, তারপর ওয়্যার্ন (হেডার ও সফট ওয়্যার্ন), তারপর কঠোর প্রয়োগ (429s স্পষ্ট রিট্রাই টাইমিংসহ), তারপর থ্রেশহোল্ড টিউন প্ল্যান অনুযায়ী, এবং বড় লঞ্চ বা কাস্টমার অনবোর্ডিংয়ের পরে রিভিউ।
আপনি যদি দ্রুতভাবে এই ধারণাগুলোকে কাজ করা কোডে পরিণত করতে চান, একটি vibe-coding প্ল্যাটফর্ম যেমন Koder.ai (koder.ai) আপনাকে ছোট একটি রেট লিমিট স্পেস প্রণয়নে এবং Go মিদলওয়্যার জেনারেট করতে সাহায্য করতে পারে যা সার্ভিস জুড়ে ধারাবাহিক প্রয়োগ নিশ্চিত করে।
একটি রেট লিমিট নির্ধারণ করে আপনি কত দ্রুত অনুরোধ করতে পারবেন—উদাহরণস্বরূপ প্রতি সেকশন বা প্রতি মিনিটে কতটি অনুরোধ। একটি কোটা নির্ধারণ করে আপনি নির্দিষ্ট একটি সময়কাল জুড়ে মোট কতটা ব্যবহার করতে পারবেন—যেমন দৈনিক, মাসিক বা বিলিং সাইকেল ভিত্তিক।
অতিরিক্ত 'ইট ওয়ার্কেড ইয়েস্টারডে' অবাক হওয়ার ঘটনা কমাতে, উভয় কথাই স্পষ্টভাবে দেখান এবং রিসেট সময় নির্দিষ্ট করে দিন যাতে গ্রাহকরা আচরণটি পূর্বাভাস করতে পারে।
আপনার বিলোপ করা সমস্যাটি কি তা দিয়ে শুরু করুন। যদি স্পাইকগুলো টাইমআউট সৃষ্টি করে, তাহলে আপনাকে শর্ট-টার্ম বর্ষ কন্ট্রোল করতে হবে; যদি নির্দিষ্ট এন্ডপয়েন্টগুলো খরচ বাড়ায়, তাহলে খরচ-ভিত্তিক বাজেট দরকার; যদি ব্রুট ফোর্স বা স্ক্র্যাপিং দেখা যায়, তাহলে কড়া অ্যাবিউজ নিয়ন্ত্রণ প্রয়োজন।
সহজ একটি উপায়: জিজ্ঞেস করুন—“এই একটাই এন্ডপয়েন্টে যদি ট্র্যাফিক 10× বাড়ে, প্রথমে কি ভাঙবে: ল্যাটেন্সি, খরচ, না সিকিউরিটি?” তারপর সেই লক্ষ্যটি ঘিরেই লিমিট ডিজাইন করুন।
প্রতি-ব্যবহারকারী সীমা ব্যবহার করুন যাতে এক জন ব্যক্তি তাদের টিমমেটদের ধীর করে না ফেলতে পারে, এবং প্রতি-সংস্থা সীমা ব্যবহার করুন যাতে একটি ওয়ার্কস্পেস একটি পূর্বানুমানযোগ্য সিলিংয়ের মধ্যে থাকে যা আপনার মূল্য নির্ধারণ ও ক্যাপাসিটির সাথে মেলে। শেয়ার করা ইন্টিগ্রেশন কির মতো ক্ষেত্রে প্রতি-টোকেন সীমা যোগ করুন যাতে একটি শেয়ার করা কী ইন্টারঅ্যাকটিভ ইউজারদের দমন না করে।
Per-IP সীমাকে প্রধানত অগ্রহণযোগ্য আচরণ থামানোর জন্য ব্যাকআপ হিসেবে বিবেচনা করুন, কারণ শেয়ার করা নেটওয়ার্কগুলো নির্দিষ্ট ব্যবহারকারীদের ব্লক করতে পারে।
টোকেন-বাকেট একটি ভালো ডিফল্ট যখন আপনি সংক্ষিপ্ত বর্শকে অনুমতি দিতে চান কিন্তু দীর্ঘ মেয়াদে গড় রেট বজায় রাখতে চান। ড্যাশবোর্ড রিফ্রেশ করার মতো UX প্যাটার্নে এটি ভালো কাজ করে, যেখানে কয়েকটি দ্রুত অনুরোধ একসঙ্গে আসে।
যদি আপনার ব্যাকএন্ড স্পাইক সহ্য করতে না পারে, তাহলে leaky bucket বা স্পষ্ট কিউইং ব্যবহার করতে পারেন—কিন্তু তা বর্শকে কম সহনশীল হবে।
যখন সমস্যাটা অনুরোধের সংখ্যা নয় বরং অনেক ইন-ফ্লাইট (উন্মুক্ত) অনুরোধের কারণে হয়, তখন concurrency সীমা যোগ করুন। ধীর এন্ডপয়েন্ট, লং-পোলিং, স্ট্রিমিং, বড় এক্সপোর্ট বা দুর্বল নেটওয়ার্ক পরিস্থিতিতে এটি প্রয়োজনীয় হয়ে ওঠে।
Concurrency ক্যাপ একটি ক্লায়েন্টকে ‘60 অনুরোধ/মিনিট’ সীমার মধ্যে থাকা সত্ত্বেও একসঙ্গে শত শত ওপেন কানেকশন ধরে রাখার থেকে বিরত রাখে।
যখন আপনি সক্রিয়ভাবে থ্রটল করছেন তখন HTTP 429 Too Many Requests ব্যবহার করুন, এবং একটি পরিষ্কার ত্রুটি বডি প্রদান করুন যাতে বলা থাকে কোন স্কোপ (user, org, IP, বা token) হিট হয়েছে এবং কখন আবার চেষ্টা করা যাবে। সবথেকে সহায়ক হেডার হল Retry-After, কারণ এটি ক্লায়েন্টকে ঠিক কতক্ষণ অপেক্ষা করতে হবে সেটাই জানায়।
সফল অনুরোধেও rate limit হেডার ফেরত দিন যাতে গ্রাহকরা ব্লক হওয়ার আগে বুঝতে পারে তারা কতটা কাছাকাছি।
সরল ডিফল্ট: যদি Retry-After উপস্থিত থাকে, অন্তত সেই সময় অপেক্ষা করুন। না থাকলে exponential backoff ব্যবহার করুন এবং jitter যোগ করুন যাতে অনেক ক্লায়েন্ট একসঙ্গে আবার চেষ্টা না করে।
রিট্রাই সীমিত রাখুন, এবং এমন ত্রুটিগুলো পুনরায় চেষ্টা করবেন না যেগুলোতে পরিবর্তন ছাড়া সফল হবে না—বিশেষ করে auth এবং ভ্যালিডেশন ত্রুটি।
হার্ড লিমিট ব্যবহার করুন যখন অতিরিক্ত ব্যবহার অন্য গ্রাহকদের ক্ষতিগ্রস্ত করতে পারে বা এমন খরচ সৃষ্টি করবে যা আপনি সহ্য করতে পারবেন না। সফট লিমিট ব্যবহার করুন যখন আপনি আগে সতর্কবার্তা দিতে চান, বাগ ঠিক করার সময় দিতে চান, অথবা গ্রাহককে আপগ্রেড করার সুযোগ দিতে চান।
প্রায়োগিক প্যাটার্ন: 80–90% হল একটি সতর্কতার থ্রেশহোল্ড, তারপর পরে প্রয়োগ করুন—এভাবে জরুরি সাপোর্ট টিকিট কমবে কিন্তু অননুমোদিত ব্যবহার চলতে থাকবে না।
IP-ভিত্তিক সীমা উদার রাখুন এবং সেগুলোকে প্রধানত অ্যাবিউজ প্যাটার্ন ঝামেলা ধরার জন্য ব্যবহার করুন, কারণ অনেক কোম্পানি NAT, অফিস Wi‑Fi বা মোবাইল ক্যারিয়ারের পেছনে একই পাবলিক IP শেয়ার করে। কড়া per-IP ক্যাপ হলে এক খারাপ স্ক্রিপ্ট পুরো গ্রাহককে ব্লক করতে পারে।
সাধারণ ব্যবহার গঠনের জন্য per-user এবং per-org সীমাকে অগ্রাধিকার দিন, এবং per-IP কে কেবল ব্যাকস্টপ হিসেবে রাখুন।
পর্যায়ক্রমে চালান যাতে আপনি প্রভাব দেখতে পারেন আগে যখন গ্রাহকরা ব্যাথা অনুভব করে। প্রথমে “report only” লগিং চালান যাতে আপনি কী ব্লক হত তা দেখতে পারেন, তারপর সীমিত এন্ডপয়েন্ট গ্রুপে প্রয়োগ করুন বা এক সাবসেট টেন্যান্টে প্রয়োগ করুন, তারপর ধীরে ধীরে বাড়ান।
429 স্পাইক, লিমিটার থেকে বাড়তি লেটেন্সি, এবং ব্লক হওয়া টপ আইডেন্টিটিগুলো মনিটর করুন—এসব সংকেত আপনাকে জানায় কোথায় থ্রেশহোল্ড বা ডাইমেনশন ভুল হয়েছে, সাপোর্টের বোঝা হওয়ার আগেই।