মূল সমস্যা: লিক, দেরি, এবং অসামঞ্জস্যপূর্ণ ফলাফল
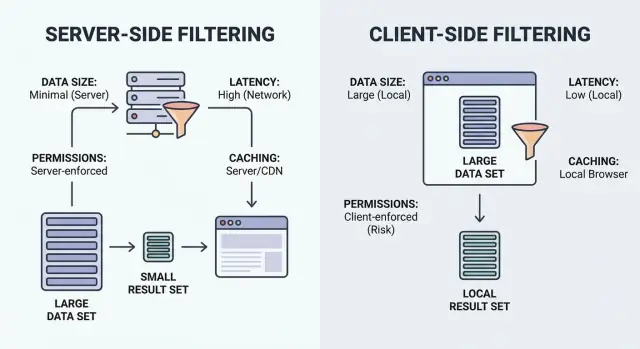
ইউআই-তে ফিল্টারিং একটিমাত্র সার্চ বক্সের বেশি কিছু। সাধারণত এতে কয়েকটি সম্পর্কিত অ্যাকশন থাকে যা ব্যবহারকারী যা দেখেন তা বদলে দেয়: টেক্সট সার্চ (নাম, ইমেইল, অর্ডার আইডি), ফ্যাসেট (স্ট্যাটাস, মালিক, তারিখ পরিসর, ট্যাগ), এবং সার্টিং (নতুন, সর্বোচ্চ ভ্যালু, শেষ কার্যকলাপ)।
মূল প্রশ্ন কোন কৌশল "ভাল"—এর চেয়ে বরং পূর্ণ ডেটাসেট কোথায় থাকে এবং কে এটি অ্যাক্সেস করার অনুমতি পাবে। যদি ব্রাউজারে এমন রেকর্ড পৌঁছে যা ব্যবহারকারী দেখতে পারবে না, তাহলে UI ভিজ্যুয়ালি লুকালে ও চললেও সংবেদনশীল ডেটা প্রকাশ পেতে পারে।
সার্ভার-সাইড বনাম ক্লায়েন্ট-সাইড ফিল্টারিং নিয়ে বেশিরভাগ বিতর্ক আসলে দুই ধরনের ব্যর্থতার প্রতি দ্রুত প্রতিক্রিয়া:
- লিক: ডেটা নেটওয়ার্ক পে-লোডে, ক্যাশড রেসপন্সে, বা আনএক্সপেক্টেড ফিল্টারের মাধ্যমে দেখা যায় যা লুকানো সারি প্রকাশ করে।
- দেরি: স্ক্রিন ধীর মনে হয় কারণ আপনি বেশি ডেটা পাঠাচ্ছেন, তারপর every keystroke-এ ডিভাইসকে ভারি কাজ করতে দেন।
একটি তৃতীয় সমস্যা আছে যা অসংখ্য বাগ রিপোর্ট তৈরি করে: অসামঞ্জস্যপূর্ণ ফলাফল। যদি কিছু ফিল্টার ক্লায়েন্টে চালানো হয় এবং অন্যগুলো সার্ভারে, ব্যবহারকারীরা কাউন্ট, পেজ এবং টোটালে মিল পায় না। পেজিনেটেড লিস্টে এটা দ্রুত বিশ্বাস ভেঙে দেয়।
প্রায়োগিক একটি ডিফল্ট সহজ: ব্যবহারকারী পুরো ডেটাসেট অ্যাক্সেস করতে পারবেন না, তাহলে সার্ভারে ফিল্টার করুন। যদি তারা অ্যাক্সেস করতে পারেন এবং ডেটাসেট দ্রুত লোড করার জন্য ছোট, তখন ক্লায়েন্ট-সাইড ফিল্টারিং ঠিক আছে।
সাধারণ সংজ্ঞা সহজ ভাষায়
ফিল্টারিং শুধু “যেগুলো মেলে সেগুলো দেখাও”। কুয়েশ্চনটা কোথায় মেলানো হচ্ছে: ব্যবহারকারীর ব্রাউজারে (ক্লায়েন্ট) না আপনার ব্যাকএন্ডে (সার্ভার)।
ক্লায়েন্ট-সাইড ফিল্টারিং ব্রাউজারে চলে। অ্যাপ বেশ কিছু রেকর্ড ডাউনলোড করে (অften JSON), তারপর লোকালি ফিল্টার প্রয়োগ করে। ডেটা লোড হলে এটি তৎক্ষণাৎ অনুভূত হতে পারে, কিন্তু এটি তখনই কাজ করে যখন ডেটাসেট ছোট এবং নিরাপদভাবে প্রকাশযোগ্য।
সার্ভার-সাইড ফিল্টারিং আপনার ব্যাকএন্ডে চলে। ব্রাউজার ফিল্টার ইনপুট পাঠায় (যেমন status=open, owner=me, createdAfter=Jan 1), এবং সার্ভার কেবল মিল করা ফলাফল ফেরত দেয়। অনুশীলনে, এটি সাধারণত একটি API এন্ডপয়েন্ট যা ফিল্টার নেয়, ডাটাবেস কুয়েরি তৈরি করে, এবং পেজিনেটেড লিস্ট প্লাস টোটাল রিটার্ন করে।
একটি সহজ মানসিক মডেল:
- ক্লায়েন্ট-সাইড: অনেক ডাউনলোড করুন, এখানেই ফিল্টার করুন।
- সার্ভার-সাইড: ঠিক যা দরকার তাই চাও।
হাইব্রিড সেটআপ সাধারণ। ভালো প্যাটার্ন হল বড় ফিল্টারগুলো সার্ভারে এন্ডফোর্স করা (পারমিশন, মালিকানা, তারিখ পরিসর, সার্চ), তারপর ছোট UI-নির্দিষ্ট টগলগুলো লোকালি ব্যবহার করা (আর্কাইভড আইটেমগুলো লুকানো, দ্রুত ট্যাগ চিপস, কলাম দৃশ্যমানতা) যাতে আরেকটি রিকোয়েস্ট দরকার না হয়।
সার্টিং, পেজিনেশন, এবং সার্চ সাধারণত একই সিদ্ধান্তের মধ্যে আসে। এগুলো পে-লোড সাইজ, ব্যবহারকারীর অনুভূতি, এবং আপনি কোন ডেটা প্রকাশ করছেন তা প্রভাবিত করে।
সিদ্ধান্ত ফ্যাক্টর ১: ডেটা সাইজ এবং পে-লোড খরচ
সবচেয়ে ব্যবহারিক প্রশ্ন দিয়ে শুরু করুন: আপনি যদি ক্লায়েন্টে ফিল্টার করেন তাহলে ব্রাউজারে কত ডেটা পাঠাবেন? যদি সৎ উত্তর হয় “কয়েকটি স্ক্রিনের চেয়ে বেশি”, তাহলে আপনি ডাউনলোড টাইম, মেমরি ব্যবহার, এবং ধীর ইন্টারেকশনের মূল্য দেবেন।
আপনি নিখুঁত অনুমান প্রয়োজন নেই। শুধু মাত্র পর্যায়-বিশ্লেষণ নিন: ব্যবহারকারী কত সারি দেখতে পারে, এবং একটি সারির গড় আকার কত? 500 আইটেমের একটি লিস্ট কয়েকটি ছোট ফিল্ড নিয়ে আলাদা, 50,000 আইটেম যেখানে প্রতিটি সারিতে লম্বা নোট, রিচ টেক্সট, বা নেস্টেড অবজেক্ট আছে তা একেবারে আলাদা।
ওয়াইড রেকর্ডই চুপচাপ পে-লোড কিলার। একটি টেবিল সারি গণনায় ছোট মনে হতে পারে কিন্তু ভারি হতে পারে যদি প্রতিটি সারিতে অনেক ফিল্ড, বড় স্ট্রিং, বা জয়েনড ডেটা (কন্ট্যাক্ট + কোম্পানি + শেষ কার্যকলাপ + ফুল ঠিকানা + ট্যাগ) থাকে। যদিও আপনি মাত্র তিনটি কলাম দেখান, টিমগুলি প্রায়ই “সব কিছু শিপ করি, কেস করব” এবং পে-লোড ফেটে যায়।
বৃদ্ধিও ভাবুন। আজ যা ঠিক আছে আগামী কয়েক মাসে কষ্টকর হয়ে উঠতে পারে। ডেটা দ্রুত বাড়লে ক্লায়েন্ট-সাইড ফিল্টারিংকে ছোট-মেয়াদী শর্টকাট হিসেবে বিবেচনা করুন, ডিফল্ট হিসেবে নয়।
রুলস অব থাম্ব:
- যদি আপনি সাধারণ মোবাইল সংযোগে পুরো ডেটাসেট আরাম করে পাঠাতে না পারেন, সার্ভারে ফিল্টার করুন।
- যদি ব্যবহারকারীরা কেবলই এক সময়ে একটি ছোট স্লাইস-ই স্পর্শ করে, সেই স্লাইস ফেচ করে সার্ভার-সাইডে ফিল্টার করুন।
- যদি ডেটাসেট ছোট, স্থিতিশীল, এবং সত্যিই প্রকাশযোগ্য হয়, ক্লায়েন্ট-সাইড ফিল্টারিং দারুণ অনুভূত হতে পারে।
শেষ পয়েন্টটি পারফরম্যান্সের চেয়েও গুরুত্বপূর্ণ। “পুরো ডেটাসেট ব্রাউজারে শিপ করা যায় কি?” এমন প্রশ্নই নিরাপত্তার প্রশ্ন। যদি উত্তর আত্মবিশ্বাসী না হয়, পাঠাবেন না।
সিদ্ধান্ত ফ্যাক্টর ২: লেটেন্সি এবং ব্যবহারকারীর অনুভূতি
ফিল্টারিংয়ের পছন্দগুলি প্রায়শই কার্যকরতার চেয়ে অনুভূতিতে ব্যর্থ হয়। ব্যবহারকারী মিলিসেকেন্ড মাপেন না—তারা বিরতি, ফ্লিকার, এবং ফলাফলগুলি দেখতে পায় যা টাইপ করার সময় উল্টে যায়।
সময় বিভিন্ন জায়গায় হারিয়ে যেতে পারে:
- নেটওয়ার্ক: রিকোয়েস্ট/রেসপন্স টাইম এবং পে-লোড সাইজ
- সার্ভার: ডাটাবেস কুয়েরি, জয়েন, সর্টিং, পারমিশন চেক
- ব্রাউজার: JSON পার্সিং, রো রেন্ডারিং, বড় অ্যারে ফিল্টার করা
এই স্ক্রিনটির জন্য "দ্রুত পর্যাপ্ত" কি তা নির্ধারণ করুন। একটি লিস্ট ভিউতে টাইপিংতে প্রতিক্রিয়াশীলতা এবং মসৃণ স্ক্রলিং দরকার হতে পারে, যেখানে একটি রিপোর্ট পেজ হালকা অপেক্ষা সহ্য করতে পারে যতক্ষণ প্রথম রেজাল্ট দ্রুত দেখায়।
শুধু অফিস Wi‑Fi-র ওপর বিচার করবেন না। ধীর কানেকশনে ক্লায়েন্ট-সাইড ফিল্টারিং প্রথম লোডের পরে দারুণ মনে হতে পারে, কিন্তু সেই প্রথম লোড ধীর হতে পারে। সার্ভার-সাইড ফিল্টারিং পে-লোড ছোট রাখে, কিন্তু প্রতিটি কীস্ট্রোক-এ রিকোয়েস্ট করলে তা ধীর মনে হতে পারে।
মানব ইনপুট অনুযায়ী ডিজাইন করুন। টাইপ করার সময় রিকোয়েস্ট ডিবাউন্স করুন। বড় রেজাল্ট সেটের জন্য প্রগ্রেসিভ লোডিং ব্যবহার করুন যাতে পেজ দ্রুত কিছু দেখায় এবং ব্যবহারকারী স্ক্রল করার সাথে সাথে মসৃণ থাকে।
সিদ্ধান্ত ফ্যাক্টর ৩: পারমিশন এবং ডেটা এক্সপোজার
পারমিশন আপনার ফিল্টারিং পন্থা ঠিক করার চেয়ে অধিক প্রাধান্য পাওয়া উচিত। ব্রাউজারে যদি কখনও এমন ডেটা চলে যায় যা ব্যবহারকারী দেখতে পারবে না, তখন আপনি ইতিমধ্যেই সমস্যায় রয়েছেন, এমনকি আপনি UI-এ এটা লুকালেও।
এই স্ক্রিনে কোন অংশগুলো সংবেদনশীল তা নামকরণ করে শুরু করুন। কিছু ফিল্ড স্পষ্ট (ইমেইল, ফোন নম্বর, ঠিকানা)। অন্যগুলো সহজে চোখে না পড়ে: ইন্টারনাল নোট, কস্ট বা মার্জিন, বিশেষ প্রাইসিং রুল, রিস্ক স্কোর, মডারেশান ফ্ল্যাগ।
বড় ফাঁদ হল “আমরা ক্লায়েন্টে ফিল্টার করি, কিন্তু কেবল অনুমোদিত সারি দেখাই।” তা একথা বোঝায় যে পুরো ডেটাসেট ডাউনলোড করা হয়েছে। যে কেউ নেটওয়ার্ক রেসপন্স পরীক্ষা করতে পারে, ডেভটুলসে খুলে দেখতে পারে, বা পে-লোড সেভ করতে পারে। UI-এ কলাম লুকানো অ্যাক্সেস কন্ট্রোল নয়।
কখন সার্ভার-সাইড ফিল্টারিং নিরাপদ ডিফল্ট
যখন অথরাইজেশন ব্যবহারকারী অনুসারে পরিবর্তিত হয়, বিশেষভাবে যখন বিভিন্ন ব্যবহারকারী ভিন্ন সারি বা ভিন্ন ফিল্ড দেখতে পারে, তখন সার্ভার-সাইড ফিল্টারিং নিরাপদ ডিফল্ট।
দ্রুত চেক:
- বিভিন্ন রোল কি ভিন্ন সারি দেখতে পায় (টিম-নির্দিষ্ট, রিজিওন-নির্দিষ্ট, assigned-to-me)?
- বিভিন্ন রোল কি ভিন্ন ফিল্ড দেখতে পায় (নোট, প্রাইসিং, PII)?
- কি রো-লেভেল নিয়ম আছে (অ্যাকাউন্ট মালিক, ডিল স্টেজ, “প্রাইভেট” ফ্ল্যাগ)?
- কি এক্সপোর্ট, সর্টিং, বা টোটাল গলা সীমাবদ্ধ তথ্য প্রকাশ করবে?
- লিক হলে কি সম্মতি সমস্যা তৈরি হবে?
যদি কোন উত্তর হ্যাঁ হয়, সার্ভারে ফিল্টার এবং ফিল্ড সিলেকশন রাখুন। কেবল সেই ডেটা পাঠান যা ব্যবহারকারী দেখতে অনুমতি পায়, এবং সার্চ, সর্ট, পেজিং, এবং এক্সপোর্টে একই নিয়ম প্রয়োগ করুন।
উদাহরণ: একটি CRM কন্ট্যাক্ট লিস্টে, রিপরা তাদের নিজস্ব অ্যাকাউন্ট দেখতে পারে, ম্যানেজাররা তাদের টিমের সব দেখেন। যদি ব্রাউজার সব কন্ট্যাক্ট ডাউনলোড করে এবং লোকালি ফিল্টার করে, একটি রিপ এখনো লুকানো অ্যাকাউন্ট রেসপন্স থেকে পুনরুদ্ধার করতে পারবে। সার্ভার-সাইড ফিল্টারিং তা প্রতিরোধ করে কারণ সার্ভার সেই রো গুলোই পাঠায় না।
সিদ্ধান্ত ফ্যাক্টর ৪: ক্যাশিং এবং ফ্রেশনেস
ক্যাশিং একটি স্ক্রিনকে মুহূর্তের মধ্যে অনুভব করাতে পারে। এটা ভুল সত্য দেখাতেও পারে। মূল বিষয় হল আপনি কী পুনরায় ব্যবহার করতে পারবেন, কতক্ষণ, এবং কোন ইভেন্টগুলো ক্যাশ মুছে ফেলবে।
ক্যাশ ইউনিট প্রথমে বেছে নিন। পুরো লিস্ট ক্যাশ করা সহজ কিন্তু সাধারণত ব্যান্ডউইডথ অপচয় করে এবং দ্রুত স্টেল হয়ে যায়। পেজ ক্যাশ করা ইনফিনিট স্ক্রলের জন্য ভাল। কুয়েরি রেজাল্ট (ফিল্টার + সর্ট + সার্চ) ক্যাশ করা সঠিক, কিন্তু ইউজার অনেক কম্বিনেশন ট্রাই করলে দ্রুত বাড়ে।
কিছু ডোমেনে ফ্রেশনেস আরও গুরুত্বপূর্ণ। ডেটা দ্রুত বদলে গেলে (স্টক লেভেল, ব্যালান্স, ডেলিভারি স্টেটাস), এমনকি ৩০ সেকেন্ড ক্যাশও ব্যবহারকারীকে বিভ্রান্ত করতে পারে। ডেটা ধীরে বদলে গেলে (আর্কাইভড রেকর্ড, রেফারেন্স ডেটা), দীর্ঘ ক্যাশ ঠিক আছে।
কোড করার আগে ইনভ্যালিডেশন প্ল্যান করুন। সময় পেরোনোর ছাড়া, কোন ঘটনাগুলো রিফ্রেশ বাধ্যতামূলক করবে তা নির্ধারণ করুন: ক্রিয়েট/এডিট/ডিলিট, পারমিশন পরিবর্তন, বাল্ক ইম্পোর্ট বা মার্জ, স্টাটাস ট্রানজিশন, আনডু/রোলব্যাক, এবং ব্যাকগ্রাউন্ড জব যা ফিল্টার করা ফিল্ড আপডেট করে।
ক্যাশ কোথায় থাকবে তাও ঠিক করুন। ব্রাউজার মেমরি ব্যাক/ফরওয়ার্ড নেভিগেশন দ্রুত করে, কিন্তু যদি আপনি এটি user ও org অনুযায়ী কী না করেন তবে এটি একাউন্টগুলোর মধ্যে ডেটা লিক করতে পারে। ব্যাকএন্ড ক্যাশিং পারমিশন ও কনসিস্টেন্সির জন্য নিরাপদ, কিন্তু কেশ কীতে পূর্ণ ফিল্টার সিগনেচার এবং কলারের পরিচয় থাকতে হবে যাতে রেজাল্ট মিশে না যায়।
ধাপে ধাপে: নতুন স্ক্রিনের জন্য কিভাবে চয়েস করবেন
লক্ষ্য অচলযোগ্য হিসেবে নিন: স্ক্রিন দ্রুত মনে হবে এবং ডেটা লিক করবে না।
একটি ব্যবহারিক সিদ্ধান্ত প্রবাহ
- শুরু করুন সবচেয়ে শক্তিশালী সীমাবদ্ধতা দিয়ে। যদি অ্যাক্সেস রোল, টিম, রিজিওন, অর্গ, বা সাবস্ক্রিপশন অনুযায়ী ভিন্ন হয়, পারমিশন জিতবে। যদি ডেটাসেট বড় বা দ্রুত বাড়ে, সাইজ জিতবে।
- ডেটা বড় বা সংবেদনশীল হলে সার্ভার-সাইডকে ডিফল্ট রাখুন। যদি আপনি পুরো ডেটাসেট ব্রাউজার কনসোল-এ লগ করতে আরামবোধ না করেন, পাঠাবেন না।
- ক্লায়েন্ট-সাইড ফিল্টারিং কেবল ছোট, নিরাপদ, পুনরায় ব্যবহৃত লিস্টের জন্য ব্যবহার করুন। স্ট্যাটাস ড্রপডাউন, ছোট ট্যাগ লিস্ট, আগে-থেকে-অনুমোদিত ফলাফলের একক পেজ।
- UI-এর আগে API আকার নির্ধারণ করুন। ফিল্টার, সর্টিং, পেজিনেশন, এবং ডিফল্টগুলো লিখে রাখুন যাতে সার্ভার এবং UI অমিল না করে।
- গার্ডরেইল যোগ করুন। ম্যাক্স পেজ সাইজ এনফোর্স করুন, টাইমআউট সেট করুন, এবং ফিল্টারিং ধীরে হলে UI কিভাবে আচরণ করবে তা ঠিক করুন (স্পিনার দেখানো, পুরানো রেজাল্ট রাখা, রিট্রাই অফার করা)।
লিক বা দেরি ঘটানোর সাধারণ ভুলগুলো
বেশিরভাগ টিম একই প্যাটার্নে পা ফেলে: একটি UI যা ডেমোতে দুর্দান্ত দেখায়, তারপর বাস্তব ডেটা, বাস্তব পারমিশন, এবং বাস্তব নেটওয়ার্ক স্পিডে ফাটল দেখা দেয়।
লিক ঘটানোর ভুল
সবচেয়ে গুরুতর ব্যর্থতা হল ফিল্টারিংকে উপস্থাপন হিসেবে Trata করা। যদি ব্রাউজারে যেকোনো রেকর্ড আসে যা ব্যবহারকারী দেখতে পারবে না, আপনি হেরে গেছেন।
দুই সাধারণ কারণ:
- দ্রুততার জন্য পুরো ডেটাসেট ব্রাউজারে পাঠানো এবং লোকালি ফিল্টার করা। যে কেউ রেসপন্স বা মেমরি-অবজেক্টে ডেটা দেখতে পাবে।
- ব্যবহারকারীর পরিচয়, অর্গ, রোল, বা পলিসি ভার্শনের উপর কেস না করে ফিল্টার করা রেসপন্স ক্যাশ করা। পারমিশন পরিবর্তন করলে পুরনো ডেটা নির্বিচারে প্রকাশ পেতে পারে।
উদাহরণ: ইন্টার্নরা কেবল তাদের রিজিওনের লিড দেখবে। যদি API সব রিজিওন রিটার্ন করে এবং ড্রপডাউন React-এ লোকালি ফিল্টার করে, ইন্টার্ন পুরো লিস্ট আবারও এক্সট্র্যাক্ট করতে পারবে।
স্ক্রিন ধীর করে এমন ভুল
দেরি প্রায়ই অনুমান থেকে আসে:
- সবসময় ধরে নেওয়া যে ক্লায়েন্ট-সাইড ফিল্টারিং দ্রুত। 50,000 সারি নিয়ে ডাউনলোড ও পার্সিং একটি ফোকাসড কুয়েরির চেয়ে ধীর হতে পারে।
- পেজিনেশন ও লোডিং স্টেট ভুলে যাওয়া। একটি স্ক্রিন যা বিশাল লিস্ট রেন্ডার হওয়া পর্যন্ত ব্লক করে থাকে তা ভাঙা মনে হয়।
একটি সূক্ষ্ম কিন্তু ব্যথাদায়ক সমস্যা হল নিয়মের অমিল। যদি সার্ভার এবং UI একইভাবে starts with না ট্রীট করে, ব্যবহারকারী কাউন্ট মেলায় না দেখবে বা আইটেম রিফ্রেশ করলে অদৃশ্য হয়ে যাবে।
শিপ করার আগে দ্রুত চেকলিস্ট
দুটি মাইন্ডসেট নিয়ে একটি চূড়ান্ত পাস করুন: একটি কৌতূহলপূর্ণ ব্যবহারকারী এবং একটি খারাপ নেটওয়ার্ক দিন।
- পে-লোড সচেতনতা: নিশ্চিত করুন রেসপন্সে কখনই সারি বা ফিল্ড নেই যা ব্যবহারকারী দেখতে না পাবে, এমনকি UI-এ লুকালেও না। টোটাল, গ্রুপ কাউন্ট, বা আইডি দেখে কেউ সীমাবদ্ধ ডেটা অনুমান করতে পারে।
- নিরাপদ লগিং: ফিল্টারগুলো প্রায়শই ইমেইল, নাম, বা আইডি ধারণ করে। সেনসিটিভ ফিল্টার মান, ফুল SQL, বা ফুল রিকোয়েস্ট বডি এমন জায়গায় লগ করবেন না যেখানে অনেক লোক অ্যাক্সেস পায়।
- ডিভাইস ও প্ল্যাটফর্মে সামঞ্জস্য: ডেস্কটপ ও মোবাইলে একই ফিল্টার প্রয়োগ করুন। পার্থক্য প্রায়শই ক্লায়েন্ট-সাইড সর্টিং, লোকেল রুল (কেস, অ্যাকসেন্ট), বা ডিফল্ট ভ্যালু থেকে আসে।
- স্পষ্ট স্টেটস: লোডিং, খালি, এবং এরর স্টেটস বোঝার মতো করুন। দ্রুত পরিবর্তন (টাইপ, ব্যাকস্পেস, টগল) টেস্ট করুন যাতে UI ফ্লিকার না করে বা স্টেলড রেজাল্ট প্রদর্শন না করে।
- ওয়ার্সট-কেস গার্ডরেইল: সর্বোচ্চ পেজ সাইজ, সর্বোচ্চ তারিখ পরিসর, এবং টাইমআউট সেট করুন। মুল্যবান কুয়েরিগুলোর বিরুদ্ধে রক্ষা করুন (ওয়াইল্ডকার্ড, অনেক OR কন্ডিশন, আনইন্ডেক্সড ফিল্ড)।
একটি সহজ টেস্ট: একটি সীমাবদ্ধ রেকর্ড তৈরি করুন এবং নিশ্চিত করুন এটি কখনই পে-লোড, কাউন্ট, বা ক্যাশে না প্রদর্শিত হয়, এমনকি যখন আপনি ব্যাপকভাবে ফিল্টার করেন বা ফিল্টার ক্লিয়ার করেন।
উদাহরণ দৃশ্য: একটি CRM কন্ট্যাক্ট লিস্ট
একটি CRM কল্পনা করুন যেখানে 200,000 কন্ট্যাক্ট আছে। সেলস রিপরা কেবল তাদের নিজ অ্যাকাউন্ট দেখতে পারে, ম্যানেজাররা তাদের টিম দেখতে পারে, এবং অ্যাডমিনরা সব দেখতে পারে। স্ক্রিনে সার্চ, ফিল্টার (স্ট্যাটাস, মালিক, শেষ কার্যকলাপ), এবং সর্টিং আছে।
ক্লায়েন্ট-সাইড ফিল্টারিং এখানে দ্রুত ব্যর্থ হয়। পে-লোড ভারী, প্রথম লোড ধীর, এবং ডেটা লিকের ঝুঁকি উচ্চ। UI সারি লুকালেও ব্রাউজার ডেটা পেয়েই গেছে। আপনি ডিভাইসেও চাপ ফেলেন: বড় অ্যারে, ভারি সর্টিং, বারবার ফিল্টার রান, বেশি মেমরি ব্যবহার, এবং পুরনো ফোনে ক্র্যাশ হওয়ার সম্ভাবনা।
একটি নিরাপদ পন্থা হল পেজিনেশনসহ সার্ভার-সাইড ফিল্টারিং। ক্লায়েন্ট ফিল্টার অপশন ও সার্চ টেক্সট সার্ভারে পাঠায়, এবং সার্ভার কেবল ব্যবহারকারী অনুমোদিত রো রিটার্ন করে, ফিল্টার ও সর্ট করা অবস্থায়।
একটি প্রায়োগিক প্যাটার্ন:
- প্রথমে পারমিশন প্রয়োগ করুন, তারপর ফিল্টার ও সর্ট।
- একবারে একটি পেজ রিটার্ন করুন (উদাহরণস্বরূপ 50 রো) এবং একটি টোটাল কাউন্ট দিন।
- কেশ সাবধানে করুন (প্রতি ইউজার বা প্রতি রোলে) যাতে পারমিশন জুড়ে রেজাল্ট মিশে না যায়।
একটি ছোট excepción যাতে ক্লায়েন্ট-সাইড ঠিক আছে: ছোট স্থির ডেটা। “Contact status”-এর মতো ৮টি মানের ড্রপডাউন একবার লোড করা যায় এবং লোকালি ফিল্টার করা ঝুঁকি বা খরচ খুব কম।
পরবর্তী ধাপ: সিদ্ধান্তগুলো ডকুমেন্ট করুন এবং কম রিরাইট নিয়ে নির্মাণ করুন
টিমগুলি সাধারণত একবার “ভুল” অপশন বেছে নেওয়ার ফলে পোড়ে না। তারা পোড়ে যখন প্রতি স্ক্রিনে আলাদা সিদ্ধান্ত নেয়, তারপর চাপের মধ্যে লিক ও ধীর পেজগুলো ঠিক করার চেষ্টা করে।
প্রতিটি স্ক্রিনের জন্য একটি ছোট সিদ্ধান্ত নোট লিখে রাখুন: ফিল্টারগুলো—ডেটাসেট সাইজ, পাঠানোর খরচ, “দ্রুত পর্যাপ্ত” কিরকম লাগে, কোন ফিল্ড সংবেদনশীল, এবং রেজাল্ট কিভাবে ক্যাশ করা হবে (বা না হবে)। সার্ভার ও UI-কে সঙ্গত রাখুন যাতে ফিল্টারিংয়ের “দুই সত্য” না দাঁড়ায়।
যদি আপনি দ্রুত স্ক্রিনগুলো Koder.ai (koder.ai) -এ তৈরি করছেন, তাহলে আগেই সিদ্ধান্ত নিন কোন ফিল্টার ব্যাকএন্ডে বাধ্যতামূলক (পারমিশন ও রো-লেভেল অ্যাক্সেস) এবং কোন ছোট UI-টগলগুলো React লেয়ারে রাখা যাবে। সেই এক সিদ্ধান্ত প্রায়ই পরে সবচেয়ে ব্যয়বহুল রিরাইটগুলো টাল দেয়।