১২ সেপ, ২০২৫·8 মিনিট
প্রোডাকশন অবজার্ভেবিলিটি স্টার্টার প্যাক — দিন এক মনিটরিং
প্রথম দিনের জন্য প্রোডাকশন অবজার্ভেবিলিটি স্টার্টার প্যাক: যোগ করার মতো নূন্যতম লগ, মেট্রিক, ও ট্রেস এবং “এটা ধীর” রিপোর্টগুলোর দ্রুত ট্রায়েজ ফ্লো।
প্রথম দিনের জন্য প্রোডাকশন অবজার্ভেবিলিটি স্টার্টার প্যাক: যোগ করার মতো নূন্যতম লগ, মেট্রিক, ও ট্রেস এবং “এটা ধীর” রিপোর্টগুলোর দ্রুত ট্রায়েজ ফ্লো।
প্রায়ই প্রথমে পুরো অ্যাপ ভেঙে পড়ে না। সাধারণত একটি ধাপই যেটা হঠাৎ ব্যস্ত হয়ে ওঠে, একটি কুয়েরি যেটা টেস্টে ঠিক ছিল, বা একটি ডিপেন্ডেন্সি যেটা টাইমআউট দিতে শুরু করে। বাস্তব ব্যবহারকারীরা বাস্তব বৈচিত্র্য নিয়ে আসে: ধীর ফোন, ফ্ল্যাকি নেটওয়ার্ক, অদ্ভুত ইনপুট, এবং অপ্রত্যাশিত সময়ে ট্র্যাফিক স্পাইক।
যখন কেউ বলে “এটা ধীর,” তারা ভীষণ ভিন্ন জিনিস বোঝাতে পারে। পেজ লোড হতে বেশি সময় নিতে পারে, ইন্টার্যাকশন ল্যাগ করতে পারে, একটি API কল টাইমআউট হতে পারে, ব্যাকগ্রাউন্ড জব জমতে পারে, বা তৃতীয়-পক্ষ সেবা সবকিছু ধীর করে দিতে পারে।
এই কারণেই আপনাকে ড্যাশবোর্ড তৈরির আগে সিগন্যাল দরকার। প্রথম দিনে, প্রতিটি এন্ডপয়েন্টের জন্য নিখুঁত চার্ট থাকার দরকার নেই। যথেষ্ট লগ, মেট্রিক, এবং ট্রেস লাগবে যাতে দ্রুত এক প্রশ্নের উত্তর পাওয়া যায়: সময় কোথায় যাচ্ছে?
শুরুতে অতিরিক্ত ইনস্ট্রুমেন্ট করারও একটি ঝুঁকি আছে। বেশি ইভেন্ট শব্দ তৈরি করে, খরচ বাড়ায়, এবং অ্যাপকেও ধীর করে দিতে পারে। খারাপ হলে টেলিমেট্রির প্রতি টিমের বিশ্বাসও কমে যায় কারণ তা অনিয়মিত ও এলোমেলো মনে হয়।
বাস্তবসম্মত প্রথম দিনের লক্ষ্য সহজ: যখন আপনি “এটা ধীর” প্রতিবেদন পান, আপনি 15 মিনিটের মধ্যে ধীর ধাপটি খুঁজে পেতে পারেন। আপনি বলতে সক্ষম হওয়া উচিত যে বোতলনেক কি ক্লায়েন্ট রেন্ডারিং-এ, API হ্যান্ডলার ও তার ডিপেন্ডেন্সিতে, ডাটাবেস বা ক্যাশে-তে, না ব্যাকগ্রাউন্ড ওয়ার্কার বা বাইরের সার্ভিস-এ।
উদাহরণ: একটি নতুন চেকআউট ফ্লো ধীর মনে হচ্ছে। অনেক টুল না থাকলেও, আপনি বলতে চান, “95% সময় পেমেন্ট প্রোভাইডার কলগুলিতে যায়,” বা “কার্ট কুয়েরি অনেক সারি স্ক্যান করছে।” যদি আপনি Koder.ai-এর মত টুল দিয়ে দ্রুত অ্যাপ বানান, সেই প্রথম দিনের বেসলাইনটি আরও জরুরি—কারণ দ্রুত শিপ করা তখনই কাজে আসে যখন আপনি দ্রুত ডিবাগ করতে পারেন।
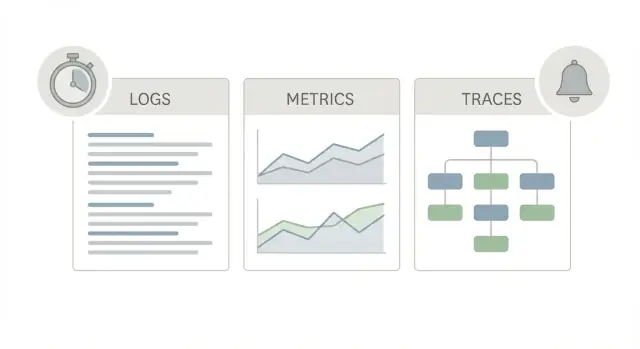
একটি ভালো প্রোডাকশন অবজার্ভেবিলিটি স্টার্টার প্যাক অ্যাপের তিনটি বিভিন্ন “ভিউ” ব্যবহার করে, কারণ প্রতিটির আলাদা প্রশ্নের উত্তর আছে।
লগস গল্প বলে। তারা বলে কী ঘটেছে একটি অনুরোধে, একটি ব্যবহারকারীতে, বা একটি ব্যাকগ্রাউন্ড জবে। একটি লগ লাইন বলতে পারে “order 123-এর জন্য পেমেন্ট ব্যর্থ” বা “DB timeout after 2s,” এবং সাথে থাকতে পারে request ID, user ID, এবং error message। কেউ যদি একটি অদ্ভুত একবারের সমস্যা রিপোর্ট করে, লগস প্রায়ই fastest way হয় সেটা নিশ্চিত করতে এবং কে প্রভাবিত হয়েছে তা জানতে।
মেট্রিক্স স্কোরবোর্ড। এগুলো সংখ্যা যা আপনি ট্রেন্ড করে দেখতে পারেন এবং এ্যালার্ট সেট করতে পারেন: request rate, error rate, latency percentiles, CPU, queue depth। মেট্রিক্স বলে কিছু বিরল নাকি ব্যাপক, এবং খারাপ হওয়া কি বাড়ছে কিনা। যদি 10:05-এ সবাইয়ের জন্য latency বেড়ে যায়, মেট্রিক্স সেটা দেখাবে।
ট্রেস হল মানচিত্র। একটি ট্রেস একটি অনুরোধকে সিস্টেম জুড়ে অনুসরণ করে (web -> API -> database -> third-party)। এটি ধাপে ধাপে দেখায় সময় কোথায় ব্যয় হচ্ছে। গুরুত্বপূর্ণ কারণ “এটা ধীর” প্রায়ই এক বড় রহস্য নয়—সাধারণত এক ধাপে ধীরতা থাকে।
একটি প্র্যাকটিক্যাল ইনসিডেন্ট ফ্লো দেখতে পারে এমন:
একটি সহজ নিয়ম: কয়েক মিনিট পরেও যদি আপনি এক বোতলনেক নির্দিষ্ট করতে না পারেন, তখন আপনাকে আরও এ্যালার্ট দরকার নেই। আপনাকে দরকার ভাল ট্রেস এবং এমন consistent IDs যা ট্রেসকে লগের সাথে যুক্ত করে।
অধিকাংশ “আমরা খুঁজে পাইনি” ইনসিডেন্ট ডেটার অভাবে নয়। তা হয় কারণ একই জিনিস সার্ভিসগুলিতে আলাদা ভাবে রেকর্ড করা হয়। প্রথম দিন কয়েকটি শেয়ারড কনভেনশন থাকলে লগ, মেট্রিক, এবং ট্রেস যখন প্রয়োজন দ্রুত মিলিয়ে যায়।
প্রতিটি deployable ইউনিটের জন্য একটি service name বেছে নিন এবং সেটা স্থিতিশীল রাখুন। যদি “checkout-api” আপনার ড্যাশবোর্ডগুলোর অর্ধেকেই “checkout” হয়ে যায়, আপনি ইতিহাস হারাবেন এবং অ্যালার্ট ভাঙবে। environment labels-ও একই করুন—ছোট সেট বেছে নিন যেমন prod এবং staging, এবং সেগুলোরা সর্বত্র ব্যবহার করুন।
এর পরে, প্রতিটি রিকোয়েস্টকে অনুসরণযোগ্য করুন। এজ-এ (API gateway, web server, বা প্রথম handler) একটি request ID জেনারেট করুন এবং তা HTTP কল, message queue, এবং ব্যাকগ্রাউন্ড জবগুলিতে পাস করুন। যদি একটি সাপোর্ট টিকিট বলে “10:42-এ এটি ধীর ছিল,” একটি সিঙ্গেল ID আপনাকে সঠিক লগ এবং ট্রেস টেনে আনতে দেয় ধরে নিয়ে।
একটি কনভেনশন সেট যা প্রথম দিনে ভাল কাজ করে:
সময় ইউনিটগুলি আগে থেকেই নির্ধারণ করুন। API latency-র জন্য milliseconds বেছে নিন এবং বড় জবগুলির জন্য seconds, এবং তা মেনে চলুন। মিশ্র ইউনিট চার্টকে ঠিক দেখালেও ভুল গল্প বলবে।
একটি সহজ উদাহরণ: যদি প্রতিটি API duration_ms, route, status, এবং request_id লগ করে, তাহলে “tenant 418-এর জন্য checkout ধীর” রিপোর্টটি দ্রুত ফিল্টার হয়ে যাবে, বিতর্ক নয়।
যদি আপনি শুধুই একটাই করেন, আপনার লগগুলোকে সার্চ করা সহজ করুন। সেটা শুরু হয় structured logs (সাধারণত JSON) দিয়ে এবং প্রতিটি সার্ভিসে একই ফিল্ড রাখার মাধ্যমে। লোকাল ডেভের জন্য plain text ঠিক আছে, কিন্তু যখন বাস্তব ট্র্যাফিক, রেট্রাই, এবং একাধিক ইনস্ট্যান্স আসে তখন এগুলো শব্দে পরিণত হয়।
একটি ভালো নিয়ম: আপনি যা ইনসিডেন্টে ব্যবহার করবেন সেটাই লগ করুন। বেশিরভাগ টিমের উত্তর জানা দরকার: এইটি কি রিকোয়েস্ট ছিল? কে এটা করেছিল? কোথায় ব্যর্থ হলো? এটা কী স্পর্শ করেছে? যদি একটি লগ লাইন এইগুলোর কোনো একটিতেই সাহায্য না করে, সম্ভবত সেটা থাকা উচিত নয়।
প্রথম দিনের জন্য ছোট, consistent ফিল্ড সেট রাখুন যাতে আপনি সার্ভিস জুড়ে ফিল্টার এবং জয়েন করতে পারেন:
যখন একটি এরর হয়, একবার লগ করুন, কনটেক্সট সহ। একটি error type (বা code), একটি সংক্ষিপ্ত message, সার্ভার এররগুলোর জন্য stack trace, এবং সংশ্লিষ্ট upstream dependency (উদাহরণ: postgres, payment provider, cache) অন্তর্ভুক্ত করুন। প্রতিটি রিট্রাইতে একই stack trace বারবার লগ করা থেকে বিরত থাকুন—এর পরিবর্তে request_id যুক্ত করুন যাতে আপনি চেইনটি অনুসরণ করতে পারেন।
উদাহরণ: একটি ব্যবহারকারী বলে সেটিংস সেভ করতে পারছে না। request_id দিয়ে একটি সার্চ করলে PATCH /settings এ 500 দেখায়, তারপর Postgres টাইটমআউট duration_ms সহ। আপনাকে পূর্ণ payload-ই লাগেনি, কেবল route, user/session, এবং dependency নামই যথেষ্ট ছিল।
প্রাইভেসি লগিংয়ের অংশ—পরবর্তী কাজ নয়। পাসওয়ার্ড, টোকেন, auth হেডার, পূর্ণ রিকোয়েস্ট বডি, বা সংবেদনশীল PII লগ করবেন না। যদি আপনাকে ব্যবহারকারী নির্ধারণ করতে হয়, একটি স্থিতিশীল ID (বা হ্যাশ করা মান) লগ করুন ইমেইল বা ফোন নম্বরের বদলে।
আপনি যদি Koder.ai (React, Go, Flutter) ব্যবহার করে অ্যাপ তৈরি করেন, এই ফিল্ডগুলো শুরু থেকেই প্রতিটি জেনারেটেড সার্ভিসে বেক করা উচিত যাতে আপনার প্রথম ইনসিডেন্টের সময় “লগিং ঠিক করা” করতে না হয়।
একটি ভালো স্টার্টার প্যাক ছোট সেটের মেট্রিক্স দিয়ে শুরু করে যা দ্রুত একটি প্রশ্নের উত্তর দেয়: সিস্টেম কি এখন সুস্থ, এবং যদি না হয়, কোথায় সমস্যা হচ্ছে?
বেশিরভাগ প্রোডাকশন সমস্যা চারটি “golden signals”-এর একটি হিসেবে দেখা দেয়: latency (response ধীরে আসে), traffic (লোড বদলেছে), errors (ফেইল), এবং saturation (কোনো শেয়ার করা রিসোর্স পূর্ণ)। যদি আপনি অ্যাপের প্রতিটি বড় অংশের জন্য এই চার সিগন্যাল দেখতে পান, অধিকাংশ ইনসিডেন্ট আপনি অনুমান ছাড়াই ট্রায়েজ করতে পারবেন।
Latency-র জন্য percentiles রাখুন, averages নয়। p50, p95, p99 ট্র্যাক করুন যাতে আপনি দেখতে পান কখন একটি ছোট গ্রুপ ব্যবহারকারী খারাপ অভিজ্ঞতা পাচ্ছে। ট্র্যাফিকের জন্য requests per second শুরু করুন (ওয়ার্কারদের জন্য jobs per minute)। এররগুলিকে 4xx বনাম 5xx আলাদা করুন: 4xx বাড়লে সাধারণত ক্লায়েন্ট আচরণ বা ভ্যালিডেশন পরিবর্তন বোঝায়; 5xx বাড়লে আপনার অ্যাপ বা তার ডিপেনডেন্সি বোঝায়। Saturation হলো “আমরা কোনো কিছুতে শেষ হয়ে আসছি” সিগন্যাল (CPU, memory, DB connections, queue backlog)।
একটি ন্যূনতম সেট যা বেশিরভাগ অ্যাপকে কভার করে:
একটি বাস্তব উদাহরণ: ব্যবহারকারীরা জানায় “এটা ধীর” এবং API p95 latency spike হয়েছে কিন্তু ট্র্যাফিক স্থির থাকলে, পরের চেক হোক saturation। যদি DB pool usage max-এর কাছে আটকে থাকে এবং timeouts বাড়ে, আপনি সম্ভবত বোতলনেক খুঁজে পেয়েছেন। DB ঠিক থাকলে কিন্তু queue depth দ্রুত বাড়লে, ব্যাকগ্রাউন্ড কাজ সম্ভবত শেয়ার করা রিসোর্স খাচ্ছে।
আপনি যদি Koder.ai-তে অ্যাপ বানান, এই চেকলিস্টটিকে আপনার দিন-এক ডিফিনিশন অফ ডান হিসেবে বিবেচনা করুন। অ্যাপ ছোটৰ সময়ে এই মেট্রিক যোগ করা সহজ—প্রথম সত্যিকারের ইনসিডেন্টের সময় নয়।
যদি একজন ব্যবহারকারী বলে “এটি ধীর,” লগস প্রায়ই বলে কী ঘটেছে, এবং মেট্রিক্স বলে কতবার ঘটছে। ট্রেস এক অনুরোধের ভিতরে সময় কোথায় গেছে তা বলে। সেই সিঙ্গেল টাইমলাইন একটি অনির্দিষ্ট অভিযোগকে স্পষ্ট ফিক্সে পরিণত করে।
সার্ভার সাইডে শুরু করুন। আপনার অ্যাপের এজে (প্রথম handler) ইনবাউন্ড রিকোয়েস্ট ইনস্ট্রুমেন্ট করুন যাতে প্রতিটি রিকোয়েস্ট একটি ট্রেস তৈরি করতে পারে। ক্লায়েন্ট-সাইড ট্রেসিং পরে করা যায়।
একটি ভাল দিন-এক ট্রেসে spanগুলো এমনভাবে মানচিত্র করা উচিত যেগুলো সাধারণত ধীরতার কারণ হয়:
ট্রেসগুলো searchable এবং তুলনাযোগ্য করতে কয়েকটি কী অ্যাট্রিবিউট consistent ভাবে ধরুন।
ইনবাউন্ড request span-এ route (টেমপ্লেট ব্যবহার করুন /orders/:id এর মত, পুরো URL নয়), HTTP method, status code, এবং latency রেকর্ড করুন। ডাটাবেস span-এ DB system (PostgreSQL, MySQL), operation type (select, update), এবং টেবিল নাম যদি সহজে যোগ করা যায় তা রেকর্ড করুন। এক্সটার্নাল কলের জন্য dependency name (payments, email, maps), target host, এবং status রেকর্ড করুন।
ডে-ওয়ানে স্যাম্পলিং গুরুত্বপূর্ণ—না হলে খরচ এবং শব্দ দ্রুত বাড়ে। একটি সাধারণ head-based রুল ব্যবহার করুন: errors এবং slow requests (যদি SDK সাপোর্ট করে) 100% trace করুন, এবং নরম্যাল ট্র্যাফিকের একটি ছোট শতাংশ (১–১০%) স্যাম্পল করুন। ট্র্যাফিক কম থাকলে উচ্চ থেকে শুরু করুন এবং ব্যবহার বাড়লে কমান।
“ভালো” কেমন দেখাবে: একটি ট্রেস যেখানে আপনি টপ টু বটম গল্পটি পড়তে পারেন। উদাহরণ: GET /checkout 2.4s নিয়েছে, DB 120ms নিয়েছে, cache 10ms, এবং একটি external payment call 2.1s নিয়েছে রিট্রাই সহ। এখন আপনি জানেন সমস্যা dependency-তে, আপনার কোডে নয়। এটাই প্রোডাকশন অবজার্ভেবিলিটি স্টার্টার প্যাকের কেন্দ্রীয় অংশ।
যখন কেউ বলে “এটা ধীর,” দ্রুত জয় হলো সেই অনির্দিষ্ট অনুভূতিটিকে কয়েকটি কংক্রিট প্রশ্নে পরিণত করা। এই স্টার্টার প্যাক ট্রাইএজ ফ্লো এমনকি আপনার অ্যাপ যদি সম্পূর্ণ নতুনও হয় কাজ করে।
সমস্যা সংকুচিত করে শুরু করুন, তারপর প্রমাণ অনুসরণ করুন। সরাসরি ডাটাবেসে ঝাঁপানো যায় না।
স্থিতিশীল করার পরে, একটি ছোট উন্নতি করুন: কী ঘটেছিল লিপিবদ্ধ করুন এবং একটি অনুপস্থিত সিগন্যাল যোগ করুন। উদাহরণ: যদি আপনি বলতে না পেরেছেন slowdown শুধুই একটি রিজিয়নে কিনা, latency মেট্রিকে region ট্যাগ যোগ করুন। যদি একটি দীর্ঘ DB span দেখা যায় কিন্তু কোন কুয়েরি ছিল তা অজানা থাকে, সাবধানে query labels বা একটি “query name” ফিল্ড যোগ করুন।
একটি দ্রুত উদাহরণ: যদি checkout p95 400ms থেকে 3s-এ লাফিয়ে যায় এবং ট্রেসগুলো বলে payment call-এ 2.4s যাচ্ছে, আপনি অ্যাপ কোড নিয়ে বিতর্ক বন্ধ করে provider, retries, এবং timeouts-এ ফোকাস করতে পারবেন।
যখন কেউ বলে “এটা ধীর,” আপনি ঠিক বোঝার আগে এক ঘণ্টা নষ্ট করতে পারেন। একটি স্টার্টার প্যাক তখনই ব্যবহার্য যখন সেটি আপনাকে দ্রুত সমস্যা সংকুচিত করতে সাহায্য করে।
তিনটি স্পষ্টকারী প্রশ্ন দিয়ে শুরু করুন:
তারপর কয়েকটি সংখ্যার দিকে তাকান যা সাধারণত বলে দেয় কোথায় যেতে হবে। নিখুঁত ড্যাশবোর্ড খোঁজার দরকার নেই—আপনি কেবল “স্বাভাবিকের চেয়ে খারাপ” সিগন্যাল চান।
যদি p95 বাড়ছে কিন্তু errors স্থির থাকে, গত ১৫ মিনিটের সবচেয়ে ধীর route-এর একটি trace খুলুন। একটি সিঙ্গেল ট্রেস প্রায়ই দেখায় সময় DB, external API, অথবা locks-এ ব্যয় হচ্ছে কিনা।
তারপর একটি লগ সার্চ করুন। যদি আপনার কাছে একটি নির্দিষ্ট ব্যবহারকারী রিপোর্ট থাকে, তাদের request_id (বা correlation ID) দিয়ে সার্চ করে টাইমলাইন পড়ুন। যদি না থাকে, একই সময় উইন্ডোতে সবচেয়ে কমন error message সার্চ করে দেখুন সেটা slowdown-এর সাথে মিলছে কি না।
শেষে, সিদ্ধান্ত নিন কি এখনই mitigat e করবেন না কি গভীরে ডুব দেবেন। যদি ব্যবহারকারীরা বাধাগ্রস্ত এবং saturation উচ্চ, একটি দ্রুত mitigation (scale up, roll back, বা একটি নন-এসেনশিয়াল feature flag ডিসেবল করা) সময় কিনে দিতে পারে। যদি প্রভাব ছোট এবং সিস্টেম স্থিতিশীল, ট্রেস ও slow query logs নিয়ে গভীরে তদন্ত চালান।
একটি রিলিজের কয়েক ঘণ্টা পরে support টিকিট আসে: “Checkout 20–30 সেকেন্ড নিচ্ছে।” কেউ নিজের ল্যাপটপে পুনরুৎপাদন করতে পারছে না, তাই অনুমান শুরু হয়। এখানেই স্টার্টার প্যাক মূল্যবান।
প্রথমে মেট্রিকসে যান এবং লক্ষণ নিশ্চিত করুন। HTTP অনুরোধের p95 latency চার্ট স্পষ্ট স্পাইক দেখায়, কিন্তু কেবল POST /checkout-এর জন্য। অন্যান্য রুটগুলি স্বাভাবিক, এবং error rate স্থির। তা সংকুচিত করে “সাইট সব জায়গায় ধীর নয়” থেকে “একটি এন্ডপয়েন্ট রিলিজের পরে ধীর”।
পরে ধীর POST /checkout-এর জন্য একটি ট্রেস খুলুন। ট্রেস ওয়াটারফল কারণে স্পষ্ট করে দেয়। দুইটি সাধারণ ফলাফল:
এখন logs দিয়ে ভ্যালিডেট করুন, ট্রেসের request ID (বা trace ID যদি আপনি সেটা লগে রাখেন) ব্যবহার করে। ঐ request-এর লগে repeated warnings দেখা যাবে যেমন “payment timeout reached” বা “context deadline exceeded,” এবং নতুন রিলিজে যোগ করা রিট্রাই গুলো দেখা যাবে। যদি DB পথ হয়, লগে lock wait messages বা slow query statement দেখা যেতে পারে।
তিনটি সিগন্যাল একসাথে মিললে ফিক্স সরাসরি হয়ে যায়:
মূল কথা: আপনি হান্ট করেননি। মেট্রিক্স এন্ডপয়েন্ট দেখালো, ট্রেস ধীর ধাপ দেখালো, এবং লগস নির্দিষ্ট রিকোয়েস্ট নিয়ে ব্যর্থতার মোড নিশ্চিত করলো।
অধিকাংশ ইনসিডেন্ট সময় এড়ানো যোগ্য গ্যাপে নষ্ট হয়: ডেটা আছে, কিন্তু শব্দময়, ঝুঁকিপূর্ণ, বা এমন কিছু অনুপস্থিত যা লক্ষণকে কারণের সাথে জোড়া দেয়। একটি স্টার্টার প্যাক কেবল তখনই কাজে লাগবে যদি তা চাপের অধীনে ব্যবহারযোগ্য থাকে।
একটি সাধারণ ফাঁদ হল খুব বেশি লগ করা, বিশেষত raw request bodies। এটা কাজে লাগতে পারে শুনতে, কিন্তু আপনি বড় স্টোরেজের জন্য টাকা দিবেন, সার্চ ধীর হয়ে যাবে, এবং আপনি ভুল করে পাসওয়ার্ড বা টোকেন বা ব্যক্তিগত ডাটা ক্যাপচার করতে পারেন। structured fields (route, status code, latency, request_id) পছন্দ করুন এবং ইনপুট থেকে ছোট, স্পষ্টভাবে অনুমোদিত অংশগুলোই লগ করুন।
আরেকটি সময়-সটান ভুল হল মেট্রিক্স যা বিশদ মনে হলেও aggregate করা অসম্ভব। high-cardinality labels যেমন পুরো user IDs, ইমেইল, বা ইউনিক order numbers আপনার metric series count বিস্ফোরিত করে এবং ড্যাশবোর্ড অবিশ্বস্ত করে। পরিবর্তে coarse labels ব্যবহার করুন (route name, HTTP method, status class, dependency name), এবং যা user-specific তা লগে রাখুন।
প্রখ্যাত ভুলগুলো যা দ্রুত নির্ণয়ে বাধা দেয়:
একটি ছোট ব্যবহারিক উদাহরণ: যদি checkout p95 800ms থেকে 4s-এ লাফায়, আপনি দুই প্রশ্নের উত্তর কয় মিনিটে চান: এটা কি ঠিক রিলিজের পরে শুরু হয়েছে, এবং সময় কি আপনার অ্যাপে ব্যয় হচ্ছে না কোনো dependency-তে? percentiles, একটি release tag, এবং route + dependency নামসহ ট্রেস থাকলে আপনি দ্রুত সেখানে পৌঁছাতে পারবেন। না হলে আপনি ইনসিডেন্ট উইন্ডো জ্বালিয়ে ফেলবেন অনুমান নিয়ে তর্কে।
বাস্তব জয় হল কনসিসটেন্সি। একটি স্টার্টার প্যাক কেবল তখনই সাহায্য করে যখন প্রতিটি নতুন সার্ভিস একই মৌলিক জিনিস নিয়ে শিপ হয়, একইভাবে নামকরণ করা হয়, এবং কিছু ভুল হলে সহজে খুঁজে পাওয়া যায়।
আপনার দিন-এক সিদ্ধান্তগুলোকে একটি ছোট টেমপ্লেটে পরিণত করুন যা টিম বারবার ব্যবহার করে। ছোট কিন্তু নির্দিষ্ট রাখুন।
একটি “home” ভিউ তৈরি করুন যা কেউ ইনসিডেন্টে খুলতে পারে। একটি স্ক্রিন দেখানো উচিত requests per minute, error rate, p95 latency, এবং আপনার প্রধান saturation মেট্রিক, environment এবং version ফিল্টারের সাথে।
শুরুতে alerting কম রাখুন। দুটি অ্যালার্টই অনেক কভার করে: একটি key route-এ error rate spike, এবং একই route-এ p95 latency spike। বেশি যোগ করলে, প্রতিটির একটি স্পষ্ট অ্যাকশন থাকুক।
শেষে, একটি মাসিক রিভিউ সেট করুন। নিশব্দ অ্যালার্ট সরান, নামকরণ শক্ত করুন, এবং গত ইনসিডেন্টে সময় বাঁচাতে পারত এমন একটি অনুপস্থিত সিগন্যাল যোগ করুন।
এইটিকে আপনার বিল্ড প্রসেসে বেক করতে, আপনার রিলিজ চেকলিস্টে একটি “observability gate” যোগ করুন: request IDs, version tags, home view, এবং দুটি বেসলাইন অ্যালার্ট ছাড়া কোনো deploy নেই। যদি আপনি Koder.ai দিয়ে শিপ করেন, আপনি planning mode-এ এই দিন-এক সিগন্যালগুলো সংজ্ঞায়িত করতে পারেন ডিপ্লয়-এর আগে, তারপর snapshots এবং rollback ব্যবহার করে দ্রুত সমন্বয় করতে পারেন।
Start with the first place users enter your system: the web server, API gateway, or your first handler.
request_id and pass it through every internal call.route, method, status, and duration_ms for every request.That alone usually gets you to a specific endpoint and a specific time window fast.
Aim for this default: you can identify the slow step in under 15 minutes.
You don’t need perfect dashboards on day one. You need enough signal to answer:
Use them together, because each answers a different question:
During an incident: confirm impact with metrics, find the bottleneck with traces, explain it with logs.
Pick a small set of conventions and apply them everywhere:
Default to structured logs (often JSON) with the same keys everywhere.
Minimum fields that pay off immediately:
Start with the four “golden signals” per major component:
Then add a tiny component checklist:
Instrument server-side first so every inbound request can create a trace.
A useful day-one trace includes spans for:
Make spans searchable with consistent attributes like (template form), , and a clear dependency name (for example , , ).
A simple, safe default is:
Start higher when traffic is low, then reduce as volume grows.
The goal is to keep traces useful without exploding cost or noise, and still have enough examples of the slow path to diagnose it.
Use a repeatable flow that follows evidence:
These mistakes burn time (and sometimes money):
service_name, environment (like prod/staging), and versionrequest_id generated at the edge and propagated across calls and jobsroute, method, status_code, and tenant_id (if multi-tenant)duration_ms)The goal is that one filter works across services instead of starting over each time.
timestamp, level, service_name, environment, versionrequest_id (and trace_id if available)route, method, status_code, duration_msuser_id or session_id (a stable ID, not an email)Log errors once with context (error type/code + message + dependency name). Avoid repeating the same stack trace on every retry.
routestatus_codepaymentspostgrescacheWrite down the one missing signal that would have made this faster, and add it next.
Keep it simple: stable IDs, percentiles, clear dependency names, and version tags everywhere.