১৬ জানু, ২০২৬·7 মিনিট
নথি-কেন্দ্রিক ওয়ার্কফ্লো: ডেটা মডেল ও UI প্যাটার্ন
নথি-কেন্দ্রিক ওয়ার্কফ্লো সম্পর্কে ব্যবহারিক ডেটা মডেল ও UI প্যাটার্ন — ভার্সন, প্রিভিউ, মেটাডেটা এবং স্পষ্ট স্ট্যাটাস স্টেট নিয়ে সংক্ষিপ্ত ব্যাখ্যা।
নথি-কেন্দ্রিক ওয়ার্কফ্লো সম্পর্কে ব্যবহারিক ডেটা মডেল ও UI প্যাটার্ন — ভার্সন, প্রিভিউ, মেটাডেটা এবং স্পষ্ট স্ট্যাটাস স্টেট নিয়ে সংক্ষিপ্ত ব্যাখ্যা।
একটি অ্যাপ নথি-কেন্দ্রিক হলে অর্থ হলো নথিটাই ব্যবহারকারীরা তৈরি করে, পর্যালোচনা করে এবং যেটার ওপর নির্ভর করে। অভিজ্ঞতা এমনভাবে গঠিত যে ফাইলগুলো—PDF, ইমেজ, স্ক্যান এবং রসিদ—ই প্রধান, না যে কোনো ফর্ম যেখানে ফাইল কেবল সংযুক্তি।
নথি-কেন্দ্রিক ওয়ার্কফ্লোতে লোকেরা আসলে নথির ভেতরে কাজ করে: তারা খুলে দেখে কী বদলেছে, প্রসঙ্গ যোগ করে, এবং সিদ্ধান্ত নেয় পরবর্তী পদক্ষেপ কী হবে। যদি নথির প্রতি বিশ্বাস না থাকে, অ্যাপের উপযোগিতা শেষ হয়ে যায়।
বেশিরভাগ নথি-কেন্দ্রিক অ্যাপের জন্য কয়েকটি মূল স্ক্রিন প্রথম দিকে থাকা দরকার:
সমস্যাগুলো দ্রুত দেখা দেয়। ব্যবহারকারী একই রসিদ দু’বার আপলোড করে। কেউ কোনও PDF এডিট করে আবার আপলোড করে কিন্তু কারণ জানায় না। একটি স্ক্যানে তারিখ, বিক্রেতা বা মালিক নেই। কয়েক সপ্তাহ পর কেউ জানে না কোন ভার্সন অনুমোদিত হয়েছে বা সিদ্ধান্তটা কিসের ভিত্তিতে নেওয়া হয়েছিল।
একটি ভাল নথি-কেন্দ্রিক অ্যাপ দ্রুত ও নির্ভরযোগ্য বোধ করায়। ব্যবহারকারী seconds-এ উত্তর পেতে সক্ষম হওয়া উচিত:
এই পরিষ্কারতা تعريف থেকে আসে। স্ক্রিন বানানোর আগে নির্দিষ্ট করুন আপনার অ্যাপে “ভার্সন,” “প্রিভিউ,” “মেটাডাটা,” এবং “স্ট্যাটাস” কী বোঝায়। যদি এই সংজ্ঞাগুলো অস্পষ্ট থাকে, আপনি ডুপ্লিকেট, বিভ্রান্ত ইতিহাস, এবং এমন রিভিউ ফ্লো পাবেন যা বাস্তব কাজের সাথে মেলে না।
UI সাধারণত সহজ দেখায় (একটি তালিকা, একটি ভিউয়ার, কয়েকটি বোতাম), কিন্তু ডেটা মডেলই ভার বহন করে। যদি মূল অবজেক্টগুলো ঠিক থাকে, তখন অডিট ইতিহাস, দ্রুত প্রিভিউ এবং নির্ভরযোগ্য অনুমোদন অনেক সহজ হয়।
শুরু করুন “ডকুমেন্ট রেকর্ড” এবং “ফাইল কনটেন্ট” আলাদা করে ভাবা থেকে। রেকর্ড হচ্ছে ব্যবহারকারীর যা নিয়ে কথা বলা হয় (ACME-র ইনভয়েস, ট্যাক্সি রসিদ)। কনটেন্ট হচ্ছে বাইনারি (PDF, JPG) যা প্রতিস্থাপন, পুনরপ্রক্রিয়াজাত বা সরানো হতে পারে কিন্তু অ্যাপে নথির অর্থ বদলায় না।
একটি ব্যবহারিক অবজেক্ট সেট মডেল করুন:
নির্ধারণ করুন কীকে এমন একটি ID দেবেন যা কখনো বদলাবে না। একটি উপকারী নিয়ম: Document ID চিরকাল থাকবে, আর Files এবং Previews পুনরায় তৈরি করা যাবে। Versions-ও স্থিতিশীল ID প্রয়োজন, কারণ মানুষ বলেন “গতকাল এটা কেমন দেখাচ্ছিল” এবং আপনাকে অডিট ট্রেইল দেখাতে হবে।
রিলেশনশিপগুলো স্পষ্টভাবে মডেল করুন। একটি Document-এর অনেক Version থাকবে। প্রতিটি Version-এর বিভিন্ন Previews (বিভিন্ন আকার বা ফরম্যাট) থাকতে পারে। এভাবে তালিকা স্ক্রিনগুলো হালকা প্রিভিউ ডেটা লোড করে দ্রুত থাকে, আর ডিটেইল স্ক্রিনগুলো প্রয়োজন হলে পুরোনো ফাইল লোড করে।
উদাহরণ: ব্যবহারকারী একটারকম ভাঁজ করা রসিদ ছবি আপলোড করে। আপনি একটি Document তৈরি করেন, মূল File সংরক্ষণ করেন, একটি থাম্বনেইল তৈরি করেন, এবং Version 1 তৈরি করেন। পরে ব্যবহারকারী একটি স্পষ্ট স্ক্যান আপলোড করে। সেটি Version 2 হয়, মন্তব্য, অনুমোদন বা সার্চ যেগুলো Document-এ যুক্ত ছিল সেগুলো ভেঙে দেয় না।
মানুষ আশা করে নথি সময়ের সঙ্গে বদলে যাবে কিন্তু “একটি ভিন্ন আইটেমে” পরিণত হবে না। সহজ উপায় হল পরিচয় (Document) কে কনটেন্ট (Version ও Files) থেকে আলাদা রাখা।
স্থায়ী document_id দিয়ে শুরু করুন যা কখনো বদলাবে না। ব্যবহারকারী একই PDF পুনরায় আপলোড করলেও, ঝেড়ে দেয়া ছবি বদলে দিলেও বা সংশোধিত স্ক্যান আপলোড করলেও তা একই ডকুমেন্ট রেকর্ডেই থাকুক। মন্তব্য, অ্যাসাইনমেন্ট এবং অডিট লগ একটি টেকসই ID তে পরিষ্কারভাবে সংযুক্ত থাকবে।
প্রতিটি অর্থবহ পরিবর্তনকে একটি নতুন version সারি হিসেবে ট্রিট করুন। প্রতিটি ভার্সনকে কে তৈরি করেছে ও কখন তা ধরতে হবে, প্লাস স্টোরেজ পয়েন্টার (file key, checksum, size, page count) এবং ডেরিভেটিভ আর্টিফ্যাক্ট (OCR টেক্সট, প্রিভিউ ইমেজ) যেগুলো সেই সুনির্দিষ্ট ফাইলে সম্পর্কিত। ইন-প্লেস এডিট এড়িয়ে চলুন—প্রথমে এটা সহজ মনে হলেও ট্রেসিবিলিটি নষ্ট করে এবং বাগ আনরোল করা কঠিন করে দেয়।
দ্রুত রিডের জন্য, ডকুমেন্টে একটি current_version_id রাখুন। বেশিরভাগ স্ক্রিন শুধু “সর্বশেষ” দেখায়, তাই প্রতিবার ভার্সন সাজাতে হয় না। যখন ইতিহাস দেখাতে হবে, আলাদা ভার্সন লোড করে পরিষ্কার টাইমলাইন দেখান।
রোলব্যাক আসলে কেবল একটি পয়েন্টার পরিবর্তন। কিছু মুছার বদলে current_version_id পুরনো ভার্সনে ফিরিয়ে দিন। এটা দ্রুত, নিরাপদ, এবং অডিট ট্রেইল অক্ষুণ্ণ রাখে।
ইতিহাস বোঝার যোগ্য রাখতে প্রতিটি ভার্সন কেন আছে তা রেকর্ড করুন। একটি ছোট, ধারাবাহিক reason ফিল্ড (প্লাস ঐচ্ছিক নোট) টাইমলাইনকে রহস্যময় আপডেটে ভরে না দেয়। সাধারণ কারণগুলোর মধ্যে re-upload replacement, scan cleanup, OCR correction, redaction, এবং approval edit আছে।
উদাহরণ: ফাইন্যান্স টিম একটি রসিদ ছবি আপলোড করে, পরে একটি পরিষ্কার স্ক্যান আপলোড করে, তারপর OCR ঠিক করে যাতে টোটাল পড়া যায়। প্রতিটি ধাপ একটি নতুন ভার্সন, কিন্তু ডকুমেন্ট ইনবক্সে একটিই আইটেম থাকে। যদি OCR ফিক্স ভুল হয়, current_version_id কেবল এক ক্লিকে আগের ভার্সনে ফিরিয়ে দিলে রোলব্যাক হবে।
নথি-কেন্দ্রিক ওয়ার্কফ্লোতে প্রিভিউই প্রায়শই ব্যবহারকারীরা সবচেয়ে বেশি ইন্টারঅ্যাক্ট করে এমন জিনিস। যদি প্রিভিউ ধীর বা ত্রুটিপূর্ণ হয়, পুরো অ্যাপই ভাঙা মনে হয়।
প্রিভিউ জেনারেশনকে আলাদা জব হিসাবে ট্রিট করুন, আপলোড স্ক্রিনের জন্য অপেক্ষা করার কিছু হিসেবে নয়। প্রথমে মূল ফাইল সেভ করুন, ব্যবহারকারীর কাছে নিয়ন্ত্রণ ফিরিয়ে দিন, তারপর ব্যাকগ্রাউন্ডে প্রিভিউ জেনারেট করুন। এতে UI প্রতিক্রিয়াশীল থাকে এবং রিট্রাই করা নিরাপদ হয়।
একাধিক প্রিভিউ সাইজ স্টোর করুন। একটাই সাইজ সব স্ক্রিনের জন্য মানায় না: তালিকার জন্য ছোট থাম্বনেইল, স্প্লিট ভিউয়ের জন্য মাঝারি ইমেজ, এবং বিস্তারিত পর্যালোচনার জন্য ফুল-পেজ ইমেজ (PDF-র পেজ-দর-পেজ) দরকার।
UI সবসময় কী দেখাবে তা জানতে প্রিভিউ স্টেট স্পষ্টভাবে ট্র্যাক করুন: pending, ready, failed, এবং needs_retry মত স্টেটগুলো ডাটা স্তরে পরিষ্কার রাখুন, UI-তে ব্যবহারকারীরা বোঝার মতো লেবেল দেখান।
রেন্ডারিং দ্রুত রাখতে, পুনরায় গণনা করে দেখানোর বদলে প্রিভিউ রেকর্ডের পাশাপাশি ডেরাইভড মানগুলি ক্যাশ করুন। সাধারণ ফিল্ডগুলো: page count, preview width/height, rotation (0/90/180/270), এবং ঐচ্ছিক “থাম্বনেইলের জন্য সেরা পেজ”।
ধীর ও অসংগঠিত ফাইলের জন্য ডিজাইন করুন। ২০০-পেজের স্ক্যানড PDF বা ভাঁজ করা রসিদ ছবি प्रोসেস হতে সময় নেবে। প্রগ্রেসিভ লোডিং ব্যবহার করুন: প্রথম রেডি পেজটা যতক্ষণ আছে দেখান, তারপর বাকি ভরাট করুন।
উদাহরণ: একজন ব্যবহারকারী ৩০টি রসিদ ছবি আপলোড করেন। তালিকা ভিউতে থাম্বনেইলগুলো “pending” দেখায়, পরে প্রতিটি কার্ড তার প্রিভিউ শেষ হলেই “ready” এ বদলে যায়। যদি কয়েকটি করাপ্টেড ইমেজের কারণে ব্যর্থ হয়, সেগুলো স্পষ্ট রিট্রাই অ্যাকশনের সাথে দৃশ্যমান থাকে—পুরো ব্যাচ ব্লক না করে।
মেটাডেটা ফাইলের গুচ্ছকে এমন কিছুতে পরিণত করে যা আপনি সার্চ, সোর্ড, রিভিউ ও অনুমোদন করতে পারেন। এটা মানুষকে সহজ প্রশ্নের দ্রুত উত্তর দিতে সাহায্য করে: এটা কী? এটা কার কাছ থেকে? এটা বৈধ কি না? পরবর্তী কী হওয়া উচিত?
মেটাডেটা পরিষ্কার রাখতে ব্যবহারিক উপায় হলো উৎস অনুসারে আলাদা করা:
এই বাকেটগুলো পরে বিতর্ক এড়ায়। যদি টোটাল ভুল হয়, আপনি দেখতে পারবেন তা OCR থেকেছে না কি মানুষের এডিট।
রসিদ ও ইনভয়েসের জন্য কিছু বাধ্যতামূলক ফিল্ড ধারাবাহিকভাবে ব্যবহার করলে ফল মেলে (একই নামকরণ, একই ফর্ম্যাট)। সাধারণ অ্যাঙ্কর ফিল্ডগুলো: vendor, date, total, currency, এবং document_number। প্রথমে এগুলো অপশনাল রাখুন—ব্যবহারকারীরা আংশিক স্ক্যান বা ঝাপসা ছবি আপলোড করে, এবং একটি ফিল্ড না থাকায় প্রক্রিয়া ব্লক করলে পুরো ফ্লো ধীর হয়ে যাবে।
অজানা মানগুলোকে প্রথম শ্রেণীর নাগরিক হিসেবে ট্রিট করুন। স্পষ্ট স্টেট ব্যবহার করুন যেমন null/unknown, এবং প্রয়োজনে কারণ দেখান (missing page, unreadable, not applicable)। এতে নথি এগিয়ে যেতে পারে এবং রিভিউয়ারের কাছে কি দৃষ্টি দেওয়া দরকার তা স্পষ্ট থাকে।
এক্সট্র্যাক্টেড ফিল্ডগুলোর provenance ও confidence সঞ্চয় করুন। উৎস হতে পারে user, OCR, import, বা API। confidence 0–1 স্কোর হতে পারে বা high/medium/low ছোট সেট। যদি OCR ‘$18.70’ পড়ে এবং কনফিডেন্স কম হয় কারণ শেষ ডিজিট জমে গেছে, UI সেটি হাইলাইট করে দ্রুত কনফার্ম চেয়ে দিতে পারে।
মাল্টি-পেজ ডকুমেন্টে আরেকটি সিদ্ধান্ত লাগে: কোনটা পুরো ডকুমেন্টের জন্য প্রযোজ্য এবং কোনটি পেজ-স্তরের। টোটাল ও vender সাধারণত ডকুমেন্ট-স্তরের; পেজ-স্তরের নোট, রেড্যাকশন, রোটেশন ও per-page classification পেজ লেভেলে থাকা উচিত।
স্ট্যাটাস এক প্রশ্নের উত্তর দেয়: “এই ডকুমেন্টটি প্রক্রিয়ার কোন ধাপে?” ছোট ও বোড়ার ধরনের রাখুন। যদি প্রতিবার কেউ নতুন স্ট্যাটাস চান আপনি যোগ করেন, তাহলে ফিল্টারগুলো ভরসে অবিশ্বাস্য হয়ে পড়বে।
কোন সিদ্ধান্তমূলক ব্যবসায়িক স্টেটগুলি বাস্তব কাজের সাথে মানায়:
“প্রসেসিং” ব্যবসায়িক স্ট্যাটাসে রাখা থেকে বিরত থাকুন। OCR চলা বা প্রিভিউ জেনারেট হওয়া সিস্টেম কী করছে তা বর্ণনা করে, নয় যে মানুষকে কি করা উচিত। সেগুলো আলাদা প্রসেসিং স্টেট হিসেবে স্টোর করুন।
অ্যাসাইনমেন্টকে স্ট্যাটাস থেকে আলাদা রাখুন (assignee_id, team_id, due_date)। একটি ডকুমেন্ট Approved হলেও ফলো-আপের জন্য অ্যাসাইন করা থাকতে পারে, বা Needs review কিন্তু এখনও কোন মালিক নেই।
স্ট্যাটাস ইতিহাস রেকর্ড করুন, শুধু বর্তমান মান নয়। একটি সাধারণ লগ (from_status, to_status, changed_at, changed_by, reason) পরে খুব কাজে আসবে যখন কেউ জিজ্ঞেস করবে, “কে এই রসিদ প্রত্যাখ্যান করেছেন এবং কেন?”
শেষে সিদ্ধান্ত করুন কোন স্ট্যাটাসে কোন অ্যাকশনগুলো অনুমোদিত। নিয়মগুলো সাদামাটা রাখুন: Imported থেকে Needs review এ যেতে পারে; Approved সাধারণত রিড-ওনলি যতক্ষণ না নতুন ভার্সন তৈরি করা হয়; Rejected পুনরায় খোলা যায় কিন্তু পূর্বের কারণ রাখতে হবে।
বেশিরভাগ সময় তালিকা স্ক্যান করা, একটি আইটেম খোলা, কয়েকটি ফিল্ড ঠিক করা এবং আবার এগোনোয় যায়। ভাল UI এই ধাপগুলোকে দ্রুত ও পূর্বানুমেয় করে।
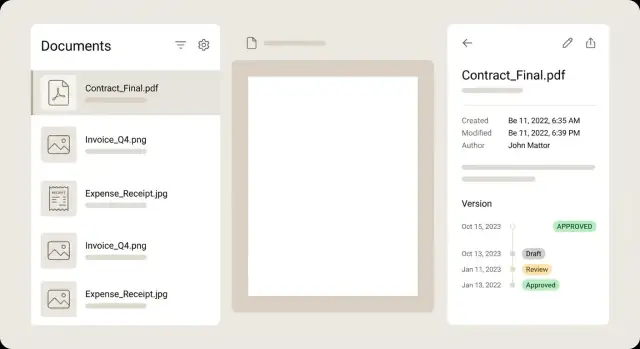
ডকুমেন্ট তালিকার জন্য প্রতিটি রোকে সারাংশের মতো ধরুন যাতে ব্যবহারকারী প্রতিটি ফাইল না খুলেই সিদ্ধান্ত নিতে পারে। একটি ভালো রো দেখায় একটি ছোট থাম্বনেইল, পরিষ্কার টাইটেল, কয়েকটি কী ফিল্ড (merchant, date, total), একটি স্ট্যাটাস ব্যাজ, এবং নরম সতর্কবাণী যখন কিছু মনোযোগের প্রয়োজন থাকে।
ডিটেইল ভিউ শান্ত ও স্ক্যানযোগ্য রাখুন। সাধারণ লেআউট: বাম দিকে প্রিভিউ এবং ডানদিকে মেটাডেটা, প্রতিটি ফিল্ডের পাশে এডিট কন্ট্রোল। ব্যবহারকারী জুম, রোটেট ও পেজ ফ্লিপ করতে পারবে ফর্মে তাদের জায়গা না হারিয়ে। যদি কোনো ফিল্ড OCR থেকে এক্সট্র্যাক্ট করা হয়, ছোট একটি কনফিডেন্স সংকেত দেখান এবং সম্ভব হলে ফিল্ডে ফোকাস করলে প্রিভিউতে সেই সোর্স এলিয়ারিয়া হাইলাইট করুন।
ভার্সনগুলো টাইমলাইন হিসেবে দেখালে ভালো কাজ করে, ড্রপডাউন না। দেখান কে কী ও কখন পরিবর্তন করেছে, এবং অতীতের যেকোনো ভার্সন রিড-ওনলি মোডে খুলতে দিন। যদি তুলনা দেন, মেটাডেটার পার্থক্যের উপর ফোকাস করুন (পরিমাণ বদলেছে, বিক্রেতা সঠিক হয়েছে), পিক্সেল-টু-পিক্সেল PDF তুলনা বোঝাপড়াকে জটিল করে।
রিভিউ মোড দ্রুততার জন্য অপ্টিমাইজ করুন। কীবোর্ড-ফার্স্ট ট্রায়াজ ফ্লো প্রায়ই যথেষ্ট: দ্রুত approve/reject অ্যাকশন, সাধারণ ক্ষেত্র দ্রুত ঠিক করার সুযোগ, এবং প্রত্যাখ্যানের জন্য একটি ছোট মন্তব্য বাক্স।
এম্পটি স্টেটগুলো গুরুত্বপূর্ণ কারণ নথিগুলো প্রায়ই মধ্য-প্রসেসিং এ থাকে। একটি ফাঁকা বক্সের বদলে বলুন কী ঘটছে: “প্রিভিউ তৈরী হচ্ছে”, “OCR চলেছে”, অথবা “এই ফাইল টাইপের জন্য প্রিভিউ নেই”।
একটি সরল ওয়্যারফ্লো অনুভবে হয় “আপলোড, চেক, অনুমোদন।” আন্ডার দ্য হুড, এটি ভাল চলে যখন আপনি ফাইল নিজেই (ভার্সন ও প্রিভিউ) কে ব্যবসায়িক অর্থ (মেটাডেটা ও স্ট্যাটাস) থেকে আলাদা রাখেন।
ব্যবহারকারী একটি PDF, ফটো বা রসিদ স্ক্যান আপলোড করে এবং তা সঙ্গে সঙ্গেই ইনবক্স তালিকায় দেখা যায়। প্রসেসিং শেষ হওয়ার জন্য অপেক্ষা করবেন না। একটি ফাইলনেম, আপলোড সময় এবং একটি স্পষ্ট ব্যাজ যেমন “Processing” দেখান। যদি উৎস জানা থাকে (ইমেল ইম্পোর্ট, মোবাইল ক্যামেরা, ড্র্যাগ-অ্যান্ড-ড্রপ), সেটিও দেখান।
আপলোডে Document রেকর্ড তৈরি করুন (দীর্ঘজীবী আইটেম) এবং একটি Version রেকর্ড (এই নির্দিষ্ট ফাইল)। current_version_id নতুন ভার্সনে সেট করুন। preview_state = pending এবং extraction_state = pending সেট করে UI-কে যা রেডি তা সৎভাবে দেখান।
ডিটেইল ভিউ অবিলম্বে খোলা উচিত, কিন্তু একটি প্লেসহোল্ডার ভিউয়ার এবং একটি পরিষ্কার “Preparing preview” মেসেজ দেখান যাতে ভাঙা ফ্রেম না দেখায়।
একটি ব্যাকগ্রাউন্ড জব থাম্বনেইল এবং ভিউয়েবল প্রিভিউ তৈরি করে (PDF-র জন্য পেজ ইমেজ, ফটোর জন্য রিসাইজ ইমেজ)। আরেকটি জব মেটাডেটা এক্সট্র্যাক্ট করে (vendor, date, total, currency, document type)। যখন প্রতিটি জব শেষ হয়, শুধু তার স্টেট ও টাইমস্ট্যাম্প আপডেট করুন যাতে ব্যর্থতা পুনরায় চেষ্টা করা যায় সবকিছু ছুড়ে না দিয়ে।
UI কম্প্যাক্ট রাখুন: প্রিভিউ স্টেট, ডাটা স্টেট দেখান এবং কম কনফিডেন্স ফিল্ডগুলো হাইলাইট করুন।
প্রিভিউ রেডি হলে, রিভিউয়াররা ফিল্ড ঠিক করে, নোট যোগ করে, এবং ডকুমেন্টকে ব্যবসায়িক স্টেটে নিয়ে যায় যেমন Imported -> Needs review -> Approved (বা Rejected)। কে কী ও কখন পরিবর্তন করেছে লগ করুন।
যদি রিভিউয়ার একটি সংশোধিত ফাইল আপলোড করে, সেটি নতুন ভার্সন হয় এবং ডকুমেন্ট স্বয়ংক্রিয়ভাবে আবার Needs review এ ফিরে যায়।
current_version_id ও অনুমোদিত মেটাডেটা পড়েএক্সপোর্ট, একাউন্টিং সিঙ্ক বা অভ্যন্তরীণ রিপোর্ট current_version_id এবং অনুমোদিত মেটাডেটা স্ন্যাপশট থেকে পড়ুক, “লেটেস্ট এক্সট্র্যাকশন” না। এভাবে আংশিক প্রসেসিং চলাকালীন রি-আপলোড সংখ্যাগরিষ্ঠভাবে সংখ্যাগরিষ্ঠ মান পরিবর্তন করবে না।
নথি-কেন্দ্রিক ওয়ার্কফ্লো সাধারণত বিরক্তিকর কারণে ব্যর্থ হয়: শুরুতেই নেওয়া শর্টকাটগুলো প্রতিদিনের সমস্যা হয়ে ওঠে যখন মানুষ ডুপ্লিকেট আপলোড করে, ভুল ঠিক করে, বা জিজ্ঞেস করে “কে কখন এটা বদলেছে?”
ফাইল নামকে ডকুমেন্টের পরিচয় ধরে নেওয়া একটি ক্লাসিক ভুল। নাম বদলে যায়, ব্যবহারকারী পুনরায় আপলোড করে, এবং ক্যামেরা ডুপ্লিকেট তৈরি করে যেমন IMG_0001। প্রতিটি ডকুমেন্টকে একটি স্থির ID দিন, ফাইল নামকে কেবল লেবেল হিসেবে বিবেচনা করুন।
অরিজিনাল ফাইল ওভাররাইট করলে সমস্যা সৃষ্টি হয়। প্রথমে সহজ মনে হলেও আপনি অডিট ট্রেইল হারাবেন এবং পরে উত্তর দেওয়া যাবে না (কি অনুমোদিত ছিল, কী এডিট করা হয়েছিল, কী পাঠানো হয়েছিল)। বাইনারি ফাইল অপরিবর্তনীয় রাখুন এবং নতুন ভার্সন রেকর্ড যোগ করুন।
স্ট্যাটাস বিভ্রান্তি সূক্ষ্ম বাগ তৈরি করে। “OCR চলছে” মানে “পর্যালোচনা দরকার” না। প্রসেসিং স্টেট সিস্টেম কি করছে তা বলে; ব্যবসায়িক স্ট্যাটাস বলে মানুষকে কি করা উচিত। যখন এগুলো মিশে যায়, ডকুমেন্ট ভুল বাকেটে আটকে যায়।
UI সিদ্ধান্তও friction তৈরি করতে পারে। যদি আপনি প্রিভিউ জেনারেট হওয়া পর্যন্ত স্ক্রিন ব্লক করেন, তবে আপলোড সফল হলেও মানুষ অ্যাপকে ধীর বলে অনুভব করবে। ডকুমেন্ট অবিলম্বে দেখান একটি পরিষ্কার প্লেসহোল্ডার সহ, পরে যখন থাম্বনেইল রেডি হবে তা পরিবর্তন করুন।
শেষে, provenance ছাড়া মান সংরক্ষণ করলে মেটাডেটা অবিশ্বাস্য হয়ে যায়। যদি টোটাল OCR থেকে এসেছে, তা উল্লেখ করুন। টাইমস্ট্যাম্প রাখুন।
একটি দ্রুত গানচেক তালিকা:
উদাহরণ: রসিদের অ্যাপে ব্যবহারকারী পরিষ্কার ছবিটি পুনরায় আপলোড করলে যদি আপনি ভার্সনিং করেন, পুরোনো ইমেজ রাখা হবে, OCR রি-প্রসেসিং চিহ্নিত হবে, এবং ডকুমেন্ট Needs review থাকবে যতক্ষণ না মানুষ টোটাল নিশ্চিত করে।
নথি-কেন্দ্রিক ওয়ার্কফ্লো “ডান” মনে হওয়া শুরু হয় যখন মানুষ যা দেখে তাতে বিশ্বাস রাখতে পারে এবং ভুল হলে পুনরুদ্ধার করা যায়। লঞ্চ করার আগে জঞ্জাল-মিশ্রিত বাস্তব নথি নিয়ে পরীক্ষা করুন (ঝাপসা রসিদ, রোটেটেড PDF, পুনরাবৃত্ত আপলোড)।
পাঁচটি পরীক্ষা যা বেশিরভাগ চমক ধরবে:
একটি বাস্তবতা পরীক্ষা: কাউকে তিনটি সমান রসিদ পর্যালোচনা করতে বলুন এবং ইচ্ছাকৃতভাবে একটিতে ভুল পরিবর্তন করান। যদি তারা বর্তমান ভার্সন চিনতে পারে, স্ট্যাটাস বুঝতে পারে, এবং এক মিনিটের মধ্যে ভুল ঠিক করতে পারে, আপনি বেশ কাছে পৌঁছেছেন।
মাসিক রসিদ রিইম্বার্সমেন্ট স্পষ্ট উদাহরণ। একজন কর্মচারী রসিদ আপলোড করে, পরে দুইজন রিভিউ করে: আগে ম্যানেজার, তারপর ফাইন্যান্স। রসিদটাই প্রোডাক্ট, তাই আপনার অ্যাপ ভার্সনিং, প্রিভিউ, মেটাডেটা এবং স্পষ্ট স্ট্যাটাস-এ বেঁচে বা মরবে।
জেমি একটি ট্যাক্সি রসিদের ছবি আপলোড করে। আপনার সিস্টেম Document #1842 তৈরি করে Version v1 (অরিজিনাল ফাইল), একটি থাম্বনেইল ও প্রিভিউ, এবং মেটাডাটা যেমন merchant, date, currency, total ও OCR কনফিডেন্স স্কোর। ডকুমেন্ট Imported এ শুরু করে, তারপর প্রিভিউ ও এক্সট্র্যাকশন রেডি হলে Needs review এ যায়।
পরে জেমি ভুলক্রমে একই রসিদ আবার আপলোড করে। একটি ডুপ্লিকেট চেক (ফাইল হ্যাশ প্লাস সমান merchant/date/total) একটি সরল অপশন দেখাতে পারে: “এটি #1842-এর ডুপ্লিকেট মনে হচ্ছে। তারপরও সংযুক্ত করবেন নাকি বাদ দেবেন।” যদি সংযুক্ত করা হয়, এটি একই Document-এ আরেকটি File হিসেবে সংরক্ষণ করুন যাতে একটি রিভিউ থ্রেড ও এক স্ট্যাটাস থাকে।
রিভিউ চলাকালীন, ম্যানেজার প্রিভিউ, কী ফিল্ড ও সতর্কবার্তা দেখে। OCR $18.00 অনুমান করেছে, কিন্তু ছবিতে স্পষ্টত $13.00। জেমি টোটাল ঠিক করে। ইতিহাস মুছবেন না—Version v2 তৈরি করুন, v1 অপরিবর্তিত রাখুন, এবং লগ করুন “Total corrected by Jamie.”
যদি আপনি দ্রুত এমন ফ্লো বানাতে চান, Koder.ai (koder.ai) সাহায্য করতে পারে প্রথম অ্যাপ জেনারেট করতে একটি চ্যাট-বেইজড প্ল্যান থেকে, কিন্তু একই নিয়ম প্রযোজ্য: প্রথমে অবজেক্ট ও স্টেট সংজ্ঞায়িত করুন, তারপর স্ক্রিনগুলো অনুসরণ করুক।
প্রায়োগিক পরবর্তী ধাপ:
একটি নথি-কেন্দ্রিক অ্যাপ মানে হলো নথিটাই প্রধান জিনিস যা ব্যবহারকারীরা তৈরি, পর্যালোচনা ও নির্ভর করে — নথিটিই মূল পণ্য়, ফাইলটি কেবল সংযুক্তি নয়। মানুষ নথিটি খুলে দেখবে, কী বদলেছে বুঝবে এবং সিদ্ধান্ত নেবে পরবর্তী পদক্ষেপ কী হবে।
প্রথমে একটি ইনবক্স/তালিকা, দ্রুত প্রিভিউসহ একটি ডকুমেন্ট ডিটেইল ভিউ, সহজ রিভিউ অ্যাকশন এলাকা (approve/reject/request changes), এবং এক্সপোর্ট/শেয়ার করার উপায় তৈরি করুন। এই চারটি স্ক্রিন সাধারণ ‘অনুসন্ধান—খোলা—সিদ্ধান্ত—হ্যান্ডঅফ’ চক্র ঢেকে দেয়।
স্টেবল নথি (Document) রেকর্ড রাখুন যা পরিবর্তন করে না, এবং বাস্তব ফাইল বাইট আলাদা File অবজেক্ট হিসেবে সংরক্ষণ করুন। এরপর Version যোগ করুন যা একটি নথিকে নির্দিষ্ট ফাইল (এবং তার ডেরিভেটিভ) এ যুক্ত করে। এই পৃথকীকরণ মন্তব্য, অ্যাসাইনমেন্ট, এবং ইতিহাস অক্ষুণ্ণ রাখে যখন ফাইল প্রতিস্থাপিত হয়।
প্রতিটি অর্থবহ পরিবর্তনকে একটি নতুন ভার্সন হিসেবে তৈরি করুন; ইন-প্লেস এডিট করার বদলে নতুন version সারি রাখুন। ডকুমেন্টে current_version_id রেখে দ্রুত “তাজা” ভার্সন দেখান, এবং ইতিহাস দেখানোর জন্য আলাদা ভার্সন লোড করুন। এতে কী অনুমোদিত ছিল এবং কেন স্পষ্ট থাকে।
অরিজিনাল ফাইল সেভ করার পর প্রিভিউ অ্যাসিঙ্ক্রোনাসভাবে জেনারেট করুন, যাতে আপলোড মুহূর্তে UI সাড়া দেয়। প্রিভিউ স্টেট ট্র্যাক করুন (উদাহরণ: pending, ready, failed) যাতে UI সৎভাবে দেখাতে পারে কী রেডি। তালিকা, স্প্লিট ভিউ এবং ফুল-পেজ রেন্ডারিংয়ের জন্য বিভিন্ন আকারের প্রিভিউ স্টোর করুন।
মেটাডেটা তিনটি ভাগে রাখুন: সিস্টেম (ফাইলনেম, সাইজ, MIME টাইপ), এক্সট্র্যাক্টেড (OCR টেক্সট, ডিটেক্টেড ফিল্ড, কনফিডেন্স) এবং ব্যবহারকারীর প্রবেশকৃত (কোরেকশন, ট্যাগ, নোট)। উৎস (provenance) এবং কনফিডেন্স রাখলে আপনি জানবেন কোনো মান OCR থেকে এসেছে নাকি মানুষের পরিবর্তন।
ছোট একটি সেট ব্যবসায়িক স্ট্যাটাস ব্যবহার করুন যা বলে ‘ব্যবহারকারী পরবর্তী কী করা উচিত’। সাধারণ স্ট্যাটাস: আমদানি করা (Imported), পর্যালোচনার প্রয়োজন (Needs review), অনুমোদিত (Approved), প্রত্যাখ্যাত (Rejected), এবং সংরক্ষিত (Archived)। প্রোসেসিং (OCR বা প্রিভিউ জেনারেট হওয়া) আলাদা ট্র্যাক করুন যাতে মানুষিক কাজ ও মেশিন কাজ মিশে না যায়।
আপলোডের সময় অপরিবর্তনীয় ফাইল চেকসাম (checksum) রাখুন এবং তা দিয়ে ডুপ্লিকেট চেক করুন; পাশাপাশি মেরচেন্ট/তারিখ/টোটালের মত কী ফিল্ড দিয়ে ফাজি মিলও পরীক্ষা করুন। সন্দেহ হলে ব্যবহারকারীকে স্পষ্ট বিকল্প দিন: একই ডকুমেন্টে সংযুক্ত করবেন নাকি বাতিল করবেন।
স্ট্যাটাস হিস্ট্রি লগ রাখুন (from_status, to_status, changed_at, changed_by, reason) যাতে পরে জানা যায় কে কেন ডিসিশন নিয়েছে। রোলব্যাক হলে পুরোনো ভার্সনে current_version_id পয়েন্টার ফিরিয়ে দিন—কাছেই কিছু মুছবেন না।
প্রথমে অবজেক্ট এবং স্টেটগুলি সংজ্ঞায়িত করুন, তারপর UI তৈরি করুন। Koder.ai ব্যবহার করলে একটি চ্যাট প্ল্যান থেকে অ্যাপ জেনারেট করতে পারেন, কিন্তু জেনারেশন শুরুর আগে Document/Version/File, প্রিভিউ ও এক্সট্র্যাকশন স্টেট এবং স্ট্যাটাস রুলগুলি স্পষ্টভাবে বলে দিন যাতে তৈরি স্ক্রিনগুলো বাস্তব ওয়ার্কফ্লো-কে ঠিকভাবে ম্যাপ করে।