2025年12月12日·1 分钟
用户真正信任的维护窗口消息模板
在计划性停机、部分中断或性能下降时,让用户安心的维护窗口消息模板,减少恐慌与支持工单。
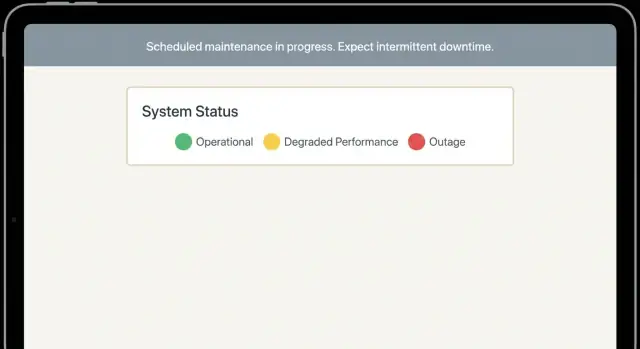
在计划性停机、部分中断或性能下降时,让用户安心的维护窗口消息模板,减少恐慌与支持工单。
大多数维护说明之所以失败,有一个简单原因:它们制造了不确定性。写着“我们正在进行维护”的横幅却不提供细节,会迫使用户去猜测哪里出问题了、要持续多久、他们的工作是否安全。猜测会变成恐惧,恐惧又会变成支持工单。
模糊的表述也会让人觉得可疑。如果用户看到错误,但你的消息听起来冷静而笼统,他们会认为你在隐瞒真实问题。用户体验到的情况和你所说之间的差距会破坏信任。
人们通常立即需要三件事:明确的影响、明确的时间、和明确的下一步。
影响指的是点名受影响的内容(登录、导出、支付),而不是只说“服务中断”。时间指的是具体的时间窗口和下次更新时间,而不是“马上”。下一步则是告诉他们在等待期间该做什么,比如“20 分钟后再试”或“改用移动应用”。
过度承诺会迅速使情况更糟。“预计不会有影响”只有在你完全确定的情况下才可用。当哪怕只有一个用户受影响时,这句话就会成为你不关注问题的证据。诚实的更新更有效:说明你知道什么、还不知道什么,以及你会在什么时候再次确认。
目标不是“粉饰”事实,而是减少不确定性。当人们理解正在发生什么、这对他们意味着什么、以及现在应该做什么时,他们就会停止不停刷新、停止假设最坏状况,也会少开工单以求掌控感。
当你用直白的词语标明情况时,用户会更放松。如果你把所有问题都称为“维护”或“故障”,人们会默认最坏的情况,开始重复尝试、刷新并发起工单。
用合适的标签开始:
“性能下降”绝不应模糊不清。说清用户会注意到什么。例如:比起“体验到性能下降”,写“导出可能比平常慢 10 到 20 分钟”更清楚。
即便列表很短,也要具体说明受影响的内容。提到用户最关心的领域:登录、支付与账单、同步、通知、仪表盘、导出、API 访问和文件上传。
避免使用吓人的词,但不要隐瞒真相。把“严重故障”替换为“部分用户无法登录”,把“系统不稳定”替换为“保存时可能会看到超时”。平静的语气来自准确,而不是乐观。
如果不确定,选择与用户感受相对应的标签,而不是内部原因。“数据库维护”对大多数人意义不大,“账单页面在最多 15 分钟内可能无法访问”会告诉他们该期待什么以及该如何应对。
用户更信任在他们被阻挡的那一刻能看到的信息。好的消息模板更关乎使用正确的展示面,而不是巧妙的措辞。
对大多数计划内工作使用应用内横幅。它在用户继续当前工作的同时保持可见,不会劫持整个屏幕。
仅在用户继续操作可能导致错误(例如支付操作、数据编辑、注册)时才使用模态窗口。如果使用模态,允许用户关闭,并在之后保留持久的横幅。
吐司通知适用于短期、低风险的更新(例如“导出在接下来的 10 分钟可能较慢”)。它们容易被忽视,所以不要用在真正的停机场景。
一条简单规则:
如果用户可能无法登录,就在登录页显示相同的信息。恐慌通常从登录处开始,因为用户会认为账户坏了。像“登录可能在 02:00–02:30 UTC 失败”这样的简单提示能迅速减少工单。
将状态页用于持续更新和历史记录(发生了什么、仍然受影响的内容、已修复的项)。将应用内通知用于告诉用户现在该做什么(等待、稍后重试、避免导出等)。不要只把关键信息放在状态页上,因为很多用户不会去查看。
当影响较大且用户需要提前安排时,可使用邮件和推送通知。否则会显得噪杂。如果发送,确保与应用内文案一致。
最后,让支持团队使用相同措辞。你的自动回复应与横幅和状态更新保持一致,避免用户收到混淆的信息。
当维护通知具体、诚实并且有用时,人们会信任它。这并不意味着啰嗦,而是要在用户紧张的头 10 秒内回答问题,给出明确的时间和计划。
可靠的通知包含五个基本要素:
时间是消息常丧失信任的地方。使用用户能理解的时间窗口,比如“1 月 16 日,01:00 至 02:30 UTC”。如果受众遍布全球,考虑再加一个多数用户共享的参考时区(例如“新加坡时间 08:00 至 09:30”)。避免不必要的精确,例如“02:17 恢复”。像“30 到 60 分钟”这样的区间显得更诚恳,也能减少用户愤怒式刷新。
如果你还不知道某件事,就说明你接下来会检查什么。例如:
“我们正在调查数据库负载升高,并审查最近的部署和慢查询。下次更新在 14:30 UTC。”
这一句会把沉默变成有计划的沟通。
即便很快就会更新,也务必包含下次更新时间。“20 分钟后更新”能安抚用户,因为这是一个你可以兑现的承诺。
举个增强信任的例子:
“文件导出可能比平时慢 10 到 30 分钟。在此期间,你可以在应用内查看报表。我们将在 16:10 UTC 发布下一次更新。”
好的维护通知之所以平静,是因为它们具体且一致。把它们当作检查清单,而不是一次性公告。
用清晰的占位符撰写第一稿。 从:受影响内容、开始时间、可能持续多久、谁会受影响开始。为稍后确认的细节留出中括号(确切结束时间、受影响的地区、功能名)。这样可以提前发布而不去猜测。
选择与现实相符的严重性标签。 在横幅、状态页和邮件中使用同一个标签。例如:Maintenance(计划内)、Partial outage(部分用户或功能受影响)、Degraded performance(慢或延迟)。如果使用颜色,请保持一致(绿色=正常,黄色=性能下降,红色=中断),这样用户能快速浏览。
为标签添加一句用通俗语言解释其含义。“Degraded”应始终具体说明,例如“导出可能需要 5–15 分钟”。
在可能的情况下提供变通方案。 即便是一个小的替代方案也能减少工单。例如:“如果现在需要该报表,请使用仪表盘的 CSV 下载,而不是计划导出。”如果没有变通方案,就明确说明一次。
在发布前规划好后续更新。 计划两次提醒:一次在窗口开始前不久,另一次在“现在开始”时发送。如果时间发生变化,先更新通知,再发送提醒。
以最终更新收尾。 说明发生了什么、何时恢复,以及如果仍有问题用户该怎么做(刷新、重试或联系支持并提供具体信息,例如时间戳或作业 ID)。
将这些模板作为起点,根据用户在你产品中的实际使用情景调整。保持语气冷静、平实。给出一项清晰的用户操作建议。
主题/标题: 计划维护:周 [星期几],[日期] [开始时间] [时区]
正文: 我们已安排在 [星期几,日期] 的 [开始时间 至 结束时间 时区] 进行维护。
在此窗口内,[哪些功能将不可用]。[哪些功能仍可用] 将保持可用。
若需准备:请在 [时间] 之前完成 [建议操作,例如:完成导出、保存草稿]。我们将在维护期间在此发布更新。
标题: 维护正在进行
正文: 维护已开始,预计将持续到 [结束时间 时区]。
当前,[哪些功能不可用]。如果你尝试 [常见操作],可能会看到 [预期错误/表现]。
下次更新在 [时间](或如有变更将更早更新)。
标题: 维护比预计时间更久
正文: 维护比预期耗时更长。新的预计结束时间为 [新结束时间 时区]。
对你的影响:[一句话说明影响]。现在你可以:[安全变通或“请在 X 后重试”]。
对于造成的中断我们表示抱歉——我们将在 [时间] 再次更新。
标题: 维护已完成
正文: 维护已于 [时间 时区] 完成。
你现在可以 [验证的前 2–3 项关键操作,例如:登录、执行导出、提交付款]。如果仍有异常,请尝试 [简单步骤,如刷新/重新登录],然后联系支持并提供 [需包含的信息,例如时间、账号、截图]。
标题: 维护后监控中
正文: 系统已恢复在线,我们将在接下来的 [X 小时] 密切监控。
你可能会注意到 [小问题,例如:加载较慢、邮件延迟],这是队列赶工造成的。如果遇到错误,请在 [时间] 后重试。
下次更新在 [时间](如有问题会更早更新)。
当应用并非完全宕机时,模糊的横幅会引起最多的恐慌。要具体说明受影响的功能(或地区、步骤)、哪些仍然可用,以及用户现在应做什么。
在大部分产品可用但某一部分不可用时使用。
模板
标题: 部分中断: [功能/服务] 在 [地区/账户类型] 不可用
正文: 我们检测到 [功能] 在 [受影响对象] 中不可用。应用的其它部分,包括 [仍可用的内容],仍在正常运行。我们的团队正在修复中。
影响: 当你尝试 [操作] 时,可能会看到 [错误信息/现象]。
变通方案: 在修复前,请 [安全的替代操作]。
下次更新: 在 [时间 + 时区](或更早,如果解决)。
当请求能成功返回,但感觉像是坏了时使用。
模板
标题: 性能下降:部分 [区域] 比平常慢
正文: 某些操作比平时更慢,尤其是 [具体操作]。你可能会看到超时或重试,但数据不应丢失。
如何处理: 如果遇到错误,请等待 [X 分钟] 再重试。避免重复同一操作(可能造成重复项)。
下次更新: 在 [时间 + 时区]。
当最难受的是不确定性时使用。
模板
标题: 间歇性问题: [功能] 有时成功、有时失败
正文: 我们正在调查一个问题,导致 [功能] 在部分尝试中成功,而在另一些尝试中失败。如果失败,请在 [X 分钟] 后安全重试一次。
如何协助: 若联系支持,请提供 [请求 ID / 时间范围 / 受影响地区]。
当用户无法登录时使用,保持冷静和直接。
模板
标题: 登录问题:部分用户可能无法登录
正文: 我们检测到 [受影响对象] 的登录失败率上升。如果被阻塞,请不要反复重置密码,除非你看到明确的密码错误。
可尝试: 先刷新一次,然后等待 [X 分钟] 再试。如果使用 SSO,请说明问题是否仅出现在 SSO 或所有登录方式。
当用户认为数据丢失时使用。
模板
标题: 数据延迟: [报表/同步/分析] 可能滞后 [X 分钟/小时]
正文: 新活动可能需要更久才能出现在 [区域]。你的数据仍在被采集,但处理出现延迟。
意味着什么: 在此期间创建的导出/报表可能不完整。如有可能,请等待至 [时间] 再运行关键报表。
下次更新: 在 [时间 + 时区]。
大多数维护期间的支持激增并非由维护本身引起,而是由会让人猜测的文案造成。如果用户必须猜测,他们就会开工单。
会快速引发恐慌的模式包括:
举个小例子:你的导出工具很慢,但应用其它部分正常。如果横幅写着“服务中断”,不在导出的用户也会停止工作并联系支持。如果横幅写着“导出可能需要 10–20 分钟;仪表盘和编辑功能正常。下次更新在 14:30 UTC”,大多数人会选择等待。
如果你要做消息模板,目标是用通俗语言快速回答三件事:受影响什么、现在我该做什么、何时会有下一次更新。
在发布前,把消息当作焦虑的用户来读。目标很简单:减少不确定性。
确保横幅、邮件、工单宏和任何状态消息的措辞一致。如果一个地方写“性能下降”,另一个写“宕机”,用户会认为你在隐瞒。
保持语气冷静、事实性。避免夸张、玩笑或“不用担心”之类的轻佻说法。像“我们正在调查导出变慢”这样简洁的表述通常比试图显得轻松的语调更有效。
做清晰度测试:新用户能否在一句话内复述问题,而不加入自己的猜测?如果不能,就重写。
结束后要明确收尾:确认问题已解决,给出恢复时间,并告诉用户下一步该做什么(例如“重试导出”,或“如果仍有错误,请刷新并重试一次”)。
一个常见的“看起来一切都坏了”的时刻是单项功能失效,而其它功能看起来正常。想象一个财务工具:账单页能打开、发票显示正常、支付仍能完成。但 CSV 导出对部分用户开始超时。人们不停刷新、再次尝试,然后发起工单,因为他们以为数据丢失。
第一条消息应说明什么能用、什么不能用、谁受影响以及现在该怎么办。例如:
“导出发票为 CSV 当前对部分账号出现超时。账单页和付款功能仍正常。如果你急需数据,请在页面上使用筛选并复制结果,或尝试导出较小的日期范围。我们正在调查,15 分钟内在此更新。”
在接下来的一小时里,更新应从“我们看到问题”演进到“这是我们做了什么”:
最终消息要闭环,说明修复、范围,并给出清晰的支持路径:
“已解决:我们增加了导出 worker 容量并调整了超时设置。10:05–11:05 UTC 期间部分 CSV 导出失败,但账单与支付保持可用。如果你仍无法导出,请在你的工单中回复导出时间和发票范围。”
像这样沟通的团队通常会看到更少的工单,因为用户能迅速学会三件事:他们的数据是安全的、现在该尝试什么、以及何时会有下一次更新。
把维护消息当作一个小型产品功能,而不是一次性道歉。目标是一致性:用户应能识别模式、知道该做什么,并信任你会按计划更新。
把最佳文案转成可复用的模块并保存在一个地方,这样团队任何人都能在不重写的情况下发布通知。把基本变量标准化,如开始时间、预计结束时间、受影响功能、地区和受影响用户范围(全部用户或子集)。
写明责任与简单的审批流程。一个人起草、另一个人审批、还有一个人发布,即便在小团队中这三项角色可能由同一人承担。事先设定更新节奏(例如事故期间每 30 分钟一次),这样支持团队就不会猜测何时会有下一条消息。
对“快照”和“回滚”类语言要谨慎。仅承诺在压力下能可靠完成的操作。如果回滚可能但不确定,就坦率说明,并把重点放在用户能依赖的保证上。
如果你想把这个过程在产品内实现,先一次性搭建好交付点并重复使用会很有帮助:一个应用内横幅组件、一个轻量的状态页和一个维护结束的“全部清除”流程。如果你的团队用 Koder.ai (koder.ai) 构建产品,你可以通过聊天驱动的构建流程创建这些 UI 组件和更新流程,然后只需调整文案和变量而无需重建整个应用。
最后,在低风险维护窗口做一次演练。使用真实模板,发布到真实展示面,计时更新,并事后回顾:
一旦形成这个闭环,模板就不再是文档,而会成为一种习惯。
Start with what’s affected, how long it will last, and what the user should do right now. A plain line like “Exports may take 10–20 minutes longer; dashboards work normally; next update at 14:30 UTC” prevents guessing and cuts tickets.
Use Maintenance for planned work with a defined window, Partial outage when a specific feature/region is down, and Degraded performance when things work but are slow or error-prone. Pick the label that matches what users feel, not the internal cause.
Write what the user will notice in one sentence, then quantify it if you can. For example: “Exports may take 10–30 minutes and may time out on large date ranges,” instead of “We’re seeing degraded performance.”
Use an in-app banner for most situations so people can keep working. Use a modal only when continuing could cause errors or lost work (like billing actions or data edits), and keep a persistent banner afterward so the message doesn’t disappear.
Put the same message on the login screen whenever sign-in might fail, because that’s where panic starts. If you only post updates inside the app, locked-out users will assume their account is broken and flood support.
Avoid false certainty like “No impact expected” unless you’re truly sure. Say what you know, what you don’t know yet, and when you’ll update next; that honesty reads as competence, not weakness.
Always include a specific next update time, even if nothing changes. “Next update in 20 minutes” sets a promise users can rely on and reduces the refresh-and-ticket cycle.
Give one safe action that reduces risk and duplicates. For example: “Retry once after 2 minutes,” “Avoid repeating the same export,” or “Use a smaller date range,” and if there’s no workaround, say so clearly once.
State what’s affected, what still works, and what to do if they’re blocked. Tell users not to do high-risk actions repeatedly (like password resets or repeated submissions) unless the message specifically tells them to.
Close with an explicit “resolved” note that includes the time, what was restored, and what to try if something still looks wrong (refresh, re-login, retry once). If users may still see edge cases, say you’re monitoring and when you’ll post the final confirmation.