2026年1月13日·1 分钟
让应用内搜索有即时感:防抖、缓存与相关性
通过防抖、小型缓存、简单的相关性规则和有用的无结果状态,即使没有搜索引擎,也能让应用内搜索感觉像即时响应。
通过防抖、小型缓存、简单的相关性规则和有用的无结果状态,即使没有搜索引擎,也能让应用内搜索感觉像即时响应。
人们说搜索应该感觉是即时的,但他们很少指零毫秒。他们的意思是能在足够快的时间内得到明确的反馈,让他们不会怀疑应用是否听到他们的输入。如果在大约一秒内有可见变化(结果更新、加载提示或稳定的“正在搜索”状态),大多数用户会保持信心并继续输入。
当界面让你在沉默中等待,或以刺耳的方式反馈时,搜索就会感觉慢。即便后端很快,如果输入卡顿、列表跳动,或结果在输入时不断重置,也无法挽回体验。
有几类模式反复出现:
这即便在小数据集中也很重要。即使只有几百条记录,人们仍把搜索当作快捷方式而不是最后手段。如果感觉不可靠,他们会改用滚动、过滤,或者直接放弃。小数据集通常也会出现在移动端和低算力设备上,在每次按键做不必要的工作会更明显。
在添加专用搜索引擎之前,你可以修复很多问题。大多数速度和有用性来自 UX 和请求控制,而不是花哨的索引。
先让界面可预测:保持输入响应,避免过早清空结果,仅在必要时显示平静的加载状态。然后用防抖和取消减少不必要的工作,避免对每个字符都发起搜索。添加小缓存,让重复查询看起来立刻有响应(比如用户退格时)。最后,用简单的排序规则(精确匹配优于部分匹配,前缀优于包含)让顶端结果更合理。
如果搜索试图包罗万象,速度优化也无济于事。版本 1 最好在范围、质量门槛和限制上明确。
决定搜索的用途。是用于快速选取已知项,还是用于探索大量内容?
对大多数应用而言,搜索几个预期字段就足够:标题、名称和关键标识符。在 CRM 中,这可能是联系人姓名、公司和邮箱。有关笔记的全文搜索可以等到有证据显示用户需要时再做。
你不需要完美排序才能上线,但你需要看起来公平的结果。
使用能让你解释的规则以便有人问时能说明为何某项会出现:
这个基线能消除惊讶感并减少随机性的印象。
边界保护性能并防止边缘案例破坏体验。
早早决定最大结果数(通常 20–50 条)、最大查询长度(比如 50–100 字符)和最小查询长度(通常为 2)。如果你将结果上限设为 25,就在界面上说明(例如 “前 25 条结果”),别暗示你搜索了全部内容。
如果应用可能在地铁、电梯或弱 Wi‑Fi 下使用,要定义哪些功能还能工作。实际的版本 1 选择是:最近项和小范围缓存可以离线搜索,而其余内容需要连接。
网络差时,避免清空屏幕。保留最后一次的良好结果并清楚地提示结果可能已过期。这样比空白状态看起来像失败要平和得多。
最快把应用内搜索做得感觉慢的方法是对每次按键都发起网络请求。人们是成段打字的,界面就会在部分结果间闪烁。防抖通过在最后一次按键后等一小会儿再搜索来避免这种情况。
一个合适的初始延迟是 150–300ms。更短可能仍会产生过多请求,太长则会让应用忽视输入的感觉。如果数据大多本地(已在内存),可以更短;若每次查询都打到服务器,靠近 250–300ms 更好。
防抖配合最小查询长度效果最佳。对许多应用来说,2 个字符足以避免像“a”这种匹配全部的无用查询。如果用户常按短码(如 “HR” 或 “ID”),允许 1–2 个字符,但只有在他们停顿时才触发搜索。
请求控制与防抖一样重要。没有它,慢响应会乱序到达并覆盖较新的结果。如果用户输入 “car” 然后快速加上 “d” 变成 “card”,“car”的响应可能最后到达并把 UI 回推。
使用以下任一模式:
等待时也要给出即时反馈,让应用在结果到达前也显得有响应。不要阻塞输入。在结果区域显示小内联旋转图标或简短提示如 “正在搜索……”。如果保留前一次结果在屏幕上,给它一个微妙标签(例如 “显示之前的结果”),以免用户混淆。
一个实用例子:在 CRM 联系人搜索中,保持列表可见,防抖 200ms,2 个字符后才搜索,并在用户继续输入时取消旧请求。界面保持沉稳,结果不闪烁,用户感到受控。
缓存是让搜索感觉即时的最简单方法之一,因为很多查询会重复。人们会打字、退格、重试相同查询或在几个过滤之间往返。
用能匹配用户实际意图的键来缓存。一个常见错误是只按文本查询缓存,结果在过滤器变化时显示错误数据。
实用的缓存键通常包含归一化的查询字符串加上当前过滤器和排序。如果有分页,包含页码或游标。如果权限按用户或工作区不同,也要包含之。
保持缓存小且短期。只存最近 20–50 次查询,条目在 30–120 秒后过期。足以覆盖来回打字,但又足够短,不会让界面长时间显示错误结果。
你也可以通过预先填充缓存来加速:最近项、最近打开的项目或默认空查询结果(通常为 “所有项” 按最近排序)。在小型 CRM 中,缓存客户列表的第一页能让第一次搜索交互立刻有响应感。
不要以同样方式缓存失败结果。临时的 500 或超时不应污染缓存。如果保留错误,也要单独存储并设置更短的 TTL。
最后,决定数据变更时如何使缓存失效。至少在当前用户创建、编辑或删除可能出现在结果中的项时清除相关缓存条目,在权限变化或切换工作区/账户时也要清除。
结果看起来随机会让用户不再信任搜索。通过几条可解释的规则,你无需专用搜索引擎也能得到稳健的相关性。
从匹配优先级开始:
然后对重要字段做小幅提升。标题通常比描述更重要;当用户粘贴 ID 或标签时,ID 或标签可能最重要。保持权重小且一致,便于推理。
在此阶段,轻量的错别字处理主要靠规范化,而不是重度模糊匹配。规范化查询和被搜索文本:小写、修剪空白、合并多重空格、在需要时移除变音符号。这一步能解决很多“为什么没搜到”的抱怨。
提前决定如何处理符号和数字,因为它们会改变用户期望。一个简单策略是:将话题标签作为 token 保留,把连字符和下划线视为空格,保留数字,并在搜索邮箱或用户名时保留 @ 和 .,去掉大多数标点。
让排序可解释。一个简单做法是在日志中为每个结果存一条短的调试原因:"title 中的前缀优先于 description 中的包含"。
快速的搜索体验往往取决于一个决定:哪些可以在设备上过滤,哪些必须向服务器请求。
当数据量小、已经在屏幕上或最近使用过时,本地过滤最有效:最近 50 条聊天、最近项目、已保存联系人或你为列表视图已获取的项。如果用户刚看过这些项,他们期望搜索能立即找到它们。
服务器搜索用于海量数据、频繁变化的数据或不想下载的私有数据。它也在结果依赖权限与共享工作区时必需。
一个稳定的实用模式:
示例:CRM 可以在用户输入 “ann” 时即时本地过滤最近查看的客户,然后悄悄加载服务器端的完整结果以覆盖整个数据库。
为避免布局位移,预留结果空间并就地更新行。若从本地结果切换到服务器结果,显示一个微妙的 “结果已更新” 提示通常就够了。键盘行为也应保持一致:方向键在列表中移动,回车选择,Esc 清除或关闭。
大多数搜索挫败感并不在排序,而在用户处于动作之间时屏幕如何表现:在他们输入之前、结果更新期间以及当没有匹配时。
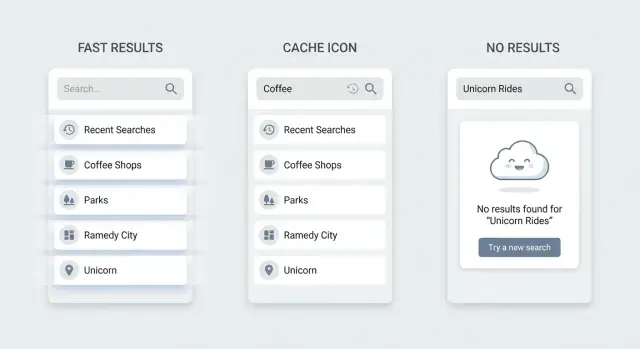
空白的搜索页会迫使用户猜测什么有效。更好的默认是显示最近搜索(让他们重复操作)和一小组热门项或常见分类(让他们不必打字就能浏览)。保持简洁、易扫视并可一键操作。
人们把闪烁解读为慢。每次按键清空列表会让界面看起来不稳定,即便后端速度很快。
保留之前的结果并在输入附近显示小的加载提示(或在输入框内显示细微旋转)。若预期等待时间更长,可以在底部添加几行骨架屏,同时保留现有列表。
请求失败时,显示内联信息并保留旧结果可见。
只写“无结果”的空白页是死胡同。根据 UI 支持的功能建议下一步。如果有激活的过滤器,提供一键“清除过滤器”。如果支持多词查询,建议尝试更少的词。如果你有已知同义词,提出替代词。
还要给出回退视图,让用户继续操作(最近项、热门项或分类),并在产品支持时提供“创建新项目”的操作。
具体场景:有人在 CRM 中搜索 “invoice” 却没有结果,因为项被标为 “billing”。有用的状态可以建议 “试试:billing” 并展示 Billing 分类。
记录无结果查询(包含激活的过滤器),以便添加同义词、改进标签或创建缺失内容。
有即时感的搜索来自一个小而清晰的版本 1。多数团队卡住是因为试图在第一天就支持所有字段、所有过滤以及完美排序。
从一个用例开始。示例:在小型 CRM 中,人们多按姓名、邮箱和公司搜索客户,然后按状态(Active、Trial、Churned)筛选。把这些字段和过滤写下来,让所有人构建同样的东西。
一个实用的一周计划:
让失效策略简单:登出、切换工作区或对底层列表做任何变更(创建、删除、状态改变)时清除缓存。如果无法可靠检测变更,使用短 TTL,把缓存当作提升速度的提示而非事实来源。
用最后一天做衡量。跟踪首次结果时间、无结果率和错误率。如果首次结果时间不错但无结果率高,说明字段、过滤或措辞需要调整。
多数“搜索慢”的抱怨其实关于反馈和正确性。用户能接受一秒的等待,只要界面感觉活跃且结果合理。当输入感觉卡住、结果跳动或应用暗示用户做错了事时,他们会放弃。
常见陷阱是把防抖设得过高。如果你在做任何事情前等待 500–800ms,输入会显得不灵敏,尤其是对于像 “hr” 或 “tax” 这样的短查询。保持延迟小,并展示即时 UI 反馈,避免输入被忽视的感觉。
另一个挫败点是让旧请求胜出。如果用户先输入 “app” 然后快速加上 “l”,“app” 的响应可能最后到达并覆盖 “appl” 的结果。在开始新请求时取消旧请求,或忽略与当前查询不符的响应。
当缓存键太模糊时,缓存会适得其反。如果缓存键仅是查询文本,而你还有过滤器(状态、日期范围、分类),就会显示错误结果,用户会失去信任。把查询 + 过滤 + 排序视为一个身份。
排序错误往往微妙但很痛苦。用户期望精确匹配优先。一个简单而一致的规则集通常胜过聪明的方案:
无结果屏如果什么都不做很糟糕。显示已搜索内容,提供清除过滤器的选项,建议更宽泛的查询,并展示一些热门或最近项。
示例:一位创始人在简单 CRM 中搜索客户,输入 “Ana”,并打开了 Active 过滤器却没有结果。一个有帮助的空状态会写 “在 'Ana' 的 Active 状态下没有客户”,并提供一键 “显示所有状态”。
在添加专用搜索引擎之前,确保基础让人感觉沉稳:输入流畅、结果不跳动,并且 UI 始终告知用户正在发生什么。
版本 1 的快速检查表:
然后确认缓存带来的利大于弊。保持它小(仅最近查询),缓存最终结果列表,并在底层数据变化时使其失效。如果无法可靠检测变化,就缩短缓存生命周期。
小而可测的步子向前推进:
如果你正在 Koder.ai (koder.ai) 上构建应用,把搜索当作一等公民来对待并写入你的提示与验收检查:定义规则、测试各种状态,并让 UI 从第一天起就表现沉稳。
目标是在大约一秒内给出可见反馈。可以是结果更新、稳定的“正在搜索”指示,或在保留上一次结果同时显示的细微加载提示,让用户不会怀疑输入是否被接收。
通常是界面而非后端造成的感受问题。输入卡顿、结果闪烁或无声等待都会让搜索感觉慢,即便服务器很快,因此先保证输入流畅并让更新看起来沉稳。
先从 150–300ms 开始。数据主要在内存时用短一些,所有请求都打到服务器时靠近 250–300ms。延迟太长会让用户觉得应用在忽略他们。
是的,大多数应用需要。常见的最小长度是 2 个字符,避免像 “a” 这类会匹配所有内容的噪声查询。但如果用户常搜短码(比如 “HR” 或 ID),可以允许 1–2 个字符,并结合短暂停顿与请求控制。
在开始新查询时取消进行中的请求,或者只渲染来自最新请求的结果,或比较响应与当前查询字符串并忽略不匹配的响应。这样可以防止较慢的旧响应覆盖更新后的结果。
保持上一次结果可见,并在结果区或输入附近显示一个小而稳定的加载提示。每次清空列表会产生闪烁,让界面显得更慢;保留现有内容直到新内容准备好会更沉稳。
用包含规范化查询、当前过滤器和排序的键来缓存最近查询,不要仅按文本缓存。缓存要小且短期(例如保留最近 20–50 次、过期时间 30–120 秒),并在底层数据变更时清除相关条目。
用用户能理解的简单规则:精确匹配优先,然后前缀匹配,再到包含匹配,并对重要字段(姓名或 ID)给予小幅提升。保持规则一致且可解释,避免顶端结果看起来随机。
先搜那些最常用的字段,再根据真实使用情况扩展。实践中的版本 1 通常是 3–5 个字段和 0–2 个过滤器;长篇笔记的全文检索可以等到确有需求再加。
显示被搜索的内容,提供便捷的恢复操作(比如清除过滤器),并在可能时建议更宽泛或更简单的查询。保留一个备用视图,例如最近项或热门项,让用户能继续操作而不是陷入死胡同。