2025年6月04日·1 分钟
为什么横向扩展比纵向扩展更难
纵向扩展通常只是增加 CPU/RAM;横向扩展需要协调、分区、一致性以及更多运维工作——这就是它更困难的原因。
纵向扩展通常只是增加 CPU/RAM;横向扩展需要协调、分区、一致性以及更多运维工作——这就是它更困难的原因。
扩展就是“在不崩溃的情况下处理更多”。这个“更多”可以是:
当人们谈论扩展时,通常想要改进以下一项或多项:
这些问题的核心主题是:纵向扩展保留了“单一系统”的感觉,而横向扩展把你的系统变成需要协调的独立机器集合——而这种协调正是难度爆发的地方。
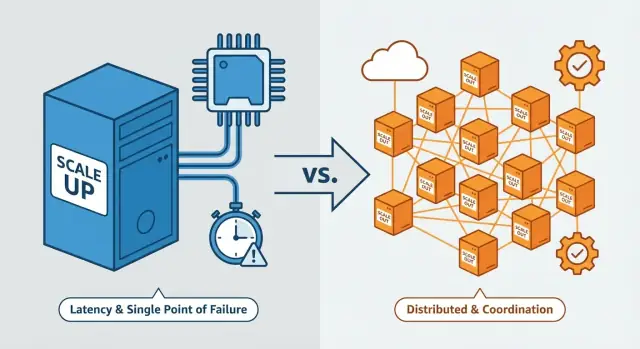
纵向扩展意味着把一台机器变强。你保持相同的架构,但升级服务器(或虚拟机):更多 CPU 核心、更多内存、更快的磁盘、更高的网络吞吐。\n 把它想象成买一辆更大的卡车:仍然只有一个司机和一辆车,但能运更多货。
横向扩展意味着增加更多机器或实例并把工作分布到它们上面——通常在负载均衡器后面运行。与其使用一台更强的服务器,不如运行多台协同工作的服务器。\n 这就像用更多的卡车:总体能搬运更多货,但现在你要考虑调度、路径规划和协调问题。
常见触发因素包括:
团队常先纵向扩展,因为快速(升级机器),当单机达到上限或需要更高可用性时再横向扩展。成熟架构通常混合使用两者:根据瓶颈既有更大的节点也有更多的节点。
纵向扩展吸引人,因为它把你的系统保留在一个地方。单节点通常有单一的内存和本地状态来源。一个进程拥有内存缓存、任务队列、会话存储(如果会话在内存中)和临时文件。
在一台服务器上,大部分操作更直接,因为几乎不需要跨节点协调:
纵向扩展时,你拉的是熟悉的控制杆:加 CPU/内存、使用更快存储、优化索引、调优查询和配置。你不必重新设计数据如何分布,也不必处理多节点如何就“下一步发生什么”达成一致。
纵向扩展并非“免费”——只是把复杂性限制在内部。\n 最终你会遇到上限:你能租到的最大实例、收益递减,或高端成本陡增。你也可能承担更高的停机风险:如果那台大机器故障或需要维护,除非你添加了冗余,否则大量系统会随之下线。
横向扩展时,你不只是得到“更多服务器”。你得到更多需要就每一项工作、时间和数据负责的独立参与者。\n 在单机场景下,协调通常是隐式的:一个内存空间、一个进程、一个状态查看点。多台机器时,协调成了你必须设计的功能。
常见工具和模式包括:
协调类 bug 很少表现为干净的崩溃。更常见的是:
这些问题通常只在真实负载下、部署期间或部分故障发生时显现。系统大多时间看起来正常——直到承受压力时。
横向扩展时,你通常不能把所有数据放在一个地方。你把数据拆到多台机器(分片),以便多节点并行存储和服务请求。这个拆分引发了复杂性:每次读写都依赖“这条记录在哪个分片?”
范围分区(range partitioning) 按有序键把数据分组(例如用户 A–F 在分片 1,G–M 在分片 2)。直观且支持范围查询(“展示上周的订单”)。缺点是负载不均:某个范围受欢迎时,相应分片会成为瓶颈。
哈希分区(hash partitioning) 用哈希函数把键分散到分片上。它更能均匀分布流量,但让范围查询变得困难,因为相关记录被散到不同分片。
增加节点后你想利用它——这意味着必须移动部分数据。移除节点(计划内或故障)时,其他分片需接手。重平衡会触发大量传输、缓存预热和临时性能下降。迁移期间还必须防止陈旧读取和错误路由写入。
即便使用哈希,真实流量也不是均匀的。名人账号、热门商品或基于时间的访问模式会把读/写集中到某个分片。一个热点分片就能限制整个系统的吞吐量。
分片带来持续的责任:维护路由规则、运行迁移、在模式变更后回填数据、以及在不破坏客户端的情况下计划分裂/合并。
横向扩展时,你不仅仅是增加更多服务器——你增加应用的多个副本。难点在于“状态”:应用在请求之间或处理过程中“记住”的任何东西。
用户在服务器 A 登录,但下次请求落到服务器 B 时,B 是否知道用户身份?
缓存能加速响应,但多台服务器意味着多份缓存。你需要处理:
多 worker 场景下,后台任务可能被执行两次,除非你进行专门设计。通常需要队列、租约/锁,或让任务具备幂等性,以免在重试和重启时发生“发送账单两次”或“重复扣款”。
在单机或单主数据库下,通常有一个清晰的“真相来源”。横向扩展时,数据和请求分布在多台机器上,保持各方同步变成持续的关注点。
为了性能和成本,规模化时常用最终一致性,但这带来一些令人惊讶的边界情况。
常见问题包括:\n
你无法消除故障,但可以为其设计:
跨服务的事务(订单 + 库存 + 支付)需要多个系统达成一致。如果某一步中途失败,你需要补偿动作和精细的记账。经典的“要么全部成功要么全部回滚”在网络和节点会独立失败的环境下很难实现。
对必须正确的东西使用强一致性:支付、账户余额、库存计数、座位预定。对非关键数据(分析、推荐),最终一致性通常可以接受。
纵向扩展时,很多“调用”是同一进程内部的函数调用:快速且可预测。横向扩展时,相同的交互变成网络调用——增加延迟、抖动和需处理的失败模式。
网络调用有固定开销(序列化、排队、跳数)和可变开销(拥塞、路由、邻居噪声)。即便平均延迟不错,尾延迟(最慢的 1–5%)也能主导用户体验,因为一个慢依赖会阻塞整个请求。
带宽和丢包也会成为约束:在高请求率下,“小”负载也会累积,重传无声地增加系统压力。
没有超时,慢调用会堆积,线程被占满。有了超时和重试可以恢复——直到重试放大了负载。
一个常见失败模式是重试风暴:后端变慢,客户超时并重试,重试增加负载,后端更慢。\n 更安全的重试通常需要:\n
多实例时,客户端需要知道把请求发到哪里——通过负载均衡器或服务发现加上客户端侧平衡。无论哪种方式,你都增加了活动部件:健康检查、连接抽离、不均匀流量分配,以及路由到半坏实例的风险。
为防止过载蔓延,你需要反压:有界队列、断路器和限流。目标是快速且可预测地失败,而不是让小的变慢变成系统级事故。
纵向扩展通常以直观的方式失败:一台更大的机器仍是单点。如果它变慢或崩溃,影响明显。
横向扩展改变了数学模型。多节点时,部分机器不健康是正常情况。系统“可用”,但用户仍会看到错误、慢页或不一致行为。这就是你必须为之设计的部分故障。
在横向架构中,服务依赖其他服务:数据库、缓存、队列、下游 API。小问题可以引发连锁反应:
为抵御部分故障,系统引入冗余:
这提高可用性,但引入了边界情况:脑裂、过时副本,以及在无法达到法定数时如何决策。
常见模式包括:\n
单机时,“系统故事”集中在一处:一份日志、一张 CPU 图表、一个进程可查看。横向扩展时,故事被分散了。
每多一台节点,就多一路日志、指标和追踪。难点不在于收集数据——而在于关联它们。一次结账错误可能从某个 web 节点开始,调用两个服务,触发缓存,并从某个特定分片读取,线索分散在不同的时间线和位置。
问题也变得更有选择性:一台节点配置错误,一片分片过热,一个可用区延迟更高。调试会感觉很随机,因为大多数时间系统“工作正常”。
分布式追踪就像给请求贴上跟踪号。关联 ID 是该跟踪号。把它传递给各服务并写入日志,这样你就能用一个 ID 拉出端到端的完整旅程。
组件越多,告警越多。若不调优,团队会疲于应对告警。目标是可操作的告警,能说明:
容量问题常在故障前显现。监控饱和度信号(CPU、内存、队列深度、连接池使用率)。如果只有部分节点出现饱和,怀疑负载均衡、分片或配置漂移——而不是单纯“更多流量”。
横向扩展时,部署不再是“替换一台机器”。你需要在保持服务可用的同时协调多台机器的变更。
横向部署常用滚动更新(逐台替换)、金丝雀(把小部分流量导到新版本)或蓝绿(在两个完整环境间切换)。它们减小了冲击范围,但增加了需求:流量切换、健康检查、连接抽离、以及“足够好才能继续”的判定标准。
在渐进式部署期间,新旧版本并存。版本倾斜意味着系统必须容忍混合行为:
API 需要向前/向后兼容,而不仅仅是正确。数据库模式变更应尽量采用可扩展方式(先添加可空字段,再将其变为必填)。消息格式应版本化,让消费者能同时读取旧/新事件。
回滚代码容易;回滚数据很难。如果迁移删除或重写字段,旧代码可能崩溃或静默错误处理记录。“扩展/收缩”迁移更安全:先部署能兼容两种模式的代码,迁移数据,随后再移除旧路径。
节点越多,配置管理就成部署的一部分。一台节点的陈旧配置、错误特性开关或过期凭据就能制造难以复现的间歇性故障。
横向扩展表面上看更便宜:很多小实例每小时单价低。但总成本不只是计算资源。增加节点还意味着更多网络、更多监控、更多协调,以及保持一致性所需的时间投入。
纵向扩展把开支集中到更少主机——通常更少的补丁、更少的代理、要传输的日志更少、要抓取的指标更少。\n 横向扩展时,单价可能更低,但你常常需要付出:
为安全处理峰值,分布式系统通常不满负载运行。你要在多个层级保留余量,这可能意味着为数十或数百台实例支付空闲成本。
横向扩展增加了值班负担并要求成熟的工具链:告警调优、运行手册、事故演练和培训。团队还要花时间划定所有权边界(谁负责哪个服务?)和协调事故。\n 结果是:即便“每单位更便宜”,总体成本可能因为人员时间、运维风险和让多台机器行为像单一系统所需的工作而更高。
选择纵向(更大机器)还是横向(更多机器)不仅仅是价格问题,还是关于工作负载形态和团队能承受多少运维复杂度。
从工作负载入手:
一个常见且稳健的路径:
许多团队把数据库保持纵向(或轻度集群化),同时将无状态应用层横向扩展。这样能降低分片痛苦,同时快速扩展 web 容量。
当你具备可靠的监控与告警、经过测试的故障转移、负载测试、以及可重复且可安全回滚的部署流程时,就更接近准备就绪。
很多扩展痛点不仅仅是“架构”问题——而是运维循环:安全迭代、可靠部署、在现实与计划不符时快速回滚。\n 如果你构建的是 web、后端或移动系统,想在不失控的前提下快速前进,Koder.ai 可以帮助你更快地原型和交付,同时辅助做出这些扩展决策。它是一个通过聊天构建应用的 vibe-coding 平台,内部采用基于 agent 的架构。实践中这意味着你可以:
由于 Koder.ai 在全球 AWS 上运行,它也支持在不同区域部署以满足延迟和数据传输约束——一旦多可用区或多区域可用性成为你扩展故事的一部分,这点很有用。
纵向扩展是把单台机器做大(更多 CPU/RAM/更快磁盘)。横向扩展是增加多台机器并把工作分摊开。
纵向扩展通常感觉更简单,因为应用依然像“单个系统”那样工作,而横向扩展需要多台系统之间保持协调和一致。
一旦有了多台节点,你就必须显式处理协调问题:
单机在很多情况下默认避免了这些分布式系统问题,因此横向扩展带来的复杂度明显更高。
这是让多台机器看起来像一个整体所需的时间和逻辑:
即便每个节点本身很简单,节点间的系统行为在负载和故障下也更难以推理。
分片/分区将数据分散到多个节点,因此没有单台机器需要存储或服务全部数据。难点在于:
它还增加了运维工作(迁移、回填、分片映射等)。
状态是指应用在请求之间或处理过程中“记住”的任何内容(会话、内存缓存、临时文件、任务进度)。
横向扩展时,请求可能落在不同服务器上,因此通常需要共享状态(例如 Redis/数据库),或者接受像黏性会话这样的折衷方案。
当多个 worker 都可能拿到同一个任务或任务被重试时,可能出现重复处理(例如重复扣款或重复发送邮件)。
常见缓解措施:
强一致性意味着写入成功后,所有读者立刻都能看到最新值。最终一致性意味着更新会传播,但短时间内可能有读者看到旧值。
对关键正确性数据(支付、余额、库存)使用强一致性;对可容忍延迟的数据(分析、推荐)通常可接受最终一致性。
在分布式系统中,许多调用变成了网络调用,带来延迟、抖动和更多失败模式。通常需要注意:
部分故障是指系统中某些组件变慢或不可用,而其他组件仍正常工作。系统可能“在线”,但仍产生错误、超时或不一致表现。
应对措施包括复制、法定数(quorum)、多可用区部署、断路器和优雅降级,以防止故障蔓延。
当应用部署在多台机器上,证据分散在不同节点:日志、指标、追踪各自为政。
实用做法: