2025年12月23日·1 分钟
SaaS API 速率限制:每用户、每组织与每 IP 的模式
SaaS API 的速率限制模式:按用户、按组织和按 IP 的限制建议,包含清晰的响应头、错误体和可执行的发布建议,便于客户理解。
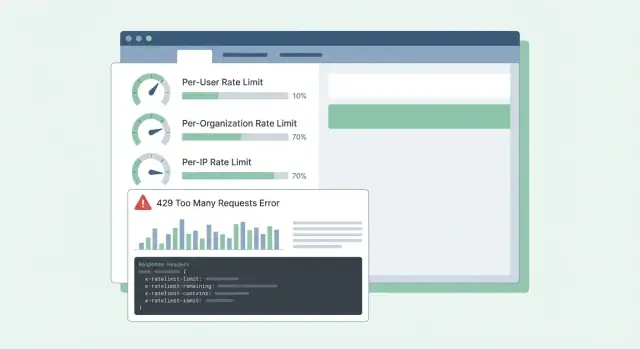
SaaS API 的速率限制模式:按用户、按组织和按 IP 的限制建议,包含清晰的响应头、错误体和可执行的发布建议,便于客户理解。
速率限制和配额听起来相似,很多人会把它们当成同一件事。速率限制是你调用 API 的速度上限(如每秒或每分钟的请求数)。配额是你在更长时间内能使用的总量(按日、按月或按计费周期)。两者都正常,但当规则不可见时会让人觉得行为很随机。
经典的抱怨是:“昨天还好好的”。使用量很少会保持稳定。短时间的突发就可能把人推过阈值,即便他们的日总量看起来还行。想象有个客户每天跑一次报表,但今天作业在超时后重试,2 分钟内发出了 10 倍的请求。API 把他们阻止了,而他们看到的只是突然的失败。
当错误信息含糊时,混淆会更严重。如果 API 返回 500 或泛型信息,客户会以为你的服务宕机,而不是他们触及了限制。他们会发紧急工单、造出变通方案,或者换供应商。即便是 429 Too Many Requests 也会让人沮丧,如果它没有说明下一步该怎么做。
大多数 SaaS API 限制流量主要有两个原因:
把这些目标混在一起会导致糟糕的设计。滥用控制通常按 IP 或按 token 做得很严格。用于正常使用调整的限制通常按用户或按组织,并且应该伴随清晰的指引:哪个限制被触发、何时重置、如何避免再次触发。
当客户能预测限制时,他们会围绕它做计划。当他们不能时,每次突发都会显得像 API 出了问题。
速率限制不仅仅是节流。它们是一个安全系统。在你选数字之前,先想清楚你想保护什么,因为不同的目标会导致不同的限制和不同的预期。
可用性通常是首要考虑。如果少数客户端能突增流量把你的 API 推到超时,大家都会受到影响。这类限制应让服务器在突发中保持响应,并快速失败,而不是让请求堆积。
成本是很多 API 背后的隐性驱动。有些请求很便宜,有些请求很昂贵(例如 LLM 调用、文件处理、写存储、付费第三方查找)。例如在像 Koder.ai 这样的平台上,一个用户通过聊天式应用生成可能触发大量模型调用。跟踪昂贵操作的限制可以避免意外高额账单。
滥用的表现不同于合法的大量使用。凭证填充、token 猜测和爬取常常表现为从少数 IP 或账户来的大量小请求。这种情况下你需要严格的限制和快速的阻断。
在多租户系统中,公平性很重要。一个喧闹的客户不应该拖垮其他人。实践中常常意味着分层控制:防突发保护让 API 在分钟级别健康,成本保护针对昂贵端点或动作,滥用保护针对认证和可疑模式,公平性保护则防止某个组织把资源抢光。
一个简单的测试帮助决策:选一个端点,问自己,“如果这个请求量变为 10 倍,首先坏掉的是什么?”答案会告诉你优先保护的目标,以及应该沿哪个维度(用户、组织、IP)进行限制。
大多数团队从单一限制开始,后来发现它伤害了不该被伤害的人。目标是选择与真实使用匹配的维度:谁在调用、谁在付费、什么看起来像滥用。
SaaS 中常见的维度包括:
每用户限制关心的是租户内部的公平性。如果某个人跑大导出,应该比团队其他人更感受到减速。
每组织限制关心的是预算和容量。即使十个用户同时跑作业,组织也不应该突增到破坏你的服务或你的定价假设的程度。
每 IP 限制应被视作安全网,而不是计费工具。IP 可能被共享(办公室 NAT、移动运营商),因此把这些限制设置得宽松些,并主要用于阻止明显滥用。
当你组合多个维度时,决定哪个“胜出”很重要。一个实用规则是:如果任何相关限制超出,就拒绝请求,并返回最具可操作性的原因。如果是工作区超出配额,就不要归咎于用户或 IP。
示例:Koder.ai 上某个 Pro 计划的工作区可能允许一定的构建请求稳态流量,同时限制单个用户在一分钟内发出数百次请求。如果合作伙伴集成使用一个共享 token,每 token 限制可以防止它淹没交互式用户。
大多数速率限制问题不是数学问题,而是选择与客户调用方式匹配的行为,并在负载下保持可预测性。
令牌桶是常见默认,因为它允许短时突发同时强制长期平均。刷新仪表盘的用户可能会触发 10 次快速请求。令牌桶允许他们在有令牌积累时这样做,然后再把速率放慢。
泄桶更严格。它把流量平滑成恒定的输出,当你的后端无法承受峰值(例如昂贵的报表生成)时,它很有用。代价是客户更早感到受限,因为突发会被排队或拒绝。
基于窗口的计数器简单,但细节很重要。固定窗口在边界处会产生突变(用户可以在 12:00:59 和 12:01:00 各突发一次)。滑动窗口感觉更公平并减少边界突发,但需要更多状态或更好的数据结构。
另一类限制是并发(进行中的请求)。它保护你免受缓慢客户端连接和长耗时端点的影响。客户可能在 60 次/分钟限制内,但同时保持 200 个打开请求,从而把系统压垮。
在真实系统中,团队常常组合一小套控制:用于一般请求速率的令牌桶、用于慢或重端点的并发上限,以及针对端点组(便宜的读取 vs 昂贵的导出)的独立预算。如果只按请求数限制,一个昂贵的端点可能会把其他所有事情挤兑掉,让 API 显得随机失效。
好的配额感觉公平且可预测。客户不应该在被阻止后才发现规则。
把短期和长期分离清楚:
许多 SaaS 团队同时使用两者:短期速率限制阻止突发,加上与定价挂钩的月度配额。
硬限制 vs 软限制主要是支持策略的选择。硬限制会立即阻断。软限制会先警告,然后再阻断。软限制能减少愤怒的工单,因为用户有机会修复 bug 或升级。
当有人超出时,行为应与保护目标匹配。当过度使用会伤害其他租户或爆炸性增加成本时,阻断是合适的。退化处理(变慢处理或降低优先级)则适用于你希望让工作继续但降低优先级的场景。“先结账后计费”在使用可预测且已有计费流程时也可行。
按层级的限制在每个层级都有清晰的“预期使用形态”时最有效。免费层可能允许较小的月度配额和较低的突发速率,而商业和企业层有更高的配额与突发上限,以便后台作业能快速完成。这类似于 Koder.ai 的免费、Pro、Business 与 Enterprise 各层对能做多少以及超过后怎么升级的不同预期。
尽早支持自定义限制对企业客户很值得。干净的做法是“按计划的默认值,按客户覆盖”。为每个组织(有时按端点)存储管理员设置的覆盖,并确保它在计划变更时保留。还要决定谁可以请求变更以及生效速度。
示例:某客户在月末最后一天导入 50,000 条记录。如果他们的月度配额快用完,在 80–90% 时发出软警告能给他们时间暂停。每秒的短期速率限制防止导入洪泛 API。经批准的组织覆盖(临时或永久)可以让业务继续进行。
先写下你要计数的内容以及它归谁。大多数团队最后会有三个身份:已登录用户、客户组织(或工作区)和客户端 IP。
一个实用计划:
设置限制时,按层级和端点组思考,而不是一个全局数字。一个常见失败是依赖跨多个应用服务器的内存计数器。计数器可能不同步,用户会看到“随机”的 429。使用像 Redis 这样的共享存储能在实例间保持稳定,并用 TTL 保持数据量小。
发布很重要。先用“仅记录”模式(记录本会被阻止的请求),然后强制一个端点组,再扩展。这能避免醒来时收到大量支持工单。
当客户触及限制时,最糟糕的结果是混淆:“你们的 API 宕机了,还是我操作有问题?”清晰、一致的响应可以减少支持工单并帮助开发者修正客户端行为。
当你在主动阻止调用时,使用 HTTP 429 Too Many Requests。保持响应体可预测,这样 SDK 和仪表板就能解析。
下面是一个在 per-user、per-org 和 per-IP 限制下都适用的简单 JSON 结构:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
头部应说明当前窗口以及客户端下步可做的事。如果只加几项,先从这些开始:RateLimit-Limit、RateLimit-Remaining、RateLimit-Reset、Retry-After 和 X-Request-Id。
示例:某客户的 cron 作业每分钟运行一次,突然开始失败。返回 429 并带有 RateLimit-Remaining: 0 和 Retry-After: 20 时,他们立刻知道这是限流而非故障,可以把重试延迟 20 秒。如果他们把 X-Request-Id 一起发给支持,你能快速找到对应事件。
还有一点:在成功响应上也返回相同的头。客户就能在触及边界前看到接近阈值的迹象。
好的客户端能让限流感觉公平。糟糕的客户端会把临时限流变成故障,因为它们会更猛地重试。
收到 429 时,把它当作减速信号。如果响应告诉你何时重试(例如通过 Retry-After),至少等到那时再重试。如果没有,使用指数退避并加入抖动,这样一千个客户端就不会同时重试。
把重试限定在有限范围内:限制重试的最大延迟(例如 30–60 秒)和总重试时间(例如 2 分钟后放弃并上报错误)。同时记录带有限流细节的事件,便于开发者后续调优。
不要对所有请求都重试。许多错误不会仅靠重试就解决:400 验证错误、401/403 认证错误、404 未找到、以及反映真实业务规则的 409 冲突,都不应无脑重试。
在写(create、charge、send email)端点上重试有风险。如果超时后客户端重试,可能造成重复创建。使用幂等键:客户端为每个逻辑动作发送唯一键,服务器对同一键的重复请求返回相同结果。
好的 SDK 能把开发者真正需要的信息暴露出来:状态(429)、建议的等待时长、请求是否安全重试,以及类似“Rate limit exceeded for org. Retry after 8s or reduce concurrency.” 的提示信息。
大多数关于限制的支持工单并不是在抱怨限制本身,而是在抱怨惊讶。如果用户无法预测接下来会发生什么,他们会认为 API 坏了或不公平。
仅用基于 IP 的限制是常见错误。很多团队背后只有一个公共 IP(办公室 Wi‑Fi、移动运营商、云 NAT)。如果按 IP 限制,某个繁忙的客户可以阻塞同一网络上的所有人。优先使用每用户和每组织限制,把每 IP 当作滥用的后备。
另一个问题是把所有端点一视同仁。一次廉价的 GET 和一次重度导出不应共享同一预算。否则客户会在浏览期间消耗掉配额,随后在尝试做真正的任务时被阻止。按端点组分桶或按成本为请求加权。
重置时机也需要明确。“每天重置”不够具体。是哪个时区?是滚动窗口还是午夜重置?如果是日历重置,说明时区;如果是滚动窗口,说明窗口长度。
最后,含糊的错误会造成混乱。返回 500 或泛型 JSON 会让人更频繁地重试。使用 429 并包含 RateLimit 头,这样客户端可以智能退避。
示例:如果某团队从共享公司网络构建 Koder.ai 集成,仅有 IP 限制会把整个组织阻塞并显得像随机故障。明确的维度和清晰的 429 响应能避免这种情况。
在对所有人开启限制前,做一次关注可预测性的最终检查:
Retry-After 以及速率限制头(Limit、Remaining、Reset)。在 JSON 体中包含简短信息、触发的限制范围和建议的重试时间。\n- 监控突发和误报。按端点组跟踪 429 率、被阻止的 top 调用者以及成功请求的突然下降。在阻断激增时告警。\n- 制定例外方案:白名单、临时提升、紧急覆盖以及审批人。直觉检查:如果你的产品有 Free、Pro、Business、Enterprise 层(像 Koder.ai),你应该能用简单语言说明普通客户每分钟和每天能做什么,以及哪些端点会被区别对待。
如果你不能把 429 解释清楚,客户会认为 API 出了问题,而不是你在保护服务。
想象一个 B2B SaaS,用户在工作区(org)内协作。几个高能用户运行重度导出,很多员工位于同一个共享办公室 IP。如果你只按 IP 限制,会把整个公司堵住。如果只按用户限制,一个脚本仍然能伤害整个工作区。
一个实用组合是:
当有人触及限制时,你的信息应告诉他们发生了什么、下一步怎么做以及何时重试。支持团队应能用类似这样的措辞支撑:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
把这类消息与 Retry-After 以及一致的 RateLimit 头配合,客户就无需猜测。
避免惊讶的发布流程:先仅观察(report-only),再警告(在头部和软警告里),然后强制执行(返回带明确重试时间的 429),再按层级调优阈值,最后在大规模发布和客户上线后复审。
如果你想快速把这些想法变成可运行的代码,像 Koder.ai (koder.ai) 这样的 vibe-coding 平台可以帮你起草速率限制规范并生成在服务间一致强制的 Go 中间件。
速率限制(rate limit)限制的是请求速率,例如每秒或每分钟的请求数。配额(quota)限制的是更长时间内的使用量,例如按日、按月或按计费周期。\n\n为了减少“昨天还能用”的惊讶,最好同时展示两者,并明确重置时点,让客户能够预测行为。
从你要防止的失败类型开始。如果短期突发会导致超时,你需要短期的突发控制;如果某些端点会产生高成本,就需要基于成本的预算;如果看到的是暴力破解或爬取,则要严格的滥用防护。\n\n一个快速判断:问自己“如果某个端点流量变为 10 倍,首先会出什么问题:延迟、成本还是安全?”然后围绕那个目标设计限制。
用每用户限制防止某个人拖慢同一租户内的其他人;用每组织限制让整个工作区保持可预期的上限,匹配定价和容量。若共享集成密钥可能淹没交互式用户,增加每 token/API key 限制。\n\n把每 IP 限制作为滥用的安全网,但不要把它当成计费工具,因为共享网络会导致误伤。
当你想允许短时间突发但保持长期平均速率时,令牌桶(token bucket)是一个好默认选择,适合仪表盘等会短时间发出多次请求的场景。\n\n如果后端无法容忍任何峰值,像泄桶(leaky bucket)或显式排队会更严格但也更不宽容突发流量,延迟感会更强。
当问题来自于过多的并发(进行中的请求)而不是总请求数时,应该增加并发限制。常见场景包括慢端点、长轮询、流式传输或大型导出,客户可能在每分钟请求数内但同时保持大量打开的连接。\n\n并发上限可防止客户在“每分钟 60 次请求”内却占用数百个打开连接的情况。
当你在主动限流时,返回 HTTP 429,并在错误体中说明哪个范围被触发(user、org、IP 或 token)以及何时可以重试。最有用的头是 Retry-After,它告诉客户端确切的等待时间。\n\n同时在成功响应上也返回速率限制头,这样客户可以在接近阈值时就察觉到而不是被动等待被阻止。
简单规则:如果响应带有 Retry-After,至少等待该时长再重试。如果没有,采用指数退避并加入随机抖动,避免大量客户端同时重试。\n\n把重试次数和总重试时间设上限(例如最多重试 2 分钟),并避免无脑重试那些不会仅靠重试就解决的错误(如 400、401、403、404、409 等)。
当超出会伤害其他客户或导致无法承受的即时成本时,使用硬限制。想先提醒用户并给他们时间修复或升级时,使用软限制。\n\n实用模式是:在 80–90% 时给出警告,然后再执行限制,这样能减少紧急支持工单同时又不会放任失控使用。
IP 限制要宽松并主要用于检测滥用,因为许多公司或移动运营商会通过 NAT 共享一个公网 IP。如果把每 IP 的上限设得过低,一个脚本的异常行为可能会阻塞整个公司网络。\n\n对于常规流量整形,更倾向于使用每用户和每组织限制,把每 IP 当作后备安全网。
分阶段发布可以让你在用户感到痛苦之前发现问题。先做“仅记录”以测量会被阻止的请求,接着在小范围或少数端点上强制,并密切监测。\n\n关注 429 激增、限流器导致的延迟增加以及被阻止的 top 身份等指标,这些信号会告诉你阈值或维度哪里出了问题,从而避免支持洪峰。