2025年8月18日·1 分钟
软删除 vs 硬删除:实际应用中重要的权衡
软删除 vs 硬删除:了解在分析、支持、GDPR 风格删除和查询复杂性上的真实权衡,以及安全恢复模式。
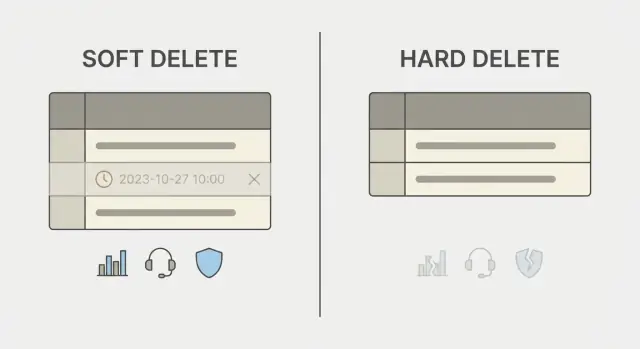
软删除和硬删除到底意味着什么
数据库里的“删除”按钮可以有两种非常不同的含义。
硬删除 会移除该行。除非你有备份、日志或副本保存了数据,否则记录就彻底没了。它容易理解,但具有不可逆性。
软删除 则保留行,但将其标记为已删除,通常用类似 deleted_at 或 is_deleted 的字段。应用随后将被标记的行视为不可见。你因此保留了关联数据、保存了历史记录,有时还能恢复该记录。
这个选择在日常工作中比人们想象的更常见。它影响你如何回答类似“上个月收入为什么下降?”,“你能找回我删除的项目吗?”,或者“我们收到 GDPR 删除请求——我们真的删除了个人数据吗?”之类的问题。它也决定了 UI 中“已删除”在用户眼中意味着什么。用户常常以为可以撤销,直到发现不能。
一个实用的经验法则:
- 当用户期望能够撤销、支持需要恢复错误操作,或你需要审计轨迹时,使用软删除。
- 当保留数据会带来法律或安全风险,或明显的存储成本而没有实际价值时,使用硬删除。
- 想要“回收站”周期时,两者结合:先软删除,然后在之后彻底清除。
举例:客户删除了一个工作区,随后发现其中包含会计需要的发票。使用软删除时,如果你的应用设计允许安全恢复,支持可以恢复它。使用硬删除时,你很可能需要解释备份、延迟或“无法实现”。
两者都没有绝对的“最佳”。最不痛苦的选项取决于你要保护的是什么:用户信任、报告准确性或隐私合规。
分析权衡:准确性 vs 保留历史
删除策略很快会在分析中体现出来。开始跟踪活跃用户、转化或收入的那一天,"已删除"就不仅是一个简单状态,而变成了一个报告决策。
如果你使用硬删除,许多指标看起来很干净,因为被移除的记录从查询中消失。但你也会丢失上下文:过去的订阅、过去的团队规模,或上个月的漏斗长什么样。一个被删除的客户会导致历史图表在重跑报告时发生变化,这对财务和增长评审来说很可怕。
如果你使用软删除,你保留了历史,但可能会不小心膨胀某些数字。一个简单的“COUNT users” 可能会包含已经离开的用户。如果在一个报告里把 deleted_at 当作流失判定而在另一个报告里忽略它,流失图表可能会重复计数。即便是收入也可能变得混乱:如果发票还在但账户被标记为已删除,归因会很难处理。
通常可行的做法是选定一种一致的报告模式并坚持:
- 在“当前状态”指标(活跃用户、当前 MRR)中过滤已删除的记录。
- 对于基于时间的仪表盘使用快照表,这样当实体后来被删除时历史不会改变。
- 将事实表与实体分离:保留不可变的事件行(支付、登录),即便隐藏了用户记录。
- 将“已删除”视为一个带有时间的生命周期状态,并明确报告(created、activated、deleted)。
- 定义保留窗口:软删除数据何时真正被移除。
关键是文档化以免分析师猜测。写清楚“活跃”是什么意思、软删除用户是否包含在内、以及如果一个账户随后被删除收入如何归因。
具体示例:某个工作区被误删后又恢复。如果你的仪表盘在计数工作区时不做过滤,你会看到一次突然的下降和随后的回升,而这在真实使用中并没有发生。使用快照可以让历史图表保持稳定,同时产品视图仍能隐藏已删除的工作区。
支持与审计轨迹:后来能恢复什么
大多数关于删除的支持工单都类似:“我误删了它”,或“我的记录去哪儿了?”你的删除策略决定支持能否在几分钟内回答,还是唯一诚实的回答是“它没了”。
用软删除,通常可以核实发生了什么并撤销。用硬删除,支持通常要依赖备份(如果有的话),那可能很慢、不完整,或对于单个项目无法实现。这就是为什么这个选择不仅仅是一个数据库细节——它决定了在出现问题时产品能有多“有帮助”。
一个简单的审计轨迹(应该保存什么)
如果你希望提供真正的支持,添加一些字段来解释删除事件:
deleted_at(时间戳)deleted_by(用户 id 或系统)delete_reason(可选,短文本)deleted_from_ip或deleted_from_device(可选)restored_at和restored_by(如果支持恢复)
即便没有完整的活动日志,这些细节也能让支持回答:谁删除了、何时发生、是误删还是自动清理。
硬删除对支持意味着什么
对于临时数据,硬删除可能没问题,但对于面向用户的记录,它改变了支持能做什么。
支持不能恢复单条记录,除非你在别处实现了回收站。他们可能需要进行完整备份恢复,这会影响其他数据。支持也不能轻易地证明发生了什么,从而导致长时间的来回沟通。
恢复功能也会改变工作量。如果用户可以在一个时限内自行恢复,工单数量会下降。如果恢复需要支持手动操作,工单可能会增加,但这些工单会变成快速且可复现的流程,而不是一次性的调查。
GDPR 风格的删除:软删除并非完全删除
“被遗忘权”通常意味着你必须停止处理某人的数据并从仍然可用的地方移除它。这并不总是意味着你必须立即擦除所有历史聚合数据,但确实意味着如果你没有合法理由保留,就不应“以防万一”保留可识别的数据。
这就是软删除与硬删除变得超越产品选择的地方。软删除(比如设置 deleted_at)通常只是把记录从应用中隐藏。数据仍在数据库中,管理员仍能查询,往往还出现在导出文件、搜索索引和分析表中。对于许多 GDPR 删除请求,这并不是抹除。
当以下情况出现时,你仍然需要清理(purge):
- 用户请求删除且你没有合理的保留理由(例如开票规则)。
- 你存储了特殊类别数据且策略要求必须移除。
- 记录出现在面向用户的导出中或可以被支持恢复。
- 第三方处理器(邮件、分析、支持工具)仍然持有数据。
备份和日志是团队常忘记的部分。你可能无法从加密备份中删除单行,但你可以设定规则:备份短期过期,并且恢复备份时必须重新应用删除事件然后系统才能上线。日志应尽量避免存储原始个人数据,并设定明确的保留期限。
一个简单可行的策略是两步删除:
- 立即软删除(以便产品行为正确,账户被禁用,并且“恢复已删除记录”可用于修复误删)。
- 启动保留计时器(例如 7 到 30 天)并调度清理任务,进行硬删除或匿名化个人字段。
- 在审计轨迹中记录所做操作,使用不可识别的标识(时间戳、原因代码),以便支持在不保留数据本身的情况下解释操作。
如果你的平台支持源码导出或数据导出,也要将导出文件视作数据存储:定义它们的存放位置、访问权限以及何时删除。
查询复杂性与产品行为:隐藏的成本
为支持发布管理员工具
创建内部界面以安全地查找、恢复和审查已删除项。
软删除听起来很简单:加一个 deleted_at(或 is_deleted)标志并隐藏该行。隐藏的成本是:现在每个读取数据的地方都需要记住这个标志。落下一次过滤,你就会遇到奇怪的 bug:总数包含了已删除项,搜索出现“幽灵”结果,或用户看到他们以为已删除的内容。
UI/UX 的边界情况很快会暴露。想象一个团队删除了名为“Roadmap”的项目,后来尝试新建一个同名项目。如果你的数据库对名称有唯一性规则,创建会失败,因为已删除的行仍然存在。搜索也会让人困惑:如果在列表中隐藏了已删除项但全局搜索未做过滤,用户会认为应用坏了。
软删除过滤常被遗漏的地方有:
- 管理仪表盘和支持工具
- 后台作业(邮件、提醒、清理)
- 分析查询与导出
- 权限检查(“这条记录存在吗?”)
- 自动完成和搜索
性能开始通常没问题,但额外的条件会增加工作量。如果大多数行都是活跃的,过滤 deleted_at IS NULL 很便宜。但如果很多行都被删除,数据库在没有合适索引的情况下要跳过更多行。通俗地说:这就像在一个抽屉里寻找当前文件,而抽屉里也放了很多旧文件。
把已删除项目放到一个单独的“归档”区域可以减少混淆。默认视图只显示活跃记录,把已删除项放在带有明确标签和时间窗口的地方。在快速开发的工具里(例如在 Koder.ai 上制作的内部应用),这一产品决策往往比任何巧妙的查询技巧更能减少支持工单。
软删除的常见数据模型
软删除不是一个功能,而是一个数据模型选择。你选择的模型会影响后续的一切:查询规则、恢复行为,以及“已删除”对产品的含义。
模型 1:deleted_at 加 deleted_by
最常见的模式是可空时间戳。删除记录时设置 deleted_at(通常也会设置 deleted_by 为用户 id)。“活跃”记录是 deleted_at 为 null 的那些。
当你需要简单恢复时,这种方式工作良好:恢复就是清空 deleted_at 和 deleted_by。它也为支持提供了简单的审计信号。
模型 2:显式状态字段
有些团队用 status 字段定义明确状态,例如 active、archived、deleted。当“归档”是一个真实的产品状态(对大多数界面隐藏但仍计入计费)时,这很有用。
代价是规则更多。你必须定义每个状态在搜索、通知、导出和分析中的含义。
模型 3:对高价值记录使用分离存储
对于敏感或高价值对象,你可以将已删除行移到单独表,或在追加日志中记录事件。
- 时间戳软删除:
deleted_at、deleted_by - 状态机:带命名状态的
status - 单独的已删除表:保持“活跃”表小而干净
- 事件日志:保留“谁做了什么”,而不是永远保存完整行
当恢复必须严格受控,或想要审计轨迹但不想把已删除数据混入日常查询时,这种做法常被采用。
子记录也需要明确规则。如果一个工作区被删除,项目、文件和成员关系怎么办?
- 级联:也将子项标记为已删除
- 限制:在处理子项前阻止删除
- 归档:将子项转换为
archived(不是 deleted) - 分离:移除关系但保留子项
每种关系选择一条规则,写下来并保持一致。大多数“恢复出错”的 bug 都来自父子记录对“已删除”的含义不一致。
如何实现安全的恢复功能(逐步)
恢复按钮听起来简单,但它可能悄悄破坏权限、将旧数据恢复到错误位置,或在“恢复”不符合用户预期时造成混淆。先写清楚你的产品对恢复的确切承诺。
一个实用的恢复流程
用一套小而严格的步骤让恢复可预测且可审计。
- 定义“恢复”意味着什么。 记录会保留原 ID 吗?它会回到原父级(工作区、项目)并保留关系吗?决定成员、角色和可见性的处理规则。
- 让用户确认并捕获原因。 展示将被恢复的内容(名称、所有者、最后修改时间)并要求明确确认。对支持团队来说,一句简短的原因(“误删”、“解决工单”)通常足够。
- 在更改前检查冲突。 常见问题:旧名称已被复用、用户不再有权限、或相关记录已被硬删除。选择规则:阻止恢复并给出明确信息,或恢复到需要审核的安全状态。
- 记录恢复操作。 记录谁恢复、何时恢复、从何处(UI、API)以及发生了哪些变化。这有助于审计和支持,且在有人问“它为什么回来?”时至关重要。
- 在合适的情况下添加时限。 许多应用允许在 30 或 90 天内恢复,然后需要不同的恢复流程或将其视为永久删除。
如果你在像 Koder.ai 这样的聊天驱动工具中快速构建应用,将这些检查纳入生成的工作流,以便每个界面和端点遵循相同规则。
常见错误与陷阱(需避免)
保持分析一致性
创建快照仪表盘,确保记录删除时图表保持稳定。
软删除最大的问题不是删除本身,而是所有忘记记录已“消失”的地方。很多团队选择软删除以求安全,随后却在搜索结果、徽章或总数中意外显示已删除项。用户会很快注意到,例如仪表盘显示“12 个项目”却只看到 11 个。
其次是访问控制问题。如果用户、团队或工作区被软删除,他们不应能登录、调用 API 或接收通知。这常在登录检查只按邮箱查找行但未检查删除标志时被遗漏。
后续会造成支持工单的常见陷阱包括:
- 在某条读取路径中缺少已删除过滤(管理视图、导出、搜索、后台作业)。
- 恢复时与唯一字段冲突(邮箱、用户名、slug、发票号)。
- 删除父级但让子级保持“活跃”(或删除子级而父级仍然存在)。
- 在分析、配额或计费计算中计入已删除行。
- 因为集成和同步任务不理解“已删除”,将删除数据发送给第三方。
唯一性冲突在恢复时尤其棘手。如果有人在旧账户软删除期间用相同邮箱创建了新账户,恢复要么失败,要么覆盖错误的身份。提前决定规则:在清除前阻止复用、允许复用但禁止恢复,或以新标识恢复。
一个常见场景:支持人员恢复了一个软删除的工作区。工作区回来了,但其成员仍被删除,并且一个集成开始把旧记录同步到合作方工具。从用户角度看,恢复“只恢复了一半”,反而制造了新问题。
在发布恢复功能前明确以下行为:
- “已删除”对登录、API 访问、通知意味着什么
- 恢复如何处理唯一字段和所有权
- 相关记录如何随父级移动(全部随动比半成更好)
- 导出和集成如何处理已删除数据(排除、标记或发送墓碑)
现实示例:工作区被误删
一个 B2B SaaS 团队有个“删除工作区”按钮。某个周五,一个管理员清理时移除了 40 个看起来不活跃的工作区。周一,三位客户抱怨他们的项目不见了并要求立即恢复。
团队原以为事情会很简单,结果并非如此。
第一个问题:如果工作区行被硬删除并级联删除了项目、文件和成员,支持无法恢复单个项。唯一选项是备份恢复,那意味着时间、风险以及向客户给出尴尬答复。
第二个问题:分析看起来出问题了。仪表盘通过查询 deleted_at IS NULL 来统计“活跃工作区”。误删导致图表出现突然下降。更糟的是,周报将其与上周比较并标记为虚假的流失激增。数据并没真正丢失,但在查询中被错误排除了。
第三个问题:其中一个受影响用户提出了隐私请求。纯粹的软删除不能满足这个要求。团队需要有计划去清理个人字段(姓名、邮箱、IP 日志)同时保留非个人的聚合数据如账单总额和发票编号。
第四个问题:大家都在问“谁点了删除?”如果没有记录,支持无法解释发生了什么。
更安全的模式是把删除当作带有清晰元数据的事件:
- 将工作区标记为已删除(并在产品中隐藏)
- 记录
deleted_by、deleted_at和原因或工单 id - 记录将受影响的内容(项目数量、席位、存储)
- 在可恢复时间窗口内允许恢复,然后按需清理特定的个人字段
这类工作流是团队在像 Koder.ai 平台上快速搭建时常见的,之后他们会意识到删除策略需要与功能同等重视。
快速检查表:如何选择正确的删除策略
测试删除边界情况
在确定模式前尝试撤销窗口和唯一字段冲突。
在软删除与硬删除之间做选择,更多是关于你的应用在记录“消失”后必须保证什么,而不是偏好。启动前问自己这些问题:
- 你是否需要真正的抹除? 如果必须满足隐私或法律请求,连同备份、导出和缓存一起规划真正的删除。单纯的软删除标志不足以满足“完全移除”。
- 你是否需要恢复按钮,以及恢复时限多久? 如果“撤销”很关键,决定恢复窗口(7 天、30 天、永久)以及到期后如何处理。
- 删除后报告还需要历史数据吗? 有些团队希望图表反映用户今天在看到的内容;另一些则需要历史计数以供财务或增长分析。你的删除选择会改变“活跃用户”和“总收入”的含义。
- 支持能否在不做大量侦查的情况下解释发生了什么? 如果会收到“我的项目不见了”之类的工单,你需要清晰的轨迹:谁在何时何地删除了它,以及足够的信息进行调查。
- 你的团队能否在各处保持一致行为? 软删除常会带来隐藏规则:每个查询都必须过滤已删除记录、每个连接都必须一致、每个界面都必须就“已删除”达成共识。
一个简单的验算方式是挑选一个现实的事故并模拟整个过程。例如:某人在周五晚上误删了一个工作区,周一支持需要查看删除事件、安全恢复并避免恢复不该回来的相关数据。如果你在像 Koder.ai 这样的平台注册应用,早期就定义这些规则能让生成的后端和 UI 遵循统一策略,而不是在代码中到处撒特殊情况。
下一步:选择策略并安全构建
通过写下一份简单的策略与团队和支持共享来确定你的做法。如果没有书面说明,策略会逐步偏离,用户会感到不一致。
先从一套明晰规则开始:
- 哪些对象会被软删除(以及可以恢复多久)
- 哪些对象会立即硬删除(以及原因)
- 软删除数据何时被清理(例如 X 天后)
- 谁可以恢复以及需提供何种证明或审批
- 隐私驱动的删除请求如何端到端处理
然后构建两条互不混淆的路径:一个用于管理员恢复以应对误删,另一个用于隐私清除以实现真正删除。恢复路径应可逆且有日志,清理路径应是不可逆的并移除或匿名化所有可识别个人的数据(如果策略要求,也包括备份或导出的文件)。
加入护栏以防删除数据重新泄露回产品。最简单的方式是把“已删除”视为测试的一等状态。在每个新查询、列表页、搜索、导出和分析作业中加入审查点。一个好的规则是:如果一个界面显示面向用户的数据,它必须对已删除记录有明确决策(隐藏、带标签显示或仅管理员可见)。
如果你还处于产品早期,先把两种流程都做成原型再确定最终模式。在 Koder.ai,你可以在规划模式下勾画删除策略,生成基本 CRUD,然后快速尝试恢复和清理场景,并在提交前调整数据模型。