2025年8月31日·1 分钟
使用扩展/收缩模式实现零停机的架构变更
学习如何使用扩展/收缩模式实现零停机的架构变更:安全添加列、分批回填、部署兼容代码,然后移除旧路径。
学习如何使用扩展/收缩模式实现零停机的架构变更:安全添加列、分批回填、部署兼容代码,然后移除旧路径。
数据库变更导致的中断并不总是明显的停机。对用户来说,可能表现为页面长时间加载、结账失败,或应用突然显示“出了点问题”。对团队来说,会看到告警、错误率上升以及需要清理的大量失败写入。
架构变更之所以危险,是因为数据库被所有运行中的应用版本共享。在发布期间,通常会同时存在旧代码和新代码(滚动部署、多实例、后台任务)。即使迁移语句本身没问题,也可能破坏某些仍在运行的版本。
常见的失败场景包括:
即便代码本身没有问题,发布也会被阻塞,因为真正的问题是不同版本间的时序和兼容性。
零停机的架构变更归结为一条规则:每一个中间状态都必须对旧代码与新代码都安全。你要在不破坏现有读写的情况下更改数据库,发布能同时兼容两种数据形态的代码,只有在确认没有依赖后才移除旧路径。
当你有真实流量、严格的 SLA、或大量应用实例与工作器时,这些额外的工作是值得的。对于流量微小的内部工具,计划内的维护窗口可能更简单。
大多数因数据库工作导致的事故,都是因为应用期望数据库瞬间改变,而数据库的变更需要时间。扩展/收缩模式通过把一个风险大的变更拆成更小、更安全的步骤来避免这类问题。
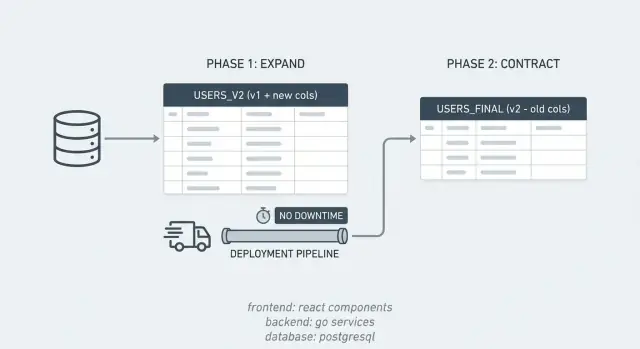
在短时间内,系统同时支持两种“方言”。你先引入新结构,保持旧结构可用,将数据逐步迁移,然后再清理旧结构。
该模式很简单:
这与滚动部署非常契合。如果你逐台更新 10 台服务器,旧版本与新版本会短时间并存。扩展/收缩确保这段重叠期内两者都能与同一数据库兼容。
它也让回滚不那么可怕。如果新发布有 bug,你可以回滚应用而不回滚数据库,因为在扩展窗口内旧结构仍然存在。
举例:你想把 PostgreSQL 列 full_name 拆成 first_name 和 last_name。先添加新列(扩展),发布能读写两种形式的代码,批量回填旧行,确认无依赖后再删除 full_name(收缩)。
扩展阶段是关于添加新选项,而不是移除旧的依赖。
常见的第一步是新增列。在 PostgreSQL 中,最安全的做法通常是将新列设为可空且无默认值。添加带默认值且非空的列可能触发表重写或更重的锁,具体行为依赖于 Postgres 版本与变更细节。一种更安全的顺序是:先添加可空列,部署能容忍的代码,回填,然后再强制 NOT NULL。
索引也需要谨慎。普通索引的创建可能会比预期阻塞写入。能用并发(concurrent)创建索引时尽量使用它,虽然耗时更长,但能避免阻塞发布。
扩展也可能意味着添加新表。如果你要从单列迁移到多对多关系,可以先添加中间表,同时保留旧列。旧路径继续工作,新结构开始收集数据。
实践中,扩展常包括:
扩展完成后,旧版与新版应用应能同时运行而不会出现意外。
大部分发布痛点出现在中间阶段:有的服务器运行新代码,有的服务器仍然运行旧代码,而数据库已经开始改变。目标很直接:在任何滚动部署的瞬间,运行中的任意版本都应能兼容旧结构与扩展后的结构。
常见做法是双写(dual-write)。如果新增了一个列,新版本同时写入旧列和新列。旧版本仍只写旧列,没问题因为它还存在。最初将新列设为可选,并把严格约束推迟到所有写入者都升级之后。
读取比写入通常切换得更谨慎。暂时优先保留旧列的读取(你知道它已经被填满)。在回填并验证后,再切换为优先读取新列,但对缺失值回退到旧列。
同时保持 API 输出稳定,即便引入了新的内部字段,避免在消费者(网页、移动端、集成方)还没准备好时改变响应格式。
一个支持回滚的典型发布顺序:
关键思想是:第一个不可逆的步骤是删除旧结构,所以把它放在最后。
回填是很多“零停机迁移”失败的地方。你要在不产生长锁、慢查询或意外负载峰值的前提下,为已有行填充新列。
分批很重要。目标是每批尽快完成(以秒计而非分钟)。如果每批都很小,你可以暂停、恢复并调优任务,而不阻塞发布。
要跟踪进度,请使用稳定的游标。在 PostgreSQL 中,通常用主键。按顺序处理行并保存上次完成的 id,或按 id 范围工作。这样当任务重启时避免昂贵的全表扫描。
这里是一个简单的模式:
UPDATE my_table
SET new_col = ...
WHERE new_col IS NULL
AND id > $last_id
ORDER BY id
LIMIT 1000;
使更新带条件(例如 WHERE new_col IS NULL)以保证任务的幂等性。重试只会触及仍需处理的行,减少不必要的写入。
要考虑到回填期间会有新数据写入。一般顺序是:
一个好的回填应该是枯燥的:稳定、可测量,并且在数据库负载升高时容易暂停。
最危险的时刻不是添加新列,而是你决定可以依赖它的时候。
在进入收缩阶段前,证明两件事:新数据是完整的,并且生产环境真的在安全地读取它。
先从一些快速且可重复的完整性检查开始:
如果你在双写,增加一致性检查以捕捉无声的 bug。例如每小时运行一个查询,查找 old_value <> new_value 的行并在非零时报警。这通常能迅速发现仍在只写旧列的某个写入者。
在迁移运行期间关注基本的生产信号。如果查询时间或锁等待飙升,哪怕是你的“安全”校验查询也可能在增加负载。部署后特别监控那些读取新列的代码路径的错误率。
应该同时保留两条路径多长时间?至少要能度过一次完整的发布周期和一次回填重跑。很多团队选择 1–2 周,直到确认没有旧应用版本在运行。
收缩阶段让团队紧张是正常的,因为它感觉像不可回头。如果扩展做得对,收缩大多是清理工作,而且仍可以分成小、低风险的步骤完成。
慎重选择时机。不要在回填刚结束就立即删除内容。至少再等一个完整发布周期,让延迟的任务与边缘情况充分暴露。
一个安全的收缩顺序通常是:
如果可以,将收缩拆成两个发布:一个移除代码引用(并加额外日志),之后再做删除数据库对象的发布。这样的分离能让回滚和排查更容易。
PostgreSQL 的细节在这里很重要。删除列大多是元数据变更,但仍会短暂地获得 ACCESS EXCLUSIVE 锁。为此安排一个尽量安静的时间并让迁移尽可能快。如果你额外创建了索引,优先使用 DROP INDEX CONCURRENTLY 来避免阻塞写入(注意它不能在事务块内运行,所以你的迁移工具需支持该操作)。
零停机迁移在数据库与应用对“可接受”状态达不成一致时会失败。该模式只有在每个中间状态对旧代码与新代码都安全时才有效。
这些错误很常见:
一个现实场景:你从 API 写入 full_name,但有个后台任务仍只设置 first_name 和 last_name。它在夜间插入了 full_name = NULL 的行,之后的代码就假设 full_name 始终存在,导致故障。
把每一步当作可能会运行数天的发布来看待:
一个可重复使用的清单能避免你发布只在某一数据库状态下工作的代码。
在部署前,确认数据库已经有扩展所需的结构(新增列/表、以低锁方式创建的索引)。然后确认应用是容错的:它应能在旧形态、扩展形态和半回填状态下工作。
将清单保持简短:
当读取使用新数据、写入不再维护旧数据,并且你至少用一次简单检查(计数或抽样)验证了回填,迁移才算完成。
假设你有一个 PostgreSQL 表 customers,列 phone 存储格式杂乱的数据(不同格式、偶有空值)。你想用 phone_e164 取代它,但不能阻塞发布或让应用下线。
一个清晰的扩展/收缩序列如下:
phone_e164,设置为可空、无默认且暂不加严格约束。phone 与 phone_e164,但读取仍以 phone 为主,用户不会感觉到变化。phone_e164。phone_e164,如果为 NULL 再回退到 phone。phone_e164 后,移除回退、删除 phone,再根据需要加上严格约束。当每一步都向后兼容时,回滚就很简单。如果读取切换导致问题,回滚应用即可;数据库中两列仍在。如果回填导致负载峰值,可暂停任务、减小批量后继续。
若要让团队保持一致,把计划记录在一个地方:精确的 SQL、哪个发布翻转读取、如何衡量完成(比如 phone_e164 非 NULL 的百分比)、以及每一步由谁负责。
当扩展/收缩成为常规操作时效果最好。为团队写一份简短的运行手册,供每次架构变更复用,最好一页纸能让新人也能按步骤操作。
一个实用的模板应包含:
提前确定责任人。"大家都以为别人会做收缩",这是旧列和特性开关被保留数月的常见原因。
即便回填在线执行,也尽量在流量较低时安排,这样更容易保持小批量、观察数据库负载,并在延迟上升时快速停止。
如果你使用 Koder.ai (koder.ai) 进行构建和部署,Planning Mode 可以帮助你在触及生产之前把各阶段和检查点都列清楚。兼容性规则依然适用,但把步骤写下来能减少遗漏那些防止中断的“无聊”步骤。
因为数据库同时被所有运行中的应用版本共享。在滚动部署和后台任务并存的情况下,旧版本和新版本的代码会同时访问数据库;任何对名称、列或约束的更改,都可能会让没有为该中间状态准备的版本出错。
这意味着你设计迁移时,确保每个中间数据库状态对新旧代码都是可用的。先添加新结构,在一段时间内同时支持新旧路径,确认没有依赖后再移除旧结构。
扩展阶段是在不移除现有依赖的前提下添加新列、表或索引。收缩阶段则是在确认新路径完全可用后,清理旧的列、旧的读写路径以及临时的同步逻辑。
通常先以可空且无默认值的列开始,这样可以避免大规模表重写或锁定。随后部署可以容忍该列缺失或为 NULL 的代码,逐步回填,最后再收紧为 NOT NULL 等约束。
当迁移过程中需要兼容旧实例时,新版本在迁移期可以同时向旧字段和新字段写入(双写)。这样即使还有旧实例存在,数据也能保持一致。
把历史行分成小批次,确保每一批能在短时间内完成(秒级而非分钟级)。使每批可幂等,例如只更新 WHERE new_col IS NULL 的行。监控查询时间、锁等待和复制滞后,必要时暂停或减小批量。
先检查完整性:统计新列的 NULL 数量、比较应填行数与已填行数、抽样比对新旧值、测试边界情况(空字符串、0、非常旧的记录)。如果双写,建立一致性检查(例如定期发现 old_value <> new_value 的行并报警)。同时监控部署后的错误率和性能指标。
常见错误包括过早设置 NOT NULL、一次性在大事务中回填导致锁和膨胀、假设默认值是“免费”的(在某些 PostgreSQL 版本会触发表重写)、以及在写入尚未可靠填充的新列时就切换读取。别忘了审计所有写入与读取该表的地方(定时任务、工作器、导出、报表查询)。
在确认不再写入旧字段、切换读取以去掉回退路径并等待足够时间以确定没有旧应用实例后再执行删除操作。许多团队把这一步当作一次独立发布以便回滚更安全。
如果可以接受维护窗且流量很小,直接一次性迁移可能更简单。但如果你有真实用户、大量实例、后台工作或 SLA,采用扩展/收缩步骤通常更值得,它能让回滚与发布更安全。在 Koder.ai 的 Planning Mode 中把各阶段和检查点写清楚,能防止跳过那些看似“无聊”但关键的步骤。