2025年12月31日·1 分钟
关联 ID 端到端:在日志中追踪用户操作
关联 ID 端到端示例:在前端生成 ID、通过 API 传递,并把它写入日志,以便支持人员能快速追踪问题。
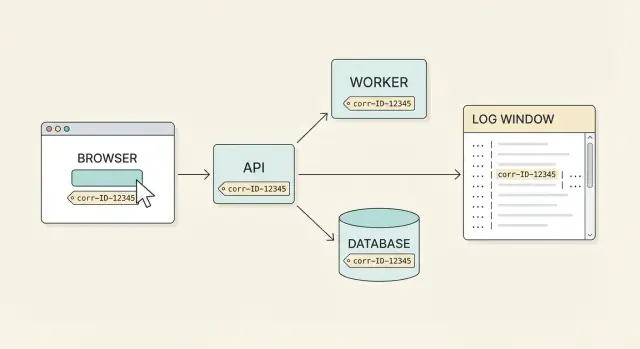
关联 ID 端到端示例:在前端生成 ID、通过 API 传递,并把它写入日志,以便支持人员能快速追踪问题。
支持团队几乎不会收到一份干净的错误报告。用户可能说“我点了付款,但失败了”,但这一次点击可能涉及浏览器、API 网关、支付服务、数据库和后台作业。每个环节在不同时间、不同机器上记录各自的日志。如果没有一个共享的标签,你就不得不猜测哪些日志行属于同一次操作。
关联 ID 就是这个共享的标签。它是附着在一次用户操作(或一次逻辑工作流)上的一个 ID,并在每个请求、重试和服务跳转中携带。真正的端到端覆盖意味着你可以从用户投诉开始,拉出跨系统的完整时间线。
人们经常把几种相似的 ID 混在一起。下面是清晰的区分:
理想的情况很简单:用户报告问题时,你让他们把 UI 上(或支持界面里)显示的关联 ID 复制给你,团队中的任何人都能在几分钟内找到完整的事件流程。你能看到前端请求、API 响应、后端步骤和数据库结果,所有这些都被同一个 ID 串联起来。
在开始生成之前,先统一一些规则。如果每个团队都选不同的头名或日志字段,支持仍然要猜测。
先确定一个规范名称并在所有地方使用。常见做法是在 HTTP 头里使用 X-Correlation-Id,同时在结构化日志字段中使用 correlation_id。选定一种拼写和大小写,写入文档,并确认你的反向代理或网关不会重命名或丢弃该头。
选择一种既容易生成又适合在工单和聊天中分享的格式。UUID 很实用,因为它唯一且平凡。保持 ID 足够短以便复制,但不要太短以致于发生冲突。一致性比聪明更重要。
同时决定 ID 必须出现的位置以便人类能实际使用它。通常意味着它应出现在请求、日志和错误输出中,并且在团队使用的搜索工具中可搜索到。
定义一个 ID 的生命周期长度。一个合理的默认是对应一次用户操作,比如“点击付款”或“保存配置”。对于跨服务和队列的更长工作流,在工作流结束前保持同一个 ID,然后在下一个操作开始时生成新的。避免“整次会话用一个 ID”,因为搜索会很快变得嘈杂。
一条硬性规则:不要在 ID 中放入个人数据。不要包含邮箱、电话号码、用户 ID 或订单号。如果需要这些上下文,把它们记录在带有适当隐私控制的独立字段中。
最容易开始的位置是在用户开始你关心的操作那一刻:点击“保存”、提交表单或触发会产生多个请求的流程。如果等后端来创建,通常会丢失故事的第一部分(UI 错误、重试、取消请求)。
使用随机且唯一的格式。UUID v4 是常见选择,现代浏览器易于生成且几乎不会冲突。保持 ID 不可读(不要包含用户名、邮箱或时间戳),以免在头和日志中泄露个人数据。
把“工作流”视为可能触发多个请求的一次用户操作:验证、上传、创建记录,然后刷新列表。在工作流开始时创建一个 ID,并在工作流结束(成功、失败或用户取消)前一直保留它。一个简单的模式是把它存储在组件状态或轻量级的请求上下文对象中。
如果用户重复开始同一操作,应为第二次尝试生成新的关联 ID。这样支持能区分“相同点击的重试”和“两次独立提交”。
把 ID 加到工作流触发的每个 API 调用中,通常通过像 X-Correlation-ID 这样的头来传递。如果你使用共享的 API 客户端(fetch 封装、Axios 实例等),只需在一次传入 ID,让客户端注入到所有调用里。
// 1) when the user action starts
const correlationId = crypto.randomUUID(); // UUID v4 in modern browsers
// 2) pass it to every request in this workflow
await api.post('/orders', payload, {
headers: { 'X-Correlation-ID': correlationId }
});
await api.get('/orders/summary', {
headers: { 'X-Correlation-ID': correlationId }
});
如果你的 UI 发出与该操作无关的后台请求(轮询、统计、自动刷新),不要重用工作流 ID。让关联 ID 聚焦在单一故事上。
一旦你在浏览器生成了关联 ID,任务很简单:每次请求都要把它带出前端,并在每个 API 边界保持不变。这是团队添加新端点、新客户端或中间件时最常出问题的环节。
最稳妥的默认是把它作为每次调用的 HTTP 头(例如 X-Correlation-Id)。头易于在一个地方添加(fetch 封装、Axios 拦截器、移动端网络层),也不需要修改请求体。
如果有跨域请求,确保你的 API 允许该头,否则浏览器可能会静默地阻止它,让你误以为已经发送。
如果必须把 ID 放在查询字符串或请求体中(某些第三方工具或文件上传会强制这样做),保持一致并写入文档。为字段选一个名字并在所有地方使用。不要在不同端点间混用 correlationId、requestId 和 cid。
重试是另一个常见陷阱。如果是同一次用户操作的重试,应保留相同的关联 ID。例如用户点击“保存”,网络中断,客户端重试 POST。支持应该看到一条连接的轨迹,而不是三条不相关的记录。新的用户点击(或新的后台作业)应使用新 ID。
对于 WebSockets,应在消息信封中包括 ID,而不仅仅在初始握手中。一次连接可能承载许多用户操作。
一个快速的可靠性检查:保持简单。
correlationId 字段。你的 API 边缘(网关、负载均衡器或第一个接收流量的服务)会决定关联 ID 是可靠还是混乱。在入口点把 ID 当成事实来源。
如果客户端发送了 ID 就接受,但不要假设它总是存在。如果缺失,则立即生成一个新的,并在当前请求的剩余处理过程中使用它。这样即便某些客户端较旧或配置错误,功能也能正常工作。
做一些轻量校验,避免坏值污染日志。保持宽松:检查长度和允许字符,但避免过于严格以致拒绝真实流量。例如允许 16–64 个字符和字母、数字、短横线、下划线。如果值不通过校验,就用新的 ID 替换并继续处理。
让调用方能看到 ID。务必在响应头中返回它,并在错误体中包含它。这样用户就能从 UI 复制,支持人员也能请求并找到精确的日志轨迹。
实际的边缘策略示例如下:
X-Correlation-ID(或你选的头)。X-Correlation-ID。示例错误负载(支持人员在工单或截图中应看到的):
{
"error": {
"code": "PAYMENT_FAILED",
"message": "We could not confirm the payment.",
"correlation_id": "c3a8f2d1-9b24-4c61-8c4a-2a7c1b9c2f61"
}
}
请求进入后端后,把关联 ID 当成请求上下文的一部分,而不是存放在全局变量里。全局变量在同时处理两个请求时会崩溃,或者在响应后仍有异步工作时失效。
一个可扩展的规则:每个可能记录日志或调用其他服务的函数都应接收包含 ID 的上下文。在 Go 服务中,这通常意味着将 context.Context 在处理器、业务逻辑和客户端代码间传递下去。
当服务 A 调用服务 B 时,把相同的 ID 拷贝到出站请求中。不要在中途生成新 ID,除非你也把原始 ID 作为单独字段保留(例如 parent_correlation_id)。如果改变了 ID,支持人员就会丢失将事件串联起来的主线索。
传播常被遗漏的场景包括:请求期间触发的后台任务、客户端库内部的重试、随后触发的 webhook 以及扇出调用。任何异步消息(队列/任务)都应携带该 ID,任何重试逻辑都应保留它。
日志应使用稳定的字段名,比如 correlation_id。选定一种拼写并在所有地方保持一致。避免混用 requestId、req_id 和 traceId,除非你也定义了清晰的映射关系。
如果可能,也把 ID 包含到数据库可见性中。一个实用方法是把它加到查询注释或会话元数据中,这样慢查询日志也能显示它。当有人报告“保存按钮卡了 10 秒”,支持可以搜索 correlation_id=abc123 并看到 API 日志、下游服务调用以及引起延迟的慢 SQL 语句。
关联 ID 只有在能被人找到并跟踪时才有用。把它作为一等日志字段(而不是埋在消息字符串里),并在各服务间保持日志条目格式一致。
把关联 ID 与一小组字段配对,以回答:什么时候、在哪里、什么和谁(以不泄露用户隐私的方式)。对大多数团队来说,这些字段包括:
timestamp(含时区)service 和 env(api、worker、prod、staging)route(或操作名)和 methodstatus 和 duration_msaccount_id 或哈希过的用户 id,而不是邮箱)有了这些,支持可以按 ID 搜索,确认看到的是正确的请求,并知道是哪个服务处理了它。
每个请求记录几条关键的面包屑,而不是完整的转录。
rows=12)。为避免日志噪声,默认把详细调试信息关掉,只把那些能帮助判断“哪里失败了”的事件放到 info 级别。如果一行日志不能帮助定位问题或衡量影响,通常不应放在 info 级别。
脱敏和结构同样重要。不要在关联 ID 或日志中放入 PII:不要包含邮箱、姓名、电话号码、完整地址或原始令牌。如果需要识别用户,记录内部 ID 或单向哈希。
用户反馈支持:“结账时我点了付款,失败了。” 最好的后续问题很简单:“你能把错误界面上显示的关联 ID 粘贴过来吗?” 他们回复 cid=9f3c2b1f6a7a4c2f。
支持现在有了一个把 UI、API 和数据库工作串起来的把柄。目标是该操作的每条日志都带有相同的 ID。
支持在日志中搜索 9f3c2b1f6a7a4c2f,会看到流程:
frontend INFO cid=9f3c2b1f6a7a4c2f event="checkout_submit" cart=3 items
api INFO cid=9f3c2b1f6a7a4c2f method=POST path=/api/checkout user=1842
api ERROR cid=9f3c2b1f6a7a4c2f msg="payment failed" provider=stripe status=502
接着工程师跟着相同的 ID 进入下一个跳点。关键是后端服务调用(以及任何队列作业)也要转发该 ID:
payments INFO cid=9f3c2b1f6a7a4c2f action="charge" amount=49.00 currency=USD
payments ERROR cid=9f3c2b1f6a7a4c2f err="timeout" upstream=stripe timeout_ms=3000
db INFO cid=9f3c2b1f6a7a4c2f query="insert into failed_payments" rows=1
现在问题很明确:支付服务在 3 秒后超时,并写入了失败记录。工程师可以检查最近的部署,确认超时设置是否改变,或者是否存在重试行为。
为闭环执行四项检查:
让关联 ID 失效最快的方式就是把链路断掉。大多数失败源自看似无害的小决定,开发时感觉没问题,但当支持需要答案时却造成麻烦。
一个经典错误是在每个跳点生成新 ID。如果浏览器发送了 ID,API 网关应保留它而不是替换它。如果确实需要内部 ID(比如队列消息或后台任务),也要把原始 ID 作为 parent 字段保留,以便故事仍能串联。
另一个常见缺口是日志记录不完整。团队在第一个 API 添加了 ID,但忘记在 worker 进程、定时任务或数据库访问层记录它。结果是死路:你能看到请求进入系统,但看不到它接下来去了哪里。
即便 ID 在每处都有,也可能因为每个服务用不同字段名或格式而难以搜索。选一个名字并在前端、API 和日志中坚持使用(例如 correlation_id)。还要选一个格式(通常是 UUID),并把它当成区分大小写处理以便复制粘贴时不出错。
不要在出错时丢失 ID。如果 API 返回 500 或验证错误,务必在错误响应中包含关联 ID(最好也在响应头中回显)。这样用户可以把它粘贴到支持聊天里,团队就能立刻追踪完整路径。
一个快速测试:支持人员能否从一个 ID 开始,沿着涉及的每条日志行一直追到最后,包括失败?如果能,说明体系运作良好。
在你告诉支持“直接搜索日志”之前,用这个做一次常规检查。只有当每个跳点都遵循相同规则时,这套方法才有效。
correlation_id。选取能使链路不间断的最小改动。
correlation_id,如果需要更多细节再增加 span_id。一个能发现缺口的快速测试:打开开发者工具,触发一次操作,从第一个请求复制关联 ID,然后确认每个相关 API 请求和每条对应的日志行都包含相同的值。
关联 ID 只有在每次都以相同方式使用时才有价值。把关联 ID 的行为当作必须完成的交付项,而不是可有可无的日志小改动。
为任何新端点或 UI 操作在定义完成标准时加入一项可追溯性检查。覆盖内容包括 ID 如何创建(或复用),在流程中如何存放,哪个头传递它,以及当头缺失时每个服务如何处理。
一个轻量级的检查清单通常就足够:
correlation_id)。支持团队也需要一个简单脚本以便快速可复现地排查问题。决定在用户界面哪儿展示 ID(例如错误对话框里的“复制调试 ID”按钮),并写清支持应如何索取 ID 以及去哪里搜索。
在生产环境依赖它之前,运行一次与真实使用相匹配的分阶段流程:点击按钮、触发验证错误、然后完成操作。确认你可以从浏览器请求一直跟到 API 日志、任何后台 worker,甚至记录了数据库调用日志的地方。
如果你在 Koder.ai 上构建应用,建议把关联 ID 的头和日志约定写进 Planning Mode,这样生成的 React 前端和 Go 服务默认就保持一致。
关联 ID 是一个共享标识,用来标记与某个用户操作或工作流相关的所有内容——包括浏览器、API、服务和后台任务。它让支持人员从一个 ID 开始,就能拉出完整的时间线,而不用猜哪几行日志属于同一次操作。
当你想要快速端到端排查某一次具体事件时(例如“点击付款失败”),就使用关联 ID。会话 ID 太宽泛,覆盖多个操作;请求 ID 太狭窄,只对应单个 HTTP 请求并且在重试时会改变。
推荐在前端用户动作开始时生成关联 ID(例如表单提交、按钮点击、多步流程开始),这样可以保留最早的操作信息,包括 UI 错误、重试或取消请求的情况。
使用类似 UUID 的不透明值,既易于复制又安全地在支持票据中共享。不要在 ID 中编码个人数据、用户名、邮箱、订单号或时间戳;这些上下文信息应记录在单独的日志字段并做相应的隐私保护。
选择一个规范的头名并在全局使用,例如 X-Correlation-ID,并在日志中使用统一的结构化字段名,比如 correlation_id。一致性比具体名称更重要,因为支持人员需要一个可预测的检索项。
如果是同一次用户动作的重试,应该复用同一个关联 ID,这样日志会连成一条完整轨迹。只有当用户发起新的独立尝试(例如稍后再次点击)时,才生成新的关联 ID。
API 边缘应该在收到请求时接受客户端发送的 ID;如果缺失或明显不合法,则立即生成一个新的 ID,并在后续请求处理期间使用它。生成或回显的 ID 应在响应头和错误体中返回,方便用户或支持复制。
把关联 ID 放到请求上下文中,并在发起对下游服务的调用时一并复制过去,包括内部 HTTP/gRPC 请求和队列作业。避免在中途随意创建新的关联 ID;如果需要更细粒度,可增加单独的内部标识而不破坏原始链路。
把它作为结构化字段写入日志,而不是埋在消息字符串里,这样可以搜索和过滤。配合一些实用字段(例如服务名、路由、状态、耗时和用户安全标识),并确保失败也记录该 ID,否则关键时刻链路会断开。
一个快速方法是触发一次操作,从第一个请求或错误界面复制关联 ID,然后确认每个相关请求头和处理该工作流的每条服务日志都包含相同的值。如果 ID 在 worker、重试或错误响应中消失,那就是优先需修复的缺口。