2025年6月05日·2 分钟
如何构建用于监控客户采纳健康评分的 Web 应用
学习如何构建一个跟踪产品使用、计算采纳健康评分并告警团队风险的 Web 应用——包括仪表盘、数据建模与实用建议。
学习如何构建一个跟踪产品使用、计算采纳健康评分并告警团队风险的 Web 应用——包括仪表盘、数据建模与实用建议。
在构建客户采纳健康评分之前,先决定你希望该评分为业务“做”什么。用于触发流失风险告警的评分,与用于指导入职、客户教育或产品改进的评分会有所不同。
采纳不只是“最近登录”。把真正表明客户获得价值的少数行为写下来:
这些将成为你最初的采纳信号,用于功能使用分析和后续的队列分析。
明确说明分数变化时会发生什么:
如果你无法指出一个决策,就不要急着追踪该指标。
澄清谁会使用客户成功仪表盘:
选择标准窗口——最近 7/30/90 天——并考虑生命周期阶段(试用、入职、稳态、续约)。这能避免把新账户和成熟账户直接比较。
为你的健康评分模型定义“完成”的标准:
这些目标将影响下游一切:事件跟踪、计分逻辑以及围绕评分构建的工作流。
选择指标时,健康评分会成为有用信号或嘈杂数字。目标是少而精的指标,反映真正的采纳,而不仅仅是活动量。
选择能表明用户反复获取价值的指标:
保持指标列表集中。如果无法在一句话内解释某指标为何重要,它可能不是核心输入。
采纳应结合上下文来解释。3 人团队的行为会与 500 人的大规模部署不同。
常见的上下文信号:
这些不必直接“加分”,但可帮助你按分段设定合理的期望与阈值。
一个有用的评分应混合:
避免过度加权滞后指标;它们更多是说明过去发生了什么。
若有可用数据,NPS/CSAT、支持工单量 与 CSM 笔记 能增加细节。把它们当作修饰或标记使用,而不是基础,因为定性数据往往稀疏且主观。
在建图表之前,先在名称和定义上达成一致。一个精简的数据字典应包含:
active_days_28d)这能避免实现仪表盘与告警时出现“同名指标含义不同”的困惑。
只有团队信任评分,它才有用。目标是建立一个你能在一分钟内向 CSM 解释清楚,在五分钟内向客户说明的模型。
先用透明的规则型评分。选取少量采纳信号(例如活跃用户、关键功能使用、已启用集成)并分配反映产品“aha”时刻的权重。
示例权重:
让权重易于辩护。你可以后续调整——不必等到模型完美再上线。
原始计数会惩罚小账户并夸大大账户。对有意义的指标做归一化:
这能让客户采纳健康评分更反映行为,而非规模。
设定阈值(例如 Green ≥ 75、Yellow 50–74、Red < 50)并记录每个截断点的理由。把阈值与预期结果(续约风险、入职完成、扩展准备度)关联,并把说明保存在内部文档或 /blog/health-score-playbook 下。
每个分数应展示:
把评分当作产品来做。给版本编号(v1、v2),并跟踪影响:流失风险告警是否更准确?CSM 是否更快采取行动?在每次计算中保存模型版本,以便随时间比较结果。
健康评分的可信度取决于其背后活动数据的质量。在构建计分逻辑前,确认各系统是否一致地捕获所需信号。
大多数采纳项目会混合使用:
一个实用规则:把关键动作在服务端跟踪(更难伪造、受广告拦截影响小),前端事件用于 UI 参与与发现场景。
保持一致的契约,使事件易于联表、查询并向利益相关者解释。常见基线:
event_nameuser_idaccount_idtimestamp(UTC)properties(feature、plan、device、workspace_id 等)为 event_name 使用受控词表(例如 project_created、report_exported),并在简明的跟踪计划中记录。
许多团队两者兼用,但要确保不会对同一真实世界动作重复计数。
健康评分通常汇总到 账户 级别,因此需要可靠的用户→账户映射。要考虑:
至少监控缺失事件、重复突增和时区一致性(以 UTC 存储;展示时转换)。及早标记异常,避免因追踪崩溃导致的流失风险告警误发。
一个客户采纳健康评分应用的成败取决于你如何建模“谁在什么时候做了什么”。目标是让常见问题能快速回答:本周这个账户表现如何?哪些功能在上升或下降?良好的数据建模能让计分、仪表盘和告警保持简单。
从一组“事实来源”表开始:
在各处使用稳定的 ID(account_id、user_id)以保持实体一致。
对频繁更新与联表的内容使用 关系型数据库(如 Postgres):accounts、users、subscriptions、scores。
将高容量的 事件 存到数据仓库/分析存储(如 BigQuery/Snowflake/ClickHouse)。这样可以在不压垮事务 DB 的情况下保持仪表盘与队列分析的响应速度。
不要每次都从原始事件重算,维护:
这些表驱动趋势图、“发生了什么变化”的洞察以及健康评分的组成部分。
对于大型事件表,规划 留存策略(例如原始数据 13 个月,聚合数据可保留更久)并按日期分区。按 account_id 和 timestamp/date 聚簇/索引以加速“账户随时间”的查询。
在关系型表中,为常用过滤与联表字段建立索引:account_id、(account_id, date) 在汇总表上,并使用外键保持数据清洁。
你的架构应便于快速交付可信的 v1,并能在无需重写的情况下演进。先决定真正需要多少组成部分。
对大多数团队来说,模块化单体(一个代码库但边界清晰:摄取、计分、API、UI)是最快的路径。它可部署为单个单元,并减少运维惊喜。
只有在有明确理由时(独立扩展需求、严格的数据隔离或不同团队拥有不同组件)才拆分服务;过早拆分会增加失败点并减慢迭代速度。
至少规划这些职责(即便它们最初都在同一个应用中):
如果想快速原型,一个低门槛的 vibe-coding 方法可以在不投入过多工程的前提下做出可用仪表盘。例如,Koder.ai 可以根据实体(accounts、events、scores)、端点与界面描述生成 React 前端与 Go + PostgreSQL 后端,帮助快速搭建一个供 CS 团队早期试用的 v1。
批量计分(例如按小时/每日)通常足够用于采纳监控,且运维简单。若需要近实时告警(例如突发使用骤降)或事件量极高,流式处理才有意义。
一个实用折衷:持续摄取事件,按计划做聚合/计分,并为少量紧急信号保留流式通道。
尽早搭建 dev/stage/prod 环境,在 stage 中预置示例账户以验证仪表盘表现。使用托管的密钥库并定期轮换凭据。
提前记录需求:预期事件量、分数新鲜度(SLA)、API 延迟目标、可用性、数据保留与隐私约束(PII 处理和访问控制)。这些能防止在压力下才做架构决策。
把计分当成生产系统来做:可复现、可观测,并且当有人问“为什么这个账户今天下降?”时能拿出答案。
从分阶段流程开始,把数据缩窄到可安全计分的表层:
此结构让计分作业在干净、紧凑的表上运行,而不是每次扫描数十亿原始行,从而提升稳定性与速度。
决定分数需要多“新鲜”:
构建调度系统以支持 回填(例如重处理最近 30/90 天),以便在修复追踪、调整权重或添加信号时重算历史数据。回填应是常规功能,而非紧急脚本。
计分作业会被重试,导入会重跑,webhook 可能二次投递。为此而设计:
使用 幂等键(event_id 或基于 timestamp + user_id + event_name + properties 的稳定哈希)并在 validated 层强制唯一性。对聚合表按 (account_id, date) upsert,以便重算替换旧结果而非叠加。
为以下内容添加运行监控:
即便是轻量阈值(例如“事件量较 7 日均值下降 40%”)也能避免因静默故障而误导客户成功仪表盘。
为每次计分运行保存审计记录:输入指标、派生特征(如环比变化)、模型版本与最终分数。当 CSM 点击“为什么?”时,你可以展示准确的变更与时间点,而不用从日志里逆向推断。
你的 Web 应用成败取决于 API。它是计分作业、UI 与下游工具(CS 平台、BI、数据导出)之间的契约。目标是构建快速、可预测并默认安全的 API。
围绕客户成功如何探索采纳来设计端点:
GET /api/accounts/{id}/health 返回最新分数、状态段(如 Green/Yellow/Red)与最后计算时间。GET /api/accounts/{id}/health/trends?from=&to= 返回分数随时间的变化与关键指标差值。GET /api/accounts/{id}/health/drivers 展示主要正/负驱动因素(例如“每周活跃座位下降 35%”)。GET /api/cohorts/health?definition= 用于队列分析与同侪基准对比。POST /api/exports/health 生成 CSV/Parquet 并保证一致的 schema。让列表端点便于切片:
plan、segment、csm_owner、lifecycle_stage 与 date_range 是基础。cursor、limit),以应对数据变化时的稳定性。ETag/If-None-Match 以减少重复请求。缓存键需兼顾过滤与权限。按账户保护数据。在每个端点服务端实施 RBAC(例如 Admin、CSM、只读),并强制执行访问规则。CSM 应只看到其负责的账户;财务角色可能能看到套餐级别汇总,但不能看到用户级详情。
除了数值型客户采纳健康评分外,一并返回“为什么”字段:主要驱动项、受影响的指标与比较基线(前一时期、队列中位数)。这能让产品采纳监控成为可执行的工具,而不是单纯的报表,并提升客户成功仪表盘的可信度。
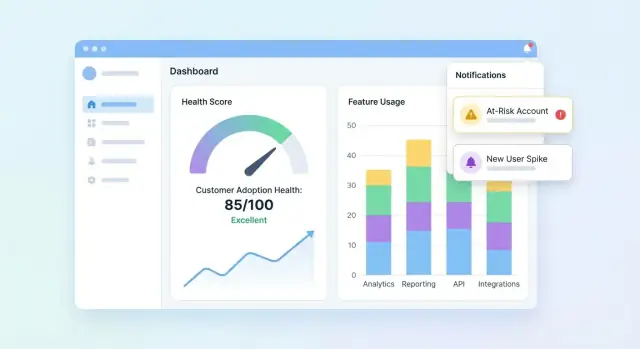
你的 UI 应快速回答三个问题:谁健康?谁在下滑?为什么?先做一个能概览全局的仪表盘,再让用户能下钻到账户查看分数背后的故事。
包含一组紧凑的卡片与图表,让客户成功团队秒懂:
把高风险名单设置为可点击,用户可打开账户并立即查看发生了什么变化。
账户页应像采纳的时间线:
添加“为什么这个分数?”面板:点击分数可查看正/负贡献信号及易懂的说明。
提供与团队管理账户方式一致的队列过滤:入职队列、套餐等级、行业。为每个队列配上趋势线和一个小表格(展示走势最快的账户),以便比较结果并发现模式。
使用清晰标签与单位,避免歧义图标,并提供颜色安全的状态指示(例如文字标签 + 形状)。把图表当作决策工具:为峰值注释、显示日期范围并保持跨页的一致下钻行为。
健康评分只有在推动行动时才有价值。告警与工作流能把“有意思的数据”转化为及时的外联、入职修复或产品推动,而无需团队持续盯着仪表盘。
从一小组高信号触发器开始:
让每条规则明确且可解释。不要只告警“健康差”,而是告警“功能 X 7 天无活动 且 入职未完成”。
不同团队有不同偏好,支持多渠道并允许配置:
允许每个团队配置:谁接收通知、启用哪些规则、哪些阈值算“紧急”。
告警疲劳会毁掉采纳监控。添加控制项如:
每条告警应回答:发生了什么、为何重要、下一步做什么。包括最近的分数驱动项、一段短时间线(例如最近 14 天)与建议任务,如“安排入职通话”或“发送集成指南”。链接至账户视图(例如 /accounts/{id})。
把告警当作待办项管理,带状态:已确认、已联系、已恢复、流失。对结果做汇报能帮助你优化规则、完善行动手册,并证明健康评分在降低流失方面的实际效果。
若你的客户采纳健康评分建立在不可靠的数据上,团队会失去信任并停止基于它行动。把质量、隐私与治理当作产品特性来设计,而不是事后补救。
在每次交接(摄取 → 仓库 → 计分输出)处做轻量验证。几个高信号测试能尽早发现大多数问题:
当测试失败,阻止计分作业(或将结果标记为“过期”),以避免损坏的管道静默地产生误导性的流失告警。
在“怪但正常”的场景中要有明确规则:
默认限制 PII:只存储产品采纳监控所需的信息。在 Web 应用中应用角色访问控制,记录谁查看/导出过数据,并在不必要时在导出中脱敏字段(例如在 CSV 中隐藏邮箱)。
编写简短运行手册以应对事件:如何暂停计分、如何回填数据、如何重跑历史作业。定期(每月或每季度)复核客户成功指标与分数权重以防止随产品演进而产生漂移。为流程对齐,把内部检查清单链接到 /blog/health-score-governance。
验证是把健康评分从“好看图表”变为值得信赖并驱动行动的关键。把首个版本当作假设而非最终答案。
从一组试点账户开始(例如 20–50 个,覆盖不同分段)。对每个账户,将评分与 CSM 的评估进行比对。
关注模式:
准确性有用,但“有用性”才带来回报。跟踪运营性结果,如:
当你调整阈值、权重或添加新信号时,把它们当作新模型版本。在可比的队列或分段上做 A/B 测试,并保留历史版本以解释分数随时间的变化原因。
添加轻量反馈控件,如“分数看起来不对”,并带原因选项(例如“入职近期完成未反映”、“使用有季节性”、“账户映射错误”)。把反馈路由到待办列表,并把其与账户与分数版本关联以便快速排查。
试点稳定后,规划扩展工作:更深的集成(CRM、计费、支持)、更细的分段(按套餐、行业、生命周期)、自动化(任务与行动手册),以及自助配置让团队无需工程即可定制视图。
在扩展过程中保持紧密的构建/迭代循环。团队常用 Koder.ai 从聊天直接生成新的仪表页、调整 API 形状或添加工作流功能(任务、导出、可回滚发布),这在你对评分模型做版本化并需同时交付 UI + 后端改动时尤其有用。
首先定义该评分的用途:
如果你不能明确说明在评分变化时会触发什么决策,就别把该指标纳入评分。
写下能证明客户正在获得价值的少数行为:
除非登录本身就代表价值,否则不要把“最近登录”当作采纳定义。
从一小组高信号指标开始:
只保留你能一句话说明其重要性的指标。
通过归一化和分段让相同行为对大小账户公平:
这样可以避免用原始计数惩罚小账户或夸大大账户的表现。
领先指标帮助提前行动;滞后指标用于确认结果:
若目标是早期预警,不要让滞后指标主导评分。
先用透明的加权得分法构建即可。示例组成:
然后定义明确的状态段(例如 Green ≥ 75、Yellow 50–74、Red < 50),并记录这些临界值的理由。
至少确保每个事件包含:
event_name、user_id、account_id、timestamp(UTC)properties(feature、plan、workspace_id 等)尽量把关键动作服务端跟踪,保持 的受控词表,并避免 SDK 与服务端重复计数。
围绕少数核心实体建模,并按工作负载拆分存储:
按日期分区大型事件表,并按 account_id 做索引/聚簇,以加速“账户随时间”的查询。
把评分当作生产流水线:
(account_id, date) upsert 聚合)这样在回答“为什么分数下降?”时,不用翻查日志也能给出答案。
先实现对工作流有帮助的端点:
GET /api/accounts/{id}/health(最新分数 + 状态)GET /api/accounts/{id}/health/trends?from=&to=(时间序列 + 差值)GET /api/accounts/{id}/health/drivers(主要正/负驱动因素)在服务端强制 RBAC,列表采用游标分页,告警用冷却窗口和最小数据阈值降低噪音。告警应链接到账户视图(例如 /accounts/{id})。
event_name