2025年8月27日·1 分钟
Go 工作池用于后台任务:重试、取消与优雅关机
在引入复杂基础设施前,用简单模式在小团队里用 Go 工作池实现后台任务的重试、取消和干净关机。
为什么后台任务很快会变得混乱
在一个小型的 Go 服务中,后台工作通常从一个简单目标开始:快速返回 HTTP 响应,然后把慢的工作留到后面去做。那可能是发送邮件、调整图片大小、同步到另一个 API、重建搜索索引,或运行夜间报告。
问题在于这些任务是真实的生产工作,只是缺少你在请求处理时自然会得到的护栏。从 HTTP 处理程序启动的一个 goroutine 看起来没问题,直到部署在任务中途发生、上游 API 变慢,或者同一个请求被重试导致任务执行两次。
第一个痛点是可预见的:
- 卡住的任务:某个调用挂起,worker 停止前进。
- 重复工作:HTTP 层的重试重新运行相同的任务。
- 没有关闭计划:进程退出,工作丢失或半途而废。
- 沉默失败:错误只记录一次(或根本没记录)然后消失。
- 重试风暴:失败的任务立即重试并压垮依赖方。
这正是像 Go 工作池这样小而明确的模式有用的地方。它把并发变为一个可控的选择(N 个 worker),把“以后做”变为明确的任务类型,并给你一个地方去处理重试、超时和取消。
举个例子:SaaS 应用需要发送发票。导入批量后你不希望同时发送 500 封邮件,也不想因为请求被重试而重新发送相同的发票。工作池让你限制吞吐量,并把“发送发票 #123”视为一个可跟踪的工作单元。
当你需要跨进程的持久保证时,工作池并不是正确的工具。如果任务必须在崩溃后生存、被安排在将来执行,或被多个服务处理,你可能需要真正的队列加上用于任务状态的持久存储。
用通俗语言描述工作池模型
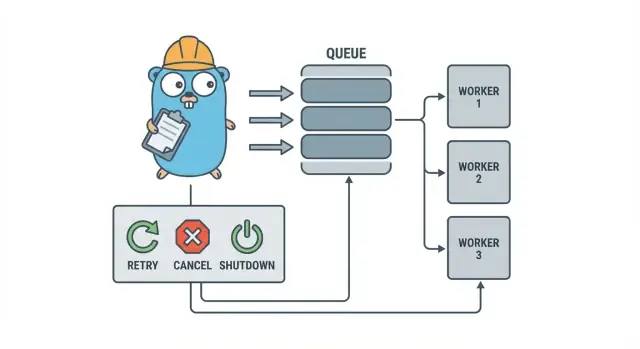
Go 工作池故意很朴素:把工作放进队列,让固定数量的 worker 从中拉取,并确保整个系统能干净地停止。
基本术语:
- Job:一单位工作,比如“调整这张图片大小”或“发送这封发票邮件”。
- Queue:任务等待的地方。
- Worker:一个重复获取任务并执行的 goroutine。
- Dispatcher:接受任务并把它们放入队列的部分。
在许多进程内的设计中,Go 的 channel 就是队列。带缓冲的 channel 在生产者阻塞前能容纳有限数量的任务。那种阻塞就是反压(backpressure),通常能防止你的服务在流量突增时接受无限工作并耗尽内存。
缓冲区大小会改变系统的感觉。小缓冲会更快显现压力(调用者更早等待)。大缓冲能平滑短时突发,但可能把过载隐藏到更晚才暴露。没有完美的数字,只有与你能容忍的等待量相匹配的数字。
你还要选择池大小是固定的还是可变的。固定池更容易推理并保持资源使用可预测。自动扩缩 worker 可以应对不均匀的负载,但会增加你需要维护的决策(何时扩、扩多少、何时缩回)。
最后,在进程内的池中,“ack” 通常只是意味着“worker 完成任务并且没有返回错误”。没有外部 broker 来确认投递,所以你的代码定义“完成”是什么意思以及任务失败或被取消时该怎么做。
设计目标:重试、取消和干净关机
工作池在机械上很简单:运行固定数量的 worker,喂给它们任务,然后处理这些任务。价值在于控制:可预测的并发、明确的故障处理以及不留下半成工作的一条关闭路径。
三个目标能让小团队保持理智:
- 限制并发,以免一次突发把数据库或外部 API 压垮。
- 避免丢失工作(或至少确切知道哪些被丢弃和为什么)。
- 保持可调试性:每个任务都应该能通过日志和几个计数器被追踪。
大多数故障都很平凡,但你仍然要对它们区别对待:
- 短暂错误(网络抖动、速率限制)应当重试。
- 永久性错误(非法输入、记录缺失)不应重试。
- 超时(依赖方挂起)必须被切断以免占满 worker。
取消并不等同于“错误”。它是一种决定:用户取消了、部署替换了进程,或服务正在关机。在 Go 中,把取消视为一等信号,使用 context 的取消,并确保每个任务在开始昂贵工作前以及执行过程中的几个安全点检查它。
干净关机是许多池崩溃的地方。提前决定“安全”对你的任务意味着什么:是完成正在进行的工作,还是快速停止并在以后重跑?一个实用流程是:
- 停止接受新任务。
- 告诉 worker 在完成当前任务后停止(或立即停止)。
- 等待一个截止时间,然后强制退出。
如果你早早定义这些规则,重试、取消和关机就会保持小而可预测,而不是变成自研框架。
逐步构建:创建一个基本工作池
工作池只是一些 goroutine 从 channel 中拉取任务并执行。重要的是让基础可预测:任务长什么样、worker 如何停止、以及如何知道所有工作何时完成。
从一个简单的 Job 类型开始。给它一个 ID(用于日志)、一个 payload(要处理的内容)、尝试计数(以后用于重试)、时间戳,以及存放每个任务上下文数据的地方。
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := &Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i < size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case <-p.ctx.Done():
return
case job, ok := <-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case <-p.ctx.Done():
return context.Canceled
case p.jobs <- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
你会很快做出几个实用选择:
- 根据你能容忍的等待量选择队列大小。
- 决定对调用者而言反压意味着什么:阻塞、返回错误或丢弃。
- 保持
Stop()和Wait()分离,这样你可以先停止摄入,然后等待正在进行的工作完成。
添加重试但不把它变成一个大框架
重试有用,但也是工作池变得混乱的地方。把目标保持窄小:仅在另一次尝试有真实成功机会时重试,并在没有希望时尽快停止。
先决定什么是可重试的。临时问题(网络抖动、超时、“稍后再试”的响应)通常值得重试。永久性问题(非法输入、缺失记录、权限被拒)则不应重试。
一个小型的重试策略通常足够:
- 把错误标记为可重试或不可重试(例如,用
Retryable(err)辅助函数包装)。 - 设置最大尝试次数(通常 3 到 5 次)。超过这个次数通常就是浪费时间。
- 使用带抖动的指数退避,避免任务同步重试。
- 限制延迟(例如,永远不要睡超过 30 秒)。
- 记录重试日志,包含尝试次数、下一次延迟和任务 ID。
退避不需要复杂。常见形式是:delay = min(base * 2^(attempt-1), max),然后加上抖动(随机化 +/-20%)。抖动很重要,否则许多 worker 会同时失败并同时重试。
延迟应该放在哪里?对于小系统,在 worker 内部 sleep 是可以的,但这会占用一个 worker 插槽。如果重试很少或者延迟很短,这是可以接受的。如果重试常见或延迟很长,考虑把任务重新入队并带上“在未来运行”的时间戳,这样 worker 可以处理其它工作。
在最终失败时要明确。保存失败的任务(和最后的错误)以便复查,记录足够的上下文以便重放,或者把它放入一个需要定期检查的死信列表。避免沉默丢弃。隐藏失败的池比没有重试更糟。
实际生效的取消和超时
Deploy your background worker
Deploy your Go app with hosting support when you are ready to run it.
当你能停止 worker 时,工作池才真正安全。最简单的规则是:把 context.Context 贯穿到每一层可能阻塞的地方。这意味着提交、执行和清理都要使用上下文。
一个实用设置使用两个时间限制:
- 每任务超时,防止某个任务占用 worker 太久。
- 关机超时,让进程即便有一些任务不配合也能退出。
在各层使用 context
为每个任务从 worker 的上下文派生出自己的上下文。然后每个可能慢的调用(数据库、HTTP、队列、文件 I/O)都必须使用这个上下文,以便能尽早返回。
func worker(ctx context.Context, jobs <-chan Job) {
for {
select {
case <-ctx.Done():
return
case job, ok := <-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
如果 Run 调用了你的 DB 或 API,把上下文传入这些调用(例如使用 QueryContext、NewRequestWithContext,或接受 context 的客户端方法)。如果在某个地方忽略了它,取消就成了“尽力而为”,通常在你最需要时会失败。
部分完成的工作与“可安全重试”的步骤
取消可能在任务中途发生,所以要假设部分完成是正常的。目标是让步骤幂等,这样重跑不会产生重复副作用。常见方法包括使用唯一键进行插入(或 upsert)、写入进度标记(started/done)、在继续前存储结果,以及在步骤间检查 ctx.Err()。
把关机当成一个最后期限:停止接受新任务,取消 worker 上下文,并只等待到关机超时以让正在进行的任务退出。
干净关机:当进程必须退出时怎么做
干净关机有一个目标:停止接收新工作,告诉正在进行的工作停止,并以不会把系统留在奇怪状态下的方式退出。
从信号开始。在大多数部署中,你会遇到本地的 SIGINT 和来自进程管理器或容器运行时的 SIGTERM。使用在信号到来时被取消的关机上下文,并把它传入你的池和任务处理程序。
接下来,停止接受新任务。不要让调用方在向再也没有消费者的 channel 提交时永远阻塞。把提交封装在一个函数后面,该函数在发送前检查已关闭标志或在选择中监听关机上下文。
然后决定排队的工作如何处理:
- Drain(排空):完成已排队的工作,但拒绝新的提交。
- Drop(丢弃):抛弃尚未开始的所有工作。
排空对付款和邮件等重要任务更安全。丢弃则适用于像重新计算缓存这类“可有可无”的任务。
一个实用的关机序列:
- 捕获 SIGINT/SIGTERM 并取消共享上下文。
- 停止提交(关闭提交路径,不一定是工作 channel 本身)。
- 根据上下文让 worker 完成或中止。
- 使用 WaitGroup 等待 worker。
- 强制一个截止时间,然后退出。
截止时间很重要。例如,给正在进行的任务 10 秒去停止。超过后,记录仍在运行的任务并退出。这让部署可预测并避免进程卡死。
工作池的日志和简单指标
Own the generated source code
Get full Go, React, and database code you can own and extend.
当工作池出问题时,通常不会大声失败。任务变慢、重试堆积,然后有人报告“没有任何事情发生”。日志和一些基本计数器能把这些情况变成清晰的故事。
给每个任务一个稳定的 ID(或在提交时生成)并在每行日志中包含它。保持日志一致:一条日志表示任务开始,一条表示完成,一条表示失败。如果重试,记录尝试次数和下一次延迟。
一个简单的日志格式:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
指标可以保持最小化但仍有价值。跟踪队列长度、进行中任务数、成功和失败总数,以及任务延迟(至少平均和最大值)。如果队列长度持续上升而进行中保持在 worker 数量上限,说明你已饱和。如果提交方在向 jobs channel 发送时阻塞,说明反压达到了调用方。这并不总是坏事,但应该是有意的。
当“任务卡住”时,查看进程是否仍在接收任务、队列长度是否在增长、worker 是否仍然存活,以及哪些任务运行时间最长。长时间运行通常指向缺失超时、依赖方变慢或永不停止的重试循环。
一个现实例子:小型 SaaS 后台队列
想象一个小型 SaaS,当订单变为 PAID 后,需要发送发票 PDF、给客户发邮件并通知内部团队。你不想这些工作阻塞 web 请求。这很适合用工作池,因为工作重要但系统仍小。
任务 payload 可以很小:只包含从数据库获取剩余数据所需的信息。API 处理程序在与订单更新相同的事务中写入一行,例如 jobs(status='queued', type='send_invoice', payload, attempts=0),然后后台循环轮询排队任务并把它们推入 worker channel。
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
当 worker 拿到任务时,正常路径很直接:加载订单、生成发票、调用邮件提供商,然后标记任务完成。
重试是把事情变得真实的地方。如果你的邮件提供商短暂不可用,你不希望 1000 个任务永远失败或每秒钟猛砸提供商。实用方法是:
- 把网络错误和 5xx 响应视为可重试。
- 使用有最大延迟的指数退避(例如 5s、15s、45s、2m)。
- 限制尝试次数(例如 10 次),然后标记任务失败。
- 记录最后的错误以便支持人员查看发生了什么。
在故障期间,任务从 queued 到 in_progress,然后带着未来运行时间回到 queued。提供商恢复后,worker 自然会清空积压。
再想象一次部署。你发送 SIGTERM。进程应停止接受新工作但完成已有的正在进行工作。停止轮询、停止向 worker channel 推送并在一个截止时间内等待 worker。完成的任务被标记为 done。在截止时间到达时仍在运行的任务应被重新标记为 queued(或留在 in_progress 并由监视器接管),以便新版本启动后能被拾取。
常见错误和陷阱
后台处理中的大多数 bug 并不在任务逻辑里。它们来自协调错误,只在负载或关机期间出现。
一个经典陷阱是从多个地方关闭同一个 channel。结果是难以复现的 panic。为每个 channel 选择一个 owner(通常是生产者),并让它成为唯一调用 close(jobs) 的地方。
重试是另一个好心办坏事的区域。如果你对所有错误都重试,就会把永久性失败也重试。这浪费时间、增加负载,并可能把一个小问题变成事故。对错误进行分类并用清晰的策略限制重试次数。
重复是不可避免的。worker 可能在任务中崩溃、超时可能在工作完成后才触发,或在部署期间重新排队。如果任务不是幂等的,重复会造成真正的损害:两份发票、两封欢迎邮件、两次退款。
最常见的错误:
- 在多个 goroutine 中关闭同一个 channel。
- 重试永久性错误而不是把它们暴露出来。
- 没有幂等键,导致重复产生双重副作用。
- 不受限的内存内队列增长直到内存峰值。
- 忽略
context.Context,导致在关机开始后工作仍在继续。
不受限队列尤其阴险。一次工作激增可能悄悄堆积在 RAM 中。优先选择有界的 channel 缓冲,并决定它满时的行为:阻塞、丢弃或返回错误。
上线前的快速检查清单
Move to a PostgreSQL job queue
Turn in-process jobs into a simple PostgreSQL queue without rewriting your handlers.
在把工作池推到生产前,你应该能够把任务生命周期口头说明清楚。如果有人问“这个任务现在在哪里?”,答案不该是猜测。
一个实用的发布前检查表:
- 你能命名每个状态和转换:queued、picked up、running、finished、failed(以及是什么把它们之间移动)。
- 并发性是一个旋钮(比如
workerCount),改变它不需要重写代码。 - 重试有上限:最大尝试次数明确、退避增长、永久失败有明确去向。
- 关机行为已验证:你停止摄入、让进行中的任务完成,并且有硬超时。
- 日志回答基本问题:job ID、尝试次数、时长和错误原因。
在发布前做一次真实演练:入队 100 个“发送收据邮件”任务,强制 20 个失败,然后在运行中重启服务。你应该能看到重试如预期工作、没有重复副作用,并且在截止时间到达时取消确实会停止工作。
如果有任何条目模糊,现在就修紧。这里的小修补能省下后续数天的时间。
下一步:什么时候加入更重的基础设施(什么时候不要)
简单的进程内池在产品早期通常足够。如果你的任务是“可有可无”的(发送邮件、刷新缓存、生成报告)并且可以重跑,工作池能让系统保持易于理解。
你已经超出进程内池的迹象
关注这些压力点:
- 你运行多个应用实例并且只想让其中一个来拾取任务。
- 你需要持久性(任务必须在崩溃和部署间保留)。
- 你需要审计轨迹:谁在何时入队、何时运行以及确切结果。
- 你需要跨服务的反压控制,而不仅仅是进程内的。
- 你需要严格的调度或长延迟(小时或天)并能可靠唤醒。
如果以上都不成立,更重的工具可能会增加比价值更多的复杂性。
逐步迁移而不是重写
最好的对冲策略是稳定的任务接口:一个小的 payload 类型、一个 ID,以及返回明确结果的处理器。这样你以后可以替换队列后端(从内存 channel 到数据库表,再到专用队列)而不改业务代码。
一个实用的中间步骤是一个小的 Go 服务,从 PostgreSQL 读取任务,用锁进行认领,并更新状态。你能得到持久性和基本的可审计性,同时保留相同的 worker 逻辑。
如果想快速原型,Koder.ai (koder.ai) 可以从聊天提示生成一个 Go + PostgreSQL 启动模板,包括后台任务表和 worker 循环,它的快照和回滚功能能在你调优重试和关机行为时提供帮助。