2025年3月01日·2 分钟
如何构建一个用于跟踪内部工具采纳的 Web 应用
学习如何设计并构建一个测量内部工具采纳的 Web 应用:明确指标、事件埋点、仪表盘、隐私与分阶段推广步骤。
学习如何设计并构建一个测量内部工具采纳的 Web 应用:明确指标、事件埋点、仪表盘、隐私与分阶段推广步骤。
在开始构建之前,先对组织内部的“采纳”达成一致。内部工具不会自己“卖得好”——采纳通常是访问、行为与习惯的混合体。
选择一小组所有人都能复述的定义:
把这些写下来,并把它们当作产品需求,而不是仅仅统计学上的注释。
跟踪应用只有在能改变后续决策时才有价值。列出你想更快或更少争议地做出的决策,例如:
如果某个指标不会驱动决策,它就不是 MVP 必需的。
明确列出受众以及每类受众需要回答的问题:
为跟踪应用本身定义成功标准(而非被跟踪工具的成功),例如:
设定简单时间表:第 1 周 完成定义与利益相关者对齐,第 2–3 周 完成 MVP 埋点与基础仪表盘,第 4 周 复盘、修补缺口并发布可重复的节奏。
只有能回答决策问题的数据才有价值。如果你什么都跟踪,就会被图表淹没还不知道要修复什么。先从一小组映射到推广目标的采纳指标开始,再逐步增加参与度与分段。
已激活用户: 完成获取最小价值所需步骤的用户数或比例。例如:通过 SSO 登录并成功完成首次工作流。
WAU/MAU: 每周活跃用户与每月活跃用户。这能快速告诉你使用是否形成习惯或只是偶发。
留存: 新用户在首周或首月后继续使用的比例。定义 cohort(例如“在十月份首次使用”)和清晰的“活跃”规则。
首次价值时间(TTFV): 新用户达到第一个有意义结果所需的时间。TTFV 越短,通常长期采纳越好。
在建立核心采纳指标后,增加一小组参与度度量:
按 部门、角色、地点或团队 划分指标,但避免过于细粒度的拆分以免鼓励“记分制”式的个人或小团队比较。目标是发现需要赋能、培训或流程设计改进的地方,而不是进行微观管理。
写下阈值,例如:
并为急剧下降添加告警(例如“功能 X 使用环比下降 30%”),以便快速调查——通常发布问题、权限问题或流程变更会首先在这些指标上显现。
在添加埋点前,先厘清日常工作中的“采纳”长什么样。内部工具用户往往较少,所以每个事件都要经得起被记录的理由:它应该能说明该工具是否在帮助人们完成真实任务。
从 2–4 个常见工作流开始,把它们写成简短的逐步旅程。例如:
对每个旅程标记你关心的时刻:首次成功、交接点(例如提交 → 批准)与瓶颈(例如校验错误)。
对有意义的动作(创建、批准、导出)和定义进度的状态变化使用 events。
对导航与流失点可以谨慎使用 page views——它们会很嘈杂,如果被当作使用的代理指标则容易误导。
当需要在各客户端间保证可靠性或覆盖面时,使用 后端日志(例如通过 API 触发的审批、定时任务、批量导入)。一个实用模式是:在 UI 上记录点击作为事件,在后端记录实际完成。
选定一致的样式并遵守(例如 verb_noun:create_request、approve_request、export_report)。定义必填属性以便事件对各团队都可用:
user_id(稳定标识)tool_id(哪个内部工具)feature(可选分组,例如 approvals)timestamp(UTC)在安全可行时增加有用的上下文:org_unit、role、request_type、success/error_code。
工具会变化。你的分类法应能在不破坏仪表盘的情况下容忍变化:
schema_version(或 event_version)。清晰的数据模型能避免以后的报表噩梦。目标是让每个事件都明确:是谁(who)在何时(when)在哪个工具(which tool)做了什么(what),同时保持系统易于维护。
大多数内部采纳跟踪应用可以从一小组表开始:
保持 events 表的一致性:event_name、timestamp、user_id、tool_id,以及一个小的 JSON/properties 字段用于存放你会筛选的详情(例如 feature、page、workflow_step)。
使用不会随人改邮件或名字而变化的稳定 ID:
idp_subject)定义原始事件的保留期(例如 13 个月),并计划 每日/每周汇总表(按工具 × 团队 × 日期),以保持仪表盘响应迅速。
记录哪些字段来自哪里:
这能避免“神秘字段”,并明确由谁修复坏数据。
埋点是把采纳跟踪变为真实的过程:你将用户行为翻译为可靠事件。关键决策是事件在哪里生成——客户端、服务器端或两者——以及如何让这些数据足够可靠以便信任。
大多数内部工具从混合方案受益:
保持客户端跟踪最小化:不要记录每次按键。关注那些能表示工作流推进的时刻。
网络抖动和浏览器限制会发生,加入:
在服务器端,把分析上报视为非阻塞:如果事件记录失败,业务动作仍应成功。
在摄取处(最好也在客户端库中)实现 schema 检查。验证必填字段(event name、timestamp、actor ID、org/team ID)、数据类型与允许值。拒绝或隔离畸形事件,避免它们悄无声息地污染仪表盘。
始终包含 env=prod|stage|dev 之类的环境标签,并在报表中过滤它们。这能防止 QA 运行、演示与开发测试膨胀采纳指标。
一个简单规则:先在服务器端记录核心动作,再在需要了解意图与 UI 摩擦的地方补充客户端事件。
如果人们不信任采纳数据如何被访问,他们就不会使用系统——或者会刻意回避跟踪。把认证与权限当作首要功能,而不是事后补充。
使用公司现有的身份提供者,使访问与员工已有登录方式一致。
一个简单的角色模型能覆盖大多数内部采纳场景:
使访问基于作用域(按工具、部门、团队或地点),避免“tool owner”拥有查看一切的能力。对导出也做相同限制——CSV 常是数据泄露的途径。
为以下操作添加审计日志:
记录最小权限默认(例如新用户默认为 Viewer)并为 Admin 访问设计审批流程——在系统中放一条 /access-request 链接或一个简单表单,以便审查变更更轻松。
内部工具采纳跟踪涉及员工数据,因此隐私不能事后再考虑。如果员工感到被监控,他们会抵触工具——而数据也会变得不可靠。把信任当作产品需求。
先定义“安全”事件类型。跟踪动作与结果,而不是员工输入的内容。
report_exported、ticket_closed、approval_submitted 之类的事件。/orders/:id)。把这些规则写下来,作为埋点清单的一部分,避免新功能无意间引入敏感数据采集。
尽早与 HR、法务和安全团队合作。确定跟踪目的(例如培训需求、流程瓶颈),并明确禁止某些用途(例如未经单独流程的绩效评估)。记录:
大多数利益相关者并不需要个人级数据。默认提供团队/组织层面的聚合视图,只有少数管理员在获得审批时可下钻到可识别数据。
使用小组抑制阈值以避免暴露微小群体的行为(例如隐藏群体大小 < 5 的拆分)。这也在组合筛选时降低复识别风险。
在应用内(以及入职流程中)加入简短说明,解释收集内容与目的。维护一份活跃的内部 FAQ,包含被跟踪与未被跟踪数据示例、保留时间线以及如何提出关切。把该 FAQ 从仪表盘与设置页链接出来,例如 /internal-analytics-faq。
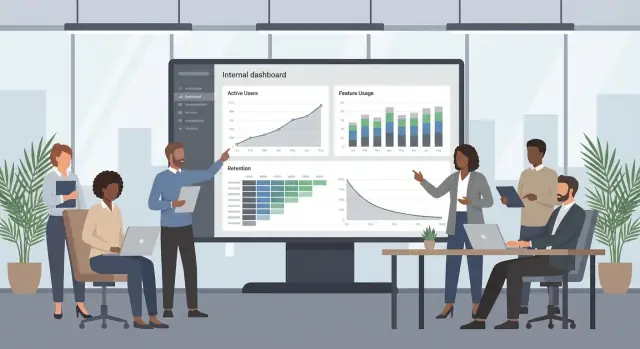
仪表盘应该回答一个问题:“下一步该怎么做?”如果一个图表有趣但不会导致行动(如提醒培训、修正入门流程、下线功能),它就是噪声。
为大多数利益相关者创建少量概览视图:
保持概览简洁:最多 6–10 个卡片,统一时间范围,并明确定义(例如“活跃”如何计算)。
当某个指标变化时,人们需要快速探索原因:
让筛选显而易见且安全:日期范围、工具、团队与分段;提供合理默认并内置重置按钮。
添加一个自动更新的短清单:
每一项应链接到相应下钻页面并给出建议的下一步。
导出功能强大但有风险。仅允许导出用户有权查看的数据,并默认避免行级员工数据。对于定期报告,包含:
/reports/adoption)当你无法回答“谁负责此工具?”、“此工具面向谁?”或“上周发生了什么变化?”时,采纳数据会难以解释。一个轻量的元数据层能把原始事件变成可操作的信息,并让你的跟踪 Web 应用对分析团队以外的人也有价值。
从一个工具目录页面开始,作为你跟踪的每个内部工具的事实来源。保持可读与可搜索,结构化程度足以支持报表。
包含:
该页面应作为你在仪表盘与运行手册中引用的中心,任何人都能快速了解“良好采纳”的样子。
给工具负责人一个界面,用来定义或完善 关键事件/功能(例如“提交了报销单”、“批准请求”),并附加关于成功标准的说明。为这些编辑存储 变更历史(谁在何时为何修改),因为事件定义会随工具演进而变化。
一个实用的模式是保存:
使用量的激增或下降通常与推广活动相关——而不仅仅是产品改动。在工具记录中存储推广元数据:
在工具记录中加入一个检查表链接,例如 /docs/tool-rollout-checklist,让负责人在一个地方协调衡量与变更管理。
你的目标不是构建“完美”的分析平台,而是交付一个可靠且团队能维护的系统。从与你现有技能与部署环境匹配的栈开始,然后在存储与性能上做几项有意识的选择。
对许多团队而言,常见的 Web 栈已经足够:
保持摄取 API 简单:一些版本化端点,如 /events 与 /identify。
如果你想快速做 MVP,vibe-coding 的方法对内部应用很有效——尤其适合 CRUD 密集的界面(工具目录、角色管理、仪表盘)与第一版的摄取端点。例如,Koder.ai 可以帮助团队从聊天驱动规格快速原型一个 React + Go + PostgreSQL 的方案,然后在你完善事件分类与权限模型时迭代。
采纳通常由 激活(activation)、使用(usage) 和 留存(retention) 共同构成。
把这些定义写下来,并把它们作为你应用必须测量的需求。
先列出跟踪应用应能让你更快或更有把握做出的决策,例如:
如果某个指标不能驱动决策,就把它排除在 MVP 之外。
一个实用的 MVP 指标集合是:
这四项覆盖了从首个价值到持续使用的漏斗,而不会让你被过多图表淹没。
跟踪有意义的工作流动作,不要无差别地记录所有内容。
create_request、approve_request、。采用统一的事件命名(例如 verb_noun)并要求一小组必填属性。
最低推荐字段:
event_nametimestamp(UTC)user_id(稳定)tool_id(稳定)使用稳定且非语义化的标识符:
user_id 设为你应用的 UUID,并映射到不可变的 IdP 标识(例如 OIDC subject)。tool_id 设为每个工具的 UUID(不要用工具名作为 key)。anonymous_id。这样可以避免当邮箱、姓名或工具标签变化时报表破裂。
采用混合模型以提高可靠性:
加入 批量发送、指数退避重试 和 小型本地队列(内存或 localStorage)以减少事件丢失。确保分析失败不会阻塞业务动作。
保持角色模型简单且基于作用域:
按工具/部门/团队/地点进行作用域限制;导出权限也应受限(CSV 常是数据泄露途径)。添加审计日志记录权限变更、设置编辑、分享、导出与 API token 创建等操作。
默认以隐私为设计原则:
/orders/:id)。在应用内和入职时发布短小说明,并维护内部 FAQ(例如 /internal-analytics-faq)说明跟踪内容、保留期以及如何提出疑问。
从能推动行动的视图开始:
加入可下钻的筛选(按工具、部门、角色、地点等),并自动列出“最高改进机会”(例如低激活但高资格的团队、功能在激活用户中未被使用、发布后使用骤降)。导出与定期报告须有权限检查,默认避免行级员工数据导出。
export_report常见模式是:UI 记录 “attempted”,而后端记录 “completed”。
有用的可选字段包括 feature、org_unit、role、workflow_step 和 success/error_code——仅当这些字段是安全且可解释时才添加。