2025年12月10日·1 分钟
用 Claude Code 根据行为生成 OpenAPI(诚实的工作流)
学习如何使用 Claude Code 根据行为生成 OpenAPI,然后将其与运行中的 API 实现对比,并创建简单的客户端与服务端校验示例。
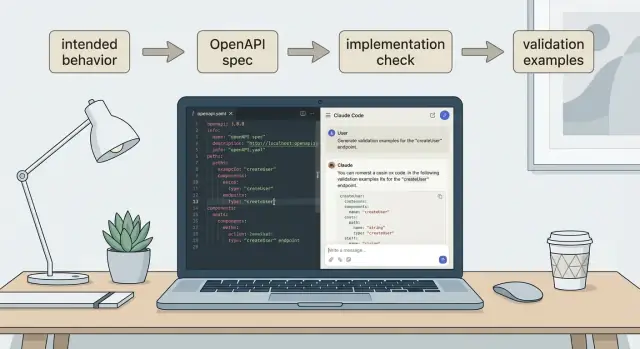
学习如何使用 Claude Code 根据行为生成 OpenAPI,然后将其与运行中的 API 实现对比,并创建简单的客户端与服务端校验示例。
OpenAPI 合同是你 API 的共享描述:有哪些端点、你发送什么、你会得到什么、错误是什么样子。这是服务器与任何调用它的方(网页应用、移动应用或其他服务)之间的约定。
问题在于漂移。运行中的 API 发生了变化,但规范没有跟上。或者规范被“清理”得比现实好看,而实现持续返回奇怪的字段、缺失的状态码或不一致的错误结构。随着时间推移,人们不再信任 OpenAPI 文件,它就变成了又一份被忽视的文档。
漂移通常来自正常的压力:一次快速修复发布了但没有更新规范,一个可选字段被“临时”加入,分页演进,或者团队维护不同的“真实来源”(后端代码、Postman 集合和一个 OpenAPI 文件)。
保持诚实的关键是规范要匹配真实行为。如果 API 有时会返回 409 表示冲突,那就应该写进合同。如果某个字段可为空,就说明。如果需要认证,不要含糊其辞。
一个好的工作流程会让你得到:
最后一点很重要,因为合同只有在被强制执行时才有用。一份诚实的规范加上可重复的检查,会把“API 文档”变成团队可以依赖的东西。
如果你从读代码或复制路由入手,你的 OpenAPI 会描述今天存在的东西,包括你可能不想承诺的怪癖。相反,应先描述调用方应该看到的 API 行为,然后用规范去验证实现是否匹配。
在写 YAML 或 JSON 之前,为每个端点收集少量事实:
然后把行为写成示例。示例迫使你具体化,并且更容易起草一致的合同。
例如对于一个任务 API,正常路径的示例可能是:“使用 title 创建任务并返回 id、title、status 和 createdAt。” 加上常见失败:“缺少 title 返回 400,返回 {\"error\":\"title is required\"}” 和 “未认证返回 401。” 如果你已知边缘情况也列上:是否允许重复标题,任务 ID 不存在时怎么处理。
把规则用简单句子记录,不依赖代码细节:
title 为必填,长度 1-120 字符。”limit(最大 200)。”dueDate 是 ISO 8601 的日期时间。”最后,决定你的 v1 范围。如果不确定,就把 v1 做小而清晰(创建、读取、列表、更新状态)。把搜索、批量更新和复杂过滤留到后面,这样合同更可信。
在你要求 Claude Code 编写规范之前,先用一个小而可重复的格式写行为说明。目标是让填空时不容易无意间猜测。
好的模板既简短易用,又一致性足够高,让两个人描述同一端点时不会差异太大。把重点放在 API 做什么,而不是如何实现。
每个端点用一个块:
METHOD + PATH:
Purpose (1 sentence):
Auth:
Request:
- Query:
- Headers:
- Body example (JSON):
Responses:
- 200 OK example (JSON):
- 4xx example (status + JSON):
Edge cases:
Data types (human terms):
至少写一个具体请求和两个响应。包含状态码和现实的 JSON 体,列出字段名。如果某字段是可选的,给出一个示例缺失它的情况。
明确指出边缘情况。这些是规范后来悄悄变得不真实的地方,因为每个人默认的假设不同:空结果、无效 ID(400 vs 404)、重复(409 vs 幂等行为)、验证失败和分页限制。
在考虑 schema 之前,也先用通俗的词说明数据类型:字符串 vs 数字、日期时间格式、布尔值和枚举(列出允许值)。这能防止出现看起来漂亮却与真实负载不匹配的 schema。
把 Claude Code 当作细心的记录员来用会效果最好。给它你的行为说明和严格的规则,说明 OpenAPI 应该如何构建。如果只说“写一个 OpenAPI 规范”,通常会出现猜测、不一致的命名和缺失的错误情况。
先粘贴行为说明,再加上明确的指令块。一个实用的提示大致像:
You are generating an OpenAPI 3.1 YAML spec.
Source of truth: the behavior notes below. Do not invent endpoints or fields.
If anything is unclear, list it under ASSUMPTIONS and leave TODO markers in the spec.
Requirements:
- Include: info, servers (placeholder), tags, paths, components/schemas, components/securitySchemes.
- For each operation: operationId, tags, summary, description, parameters, requestBody (when needed), responses.
- Model errors consistently with a reusable Error schema and reference it in 4xx/5xx responses.
- Keep naming consistent: PascalCase schema names, lowerCamelCase fields, stable operationId pattern.
Behavior notes:
[PASTE YOUR NOTES HERE]
Output only the OpenAPI YAML, then a short ASSUMPTIONS list.
拿到草稿后先看 ASSUMPTIONS,那里决定了诚实度是否丢失。批准正确的部分,修正错误,再用更新过的说明重跑。
为保持命名一致性,事先声明并坚持约定。例如:稳定的 operationId 模式、只用名词的 tag 名称、单数 schema 名称、一个共享的 Error schema,以及统一使用的认证方案名。
如果你在像 Koder.ai 这样带“vibe-coding”的工作区工作,尽早把 YAML 保存为真实文件并小步迭代会很有帮助。你可以看到哪些更改来自已批准的行为决策,哪些来自模型的猜测。
在你把规范拿去和生产比较之前,先确保 OpenAPI 文件内部一致。这是最快能发现“愿景化”或模糊描述的地方。
像客户端开发者那样逐个端点读一遍规范。关注调用方必须发送的内容和他们可以依赖收到的内容。
一次实用的审阅:
错误响应需要额外注意。选一个共享形状并复用它。有的团队保持非常简单({ error: string }),有的用对象({ error: { code, message, details } })。两种都可行,但不要在端点间混用。若混用,客户端会累积特例处理逻辑。
一个快速的合理性场景:如果 POST /tasks 要求 title,schema 应把它标为必填,失败响应应展示实际返回的错误体,操作也要明确说明是否需要认证。
当规范读起来像你期望的行为时,把运行中的 API 当作客户端今天所体验到的事实。目标不是“分出高下”,而是尽早找出差异并对每一项做出明确决定。
第一轮对比时,真实的请求/响应样本通常是最简单的选择。如果日志和自动化测试可靠,也可以用它们。
关注常见不匹配:某处存在的端点在另一处缺失,字段名或结构不同,状态码不同(200 vs 201、400 vs 422),未记录的行为(分页、排序、过滤),以及认证差异(规范说公开,代码却要求 token)。
示例:你的 OpenAPI 说 POST /tasks 返回 201 并包含 {id,title}。你调用运行中的 API 却得到 200 并包含 {id,title,createdAt}。如果你要从规范生成客户端 SDK,这类“不精确相同”的差异会造成问题。
在修改任何东西前,决定如何解决冲突:
把每次变更控制在小范围内:一个端点、一个响应或一个 schema 调整。这样更易审查,也更易重新测试。
当你已有一份可信的规范时,把它转成小型校验示例。这是防止漂移再次出现的关键措施。
在服务端,校验意味着当请求不匹配合同时尽早失败,并返回清晰的错误。这能保护数据并且让 bug 更易定位。
把服务端校验示例表达成三部分:输入、期望输出和期望错误(错误码或消息模式,而不是精确文字)。
示例(合同说 title 必填且长度为 1 到 120 字符):
{
"name": "Create task without title returns 400",
"request": {"method": "POST", "path": "/tasks", "body": {"title": ""}},
"expect": {"status": 400, "body": {"error": {"code": "VALIDATION_ERROR"}}}
}
在客户端,校验是为了在服务器开始返回不同形状或必需字段消失时尽早发现问题。
把客户端检查聚焦在你真正依赖的内容,比如“一个任务有 id、title、status。”避免断言每个可选字段或严格的字段顺序。你希望测试在破坏性变更时失败,而不是因为无害的新增而报错。
一些保持测试可读的原则:
如果你用 Koder.ai,可以把这些示例用例与 OpenAPI 文件并列保存,当行为变更时作为同一审查的一部分一并更新。
想象一个小型 API,有三个端点:POST /tasks 创建任务,GET /tasks 列表任务,和 GET /tasks/{id} 返回单个任务。
从为某个端点写几条具体示例开始,就像你在向测试人员解释它一样。
对于 POST /tasks,期望行为可以是:
{ \"title\": \"Buy milk\" } 并得到 201,返回新任务对象,包含 id、title 和 done:false。\n- 失败 1:发送 {} 并得到 400,返回类似 { \"error\": \"title is required\" }。\n- 失败 2:发送 { \"title\": \"x\" }(太短)并得到 422,返回 { \"error\": \"title must be at least 3 characters\" }。当 Claude Code 起草 OpenAPI 时,这个端点片段应捕获 schema、状态码和真实示例:
paths:
/tasks:
post:
summary: Create a task
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTaskRequest'
examples:
ok:
value: { "title": "Buy milk" }
responses:
'201':
description: Created
content:
application/json:
schema:
$ref: '#/components/schemas/Task'
examples:
created:
value: { "id": "t_123", "title": "Buy milk", "done": false }
'400':
description: Bad Request
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
missingTitle:
value: { "error": "title is required" }
'422':
description: Unprocessable Entity
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
tooShort:
value: { "error": "title must be at least 3 characters" }
一个常见的细微不匹配是:运行中的 API 返回了 200 而不是 201,或返回了 { "taskId": 123 } 而不是 { "id": "t_123" }。这类“看起来差不多”的差异会破坏使用规范生成的客户端。
通过选定一个真实的“事实来源”来修复它。如果期望行为是正确的,就把实现改为返回 201 并匹配约定的 Task 形状。如果生产行为已经被依赖,就更新规范(和行为说明)以匹配现实,然后补上缺失的校验和错误响应,免得客户端受惊。
当合同不再描述规则,而是描述 API 在某天某次请求中返回的内容时,它就不诚实了。一个简单的测试是:新的实现能否在不复制今天的怪癖的情况下通过这个规范?
一个陷阱是过拟合。你捕捉了一个响应并把它定为规则。例:现在的 API 对每个任务都返回 dueDate: null,于是规范写成该字段总是可空,但真实规则可能是“当 status 为 scheduled 时才必须有 dueDate”。合同应表达规则,而不是当前数据集的样貌。
错误处理是诚实度经常破裂的地方。只描述成功响应很诱人,因为它们看起来干净。但客户端需要基础的错误约定:缺少 token 返回 401,访问被拒绝返回 403,未知 ID 返回 404,以及一致的验证错误(400 或 422)。
其他导致问题的模式:
taskId,另一个用 id,或 priority 在某处为字符串在另一处为数字)。\n- 示例与 schema 相互矛盾(枚举值不匹配,日期时间示例不是 ISO 8601)。\n- 为避免决策,类型被放宽(所有字段都变成 string,所有字段都变成可选)。\n- 规范读起来像营销文案(“快速”、“安全”),而不是可测试的合同。一个好的合同是可以被测试的。如果你无法从规范写出一个会失败的测试,那它还不够诚实。
在把 OpenAPI 文件交给另一个团队(或粘到文档里)之前,做一次快速自问:别人能否不用读你思路就直接使用它?
从示例开始。一个规范即便有效也可能无用,如果每个请求和响应都抽象得看不清。对每个操作,至少包含一个现实的请求示例和一个成功响应示例。对于错误,常见失败(认证、验证)每种一个示例通常就够了。
然后检查一致性。如果一个端点返回 { "error": "..." } 而另一个返回 { "message": "..." },客户端会有分支逻辑。选一个错误形状并复用它,同时保持状态码可预测。
一个短清单:
一个实用技巧:挑一个端点,假装你从未见过该 API,回答“我发送什么、我收到什么、什么会出错?”如果 OpenAPI 不能清楚回答这些问题,那它还没准备好。
当这个工作流程成为常态而不是发布前的匆忙时,回报最大。定一个简单规则并坚持它:端点变更时运行此流程,发布前再运行一次。
保持所有权简单。改动端点的人负责更新行为说明和规范草案。第二个人像代码评审那样审查“规范与实现”的 diff。QA 或支持同事通常是很好的审阅者,因为他们能快速指出不清晰的响应和边缘情况。
把合同编辑当作代码编辑来处理。如果你使用基于聊天的构建工具(比如 Koder.ai),在高风险修改前做快照并在需要时回滚可以让迭代更安全。Koder.ai 还支持导出源代码,这让规范和实现能够并排保存在你的仓库中。
一个通常不会拖慢团队的常规流程:
下一步行动:挑一个已存在的端点。写 5-10 行行为说明(输入、输出、错误情况),从这些说明生成一个 OpenAPI 草稿,验证它,然后把它和运行中的实现做比对。修复一个不匹配,重新测试,然后重复。做完一个端点后,这个习惯往往就会坚持下去。
OpenAPI 漂移指的是你实际运行的 API 与团队共享的 OpenAPI 文件不再一致。规范可能缺少新字段、状态码或认证规则,也可能描述的是“理想”的行为,而服务器并不遵循。\n\n这很重要,因为客户端(应用、其他服务、生成的 SDK、测试)是基于合同而不是服务器“通常”做法来做出判断的。
客户端的故障变得随机且难以排查:移动端期待 201 却收到 200,SDK 无法反序列化响应因为字段被重命名,或是错误处理逻辑因为错误形状不同而失效。\n\n即便没有崩溃,团队也会逐渐失去对规范的信任,停止使用它,这样早期预警机制就不存在了。
因为代码反映的是当前行为,包括那些你可能不想长期承诺的偶然细节。\n\n更好的做法是:先写出期望行为(输入、输出、错误),然后验证实现是否符合。这会给你一个可执行的合同,而不是今天路由的快照。
每个端点至少记录:\n\n- 目的:一句话说明它的作用\n- 认证:是否需要 token/角色或公开访问\n- 请求:query/path 参数、头部,以及一个 JSON 请求体示例\n- 响应:至少一个成功示例和一到两个现实的错误示例并带状态码\n- 边缘情况:缺失/无效 ID、重复(409?)、空结果、分页上限\n\n如果你能写出一个具体请求和两个响应示例,通常就足够起草一个真实的规范了。
选一个错误体形状并在整个规范中复用。\n\n一个简单且常用的默认形式是:\n\n- { "error": "message" },或\n- { "error": { "code": "...", "message": "...", "details": ... } }\n\n在端点和示例中保持一致比过于复杂更重要,因为客户端会硬编码这个形状。
把你的行为说明给 Claude Code,并给出严格的规则,告诉它不要凭空生成字段。实用的说明包括:\n\n- “行为说明是唯一的真实来源。不要猜测。”\n- “如果不明确,在规范中添加 TODO 并在 ASSUMPTIONS 下列出。”\n- “包含可复用的 schema(如 Error)并引用它。”\n- “使用一致命名(PascalCase 的 schema,lowerCamelCase 的字段)。”\n\n生成后先审查 ASSUMPTIONS,那通常是漂移开始的地方,如果接受了模型的猜测就会出问题。
先验证规范本身:\n\n- 必填与可选字段是否正确\n- 格式是否明确(UUID、email、ISO 8601 date-time)\n- 示例是否与 schema 对齐(枚举、类型、可空性)\n- 状态码是否有意而为(例如创建通常用 201)\n- 每个端点的认证要求是否明确\n\n这能在你比较生产行为前先捕捉到“愿景式”的 OpenAPI 文件问题。
把运行中的 API 当作用户今天所体验到的行为,然后针对每一处差异作出决定:\n\n- 如果行为正确但未记录:更新规范\n- 如果规范是已达成的合同:修复代码以匹配规范\n- 如果两者都不对:先调整期望行为,然后更新两者\n\n保持改动小而可复审(一次一个端点或一个响应),这样可以快速重新测试。
服务端验证应在请求不符合合同时尽早拒绝,并返回清晰、一致的错误(状态 + 错误码/形状)。\n\n客户端验证应尽早检测返回形状的破坏性变化,断言你真正依赖的内容:\n\n- 必需字段存在且类型正确\n- 状态码匹配预期流程\n- 错误响应符合约定的形状\n\n避免断言每个可选字段,这样测试会在真正的破坏性变更时失败,而不是因为无害的新增字段而频繁报错。
一个可行的例行流程是:\n\n- 变更端点时更新行为说明与规范草案\n- 在合并前验证 OpenAPI 文件(schemas、示例、状态码、认证)\n- 发布前将一些真实的请求/响应样例与规范比对\n- 在测试中加入小型合同检查,这样漂移会被自动发现\n\n如果你在 Koder.ai 中开发,可以把 OpenAPI 文件和代码并存,风险修改前做快照,必要时回滚。