2025年10月23日·1 分钟
服务端与客户端过滤:决策检查表
服务端与客户端过滤决策检查表:根据数据量、延迟、权限和缓存来选择,避免 UI 泄露或卡顿。
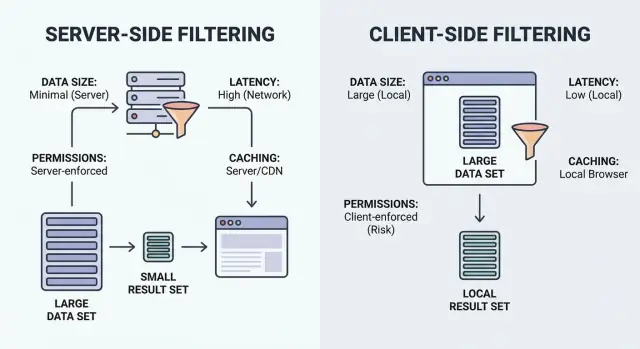
服务端与客户端过滤决策检查表:根据数据量、延迟、权限和缓存来选择,避免 UI 泄露或卡顿。
在 UI 中的过滤不只是一个搜索框。通常它包含几类相关动作,这些动作都会改变用户所见内容:文本搜索(姓名、邮箱、订单 ID)、面板(状态、所有者、日期范围、标签)和排序(最新、最高价值、最后活动)。
关键问题不是哪种技术“更好”,而是完整数据集存放在哪里,谁能访问它。如果浏览器接收了用户不该看到的记录,UI 即使视觉上隐藏了它们也会泄露敏感数据。
多数关于服务端 vs 客户端过滤的争论,实际上是对用户立刻能注意到的两类失败的反应:
还有第三个问题会制造无尽的 bug 报告:结果不一致。如果某些过滤在客户端运行而其他在服务端运行,用户会看到不匹配的计数、页面和总数。尤其在分页列表上,这会很快破坏信任。
一个实用的默认规则很简单:如果用户不被允许访问完整数据集,请在服务端过滤。如果允许并且数据集足够小可以快速加载,客户端过滤可以接受。
过滤就是“显示符合条件的项目”。关键是匹配在何处发生:在用户的浏览器(客户端)还是你的后端(服务端)。
客户端过滤 在浏览器运行。应用下载一组记录(通常是 JSON),然后在本地应用过滤。数据加载后它能感觉很快,但只有在数据集足够小并且对外暴露安全时才适用。
服务端过滤 在你的后端运行。浏览器发送过滤输入(比如 status=open、owner=me、createdAfter=Jan 1),服务器只返回匹配的结果。通常这是一个接受过滤参数的 API 端点,构建数据库查询并返回分页列表和总数。
一个简单的心智模型:
混合方案很常见。一个好的模式是把“重量级”过滤在服务端强制(权限、所有权、日期范围、搜索),再在本地用小的仅影响 UI 的切换(隐藏归档项、快速标签、列可见性)而不发起额外请求。
排序、分页和搜索通常也属于同一决策范畴。它们影响有效载荷大小、用户感受以及你暴露了哪些数据。
先问最实际的问题:如果在客户端过滤,你需要发送多少数据到浏览器?如果真实答案是“超过几屏内容”,你会在下载时间、内存使用和交互速度上付出代价。
你不需要精确估算。只要得到数量级:用户可能看到多少行,每行的平均大小是多少?500 条短字段的列表和 50,000 条包含长备注、富文本或嵌套对象的记录是完全不同的情况。
宽表记录是有效载荷的隐形杀手。按行数看表格可能很小,但如果每行包含很多字段、长字符串或关联数据(联系人 + 公司 + 最近活动 + 完整地址 + 标签),负载就会暴涨。即使 UI 只显示三列,团队也常常“把所有数据都发过去以防万一”,结果有效载荷爆炸。
还要考虑增长。今天还能接受的数据集,几个月后可能就难以承受。如果数据增长很快,把客户端过滤视为短期捷径,而不是默认选择。
经验法则:
最后一点不仅关乎性能:问自己“我们能把所有数据都发给浏览器吗?”这也是个安全问题。如果答案不是肯定的,请不要发送。
过滤选择往往在“感觉”上失败,而不是在正确性上。用户不会用毫秒来衡量,他们注意的是停顿、闪烁和在输入时结果跳动。
时间可以在不同环节消耗:
为该屏定义“够快”的标准。列表视图可能需要在输入时立即响应并流畅滚动,而报表页面只要首条结果迅速出现即可接受短等待。
不要只在办公室 Wi‑Fi 下评判。在慢速连接上,客户端过滤在首次加载后可能感觉很好,但首次加载本身可能很慢。服务端过滤保持有效载荷小,但如果你在每次按键都发请求,也会感觉卡顿。
围绕人的输入设计。对输入做防抖。对于大结果集,使用渐进加载(progressive loading),让页面快速显示一些内容并在用户滚动时保持流畅。
权限应比速度更决定你的过滤方式。如果浏览器收到用户不应看到的数据,即使 UI 隐藏了这些数据,你也已经出现问题。
先列出该屏幕上哪些内容是敏感的。一些字段显而易见(邮箱、电话、地址)。另一些容易被忽视:内部备注、成本或毛利、特殊定价规则、风险评分、审核标记。
最大陷阱是“我们在客户端过滤,但只显示允许的行”。这仍然意味着完整数据集被下载了。任何人都可以检查网络响应、打开开发者工具或保存有效载荷。仅仅在 UI 隐藏列并不是访问控制。
当授权因用户而异时,服务端过滤是更安全的默认:尤其是不同用户能看到不同的行或不同的字段时。
快速检查:
如果有任意一个答案是肯定的,就把过滤和字段选择放到服务端。只发送用户被允许看到的内容,并对搜索、排序、分页和导出应用相同规则。
举例:在 CRM 联系人列表中,业务代表只能看到自己的账户,经理可以查看全部。如果浏览器下载了所有联系人并在本地过滤,业务代表仍能从响应中恢复隐藏账户。服务端过滤通过从未发送那些行来防止这种情况。
缓存可以让界面感觉瞬时,也可能呈现错误的事实。关键在于决定哪些内容可以重用、多长时间,以及哪些事件必须清除缓存。
先选择缓存单元。缓存整个列表很简单但通常浪费带宽且容易过期。缓存分页对无限滚动有效。缓存查询结果(过滤 + 排序 + 搜索)准确,但如果用户尝试很多组合,缓存会膨胀。
在某些领域,新鲜度更重要。如果数据变化很快(库存、余额、配送状态),即便 30 秒缓存也会让用户困惑。如果数据变化慢(归档记录、参考数据),更长的缓存通常没问题。
在编写代码前规划失效策略。除了时间过期,还要决定哪些操作应强制刷新:创建/编辑/删除、权限变更、批量导入或合并、状态变更、回滚操作,以及后台任务更新了用户用来过滤的字段。
还要决定缓存放在哪里。浏览器内存能使前进/后退变快,但如果不按用户和组织键控,可能会在账户间泄露数据。后端缓存对权限和一致性更安全,但必须包含完整的过滤签名和调用者身份,避免不同权限的结果混合。
目标应不可妥协:界面在不泄露数据的前提下要感觉快速。
多数团队踩到相同的坑:演示时看起来很棒的 UI,在真实数据、真实权限和真实网络下就暴露出了问题。
最严重的失败是把过滤当成展示层处理。如果浏览器接收了不该有的记录,你已经失败。
两个常见原因:
示例:实习生只应看到其辖区的线索。如果 API 返回了所有区域而下拉在 React 中本地过滤,实习生仍能提取完整列表。
卡顿常常来自错误的假设:
一个微妙但痛苦的问题是规则不匹配。如果服务器和客户端对“前缀匹配”或大小写处理不同,用户会看到计数不一致或刷新后项目消失。
带着两种心态做最终检查:好奇的用户和网络不佳的那一天。
一个简单测试:创建一个受限记录并确认它在有效载荷、计数或缓存中永远不会出现,即便你广泛地过滤或清除过滤条件。
想象一个有 200,000 条联系人的 CRM。业务代表只能看到自己的账户,经理能看到其团队,管理员能看到全部。界面有搜索、过滤(状态、所有者、最近活动)和排序。
客户端过滤在这里会很快失败。有效载荷很大、首次加载变慢,且数据泄露风险高。即便 UI 隐藏了某些行,浏览器也接收了数据。你还会给设备施加压力:大型数组、繁重排序、重复过滤、高内存使用,旧手机可能崩溃。
更安全的做法是带分页的服务端过滤。客户端发送过滤选项和搜索文本,服务器只返回用户被允许看到的、已经过滤和排序后的行。
实用模式:
一个小例外是微小且静态的数据:一个包含 8 个值的“联系人状态”下拉可以一次性加载并在本地过滤,风险和成本都很小。
团队通常不是因为某次选择“错”一次而受苦,而是因为在每个屏做不同选择,然后在压力下修复泄露和慢页。
为每个屏写一份简短的决策说明:包含数据集大小、发送成本、什么程度算“够快”、哪些字段敏感、以及结果应如何缓存(或不缓存)。保持服务器和 UI 的一致,避免出现两个过滤“真相”。
如果你在 Koder.ai (koder.ai) 上快速构建屏幕,值得事先决定哪些过滤必须在后端执行(权限与行级访问),哪些小的仅限 UI 的切换可以留在 React 层。那一个决定往往能防止之后最昂贵的重写。
当用户权限不同、数据集很大,或需要一致的分页和总数时,默认使用服务端过滤。只有当完整数据集很小、对外暴露安全且下载速度快时,才考虑客户端过滤。
因为浏览器接收到的任何数据都可以被查看。即便界面隐藏了某些行或列,用户仍可在网络响应、缓存或内存对象中看到这些数据。
通常是因为你传输了过多数据,然后在每次按键时对大型数组进行过滤/排序,或者在每次按键都向服务端发送请求但没有防抖。保持有效载荷小,避免在每次输入改动时做繁重计算。
把“真实”过滤来源保持一致:权限、搜索、排序和分页应统一在服务器端执行。把客户端逻辑限制在不会改变底层数据集的小型 UI 切换项上。
客户端缓存容易显示陈旧或错误数据,且如果缓存键没有包含用户信息可能导致不同账号间的数据泄露。服务端缓存对权限更安全,但必须包含完整的过滤签名和调用者身份,防止结果混淆。
问两个问题:用户实际可能有多少行,以及每行大约多少字节。如果你不会在典型移动网络或旧设备上舒适地加载它,就把过滤放到服务端并使用分页。
服务端。如果角色、团队、区域或所有权规则会改变某人能看到的行或字段,服务器必须强制行级和字段级访问。客户端只应接收用户被允许查看的记录与字段。
先定义过滤和排序契约:允许的过滤字段、默认排序、分页规则,以及搜索如何匹配(大小写、重音、部分匹配)。然后在后端一致实现相同逻辑,并测试总数与分页是否匹配。
对输入进行防抖以避免每次按键都请求,并在新结果到来前保留旧结果以减少闪烁。使用分页或渐进加载,让用户快速看到部分结果,而不是等待大型响应完成。
先强制执行权限,然后再应用过滤和排序,返回单页结果和总数。避免发送“以防万一”的额外字段,并且确保缓存键包含用户/组织/角色,这样普通销售不可能收到经理的数据。