2025年6月12日·2 分钟
从用户故事到数据库模式:AI 指导的方法
学习一种实用方法,将用户故事、实体和工作流转成清晰的数据库模式,并了解 AI 推理如何帮助检查缺失项与规则。
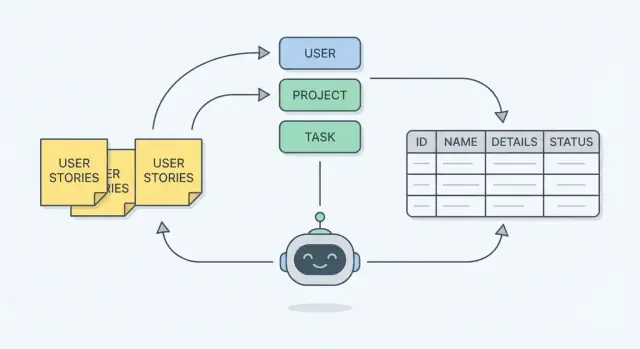
学习一种实用方法,将用户故事、实体和工作流转成清晰的数据库模式,并了解 AI 推理如何帮助检查缺失项与规则。
一个 数据库模式 是应用如何记住事物的计划。实操上,它包括:
当模式与真实工作匹配时,它反映人们实际做的事——创建、审核、批准、排程、分配、取消——而不是白板上听起来整洁的概念。
用户故事和验收标准用通俗语言描述真实需求:谁在做什么,以及“完成”意味着什么。如果以这些为来源,模式不太可能漏掉关键细节(比如“我们必须记录谁批准了退款”或“一次预订可以被多次重新安排”)。
从故事出发还能让你对范围保持诚实。如果故事(或工作流)里没有它,就把它当作可选,而不是偷偷构建复杂模型“以防万一”。
AI 可以帮助你更快地推进:
AI 不能可靠地做到:
把 AI 当作强力助理,而非最终决策者。
如果你想把这个助理变成执行力,像 Koder.ai 这样的 vibe-coding 平台可以帮助你更快地把模式决策变成一个可运行的 React + Go + PostgreSQL 应用——同时让你保持对模型、约束和迁移的控制。
模式设计是一个循环:草案 → 针对故事测试 → 发现缺失数据 → 细化。目标不是一次性完美输出,而是能将每张表追溯到特定用户故事并自信地说:“是的,我们可以存储这个工作流所需的一切——并且能解释每张表存在的理由。”
在把需求转成表之前,先弄清你在建模什么。一个好的模式很少从空白页开始——它始于人们实际做的具体工作,以及你以后需要的证明(屏幕、输出和边缘情况)。
用户故事是主线,但单靠它们不够。收集:
如果你使用 AI,这些输入能让模型不过度发明结构。AI 可以快速提出实体和字段,但需要真实工件来避免与产品不匹配的设计。
验收标准通常包含最重要的数据库规则,即使它们没有显式提到数据。寻找类似的陈述:
模糊的故事(“作为用户,我可以管理项目”)常常隐藏多个实体和工作流。另一个常见缺口是漏掉边缘情况,如取消、重试、部分退款或重新分配。
在考虑表或图表之前,读一遍用户故事并标出名词。在需求写作中,名词通常指向系统必须记住的“东西”——这些通常会成为你的实体。
一个简单的心理模型:名词成为实体,而动词成为操作或工作流。例如故事说 “A manager assigns a technician to a job”,很有可能的实体是 manager, technician, 和 job——而“assigns”暗示你以后要建模的关系。
并非每个名词都值得独立成表。当一个名词满足以下条件时,它就是实体的强候选:
如果一个名词只出现一次,或只是描述别的东西(“红色按钮”、“星期五”),它可能不是实体。
一个常见错误是把每个细节都做成表。用下面的经验法则:
两个经典示例:
AI 可以通过扫描故事来加速实体发现并返回按主题分组的候选名词(人员、工作项、文档、地点)。一个有用的提示是:“提取必须存储的数据的名词,并合并重复/同义词。”
把输出当作起点,不是最终答案。继续问:
第 1 步的目标是得出一个简短、干净的实体列表,并能通过指向真实故事来为其辩护。
一旦你命名了实体(如 Order, Customer, Ticket),下一步是捕捉以后会用到的细节。在数据库里,这些细节是字段(也叫属性)——系统不能忘记的提醒。
从用户故事开始,然后把验收标准当作必须存储的清单来读。
如果需求说 “Users can filter orders by delivery date”,那么 delivery_date 就不是可选的——它必须存在为字段(或能可靠地从其他存储的数据推导)。如果需求说 “Show who approved the request and when”,你可能需要 approved_by 和 approved_at。
一个实用测试:"有人需要用来显示、搜索、排序、审计或计算这个值吗?" 如果需要,它很可能应该是字段。
许多故事包含“status”、“type”或“priority”之类的词。把它们当作受控词汇——一组允许的有限值。
如果集合很小且稳定,简单的枚举(enum)字段可以胜任。若可能扩展、需要标签或需要权限(例如管理员管理的分类),使用单独的查找表(如 status_codes)并存储引用。
这是把故事转成可被信任字段的方式——可搜索、可报表、且不易输错。
列出实体(User、Order、Invoice、Comment 等)并起草它们的字段后,下一步是把它们连接起来。关系是故事暗含的“这些东西如何交互”的那一层。
一对一(1:1) 意味着“一个东西恰好有另一个东西的一个实例”。
User ↔ Profile(通常可以合并,除非有分离的理由)。一对多(1:N) 意味着“一个东西可以有很多另一种东西”。这是最常见的。
User → Order(在 Order 上存 user_id)。多对多(M:N) 意味着“多个东西可以互相关联”。需要额外的表。
数据库不能把“产品 ID 列表”整齐地存在 Order 里而不造成后患(查询、更新、报表难办)。相反,要建一个连接表来表示关系本身。
示例:
OrderProductOrderItem(连接表)OrderItem 通常包含:
order_idproduct_idquantity, unit_price, discount注意故事的细节(“数量”)往往属于关系本身,而不是任一实体。
故事还会告诉你某个连接是必须的还是有时不存在。
Order 需要 user_id(不可为空)。phone 可以为空。shipping_address_id 对数字产品可能为空。快速检查:如果故事暗示在创建记录时必须有这个关联,就把它设为必需;如果故事里用到“可以”/“可能”等词,就把它设为可选。
阅读故事时,把它改写为简单的配对句:
User 1:N CommentComment N:1 User为故事中每个交互做这件事。到最后,你会得到一个在建任何 ER 图工具前就与工作流程相匹配的连通模型。
用户故事告诉你人们想要什么。工作流则展示工作如何一步步流转。把工作流转成数据是发现“我们忘记存储某项信息”的最快方法之一——在你动手建之前就能发现问题。
把工作流写成动作和状态变化的序列。例如:
这些加粗词通常会成为一个 status 字段(或一个小的“状态”表),包含明确的允许值。
在逐步梳理每一步时,问:“以后我们需要知道什么?”工作流通常会揭示以下字段:
submitted_at, approved_at, completed_atcreated_by, assigned_to, approved_byrejection_reason, approval_notesequence如果工作流包括等待、升级或交接,通常至少需要一个时间戳和一个“当前由谁持有”的字段。
有些工作步骤不只是字段——它们是独立的数据结构:
同时给 AI 两类资料:(1)用户故事与验收标准;(2)工作流步骤。让它列出每一步需要的数据(状态、执行者、时间戳、输出),然后高亮当前字段/表无法支持的需求。
在像 Koder.ai 这样的工具里,这种“差距检查”尤其实用,因为你可以快速迭代:调整模式假设、重新生成脚手架,并快速继续,而不是陷入大量手工样板代码中。
把用户故事转成表时,你不仅是在列字段——你还在决定数据如何在时间里保持可识别和一致。
主键 唯一标识一条记录——把它想成该行的永久身份证。
为什么每行都需要一个:故事里暗示会有更新、引用和历史。如果故事说 “支持可以查看订单并发起退款”,你需要一个稳定的方式指向该订单——即便客户改了邮箱、地址被编辑或订单状态改变。
在实践中,这通常是一个内部的 id(数字或 UUID),且永不改变。
外键 是一张表安全地指向另一张表的方式。如果 orders.customer_id 引用 customers.id,数据库可以强制每个订单都属于真实存在的客户。
这对应类似“作为用户,我可以看到我的发票”的故事。发票不是漂浮的;它挂在客户(常常也挂在订单或订阅)下面。
用户故事经常包含隐藏的唯一性要求:
email 上强制唯一(或在多租户场景下按租户唯一)。invoice_number 唯一。这些规则能防止日后出现令人困惑的重复数据。
索引能加速“按邮箱查找客户”或“按客户列出订单”等查询。先从与你最常用查询和唯一性规则一致的索引开始。
需要推迟的:为罕见报表或推测性过滤加重索引。把这些需求记在故事里,先验证模式,再基于真实使用和慢查询证据做优化。
范式的唯一目标是避免冲突性重复。如果同一事实能被保存在两个地方,迟早会出现不一致(两个拼写、两种价格、两个“当前”地址)。规范化的模式把每个事实只存一次,然后引用它。
如果你看到像“Phone1、Phone2、Phone3”或“ItemA、ItemB、ItemC”这样的模式,那就是应该拆成单独表(例如 CustomerPhones, OrderItems)。重复组让搜索、验证和扩展都变难。
如果 CustomerName 出现在 Orders, Invoices, 和 Shipments,你就出了多个真相来源。把客户细节放在 Customers,其他地方只存 customer_id。
像 billing_address, shipping_address, home_address 在概念上可以,但如果你实际在建模“多地址及其类型”,就用 Addresses 表并加 type 字段。
如果用户从已知集合中选择(状态、类别、角色),保持一致建模:要么受限的枚举,要么查找表。这样能避免 “Pending” vs “pending” vs “PENDING”。
一个有用的直觉检验:在一张表里,如果某列描述的不是该表的主要实体,它很可能属于别的表。示例:除非它表示“下单时的价格快照”,否则 Orders 不应存 product_price。
有时你会故意保存重复:
关键是要有意为之:记录哪个字段是事实源,以及副本如何更新。
AI 能标出可疑重复(重复列、相似字段名、不一致的“status”字段)并建议拆成表。人类则根据产品的实际使用场景在简洁性、灵活性和性能间做取舍。
一个有用的规则:存储那些你无法可靠重建的事实;其他的都计算。
存储数据 是事实源:单行项目、时间戳、状态变更、谁做了什么。 计算数据 是从这些事实推导出的结果:总计、计数、像“is overdue”这样的标记,以及像“当前库存”的汇总。
如果两个值可以从相同的底层事实计算出来,优先存事实并计算其余部分。否则你会遇到矛盾。
派生值会在其输入改变时变化。如果你同时保存输入和派生结果,就必须在每条工作流和边界情况下保持它们同步(编辑、退款、部分发货、回溯更改)。一次遗漏更新,数据库就会讲两个不同的故事。
示例:既存 order_total 又存 order_items。如果有人改了数量或应用折扣而总价没被完美更新,财务看到一个数字,购物车显示另一个。
工作流会显示你何时需要历史真相,而不仅仅是“当前真相”。如果用户需要知道某个值“当时是什么”,就要存快照。
对于订单,你可能会存:
order_total(快照),因为税费、折扣和定价规则以后可能改变对于库存,“库存水平”通常由变动(入库、销售、调整)计算而来。但如果你需要审计轨迹,就存变动记录并可选地定期存储快照以提高报表速度。
对于登录追踪,保存 last_login_at 作为事实(事件时间戳)是合理的。“过去 30 天是否活跃?”这类问题仍然作为计算得出。
我们用一个熟悉的支持工单应用为例。从五条用户故事出发,得到一个简单的 ER 模型(实体 + 字段 + 关系),然后把它与一个工作流做对照。
由这些名词我们得出核心实体:
之前(常见遗漏):Ticket 有 assignee_id,但我们忘了确保只有客服(agent)可以被指派。
之后:AI 报告该问题,你可以增加一条实际规则:assignee 必须是 role = “agent” 的 User(通过应用层验证或数据库约束/策略来实现,视你的技术栈而定)。这能防止“把工单指派给客户”这类会破坏报表的数据。
只有当每条用户故事都能用你真实能存储并查询的数据回答时,模式才算“完成”。最简单的验证步骤是逐条拿起故事并问:
“我们能从数据库可靠地回答这个问题吗?如果不能,模型就有缺口。”
把每条用户故事改写为一个或多个测试问题——你期望报表、屏幕或 API 会提出的问题。例如:
如果你无法把故事表达为清晰问题,说明故事本身不清楚。如果能表达但模式无法回答,则缺少字段、关系、状态/事件或约束。
创建一个小数据集(关键表每张表 5–20 行),包含正常情况和棘手情况(重复、缺失、取消)。然后用这些数据“演练”故事。你会很快发现诸如“我们无法区分购买时使用的是哪个地址”或“我们没有地方存谁批准了变更”之类的问题。
让 AI 为每条故事生成验证问题(包括边缘情况和删除场景),并列出回答这些问题所需的数据。把这个列表与你的模式对照:任何不匹配都是一个具体的待办项,而不是一种模糊的“不对劲”感觉。
AI 能加快建模,但也会带来泄露敏感信息或把糟糕假设硬编码进去的风险。把它当作非常迅速的助理:有用,但需要护栏。
分享足够真实以便建模、但已脱敏以保证安全的输入:
invoice_total: 129.50, status: "paid")避免任何能识别个人或泄露机密运营的信息:
如果需要真实性,生成符合格式和范围的合成样本——绝不要复制生产行。
模式失败多数源于“每个人都默认了不同的理解”。在 ER 图旁(或同一仓库里)保留一个简短的决策日志:
这会把 AI 输出变成团队知识,而不是一次性的产物。
模式会随新故事演进。用下列方式保证安全:
如果你用像 Koder.ai 这样的工具,利用快照与回滚等护栏来迭代模式变更,并在需要更深层次定制或传统审查时导出源码。
从故事开始,找出那些表示系统必须记住的名词(例如 Ticket, User, Category)。
当一个名词满足下列条件时,可以提升为实体:
保持一个可以通过指向具体故事句子来证明的简短实体清单。
使用“属性 vs 实体”的判别法:
customer.phone_number),把它作为字段。一个快速提示:如果你可能需要“多个这样的项”,通常就需要另一张表。
把验收条件当作存储清单。如果某个需求需要过滤/排序/展示/审计某个内容,你必须存储它(或能可靠地从已有数据推导出来)。
示例:
approved_by, approved_atdelivery_dateemail 上添加唯一约束/索引把故事句子改写成关系句子:
orders 上放 customer_id)order_items)如果关系本身包含数据(数量、价格、角色),这些数据应该放在连接表上。
用一个连接表来建模 M:N,并在里面存两张表的外键以及关系专属字段。
典型模式:
ordersproductsorder_items,包含 , , , 逐步演练工作流并问:“后来我们要证明这一步发生过,需要什么信息?”
常见添加项:
submitted_at, closed_atcreated_by, assigned_to, 先从以下开始:
id)orders.customer_id → customers.id)然后为常用查找添加索引(如 , , )。把推测性的索引留到看见真实查询模式后再做。
运行一个快速的一致性检查:
Phone1/Phone2),拆成子表。只有在有明确理由(性能、报表、审计快照)时再去反规范化,并记录哪个字段是权威来源。
把那些无法可靠重建的事实存下来;其他的都计算得出。
适合存储的:
适合计算的:
如果决定存派生值(比如 ),要明确如何保持同步,并测试退款/编辑/部分发货等边界情况。
把 AI 当作起草和交叉检查的工具,然后根据你的工件验证结果。
实用提示:
防护措施:
order_idproduct_idquantityunit_price避免把“ID 列表”存成单个列——查询、更新和完整性维护会变得棘手。
closed_byrejection_reason如果你需要“谁何时更改了什么”,加一个事件/审计表,而不是覆盖单一字段。
emailcustomer_idstatus + created_atorder_total