02 thg 12, 2025·8 phút
Tầm nhìn AI ban đầu của Larry Page đằng sau chiến lược dài hạn của Google
Khám phá cách những ý tưởng ban đầu của Larry Page về AI và tri thức đã định hình chiến lược dài hạn của Google — từ chất lượng tìm kiếm tới các canh bạc moonshot và đặt cược AI-first.
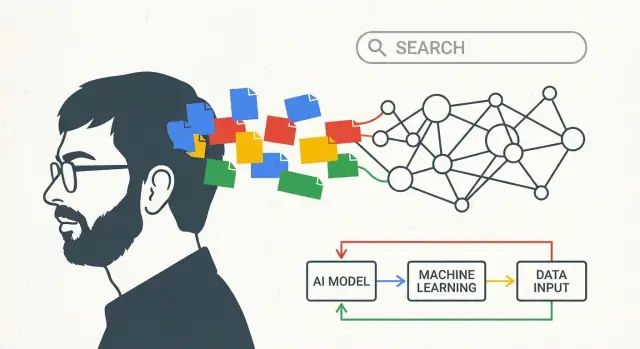
Điều bài viết này muốn nói về “tầm nhìn AI của Larry Page”
Đây không phải một bài thổi phồng về một khoảnh khắc đột phá duy nhất. Nó nói về tư duy dài hạn: cách một công ty có thể chọn một hướng sớm, tiếp tục đầu tư qua nhiều bước chuyển công nghệ, và từ từ biến một ý tưởng lớn thành sản phẩm hàng ngày.
Khi bài viết này nói “tầm nhìn AI của Larry Page,” nó không có nghĩa là “Google đã dự đoán chatbot hôm nay.” Nó có nghĩa điều đơn giản hơn — và bền vững hơn: xây dựng hệ thống học từ kinh nghiệm.
Định nghĩa bằng ngôn ngữ thông thường
Trong bài này, “tầm nhìn AI” ám chỉ vài niềm tin liên kết với nhau:
- Máy tính nên cải thiện hiệu năng bằng cách học từ dữ liệu, không chỉ làm theo các quy tắc viết tay.
- Hệ thống tốt nhất sẽ ngày càng tiến bộ vì việc sử dụng thực tế tạo ra phản hồi (người dùng bấm vào gì, họ bỏ qua gì, họ diễn đạt lại như thế nào).
- Để làm cho việc học khả thi, cần hạ tầng: tính toán nhanh, lưu trữ đáng tin cậy, và cách chạy thí nghiệm an toàn ở quy mô rất lớn.
Nói cách khác, “tầm nhìn” ít về một mô hình đơn lẻ hơn là về một động cơ: thu thập tín hiệu, học mẫu, phát hành cải tiến, lặp lại.
Mạch truyện chúng ta sẽ theo
Để làm rõ ý này, phần còn lại của bài lần theo một tiến trình đơn giản:
- Tìm kiếm: bắt đầu với một vấn đề rõ ràng — giúp người dùng tìm câu trả lời tốt.\
- Dữ liệu + hạ tầng: dùng việc sử dụng thực tế để học “tốt” là gì, và xây dựng máy móc xử lý chúng.\
- Sản phẩm AI-đầu tiên: xem hệ thống học như cách mặc định, để giọng nói, hình ảnh và giao diện mới có thể hoạt động tốt mà không phải viết lại mọi thứ từ đầu.
Đến cuối bài, “tầm nhìn AI của Larry Page” sẽ ít giống khẩu hiệu hơn và nhiều hơn là một chiến lược: đầu tư sớm vào hệ thống học, xây ống dẫn nuôi chúng, và kiên nhẫn để tiến triển tích lũy qua nhiều năm.
Vấn đề ban đầu Google cố giải quyết: tìm câu trả lời tốt
Web thời kỳ đầu có một vấn đề đơn giản nhưng hệ quả lộn xộn: bỗng dưng có quá nhiều thông tin để một người có thể lọc, và hầu hết công cụ tìm kiếm lúc đó cơ bản chỉ đoán điều gì quan trọng.
Nếu bạn gõ truy vấn, nhiều công cụ dựa vào các tín hiệu hiển nhiên — từ khóa xuất hiện bao nhiêu lần trên trang, có trong tiêu đề không, hoặc chủ sở hữu site nhồi từ vào văn bản ẩn thế nào. Điều đó khiến kết quả dễ bị khai thác và khó tin tưởng. Web phát triển nhanh hơn công cụ tổ chức nó.
PageRank, giải thích như một hệ đề xuất
Khác biệt then chốt của Larry Page và Sergey Brin là web đã có một hệ thống bỏ phiếu tích hợp: các liên kết.
Một liên kết từ trang này tới trang khác giống như trích dẫn trong bài báo hay một khuyến nghị từ bạn bè. Nhưng không phải khuyến nghị nào cũng giá trị như nhau. Một liên kết từ trang mà nhiều trang khác coi là giá trị nên được trọng hơn liên kết từ trang vô danh. PageRank biến ý tưởng đó thành toán học: thay vì xếp hạng trang chỉ bằng những gì trang đó tự viết về chính nó, Google xếp hạng trang bằng những gì phần còn lại của web “nói” thông qua liên kết.
Điều này cùng lúc làm hai việc quan trọng:
- Giúp đưa những trang có thẩm quyền lên dù họ không lặp lại chính xác từ truy vấn.\
- Làm cho việc thao túng thứ hạng khó hơn, vì độ tin cậy phải được kiếm từ mạng lưới site.
Tại sao đo lường và lặp lại quan trọng ngay từ đầu
Chỉ có một ý tưởng xếp hạng thông minh thôi thì chưa đủ. Chất lượng tìm kiếm là mục tiêu di động: trang mới xuất hiện, spam thay đổi, và ý người dùng về một truy vấn có thể thay đổi.
Vì vậy hệ thống phải có thể đo lường và cập nhật. Google dựa vào thử nghiệm liên tục — thử thay đổi, đo xem kết quả có tốt hơn không, rồi lặp lại. Thói quen lặp này định hình cách tiếp cận dài hạn đối với hệ thống “học”: coi tìm kiếm là thứ bạn có thể đánh giá liên tục, không phải một dự án kỹ thuật làm một lần.
Dữ liệu như bánh đà: học từ việc sử dụng thực tế
Tìm kiếm tốt không chỉ dựa vào thuật toán thông minh — mà còn phụ thuộc vào chất lượng và số lượng tín hiệu mà các thuật toán đó có thể học.
Google thời kỳ đầu có lợi thế sẵn có: chính web đầy “phiếu bầu” về điều gì quan trọng. Các liên kết giữa trang (nền tảng PageRank) hoạt như trích dẫn, và anchor text ("click here" vs. "best hiking boots") thêm ý nghĩa. Trên đó, mô hình ngôn ngữ trên nhiều trang giúp hệ thống hiểu từ đồng nghĩa, lỗi chính tả, và nhiều cách khác nhau người ta đặt cùng một câu hỏi.
Vòng phản hồi làm tăng quy mô
Khi người dùng bắt đầu dùng một công cụ tìm kiếm ở quy mô lớn, việc sử dụng tạo thêm các tín hiệu:
- Các lượt click cho thấy kết quả nào có vẻ phù hợp với người dùng thực cho một truy vấn.\
- “Click lâu” so với quay lại nhanh có thể gợi ý sự hài lòng.\
- Việc sửa truy vấn (tìm lại với từ khác) có thể tiết lộ sự không phù hợp giữa ý định và kết quả.
Đây là bánh đà: kết quả tốt hơn thu hút nhiều người dùng hơn; nhiều người dùng tạo tín hiệu phong phú hơn; tín hiệu phong phú cải thiện xếp hạng và hiểu biết; và cải tiến đó kéo thêm người dùng nữa. Theo thời gian, tìm kiếm bớt giống tập hợp quy tắc cố định và giống hệ thống học tự điều chỉnh theo những gì người dùng thực sự thấy hữu ích.
Tại sao đa dạng dữ liệu quan trọng
Các loại dữ liệu khác nhau hỗ trợ lẫn nhau. Cấu trúc liên kết có thể đưa ra thẩm quyền, trong khi hành vi click phản ánh sở thích hiện tại, và dữ liệu ngôn ngữ giúp giải nghĩa truy vấn mơ hồ (“jaguar” là động vật hay ô tô). Cùng nhau, chúng cho phép trả lời không chỉ “những trang nào chứa từ này,” mà là “câu trả lời tốt nhất cho ý định này là gì.”
Ghi chú về quyền riêng tư
Bánh đà này gợi ra câu hỏi quyền riêng tư rõ ràng. Báo cáo công khai đã ghi nhận rằng các sản phẩm tiêu dùng lớn tạo ra dữ liệu tương tác khổng lồ, và các công ty dùng tín hiệu tổng hợp để nâng cao chất lượng. Cũng có ghi nhận rằng Google đã đầu tư vào kiểm soát quyền riêng tư và bảo mật theo thời gian, mặc dù chi tiết và hiệu quả vẫn là chủ đề tranh luận.
Điều rút ra đơn giản: học từ sử dụng thực tế rất mạnh — và lòng tin phụ thuộc vào cách học đó được xử lý có trách nhiệm hay không.
Xây “cỗ máy”: hạ tầng giúp AI trở nên khả dụng
Google không đầu tư sớm vào điện toán phân tán vì đó là trào lưu — mà vì đó là cách duy nhất để theo kịp quy mô lộn xộn của web. Nếu muốn crawl hàng tỷ trang, cập nhật thứ hạng thường xuyên, và trả lời truy vấn trong vài phần nghìn giây, bạn không thể dựa vào một máy tính lớn duy nhất. Cần hàng nghìn máy rẻ hơn cùng làm việc, với phần mềm coi sự cố là bình thường.
Tại sao điện toán phân tán quan trọng từ sớm
Tìm kiếm buộc Google phải xây hệ thống có thể lưu trữ và xử lý lượng dữ liệu khổng lồ một cách đáng tin cậy. Cách tiếp cận “nhiều máy, một hệ thống” đó trở thành nền tảng cho mọi thứ tiếp theo: lập chỉ mục, phân tích, thí nghiệm, và cuối cùng là học máy.
Sự hiểu trọng điểm là hạ tầng không tách rời khỏi AI — nó quyết định loại mô hình nào khả thi.
Hạ tầng biến AI từ bản demo thành sản phẩm như thế nào
Huấn luyện một mô hình hữu ích nghĩa là cho nó nhiều ví dụ thực. Phục vụ mô hình nghĩa là chạy nó cho hàng triệu người, ngay lập tức, không bị gián đoạn. Cả hai đều là “vấn đề quy mô”:
- Huấn luyện cần compute khổng lồ để xử lý dữ liệu lặp đi lặp lại.\
- Phục vụ cần hệ thống độ trễ thấp để đưa dự đoán nhanh (thường trong mili giây), ngay cả khi lưu lượng tăng đột biến.
Khi bạn xây được pipeline lưu trữ dữ liệu, phân phối tính toán, giám sát hiệu năng, và triển khai cập nhật an toàn, hệ thống dựa trên học có thể cải thiện liên tục chứ không chỉ xuất hiện như các lần viết lại hiếm hoi và rủi ro.
Ví dụ đơn giản hàng ngày về “AI nhờ có ống dẫn”
Một vài tính năng quen thuộc cho thấy vì sao cỗ máy quan trọng:
- Sửa lỗi chính tả: nhận ra mẫu như “restarant” → “restaurant” cần học từ nhiều truy vấn và click, rồi áp dụng sửa ngay thời điểm truy vấn.\
- Gợi ý hoàn thành: dự đoán bạn sắp gõ gì dựa trên hành vi tổng hợp và suy luận nhanh — nếu không thì gợi ý sẽ chậm và sai.\
- Dịch: chất lượng dịch tốt hơn đến từ huấn luyện trên bộ dữ liệu lớn và triển khai mô hình có thể chạy nhanh cho người dùng toàn cầu.
Ưu thế dài hạn của Google không chỉ là có thuật toán hay — mà là xây dựng động cơ vận hành cho phép thuật toán học, triển khai và cải tiến ở quy mô Internet.
Từ quy tắc sang học: tìm kiếm âm thầm trở nên giống “AI” hơn
Kéo dài ngân sách xây dựng
Kéo dài ngân sách build bằng cách kiếm credit khi chia sẻ sản phẩm bạn xây hoặc giới thiệu người khác đến Koder.ai.
Google lúc đầu đã trông “thông minh,” nhưng phần lớn trí tuệ đó là kỹ thuật: phân tích liên kết (PageRank), tín hiệu xếp hạng tinh chỉnh bằng tay, và nhiều heuristics chống spam. Theo thời gian, trọng tâm dịch chuyển từ quy tắc viết tay sang hệ thống học các mẫu từ dữ liệu — đặc biệt là về ý định người dùng, không chỉ những gì họ gõ.
ML thay đổi cảm nhận về tìm kiếm như thế nào
Học máy dần cải thiện ba điều người dùng thường nhận thấy:
- Chất lượng xếp hạng: thay vì gán trọng số cho tín hiệu bằng công thức cố định, mô hình học tổ hợp tín hiệu nào thường làm hài lòng người dùng (đo bằng hành vi tổng hợp ẩn danh và phản hồi từ người đánh giá chất lượng).\
- Hiểu ý định: các truy vấn như “jaguar speed” hay “apple support” buộc mô hình suy ra nghĩa, ngữ cảnh, và sự mơ hồ. Hệ thống học giúp ánh xạ từ ngữ tới khái niệm và mục tiêu có khả năng.\
- Spam và độ tin cậy: khi trang nhồi nhét nội dung và SEO thao túng tăng, ML giúp phát hiện mẫu liên kết bất thường, nội dung mỏng, và thủ thuật khác — hỗ trợ nỗ lực rộng hơn hướng tới kết quả chất lượng cao.
Mốc thời gian dễ hiểu cho độc giả
- 1998: PageRank và bài báo gốc của Page & Brin đặt nền tảng cho mức độ liên quan thông qua liên kết.\
- Đầu những năm 2000: sửa chính tả thống kê và gợi ý truy vấn cải thiện “bạn có ý nói” và việc sửa truy vấn.\
- 2011: Panda nhắm tới nội dung chất lượng thấp; tín hiệu chất lượng trở nên hệ thống hơn.\
- 2012: Penguin xử phạt thao túng liên kết, đẩy chống spam vượt ra khỏi quy tắc thủ công.\
- 2015: RankBrain (thành phần xếp hạng dựa trên học) giúp xử lý truy vấn lạ hoặc mơ hồ.\
- 2018–2019: neural matching và BERT nâng cao hiểu ngôn ngữ, đặc biệt cho truy vấn dài và giới từ.\
- 2021+: kỷ nguyên MUM với mô hình đa nhiệm và nỗ lực “nội dung hữu ích” hướng tới hiểu sâu hơn về ý định và tính hữu dụng.
Nguồn nên tham khảo
Để tăng độ tin cậy, trích dẫn hòa trộn giữa nghiên cứu gốc và giải thích sản phẩm công khai:
- Bài nghiên cứu: Brin & Page (PageRank, 1998), BERT (Devlin et al., 2018).\
- Thông báo chính thức về tìm kiếm: các bài trên blog Google Search về RankBrain, BERT, MUM, cập nhật Panda/Penguin.\
- Bài nói/phỏng vấn/sự kiện: phỏng vấn Amit Singhal về tiến hóa xếp hạng; bài phát biểu của Sundar Pichai (Google I/O); các sự kiện “Search On” cho các mốc hiện đại.
Văn hóa nghiên cứu: biến những canh bạc dài thành hệ thống hữu dụng
Chiến lược dài hạn của Google không chỉ là có ý tưởng lớn — nó phụ thuộc vào văn hóa nghiên cứu có thể biến các bài báo học thuật thành thứ hàng triệu người thật sự dùng. Điều đó nghĩa là khuyến khích tò mò, nhưng cũng xây đường dẫn từ nguyên mẫu tới sản phẩm đáng tin cậy.
Từ “xuất bản” đến “triển khai”
Nhiều công ty coi nghiên cứu như một hòn đảo riêng. Google thúc đẩy vòng lặp chặt hơn: nhà nghiên cứu có thể khám phá hướng táo bạo, xuất bản kết quả, và vẫn hợp tác với đội sản phẩm quan tâm đến độ trễ, độ tin cậy và niềm tin người dùng. Khi vòng lặp hoạt động, một bài báo không phải điểm dừng — nó là khởi đầu cho hệ thống tốt hơn, nhanh hơn.
Cách thấy rõ điều này là các ý tưởng mô hình xuất hiện dưới dạng các tính năng “nhỏ”: sửa chính tả tốt hơn, xếp hạng thông minh hơn, gợi ý cải tiến, hoặc dịch nghe tự nhiên hơn. Mỗi bước trông có vẻ nhỏ, nhưng cộng lại chúng thay đổi cảm nhận về “tìm kiếm.”
Nỗ lực tiêu biểu định hướng tiến độ
Một số nỗ lực trở thành biểu tượng của đường ống từ bài báo tới sản phẩm. Google Brain thúc đẩy deep learning trong công ty bằng cách chứng minh nó có thể vượt cách tiếp cận cũ khi có đủ dữ liệu và compute. Sau đó, TensorFlow giúp các đội dễ huấn luyện và triển khai mô hình nhất quán — một thành phần thô nhưng quan trọng để nhân rộng học máy qua nhiều sản phẩm.
Nghiên cứu về dịch máy neural, nhận dạng giọng nói và thị giác máy cũng chuyển từ phòng thí nghiệm thành trải nghiệm hàng ngày, thường sau nhiều vòng lặp cải thiện chất lượng và giảm chi phí.
Tại sao kiên nhẫn quan trọng
Đường cong lợi ích hiếm khi ngay lập tức. Phiên bản đầu có thể đắt, sai nhiều, hoặc khó tích hợp. Lợi thế đến từ việc kiên trì đủ lâu để xây hạ tầng, thu phản hồi, và tinh chỉnh mô hình cho đến khi nó đáng tin cậy. Sự kiên nhẫn — tài trợ “canh bạc dài,” chấp nhận đường vòng, và lặp đi lặp lại nhiều năm — giúp chuyển các khái niệm AI táo bạo thành hệ thống hữu dụng mà mọi người có thể tin tưởng ở quy mô Google.
Đầu vào mới: giọng nói, hình ảnh và video buộc mô hình phải thông minh hơn
Tìm kiếm văn bản cho phép thủ thuật xếp hạng. Nhưng khi Google bắt đầu xử lý giọng nói, ảnh, và video, cách tiếp cận cũ bộc lộ rõ giới hạn. Những đầu vào này lộn xộn: giọng điệu, tiếng ồn nền, ảnh mờ, video rung, tiếng lóng, và ngữ cảnh không được viết ra. Để khiến chúng hữu ích, Google cần hệ thống học các mẫu từ dữ liệu thay vì dựa vào quy tắc viết tay.
Giọng nói: biến âm thanh thành ý định
Với tìm kiếm bằng giọng nói và gõ bằng giọng nói trên Android, mục tiêu không chỉ là “chép chính xác từ.” Mà là hiểu người nói muốn gì — nhanh, trên thiết bị hoặc qua kết nối yếu.
Nhận dạng giọng nói thúc đẩy Google theo hướng học máy quy mô lớn vì hiệu năng cải thiện nhất khi mô hình được huấn luyện trên bộ dữ liệu âm thanh lớn và đa dạng. Áp lực sản phẩm đó biện minh cho đầu tư mạnh vào compute (để huấn luyện), công cụ chuyên dụng (pipeline dữ liệu, tập đánh giá, hệ thống triển khai), và tuyển người có thể lặp trên mô hình như sản phẩm sống — không phải demo nghiên cứu một lần.
Ảnh: ý nghĩa chứ không phải metadata
Ảnh không kèm từ khoá. Người dùng mong Google Photos tìm được “chó,” “bãi biển,” hoặc “chuyến đi Paris của tôi,” ngay cả khi họ không gắn thẻ gì.
Kỳ vọng đó buộc phải hiểu ảnh mạnh hơn: phát hiện đối tượng, nhóm khuôn mặt, và tìm kiếm tương đồng. Lại một lần nữa, quy tắc không che phủ được sự đa dạng của đời thực, nên hệ thống học trở thành con đường thực tế. Cải thiện độ chính xác cần nhiều dữ liệu gán nhãn hơn, hạ tầng huấn luyện tốt hơn, và chu kỳ thí nghiệm nhanh hơn.
Video và đề xuất: quy mô phơi bày điểm yếu
Video thêm một thách thức kép: đó là chuỗi ảnh theo thời gian cộng âm thanh. Giúp người dùng điều hướng YouTube — tìm kiếm, phụ đề, “Tiếp theo,” và bộ lọc an toàn — đòi hỏi mô hình tổng quát qua chủ đề và ngôn ngữ.
Đề xuất làm rõ hơn nhu cầu ML. Khi hàng tỷ người click, xem, bỏ qua và quay lại, hệ thống phải tự thích nghi liên tục. Vòng phản hồi đó tự nhiên thưởng cho đầu tư vào huấn luyện có quy mô, chỉ số và nhân lực để giữ mô hình cải tiến mà không làm mất niềm tin.
Chuyển sang AI-first: xem AI như mặc định chứ không phải tính năng
Vận hành vòng học nhanh
Tạo một MVP web hoặc backend từ chat, sau đó thêm vòng phản hồi để học hỏi từ người dùng.
“AI-first” dễ hiểu nhất như một quyết định sản phẩm: thay vì thêm AI như công cụ phụ, bạn coi nó là bộ động cơ bên trong mọi thứ người dùng đã dùng. Google mô tả hướng này công khai khoảng 2016–2017, chuyển từ “mobile-first” sang “AI-first.” Ý tưởng không phải mọi tính năng bỗng trở nên “thông minh,” mà là cách mặc định để sản phẩm cải tiến sẽ ngày càng là hệ thống học — xếp hạng, đề xuất, nhận dạng giọng nói, dịch, và phát hiện spam — chứ không phải quy tắc tinh chỉnh thủ công.
AI nằm trong vòng lõi
Về mặt thực tế, cách tiếp cận AI-first xuất hiện khi “vòng lõi” của sản phẩm âm thầm thay đổi:
- Kết quả tìm kiếm tốt hơn vì hệ thống học mẫu trong truy vấn và click, không phải vì đội viết tay hàng nghìn if-then.\
- Ảnh được tổ chức theo nội dung chứ không chỉ tên tập tin và thư mục.\
- Gmail chặn nhiều thư không mong muốn hơn bằng cách học hành vi thay đổi, không chỉ khớp từ khoá đã biết.
Người dùng có thể không thấy nút nào mang tên “AI.” Họ chỉ nhận ra ít kết quả sai hơn, ít ma sát và trả lời nhanh hơn.
Trợ lý nâng tiêu chuẩn ngôn ngữ tự nhiên
Trợ lý giọng nói và giao diện hội thoại làm thay đổi kỳ vọng. Khi người ta có thể nói, “Nhắc mình gọi mẹ khi về nhà,” họ bắt đầu mong phần mềm hiểu ý định, bối cảnh và ngôn ngữ đời thường lộn xộn.
Điều đó thúc đẩy sản phẩm coi hiểu ngôn ngữ tự nhiên là năng lực cơ bản — cả với giọng nói, gõ và thậm chí là input từ camera (chỉ điện thoại vào vật gì đó và hỏi đó là gì). Cú chuyển, do đó, vừa là đáp ứng thói quen mới của người dùng vừa là tham vọng nghiên cứu.
Quan trọng là, “AI-first” nên đọc như một hướng đi — được hỗ trợ bởi các tuyên bố và bước đi công khai lặp lại — hơn là khẳng định AI thay thế mọi cách tiếp cận ngay lập tức.
Alphabet và cuộc chơi dài: không gian cho những canh bạc vượt tìm kiếm
Việc thành lập Alphabet năm 2015 không chỉ là đổi tên mà là quyết định vận hành: tách lõi đã ổn định doanh thu (Google) khỏi những nỗ lực rủi ro thời hạn dài (thường gọi là “Other Bets”). Cấu trúc đó quan trọng nếu bạn nghĩ về tầm nhìn AI của Larry Page như một dự án nhiều thập kỷ, không chỉ một chu kỳ sản phẩm.
Tại sao tách “lõi” khỏi “canh bạc”
Google Search, Ads, YouTube và Android cần thực thi liên tục: độ tin cậy, kiểm soát chi phí và lặp nhanh. Các moonshot — xe tự lái, khoa học đời sống, dự án kết nối — cần thứ khác: chịu được bất định, chỗ cho thí nghiệm tốn kém, và cho phép sai lầm.
Dưới Alphabet, lõi có thể quản lý với kỳ vọng hiệu suất rõ ràng, trong khi các canh bạc được đánh giá bằng các cột mốc học hỏi: “Chúng ta đã chứng minh giả thiết kỹ thuật chính chưa?” “Mô hình có cải thiện đủ khi có dữ liệu thực không?” “Vấn đề có giải quyết được ở mức an toàn chấp nhận được không?”
Lý lẽ moonshot: thí nghiệm như chiến lược
Tư duy “chơi dài” này không giả định mọi dự án đều thành công. Nó giả định rằng thí nghiệm bền bỉ là cách bạn khám phá điều gì sẽ quan trọng sau này.
Một xưởng moonshot như X là ví dụ điển hình: các đội thử giả thuyết táo bạo, đo lường kết quả, và dừng ý tưởng nhanh khi bằng chứng yếu. Kỷ luật đó đặc biệt liên quan đến AI, nơi tiến bộ thường phụ thuộc vào lặp lại — dữ liệu tốt hơn, thiết lập huấn luyện tốt hơn, đánh giá tốt hơn — chứ không chỉ một đột phá duy nhất.
Điều cần rút ra (không kèm lời hứa)
Alphabet không đảm bảo chiến thắng tương lai. Nó là cách bảo vệ hai nhịp công việc khác nhau:
- Giữ lõi kinh doanh tập trung và có trách nhiệm.\
- Tạo nơi rõ ràng cho nghiên cứu và canh bạc độ biến động cao.
Với các đội, bài học là cấu trúc: nếu muốn kết quả AI dài hạn, hãy thiết kế cho nó. Tách giao hàng ngắn hạn khỏi công việc khám phá, cấp vốn thí nghiệm như phương tiện học, và đo tiến trình bằng insight đã được xác thực — không chỉ tiêu đề báo.
Những phần khó: chất lượng, an toàn và niềm tin ở quy mô lớn
Ra mắt theo từng lát
Xác thực một lời hứa rõ ràng dành cho người dùng bằng một bản phát hành nhỏ và cập nhật nhanh.
Khi hệ thống AI phục vụ hàng tỷ truy vấn, tỉ lệ lỗi nhỏ trở thành tin nổi bật hàng ngày. Một mô hình “đa số đúng” vẫn có thể gây hiểu lầm cho hàng triệu người — đặc biệt trong các lĩnh vực y tế, tài chính, bầu cử hoặc tin nóng. Ở quy mô Google, chất lượng không phải điều tùy chọn; đó là trách nhiệm cộng dồn.
Các cân bằng cốt lõi
Thiên kiến và đại diện. Mô hình học từ dữ liệu, bao gồm thiên kiến xã hội và lịch sử. Xếp hạng “trung lập” vẫn có thể khuếch đại quan điểm thống trị hoặc phục vụ kém các ngôn ngữ, vùng miền thiểu số.
Sai lầm và sự tự tin quá mức. AI thường thất bại theo cách nghe có vẻ thuyết phục. Sai lầm gây hại nhất không phải là lỗi hiển nhiên; là những câu trả lời có vẻ hợp lý mà người dùng tin.
An toàn vs. tính hữu dụng. Bộ lọc mạnh giảm hại nhưng có thể chặn truy vấn hợp lệ. Bộ lọc yếu tăng phạm vi nhưng làm tăng rủi ro lừa đảo, tự làm hại, hoặc sai lệch thông tin.
Trách nhiệm giải trình. Khi hệ thống tự động hóa nhiều hơn, câu hỏi trở nên khó trả lời: Ai phê duyệt hành vi này? Nó được kiểm tra thế nào? Người dùng kháng nghị hoặc sửa lỗi ra sao?
Tại sao quy mô làm tăng nhu cầu về biện pháp bảo vệ
Quy mô cải thiện khả năng, nhưng cũng:
- Mở rộng các trường hợp méo (ngôn ngữ, văn hoá, ngữ cảnh nhạy cảm).\
- Tăng động lực cho lạm dụng (spam, prompt injection, SEO đối kháng).\
- Làm cho lỗi khó lùi lại khi đã tích hợp rộng rãi qua sản phẩm.
Vì vậy biện pháp bảo vệ cũng phải mở rộng: bộ đánh giá, red-teaming, thực thi chính sách, nguồn gốc cho nguồn thông tin, và giao diện người dùng rõ ràng báo hiệu sự không chắc chắn.
Danh sách kiểm tra thực tế để đánh giá các khẳng định AI
Dùng bộ này để đánh giá bất cứ tính năng “AI-powered” nào — dù từ Google hay ai khác:
- Chế độ lỗi là gì? Họ có cho thấy nơi nó sai, không chỉ demo?\
- Nó được đo thế nào? Tìm các chỉ số thực (độ chính xác, tỉ lệ độc hại, tỉ lệ ảo tưởng), không phải các “cải thiện” mơ hồ.\
- Dữ liệu huấn luyện là gì? Ít nhất: danh mục rộng, tính cập nhật, và chính sách loại trừ.\
- Biện pháp bảo vệ là gì? Quy tắc an toàn, đường dẫn xem xét con người, và giám sát lạm dụng.\
- Người dùng có thể kiểm chứng không? Trích dẫn, văn bản hiển thị, hoặc giải thích để bạn kiểm tra tuyên bố.\
- Sửa lỗi được xử lý thế nào? Báo cáo rõ ràng, cập nhật nhanh và khả năng kiểm toán.
Niềm tin được xây bằng quy trình lặp lại — không phải một mô hình đột phá duy nhất.
Bài học cho các đội: cách nghĩ dài hạn về AI
Mẫu chuyển giao nhất đằng sau đường dài của Google rất đơn giản: mục tiêu rõ → dữ liệu → hạ tầng → lặp lại. Bạn không cần quy mô của Google để sử dụng vòng lặp — bạn cần kỷ luật về điều mình tối ưu, và cách học từ việc dùng thực mà không tự lừa mình.
Mẫu cốt lõi bạn có thể sao chép
Bắt đầu với một lời hứa người dùng có thể đo được (tốc độ, ít lỗi hơn, khớp tốt hơn). Ghi số liệu để quan sát kết quả. Xây máy tối thiểu cho phép bạn thu thập, gán nhãn và phát hành cải tiến an toàn. Rồi lặp bằng các bước nhỏ, thường xuyên — coi mỗi bản phát hành là cơ hội học.
Nếu cổ chai của bạn là đi từ “ý tưởng” đến “sản phẩm có đo lường” đủ nhanh, quy trình xây dựng hiện nay có thể giúp. Ví dụ, Koder.ai là nền tảng vibe-coding nơi đội có thể tạo web, backend hoặc app di động từ giao diện chat — hữu ích để dựng MVP có vòng phản hồi (like/dislike, báo lỗi, khảo sát nhanh) mà không chờ tuần cho pipeline tùy chỉnh. Những tính năng như chế độ lập kế hoạch cùng snapshot/rollback cũng khớp với nguyên tắc “thí nghiệm an toàn, đo lường, lặp lại.”
6 điều lãnh đạo có thể áp dụng (không cần Google)
- Chọn một ngôi sao hướng dẫn rõ ràng. “Cải thiện trải nghiệm tìm kiếm” rõ ràng hơn “áp dụng AI.” Định nghĩa thành công bằng cảm nhận người dùng.\
- Thiết kế sản phẩm để tạo dữ liệu học. Thêm vòng phản hồi (thumbs up/down, sửa, “cái này có giúp không?”) ghi lại ý định, không chỉ click.\
- Đầu tư sớm vào ống dẫn, không chỉ mô hình. Kiểm tra chất lượng dữ liệu, dashboard đánh giá, và workflow triển khai đánh bại nguyên mẫu một lần rồi bỏ.\
- Xem đánh giá như tính năng sản phẩm. Tạo bảng điểm lặp lại (chất lượng, độ trễ, chi phí, an toàn) để lặp không thành phỏng đoán.\
- Phát hành theo lát. Bắt đầu với trường hợp hẹp, tung cho nhóm nhỏ, đo, rồi mở rộng. Đà tốt hơn tung ra một lần lớn.\
- Giữ cho canh bạc dài sống được. Dành một phần nhỏ nguồn lực cho thí nghiệm, nhưng yêu cầu cột mốc học rõ ràng để giữ chúng có trách nhiệm.
Tài liệu liên quan
Nếu muốn bước tiếp thực tế, đưa các đầu mục này vào danh sách đọc của đội:
- /blog/ai-strategy-basics\
- /blog/data-flywheels-for-product-teams\
- /blog/evaluating-ml-models-without-a-phd\
- /blog/ai-governance-lightweight