17 thg 12, 2025·8 phút
Pooling kết nối PostgreSQL: pool trong ứng dụng vs PgBouncer
Pooling kết nối PostgreSQL: so sánh pool trong ứng dụng và PgBouncer cho backend Go, số liệu cần theo dõi, và các cấu hình sai gây đột biến độ trễ.
Pooling kết nối PostgreSQL: so sánh pool trong ứng dụng và PgBouncer cho backend Go, số liệu cần theo dõi, và các cấu hình sai gây đột biến độ trễ.
Một kết nối cơ sở dữ liệu giống như một đường điện thoại giữa app của bạn và Postgres. Mở một kết nối tốn thời gian và tài nguyên ở cả hai bên: thiết lập TCP/TLS, xác thực, bộ nhớ, và một tiến trình backend ở phía Postgres. Một connection pool giữ một tập nhỏ các “đường điện thoại” này luôn mở để app có thể tái sử dụng thay vì phải gọi lại cho mỗi yêu cầu.
Khi không dùng pooling hoặc cấu hình sai kích thước, bạn hiếm khi thấy lỗi rõ ràng trước. Bạn thấy chậm ngẫu nhiên. Những yêu cầu thường mất 20–50 ms bỗng nhiên kéo lên 500 ms hoặc vài giây, và p95 tăng vọt. Rồi timeout xuất hiện, tiếp theo là “too many connections”, hoặc một hàng đợi trong app khi nó chờ một kết nối rảnh.
Giới hạn kết nối quan trọng ngay cả với app nhỏ vì lưu lượng có tính nhấp nhô. Một email marketing, một cron job, hoặc vài endpoint chậm có thể khiến hàng chục yêu cầu cùng lúc chạm đến database. Nếu mỗi yêu cầu mở một kết nối mới, Postgres có thể tiêu tốn nhiều tài nguyên chỉ để chấp nhận và quản lý kết nối thay vì chạy truy vấn. Nếu bạn đã có pool nhưng nó quá lớn, bạn có thể làm quá tải Postgres với quá nhiều backend đang hoạt động và gây ra chuyển đổi ngữ cảnh và áp lực bộ nhớ.
Để ý các triệu chứng ban đầu như:
Pooling giảm churn kết nối và giúp Postgres xử lý các đợt nhấp nhô. Nó không sửa truy vấn chậm. Nếu một truy vấn đang quét toàn bộ bảng hoặc chờ lock, pooling chủ yếu thay đổi cách hệ thống thất bại (hàng đợi sớm hơn, timeout muộn hơn), chứ không làm cho nó nhanh hơn.
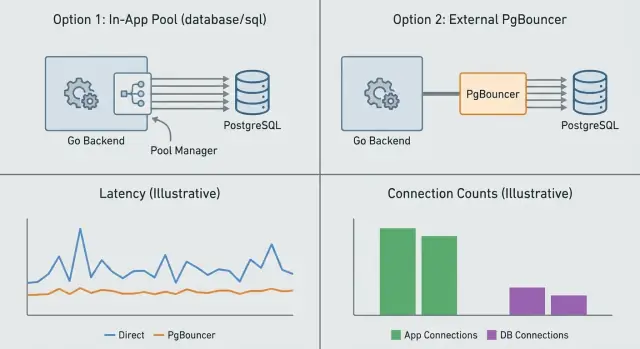
Connection pooling là kiểm soát có bao nhiêu kết nối cơ sở dữ liệu tồn tại cùng lúc và cách chúng được tái sử dụng. Bạn có thể làm việc này bên trong ứng dụng (app-level pooling) hoặc bằng một dịch vụ riêng nằm trước Postgres (PgBouncer). Chúng giải quyết các vấn đề liên quan nhưng khác nhau.
Pooling cấp ứng dụng (trong Go, thường là pool tích hợp database/sql) quản lý kết nối theo tiến trình. Nó quyết định khi nào mở kết nối mới, khi nào tái sử dụng, và khi nào đóng các kết nối không dùng. Điều nó không thể làm là phối hợp giữa nhiều bản sao ứng dụng. Nếu bạn chạy 10 replica, bạn thực sự có 10 pool riêng biệt.
PgBouncer ngồi giữa app và Postgres và pool thay cho nhiều client. Nó hữu ích nhất khi bạn có nhiều yêu cầu ngắn hạn, nhiều instance app, hoặc lưu lượng nhấp nhô. Nó giới hạn số kết nối server tới Postgres ngay cả khi hàng trăm kết nối client đến cùng lúc.
Phân chia nhiệm vụ đơn giản:
Chúng có thể hoạt động cùng nhau mà không gây “double pooling” miễn là mỗi lớp có mục đích rõ ràng: một pool database/sql hợp lý cho mỗi process Go, cộng với PgBouncer để thực thi ngân sách kết nối toàn cục.
Một nhầm lẫn phổ biến là nghĩ “nhiều pool hơn nghĩa là nhiều sức chứa hơn.” Thường thì ngược lại. Nếu mỗi service, worker và replica có pool lớn riêng, tổng số kết nối có thể bùng nổ và gây hàng đợi, chuyển đổi ngữ cảnh, và đột biến độ trễ.
database/sql của Go thực sự hoạt động thế nàoTrong Go, sql.DB là một bộ quản lý pool kết nối, không phải một kết nối đơn. Khi bạn gọi db.Query hoặc db.Exec, database/sql cố gắng tái sử dụng một kết nối idle. Nếu không có, nó có thể mở một kết nối mới (đến giới hạn của bạn) hoặc khiến yêu cầu chờ.
Chính sự chờ này thường tạo ra “độ trễ bí ẩn”. Khi pool bị bão hòa, yêu cầu xếp hàng trong app. Từ bên ngoài, có vẻ như Postgres chậm, nhưng thực tế thời gian được tiêu tốn để đợi một kết nối rảnh.
Hầu hết tinh chỉnh nằm ở bốn thiết lập:
MaxOpenConns: giới hạn cứng trên số kết nối mở (idle + đang dùng). Khi đạt giới hạn, caller bị block.MaxIdleConns: bao nhiêu kết nối có thể sẵn sàng để tái sử dụng. Quá thấp sẽ gây reconnect thường xuyên.ConnMaxLifetime: buộc tái tạo kết nối theo chu kỳ. Hữu ích cho load balancer và timeout NAT, nhưng quá thấp gây churn.ConnMaxIdleTime: đóng các kết nối không dùng trong thời gian dài.Tái sử dụng kết nối thường hạ thấp độ trễ và CPU database vì tránh thiết lập lặp lại (TCP/TLS, auth, session init). Nhưng pool quá lớn có thể gây phản tác dụng: nó cho phép nhiều truy vấn đồng thời hơn khả năng Postgres xử lý tốt, tăng cạnh tranh và overhead.
Hãy nghĩ về tổng thể, không chỉ per-process. Nếu mỗi instance Go cho phép 50 kết nối mở và bạn scale lên 20 instance, bạn thực sự đã cho phép 1.000 kết nối. So sánh con số đó với những gì Postgres của bạn có thể chạy mượt.
Một khởi điểm thực tế là gắn MaxOpenConns vào độ đồng thời kỳ vọng mỗi instance, rồi kiểm chứng với số liệu pool (in-use, idle, và wait time) trước khi tăng.
PgBouncer là một proxy nhỏ giữa app và PostgreSQL. Dịch vụ của bạn kết nối tới PgBouncer, và PgBouncer giữ một số kết nối thực tế hạn chế tới Postgres. Trong đợt tăng, PgBouncer xếp hàng công việc client thay vì ngay lập tức tạo thêm backend Postgres. Hàng đợi này có thể là khác biệt giữa chậm có kiểm soát và database bị quá tải.
PgBouncer có ba chế độ pooling:
Session pooling giống nhất với kết nối trực tiếp tới Postgres. Nó ít gây ngạc nhiên nhất, nhưng tiết kiệm ít connection server hơn khi tải nhấp nhô.
Với API HTTP điển hình bằng Go, transaction pooling thường là lựa chọn mặc định tốt. Hầu hết request thực hiện một truy vấn nhỏ hoặc một transaction ngắn rồi xong. Transaction pooling cho phép nhiều kết nối client chia sẻ một ngân sách kết nối Postgres nhỏ hơn.
Nhược điểm là trạng thái phiên (session state). Trong chế độ transaction, bất cứ thứ gì giả định một server connection cố định có thể hỏng hoặc hành xử khác, bao gồm:
SET, SET ROLE, search_path)Nếu app của bạn phụ thuộc vào loại trạng thái đó, session pooling an toàn hơn. Statement pooling là hạn chế nhất và hiếm khi phù hợp với web app.
Một quy tắc hữu ích: nếu mỗi request có thể thiết lập những gì nó cần trong một transaction, transaction pooling thường giữ độ trễ ổn định hơn khi tải tăng. Nếu bạn cần hành vi session lâu dài, dùng session pooling và tập trung vào giới hạn chặt chẽ hơn trong app.
Nếu bạn chạy service Go với database/sql, bạn đã có pool phía app. Với nhiều đội, đó là đủ: vài instance, traffic ổn định, và truy vấn không quá nhấp nhô. Trong trường hợp đó, lựa chọn đơn giản và an toàn nhất là tinh chỉnh pool Go, giữ giới hạn kết nối hợp lý, và dừng lại ở đó.
PgBouncer giúp nhiều nhất khi database bị truy cập bởi quá nhiều client cùng lúc. Điều này thể hiện bằng nhiều instance app (hoặc autoscaling kiểu serverless), traffic nhấp nhô, và nhiều truy vấn ngắn.
PgBouncer cũng có thể gây hại nếu dùng sai chế độ. Nếu code của bạn phụ thuộc vào trạng thái session (temporary tables, prepared statements dùng qua các request, advisory locks giữ qua các lần gọi, hoặc cài đặt session), transaction pooling có thể gây lỗi khó hiểu. Nếu bạn thực sự cần hành vi session, dùng session pooling hoặc bỏ qua PgBouncer và cấu hình pool app cẩn thận.
Dùng quy tắc này làm tham khảo:
Giới hạn kết nối là một ngân sách. Nếu bạn tiêu hết ngay, mỗi request mới phải chờ và tail latency nhảy vọt. Mục tiêu là giới hạn độ đồng thời theo cách có kiểm soát trong khi giữ throughput ổn định.
Đo các đỉnh và độ trễ tail hiện tại. Ghi lại peak active connections (không phải trung bình), cùng p50/p95/p99 cho request và các truy vấn chính. Ghi nhận lỗi kết nối hoặc timeout.
Đặt ngân sách kết nối an toàn cho app. Bắt đầu từ max_connections và trừ ra chỗ dự phòng cho truy cập admin, migration, background jobs, và đột biến. Nếu nhiều service chia database, phân chia ngân sách có chủ ý.
Ánh ngân sách sang giới hạn Go theo instance. Chia ngân sách app cho số instance và đặt MaxOpenConns theo đó (hoặc thấp hơn một chút). Đặt MaxIdleConns đủ cao để tránh reconnect liên tục, và đặt thời lượng để kết nối được tái chế thỉnh thoảng mà không gây churn.
Chỉ thêm PgBouncer nếu cần, và chọn chế độ. Dùng session pooling nếu bạn cần trạng thái session. Dùng transaction pooling khi bạn muốn giảm nhiều nhất số kết nối server và app tương thích.
Triển khai dần và so sánh trước/sau. Thay đổi từng thứ một, canary, rồi so sánh tail latency, pool wait time, và CPU database.
Ví dụ: nếu Postgres có thể cấp an toàn 200 kết nối cho service của bạn và bạn chạy 10 instance Go, bắt đầu với MaxOpenConns=15-18 mỗi instance. Điều đó để chỗ cho các đợt tăng và giảm khả năng mọi instance cùng chạm trần cùng lúc.
Vấn đề pooling hiếm khi xuất hiện trước bằng thông báo “too many connections.” Thường bạn thấy thời gian chờ tăng rồi một cú nhảy đột ngột ở p95 và p99.
Bắt đầu từ những gì app Go báo cáo. Với database/sql, giám sát open connections, in-use, idle, wait count, và wait time. Nếu wait count tăng trong khi traffic ổn định, pool bị undersized hoặc kết nối bị giữ quá lâu.
Ở phía database, theo dõi active connections vs max, CPU, và hoạt động lock. Nếu CPU thấp nhưng độ trễ cao, thường là do hàng đợi hoặc lock, không phải do tính toán thô.
Nếu bạn chạy PgBouncer, thêm một góc nhìn thứ ba: client connections, server connections tới Postgres, và queue depth. Một queue tăng trong khi server connections ổn định là dấu rõ ràng ngân sách bị bão hòa.
Các cảnh báo tốt:
Vấn đề pooling thường xuất hiện trong đợt tăng: yêu cầu xếp hàng chờ kết nối, rồi mọi thứ lại ổn. Nguyên nhân thường là một thiết lập hợp lý trên một instance nhưng nguy hiểm khi chạy nhiều bản sao dịch vụ.
Nguyên nhân phổ biến:
MaxOpenConns đặt theo instance mà không có ngân sách toàn cục. 100 kết nối mỗi instance trên 20 instance là 2.000 kết nối tiềm năng.ConnMaxLifetime / ConnMaxIdleTime đặt quá ngắn. Điều này có thể gây bão reconnect khi nhiều kết nối tái tạo cùng lúc.Cách đơn giản giảm đột biến là coi pooling như giới hạn chung, không phải mặc định cục bộ app: giới hạn tổng kết nối trên tất cả instance, giữ pool idle vừa phải, và dùng lifetime đủ dài để tránh reconnect đồng bộ.
Khi traffic tăng đột ngột, thường bạn thấy một trong ba kết quả: yêu cầu xếp hàng chờ kết nối, yêu cầu timeout, hoặc mọi thứ chậm đến mức retry chồng lên nhau.
Queueing là thứ ranh mãnh. Handler vẫn chạy nhưng bị treo chờ kết nối. Thời gian chờ này thành phần của thời gian phản hồi, nên một pool nhỏ có thể biến truy vấn 50 ms thành endpoint nhiều giây dưới tải.
Mô hình tư duy hữu ích: nếu pool có 30 kết nối dùng được và bỗng dưng có 300 request đồng thời cần DB, 270 trong số đó phải chờ. Nếu mỗi request giữ kết nối 100 ms, tail latency nhanh chóng lên tới vài giây.
Đặt ngân sách timeout rõ ràng và tuân thủ. Timeout app nên ngắn hơn timeout DB một chút để bạn fail fast và giảm áp lực thay vì để công việc treo.
statement_timeout để một truy vấn tồi không chiếm kết nối mãi mãiSau đó thêm cơ chế backpressure để không làm quá tải pool ngay từ đầu. Chọn một hoặc hai cơ chế dễ đoán, như giới hạn độ đồng thời per-endpoint, trả lỗi có chủ đích (như 429), hoặc tách các job nền ra khỏi lưu lượng người dùng.
Cuối cùng, sửa truy vấn chậm trước. Dưới áp lực pooling, truy vấn chậm giữ kết nối lâu hơn, làm tăng thời gian chờ, làm tăng timeout, kích hoạt retry. Vòng phản hồi này biến “hơi chậm” thành “mọi thứ đều chậm.”
Hãy coi load test là để xác thực ngân sách kết nối, không chỉ throughput. Mục tiêu là xác nhận pooling hành xử dưới áp lực như trên staging.
Test với lưu lượng thực tế: cùng tỉ lệ request, mẫu burst, và cùng số instance app như production. Benchmark một endpoint đơn thường che giấu vấn đề pool cho tới ngày ra mắt.
Có phần warm-up để không đo cache lạnh và hiệu ứng ramp-up. Để pool đạt kích thước bình thường, rồi bắt đầu ghi số liệu.
Nếu bạn so sánh chiến lược, giữ workload giống hệt và chạy:
database/sql, không có PgBouncer)Sau mỗi lần chạy, ghi lại một bảng điểm bạn có thể tái sử dụng sau mỗi release:
Theo thời gian, điều này biến quy hoạch năng lực thành việc có thể lặp lại thay vì đoán mò.
Trước khi chạm vào kích thước pool, viết ra một con số: ngân sách kết nối. Đó là số tối đa an toàn của kết nối Postgres đang hoạt động cho môi trường này (dev, staging, prod), bao gồm background job và truy cập admin. Nếu bạn không thể nêu con số, bạn đang đoán mò.
Danh sách kiểm tra nhanh:
MaxOpenConns) phù hợp với ngân sách (hoặc với cap của PgBouncer).max_connections và bất kỳ connection dự phòng nào khớp với kế hoạch của bạn.Kế hoạch rollout dễ rollback:
Nếu bạn đang xây và host app Go + PostgreSQL trên Koder.ai (koder.ai), Planning Mode có thể giúp bạn lập bản đồ thay đổi và những gì sẽ đo, còn snapshots và rollback giúp bạn revert nếu tail latency tệ hơn.
Bước tiếp theo: thêm một phép đo trước khi đợt tăng lưu lượng tiếp theo. “Thời gian chờ kết nối” trong app thường là chỉ báo hữu ích nhất, vì nó cho thấy áp lực pooling trước khi người dùng cảm nhận được.
A pool keeps a small set of PostgreSQL connections open and reuses them across requests. This avoids paying the setup cost (TCP/TLS, auth, backend process setup) over and over, which helps keep tail latency steady during bursts.
When the pool is saturated, requests wait inside your app for a free connection, and that wait time shows up as slow responses. This often looks like “random slowness” because averages can stay fine while p95/p99 jump during traffic bursts.
No, it mostly changes how the system behaves under load by reducing reconnect churn and controlling concurrency. If a query is slow because of scans, locks, or poor indexing, pooling can’t make it fast; it can only limit how many slow queries run at once.
App pooling manages connections per process, so each app instance has its own pool and its own limits. PgBouncer sits in front of Postgres and enforces a global connection budget across many clients, which is especially useful when you have many replicas or spiky traffic.
If you run a small number of instances and your total open connections stay comfortably under the database limit, tuning Go’s database/sql pool is usually enough. Add PgBouncer when many instances, autoscaling, or bursty traffic could push total connections beyond what Postgres can handle smoothly.
A good default is to set a total connection budget for the service, then divide it by the number of app instances and set MaxOpenConns slightly below that per instance. Start small, watch wait time and p95/p99, and only increase if you’re sure the database has headroom.
Transaction pooling is often a strong default for typical HTTP APIs because it lets many client connections share fewer server connections and stays stable during bursts. Use session pooling if your code relies on session state persisting across statements, such as temp tables, session settings, or prepared statements reused across requests.
Prepared statements, temp tables, advisory locks, and session-level settings can behave differently because a client may not get the same server connection next time. If you need those features, either keep everything within a single transaction per request or switch to session pooling to avoid confusing failures.
Watch p95/p99 latency alongside app pool wait time, because wait time often rises before users complain. On Postgres, track active connections, CPU, and locks; on PgBouncer, track client connections, server connections, and queue depth to see if you’re saturating your connection budget.
First, stop unlimited waiting by setting request deadlines and a DB statement timeout so one slow query can’t hold connections forever. Then add backpressure by limiting concurrency for DB-heavy endpoints or shedding load, and reduce connection churn by avoiding overly short connection lifetimes that cause reconnect storms.