23 thg 10, 2025·7 phút
Lọc phía máy chủ vs phía trình duyệt: danh sách kiểm tra để quyết định
Danh sách kiểm tra để chọn lọc phía server hay client dựa trên kích thước dữ liệu, độ trễ, quyền truy cập và cache — tránh rò rỉ UI hoặc giật lag.
Danh sách kiểm tra để chọn lọc phía server hay client dựa trên kích thước dữ liệu, độ trễ, quyền truy cập và cache — tránh rò rỉ UI hoặc giật lag.
Lọc trong UI không chỉ là một ô tìm kiếm. Nó thường gồm vài hành động liên quan thay đổi những gì người dùng thấy: tìm theo chữ (tên, email, mã đơn), các facet (trạng thái, người sở hữu, khoảng ngày, thẻ), và sắp xếp (mới nhất, giá trị cao nhất, hoạt động cuối cùng).
Câu hỏi then chốt không phải kỹ thuật nào “tốt hơn”. Mà là nơi lưu dataset đầy đủ, và ai được phép truy cập nó. Nếu trình duyệt nhận các bản ghi mà người dùng không nên thấy, UI có thể phơi bày dữ liệu nhạy cảm ngay cả khi bạn ẩn nó về mặt hiển thị.
Hầu hết tranh luận về server-side vs client-side filtering thực ra là phản ứng trước hai thất bại người dùng nhận thấy ngay:
Có một vấn đề thứ ba gây báo lỗi bất tận: kết quả không nhất quán. Nếu một số bộ lọc chạy trên client và số khác chạy trên server, người dùng sẽ thấy tổng, trang và số lượng không khớp. Điều đó làm mất niềm tin rất nhanh, đặc biệt trên danh sách phân trang.
Một mặc định thực tế là đơn giản: nếu người dùng không được phép truy cập toàn bộ dataset, thì lọc trên server. Nếu được phép và dataset đủ nhỏ để tải nhanh, lọc trên client có thể chấp nhận được.
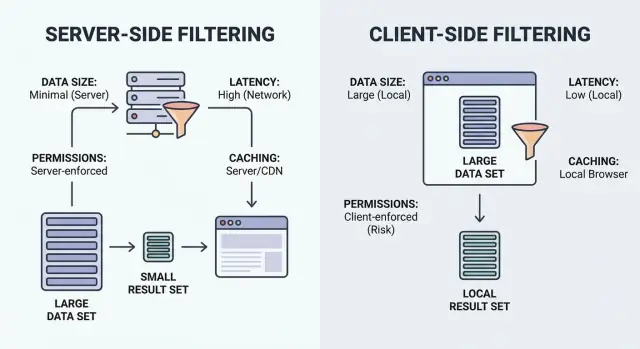
Lọc chỉ là “hiển thị các mục khớp”. Câu hỏi là việc khớp xảy ra ở đâu: trên trình duyệt của người dùng (client) hay trên backend của bạn (server).
Lọc phía client chạy trong trình duyệt. Ứng dụng tải một tập bản ghi (thường JSON), rồi áp bộ lọc cục bộ. Sau khi dữ liệu đã tải, nó có thể cảm thấy tức thì, nhưng chỉ hoạt động khi dataset đủ nhỏ để gửi và đủ an toàn để phơi bày.
Lọc phía server chạy trên backend. Trình duyệt gửi các input lọc (ví dụ status=open, owner=me, createdAfter=Jan 1), và server trả về chỉ kết quả khớp. Thực tế, đây thường là một endpoint API nhận filter, dựng truy vấn cơ sở dữ liệu, và trả về danh sách phân trang cùng tổng số.
Mô hình tư duy đơn giản:
Các setup kết hợp là phổ biến. Một mô hình tốt là thực thi các bộ lọc “lớn” trên server (quyền, sở hữu, khoảng ngày, tìm kiếm), rồi dùng các toggle nhỏ chỉ cho UI cục bộ (ẩn mục lưu trữ, chip thẻ nhanh, hiển thị cột) mà không cần request thêm.
Sắp xếp, phân trang và tìm kiếm thường thuộc cùng quyết định. Chúng ảnh hưởng đến kích thước payload, cảm nhận người dùng và dữ liệu bạn đang phơi bày.
Bắt đầu bằng câu hỏi thực tế nhất: bạn sẽ gửi bao nhiêu dữ liệu tới trình duyệt nếu lọc trên client? Nếu câu trả lời trung thực là “nhiều hơn vài màn hình”, bạn sẽ trả giá bằng thời gian tải, bộ nhớ và các tương tác chậm.
Bạn không cần ước lượng hoàn hảo. Chỉ cần biết bậc: người dùng có thể thấy bao nhiêu hàng, và kích thước trung bình mỗi hàng ra sao? Danh sách 500 mục với vài trường ngắn rất khác so với 50.000 mục mà mỗi hàng chứa ghi chú dài, rich text hoặc object lồng.
Bản ghi rộng là kẻ giết payload thầm lặng. Một bảng có thể trông nhỏ về số hàng nhưng nặng nếu mỗi hàng chứa nhiều trường, chuỗi lớn, hoặc dữ liệu join (contact + công ty + hoạt động cuối + địa chỉ đầy đủ + thẻ). Dù chỉ hiển thị ba cột, các team thường gửi “mọi thứ, phòng khi cần”, và payload phình ra.
Cũng nghĩ đến tăng trưởng. Dataset hôm nay ổn có thể trở nên nặng chỉ sau vài tháng. Nếu dữ liệu tăng nhanh, coi lọc phía client là giải pháp tạm thời, không phải mặc định.
Quy tắc tham khảo:
Điểm cuối cùng không chỉ về hiệu năng. “Chúng ta có thể gửi toàn bộ dataset lên trình duyệt không?” cũng là câu hỏi bảo mật. Nếu không thể trả lời chắc chắn là có, thì đừng gửi.
Quyết định lọc thường thất bại về cảm nhận, không phải về tính đúng. Người dùng không đo mili giây. Họ nhận thấy giật, nhấp nháy và kết quả nhảy lung tung khi họ gõ.
Thời gian có thể mất ở nhiều chỗ khác nhau:
Xác định “nhanh đủ” cho màn hình này. Một view danh sách có thể cần phản hồi khi gõ và cuộn mượt, trong khi một trang báo cáo có thể chịu đựng chờ hơi lâu miễn là kết quả đầu tiên xuất hiện nhanh.
Đừng chỉ đánh giá trên Wi‑Fi văn phòng. Trên kết nối chậm, lọc phía client có thể cho cảm nhận tốt sau lần tải đầu, nhưng lần tải đầu có thể rất chậm. Lọc phía server giữ payload nhỏ, nhưng có thể cảm thấy trễ nếu bạn gửi request cho mỗi phím bấm.
Thiết kế xoay quanh input của con người. Debounce request khi gõ. Với tập kết quả lớn, dùng tải dần để trang hiển thị thứ gì đó nhanh và giữ mượt khi người dùng cuộn.
Quyền truy cập nên quyết định cách lọc hơn là chỉ tốc độ. Nếu trình duyệt từng nhận dữ liệu mà người dùng không được xem, bạn đã có vấn đề, ngay cả khi bạn ẩn nó phía UI.
Bắt đầu bằng cách liệt kê trường nào nhạy cảm trên màn hình này. Một số trường rõ ràng (email, số điện thoại, địa chỉ). Những trường khác dễ bị bỏ sót: ghi chú nội bộ, chi phí hoặc biên lợi nhuận, quy tắc giá đặc biệt, điểm rủi ro, cờ kiểm duyệt.
Cái bẫy lớn là “chúng ta lọc ở client, nhưng chỉ hiển thị hàng được phép”. Điều đó vẫn nghĩa là dataset đầy đủ đã được tải. Bất kỳ ai cũng có thể kiểm tra phản hồi mạng, mở dev tools hoặc lưu payload. Ẩn cột trong UI không phải là kiểm soát truy cập.
Lọc phía server là mặc định an toàn khi ủy quyền khác nhau theo user, đặc biệt khi người dùng khác nhau có thể thấy các hàng khác nhau hoặc các trường khác nhau.
Kiểm tra nhanh:
Nếu có bất kỳ câu trả lời nào là có, giữ việc lọc và lựa chọn trường ở server. Chỉ gửi những gì người dùng được phép thấy, và áp cùng quy tắc cho tìm kiếm, sắp xếp, phân trang và xuất.
Ví dụ: trong danh sách contact của CRM, đại diện bán hàng chỉ xem account của họ trong khi quản lý xem toàn bộ. Nếu trình duyệt tải về tất cả contact rồi lọc cục bộ, đại diện vẫn có thể phục hồi account ẩn từ phản hồi. Lọc phía server ngăn điều đó bằng cách không bao giờ gửi các hàng đó.
Caching có thể làm màn hình cảm thấy tức thì. Nó cũng có thể hiển thị thông tin sai. Chìa khóa là quyết định bạn được phép tái sử dụng gì, trong bao lâu, và sự kiện nào phải xóa cache.
Bắt đầu bằng cách chọn đơn vị cache. Cache toàn bộ danh sách đơn giản nhưng thường lãng phí băng thông và nhanh lỗi thời. Cache theo trang phù hợp với infinite scroll. Cache theo truy vấn (filter + sắp xếp + tìm kiếm) chính xác, nhưng có thể phình nhanh nếu người dùng thử nhiều tổ hợp.
Tính mới quan trọng hơn trong một số miền. Nếu dữ liệu thay đổi nhanh (tồn kho, số dư, trạng thái giao hàng), ngay cả cache 30 giây cũng có thể làm người dùng hiểu nhầm. Nếu dữ liệu thay đổi chậm (bản ghi lưu trữ, dữ liệu tham chiếu), cache lâu hơn thường ổn.
Lên kế hoạch invalidation trước khi code. Ngoài thời gian trôi qua, quyết định hành động nào phải ép refresh: tạo/sửa/xóa, thay đổi quyền, import/merge hàng loạt, chuyển trạng thái, undo/rollback, và các job nền cập nhật trường mà người dùng lọc.
Cũng chọn nơi cache nằm. Bộ nhớ trình duyệt giúp back/forward nhanh, nhưng có thể rò rỉ dữ liệu giữa các tài khoản nếu bạn không khóa theo user và org. Cache phía backend an toàn hơn cho quyền và nhất quán, nhưng phải bao gồm đầy đủ chữ ký filter và danh tính caller để kết quả không bị lẫn.
Mục tiêu không thể thương lượng: màn hình phải cảm giác nhanh mà không rò rỉ dữ liệu.
Phần lớn team bị vấp cùng kiểu: UI đẹp trong demo, rồi dữ liệu thật, quyền thật và tốc độ mạng thật lộ ra các vết nứt.
Thất bại nghiêm trọng nhất là coi lọc chỉ là trình bày. Nếu trình duyệt nhận bản ghi không nên có, bạn đã mất.
Hai nguyên nhân thường gặp:
Ví dụ: thực tập sinh chỉ nên thấy leads vùng họ phụ trách. Nếu API trả về tất cả vùng và dropdown lọc bằng React, thực tập sinh vẫn có thể trích xuất toàn bộ danh sách.
Độ trễ thường đến từ giả định:
Một vấn đề tinh tế nhưng đau là quy tắc không khớp. Nếu server xử lý “starts with” khác client, người dùng thấy tổng không khớp, hoặc mục biến mất sau khi refresh.
Làm bước rà soát cuối với hai tư duy: người dùng tò mò và ngày mạng tệ.
Một bài test đơn giản: tạo một bản ghi bị hạn chế và xác nhận nó không bao giờ xuất hiện trong payload, tổng số, hoặc cache, ngay cả khi bạn lọc rộng hoặc xóa bộ lọc.
Hình dung một CRM với 200.000 contact. Đại diện bán hàng chỉ thấy account của họ, quản lý thấy team họ, admin thấy mọi thứ. Màn hình có tìm kiếm, bộ lọc (trạng thái, owner, hoạt động gần nhất) và sắp xếp.
Lọc phía client thất bại nhanh ở đây. Payload nặng, lần tải đầu chậm, và rủi ro rò rỉ dữ liệu cao. Dù UI ẩn hàng, trình duyệt vẫn nhận dữ liệu. Bạn cũng đẩy áp lực lên thiết bị: mảng lớn, sắp xếp nặng, chạy bộ lọc nhiều lần, dùng nhiều nhớ và crash trên điện thoại cũ.
Cách an toàn hơn là lọc phía server với phân trang. Client gửi lựa chọn filter và text tìm kiếm, server trả về chỉ các hàng người dùng được phép thấy, đã lọc và sắp xếp.
Mẫu thực tế:
Ngoại lệ nhỏ khi client-side ổn: dữ liệu tiny, tĩnh. Dropdown “Contact status” với 8 giá trị có thể tải một lần và lọc cục bộ mà ít rủi ro hoặc chi phí.
Các team thường không bị cháy vì chọn sai một lần. Họ bị cháy vì chọn khác nhau cho mỗi màn hình, rồi cố sửa rò rỉ và trang chậm khi đang chịu áp lực.
Viết một ghi chú quyết định ngắn cho mỗi màn hình gồm: kích thước dataset, chi phí gửi, cảm nhận "nhanh đủ" là gì, trường nào nhạy cảm, và cách cache (hoặc không). Giữ server và UI đồng bộ để không có “hai chân lý” cho việc lọc.
Nếu bạn đang xây nhanh bằng Koder.ai (koder.ai), nên quyết trước bộ lọc nào phải thực thi trên backend (quyền và truy cập hàng) và toggle UI nhỏ nào có thể ở lớp React. Một lựa chọn như vậy tránh được những lần viết lại tốn kém sau này.
Ưu tiên dùng server-side khi người dùng có quyền khác nhau, dataset lớn, hoặc khi bạn cần tổng số và phân trang chính xác. Chỉ dùng client-side khi toàn bộ dataset nhỏ, an toàn để phơi bày và nhanh để tải về.
Bất cứ gì trình duyệt nhận được đều có thể bị kiểm tra. Dù UI có ẩn hàng hoặc cột, người dùng vẫn xem được dữ liệu trong phản hồi mạng, cache hoặc đối tượng trong bộ nhớ.
Thông thường xảy ra khi bạn gửi quá nhiều dữ liệu rồi lọc/sắp xếp mảng lớn sau mỗi lần gõ, hoặc khi bạn gửi yêu cầu lên server cho mỗi phím bấm mà không debounce. Giữ payload nhỏ và tránh làm công việc nặng trên mỗi thay đổi input.
Giữ một nguồn chân lý cho các bộ lọc “thực”: quyền truy cập, tìm kiếm, sắp xếp và phân trang nên được thực thi trên server cùng nhau. Giới hạn logic phía client cho các toggle UI nhỏ không thay đổi dataset cơ bản.
Caching phía client có thể hiển thị dữ liệu lỗi thời hoặc rò rỉ giữa các tài khoản nếu khóa cache không chính xác. Caching phía server an toàn hơn cho quyền, nhưng phải bao gồm đầy đủ chữ ký filter và danh tính caller để kết quả không bị trộn lẫn.
Hỏi hai câu: người dùng có thể có bao nhiêu hàng thực tế, và mỗi hàng lớn bao nhiêu byte. Nếu bạn không thoải mái tải nó trên kết nối di động thông thường hoặc trên thiết bị cũ, chuyển lọc về server và phân trang.
Server-side. Nếu vai trò, nhóm, vùng hoặc quy tắc sở hữu thay đổi những gì người ta thấy, server phải thực thi quyền truy cập hàng và trường. Client chỉ nên nhận những bản ghi và trường mà người dùng được phép xem.
Định nghĩa hợp đồng filter và sort trước: những trường filter được chấp nhận, sắp xếp mặc định, quy tắc phân trang và cách search khớp (không phân biệt hoa thường, dấu, khớp một phần). Sau đó thực hiện logic giống nhau trên backend và kiểm thử tổng số và trang khớp nhau.
Debounce khi gõ để không gửi yêu cầu cho mỗi phím, giữ kết quả cũ hiển thị cho đến khi kết quả mới về để giảm nhấp nháy. Dùng phân trang hoặc tải dần để người dùng thấy cái gì đó nhanh mà không phải chờ phản hồi to.
Thực thi quyền trước, rồi tới bộ lọc và sắp xếp, trả về một trang cùng tổng số. Tránh gửi “thêm trường phòng khi cần”, và đảm bảo khóa cache bao gồm user/org/role để một nhân viên không bao giờ nhận dữ liệu dành cho quản lý.