23 thg 12, 2025·8 phút
Giới hạn tần suất API SaaS: mẫu theo người dùng, tổ chức và IP
Các mẫu giới hạn tần suất API SaaS theo người dùng, tổ chức và IP, kèm header, body lỗi và mẹo triển khai để khách hàng hiểu.
Các mẫu giới hạn tần suất API SaaS theo người dùng, tổ chức và IP, kèm header, body lỗi và mẹo triển khai để khách hàng hiểu.
Rate limit và quota nghe giống nhau, nên nhiều người đối xử như là một. Rate limit là tốc độ bạn có thể gọi API (requests trên giây hoặc trên phút). Quota là tổng mức sử dụng trong khoảng thời gian dài hơn (mỗi ngày, mỗi tháng hoặc chu kỳ thanh toán). Cả hai đều hợp lý, nhưng khi quy tắc không hiển thị rõ, chúng có cảm giác ngẫu nhiên.
Phàn nàn kinh điển là: “hôm qua vẫn chạy được.” Lượng dùng hiếm khi ổn định. Một spike ngắn có thể đẩy ai đó vượt ngưỡng dù tổng hàng ngày vẫn ổn. Hãy tưởng tượng một khách hàng chạy báo cáo mỗi ngày một lần, nhưng hôm nay công việc retry sau timeout và tạo ra nhiều lượt gọi hơn 10× trong 2 phút. API chặn, và họ chỉ thấy lỗi đột ngột.
Sự bối rối tệ hơn khi lỗi mơ hồ. Nếu API trả 500 hoặc thông điệp chung chung, khách hàng nghĩ dịch vụ sập chứ không phải họ chạm giới hạn. Họ mở ticket khẩn, dựng giải pháp thay thế, hoặc chuyển nhà cung cấp. Ngay cả 429 Too Many Requests cũng khiến bực mình nếu không nói phải làm gì tiếp theo.
Hầu hết API SaaS hạn chế lưu lượng vì hai lý do khác nhau:
Trộn hai mục tiêu này dẫn đến thiết kế tệ. Kiểm soát abuse thường là per-IP hoặc per-token và có thể nghiêm ngặt. Điều chỉnh dùng bình thường thường là per-user hoặc per-organization và nên kèm hướng dẫn rõ ràng: giới hạn nào bị chạm, khi nào reset, và cách tránh lặp lại.
Khi khách hàng có thể dự đoán giới hạn, họ lên kế hoạch. Khi không thể, mỗi spike đều như API bị hỏng.
Rate limit không chỉ là cùm ga. Chúng là hệ thống an toàn. Trước khi chọn con số, hãy rõ ràng về thứ bạn muốn bảo vệ, vì mỗi mục tiêu dẫn tới giới hạn và kỳ vọng khác nhau.
Sẵn sàng (availability) thường đứng đầu. Nếu vài client spike traffic và đẩy API vào timeout, mọi người đều bị ảnh hưởng. Giới hạn ở đây nên giữ server phản hồi trong burst và fail fast thay vì để request chất đống.
Chi phí là động lực thầm lặng phía sau nhiều API. Một vài request rẻ, một vài request đắt (gọi LLM, xử lý file, ghi lưu trữ, lookup trả phí từ bên thứ ba). Ví dụ, trên nền tảng như Koder.ai, một user có thể kích hoạt nhiều cuộc gọi model qua tính năng tạo app theo chat. Giới hạn theo hành động tốn kém giúp tránh hoá đơn bất ngờ.
Abuse trông khác với lưu lượng hợp lệ cao. Credential stuffing, dò token, scraping thường xuất hiện như nhiều request nhỏ từ tập hợp IP hoặc tài khoản hẹp. Ở đây bạn muốn giới hạn nghiêm và chặn nhanh.
Công bằng quan trọng trong hệ multi-tenant. Một khách ồn ào không nên làm suy giảm người khác. Trong thực tế, điều này thường có nghĩa xếp lớp kiểm soát: một burst guard để giữ API khỏe từng phút, một cost guard cho endpoint tốn kém, một abuse guard tập trung vào auth và mẫu đáng ngờ, và một fairness guard để một org không lấn át các org khác.
Một bài test đơn giản: chọn một endpoint và hỏi, “Nếu request này tăng 10×, cái gì hỏng trước?” Câu trả lời cho biết mục tiêu bảo vệ nào cần ưu tiên, và chiều nào (user, org, IP) nên mang giới hạn.
Hầu hết đội bắt đầu với một giới hạn rồi sau đó phát hiện nó làm tổn thương người dùng sai. Mục tiêu là chọn chiều phù hợp với cách dùng thực tế: ai gọi, ai trả tiền, và gì trông giống hành vi abuse.
Các chiều phổ biến trong SaaS như:
Giới hạn per-user là về công bằng bên trong tenant. Nếu một người chạy export lớn, họ nên cảm nhận độ chậm hơn các thành viên khác.
Giới hạn per-org là về ngân sách và năng lực. Dù mười người chạy job cùng lúc, org không nên spike đến mức phá hỏng dịch vụ hoặc giả định giá của bạn.
Giới hạn per-IP tốt nhất coi như lưới an toàn, không dùng để tính phí. IP có thể được chia sẻ (NAT văn phòng, nhà mạng di động), nên giữ giới hạn này hào phóng và chỉ dùng để ngăn abuse rõ ràng.
Khi kết hợp nhiều chiều, quyết định chiều nào “thắng” khi nhiều giới hạn áp dụng. Quy tắc thực tế: từ chối request nếu bất kỳ giới hạn liên quan nào vượt, và trả về lý do dễ hành động nhất. Nếu workspace vượt quota org, đừng đổ lỗi cho user hay IP.
Ví dụ: workspace Koder.ai trên gói Pro có thể cho phép luồng build ổn định per-org, đồng thời giới hạn một user không được bắn hàng trăm request trong một phút. Nếu integration partner dùng một token chia sẻ, giới hạn per-token có thể ngăn nó áp đảo người dùng tương tác.
Hầu hết vấn đề rate limiting không phải về toán học. Là về chọn hành vi phù hợp với cách khách hàng gọi API, rồi giữ cho nó dự đoán được dưới tải.
Token bucket là mặc định phổ biến vì nó cho phép burst ngắn nhưng thi hành trung bình ổn định. Một user refresh dashboard có thể kích vài request nhanh. Token bucket cho phép nếu họ đã tích token, sau đó làm chậm lại.
Leaky bucket nghiêm ngặt hơn. Nó làm mịn traffic thành luồng ra hằng định, hữu ích khi backend không chịu đựng được spike (ví dụ tạo báo cáo tốn kém). Đổi lại, khách hàng cảm thấy sớm hơn vì burst biến thành hàng đợi hoặc bị từ chối.
Bộ đếm theo cửa sổ đơn thuần thì đơn giản nhưng chi tiết quan trọng. Fixed windows tạo mép sắc ở biên (user có thể burst lúc 12:00:59 và lại tại 12:01:00). Sliding windows công bằng hơn và giảm spike biên, nhưng cần nhiều state hơn hoặc cấu trúc dữ liệu tốt hơn.
Một loại riêng là concurrency (request đang xử lý). Điều này bảo vệ bạn khỏi kết nối client chậm và endpoint chạy lâu. Một khách có thể ở trong 60 requests/phút nhưng vẫn làm quá tải bằng cách giữ 200 request mở cùng lúc.
Trong hệ thật, đội thường kết hợp một tập nhỏ điều khiển: token bucket cho rate chung, concurrency cap cho endpoint chậm/nặng, và ngân sách riêng cho nhóm endpoint (read rẻ vs export tốn kém). Nếu chỉ giới hạn theo số request, một endpoint tốn kém có thể chiếm hết và làm API trông hỏng ngẫu nhiên.
Quota tốt phải công bằng và dự đoán được. Khách hàng không nên chỉ phát hiện quy tắc sau khi bị chặn.
Giữ sự phân tách rõ:
Nhiều đội dùng cả hai: rate limit ngắn để ngăn burst cộng quota tháng gắn với giá.
Hard vs soft limit chủ yếu là lựa chọn hỗ trợ. Hard block ngay lập tức. Soft cảnh báo trước rồi block sau. Soft giảm ticket giận dữ vì người ta có cơ hội sửa lỗi hoặc nâng cấp trước khi integration vỡ.
Khi ai đó vượt, hành vi nên phù hợp với mục tiêu bảo vệ. Block khi overuse có thể tổn hại tenant khác hoặc nổ chi phí. Degrade (xử lý chậm hơn hoặc ưu tiên thấp hơn) khi bạn muốn giữ luồng di chuyển. “Bill later” có thể ổn khi dùng dự đoán và bạn đã có luồng thanh toán.
Giới hạn theo tier hiệu quả khi mỗi tier có “hình dạng dùng dự kiến” rõ ràng. Free cho phép quota tháng nhỏ và burst thấp, business/enterprise có quota và burst cao hơn để các job nền hoàn thành nhanh. Giống cách các tier Free, Pro, Business, Enterprise của Koder.ai đặt kỳ vọng khác nhau.
Hỗ trợ custom limit sớm là xứng đáng, nhất là enterprise. Cách sạch là “mặc định theo plan, override theo khách hàng.” Lưu override do admin đặt per-org (và đôi khi per-endpoint) và đảm bảo nó tồn tại qua thay đổi plan. Quyết định ai có thể yêu cầu thay đổi và bao lâu có hiệu lực.
Ví dụ: khách hàng import 50,000 bản ghi vào ngày cuối tháng. Nếu quota tháng sắp hết, cảnh báo mềm ở 80–90% cho họ thời gian tạm dừng. Rate limit per-second ngăn import làm ngập API. Override org đã được duyệt (tạm thời hoặc lâu dài) giữ doanh nghiệp tiếp tục hoạt động.
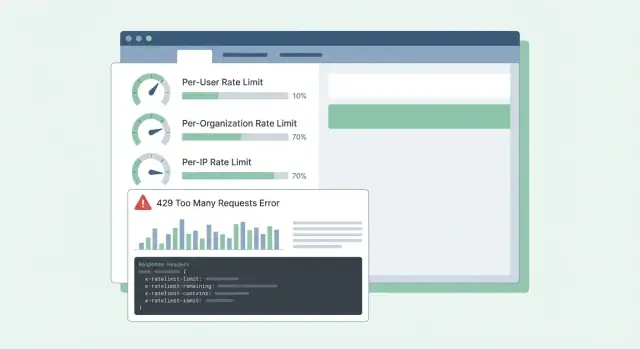
Bắt đầu bằng việc ghi rõ bạn sẽ đếm gì và thuộc về ai. Hầu hết đội kết luận với ba danh tính: user đã đăng nhập, org (workspace), và client IP.
Kế hoạch thực tế:
Khi đặt giới hạn, nghĩ theo tier và nhóm endpoint, không phải một con số toàn cục duy nhất. Lỗi thường gặp là dựa vào counter in-memory trên nhiều app server. Counter không đồng ý, và người dùng thấy 429 “ngẫu nhiên”. Store chia sẻ như Redis giữ giới hạn ổn định giữa các instance, và TTL giữ dữ liệu nhỏ.
Rollout quan trọng. Bắt đầu ở chế độ “chỉ báo cáo” (log những gì sẽ bị chặn), rồi thi hành với một nhóm endpoint, sau đó mở rộng. Đó là cách tránh thức dậy vì một đống ticket hỗ trợ.
Khi khách hàng chạm giới hạn, kết quả tệ nhất là bối rối: “API của bạn hỏng hay mình làm gì sai?” Phản hồi rõ ràng, nhất quán giảm ticket và giúp người ta sửa client.
Dùng HTTP 429 Too Many Requests khi bạn đang chặn. Giữ body predictable để SDK và dashboard có thể đọc.
Dưới đây là một JSON dạng đơn giản hoạt động tốt cho per-user, per-org và per-IP limits:
{
"error": {
"code": "rate_limit_exceeded",
"message": "Rate limit exceeded for org. Try again later.",
"limit_scope": "org",
"reset_at": "2026-01-17T12:34:56Z",
"request_id": "req_01H..."
}
}
Header nên giải thích cửa sổ hiện tại và client có thể làm gì tiếp. Nếu chỉ thêm vài header, bắt đầu với: RateLimit-Limit, RateLimit-Remaining, RateLimit-Reset, Retry-After, và X-Request-Id.
Ví dụ: cron job của khách chạy mỗi phút bỗng thất bại. Với 429 cộng RateLimit-Remaining: 0 và Retry-After: 20, họ biết ngay đó là giới hạn chứ không phải outage, và có thể delay retry 20 giây. Nếu họ chia X-Request-Id với support, bạn tìm được event nhanh.
Một chi tiết nữa: trả cùng các header đó trên request thành công. Khách hàng có thể thấy họ đang tới gần giới hạn trước khi chạm.
Client tốt làm cho giới hạn có cảm giác công bằng. Client xấu biến một giới hạn tạm thời thành outage bằng cách bắn mạnh hơn.
Khi nhận 429, coi đó là tín hiệu chậm lại. Nếu response cho biết khi nào thử lại (ví dụ qua Retry-After), chờ ít nhất thời gian đó. Nếu không, dùng exponential backoff và thêm jitter để cả nghìn client không retry cùng lúc.
Giữ retry trong giới hạn: đặt cap delay giữa các lần (ví dụ 30–60s) và cap tổng thời gian retry (ví dụ dừng sau 2 phút và báo lỗi). Đồng thời log event kèm thông tin giới hạn để dev điều chỉnh sau.
Đừng retry mọi thứ. Nhiều lỗi không thể thành công bằng retry thuần túy: 400 validation, 401/403 auth, 404 not found, và 409 conflict phản ánh quy tắc nghiệp vụ thực.
Retry với endpoint write (create, charge, send email) rủi ro vì timeout rồi client retry có thể tạo bản ghi trùng. Dùng idempotency keys: client gửi một key duy nhất cho mỗi hành động logic, và server trả cùng kết quả cho các lần lặp lại cùng key.
SDK tốt có thể làm việc này dễ hơn bằng cách hiển thị cho dev: status (429), nên chờ bao lâu, request có an toàn để retry không, và một thông điệp như “Rate limit exceeded for org. Retry after 8s or reduce concurrency.”
Hầu hết ticket hỗ trợ về giới hạn không phải về giới hạn mà về bất ngờ. Nếu người dùng không thể dự đoán bước tiếp theo, họ cho rằng API hỏng hoặc không công bằng.
Chỉ dùng giới hạn theo IP là sai lầm thường gặp. Nhiều đội đứng sau một IP công cộng (Wi‑Fi văn phòng, nhà mạng di động, cloud NAT). Nếu bạn giới hạn theo IP, một khách bận có thể chặn mọi người cùng mạng. Ưu tiên per-user và per-org, dùng per-IP chủ yếu làm lưới an toàn.
Vấn đề khác là đối xử tất cả endpoint như nhau. Một GET rẻ tiền và một job export nặng không nên dùng chung ngân sách. Nếu không, khách hàng tiêu allowance khi lướt bình thường rồi bị chặn khi muốn làm việc thực sự. Tách bucket theo nhóm endpoint hoặc gán trọng số theo chi phí request.
Thời gian reset cũng cần rõ. “Reset hàng ngày” chưa đủ. Là múi giờ nào? Rolling window hay reset nửa đêm? Nếu reset theo lịch, nói rõ múi giờ. Nếu rolling window, nói rõ độ dài cửa sổ.
Cuối cùng, lỗi mơ hồ tạo hỗn loạn. Trả 500 hoặc JSON chung chung khiến người ta retry mạnh hơn. Dùng 429 và kèm header RateLimit để client biết cách back off.
Ví dụ: nếu một đội xây integration Koder.ai từ mạng công ty chia sẻ, giới hạn chỉ theo IP có thể chặn cả org và trông như outage ngẫu nhiên. Chiều giới hạn rõ và phản hồi 429 rõ ngăn việc đó.
Trước khi bật giới hạn cho mọi người, rà soát lần cuối tập trung vào tính dự đoán:
Retry-After và header RateLimit (Limit, Remaining, Reset). Trong body JSON, có message ngắn, giới hạn nào bị chạm và khi thử lại.Một kiểm tra cảm tính: nếu sản phẩm bạn có các tier Free, Pro, Business, Enterprise (như Koder.ai), bạn nên giải thích được bằng ngôn ngữ đơn giản khách hàng bình thường làm được bao nhiêu mỗi phút và mỗi ngày, và endpoint nào xử lý khác.
Nếu bạn không thể giải thích một 429 rõ, khách hàng sẽ nghĩ API bị hỏng chứ không phải đang bảo vệ dịch vụ.
Hãy tưởng tượng B2B SaaS nơi mọi người làm việc trong workspace (org). Một vài power user chạy export nặng, và nhiều nhân viên ngồi sau cùng một IP văn phòng. Nếu bạn chỉ giới hạn theo IP, bạn chặn cả công ty. Nếu chỉ theo user, một script vẫn có thể làm tổn hại cả workspace.
Một hỗn hợp thực tế là:
Khi ai đó chạm giới hạn, thông điệp của bạn nên nói họ đã làm gì, cần làm gì tiếp, và khi thử lại. Hỗ trợ nên có thể đứng sau câu chữ như:
“Request rate exceeded for workspace ACME. You can retry after 23 seconds. If you are running an export, reduce concurrency to 2 or schedule it off-peak. If this blocks normal use, reply with your workspace ID and timestamp and we can review your quota.”
Ghép thông điệp đó với Retry-After và header RateLimit nhất quán để khách hàng không phải đoán.
Rollout tránh bất ngờ: chỉ quan sát trước, rồi cảnh báo (header và warning mềm), sau đó thi hành (429 với thời gian retry rõ), rồi tinh chỉnh ngưỡng theo tier, và review sau các bản phát hành lớn hoặc onboarding khách hàng.
Nếu bạn muốn nhanh chuyển ý tưởng này thành mã chạy được, một nền tảng vibe-coding như Koder.ai (koder.ai) có thể giúp soạn spec giới hạn nhanh và sinh middleware Go thực thi nhất quán giữa các dịch vụ.
Một rate limit giới hạn tốc độ gửi yêu cầu, ví dụ requests mỗi giây hoặc mỗi phút. Một quota giới hạn tổng mức sử dụng trong khoảng thời gian dài hơn, ví dụ mỗi ngày, mỗi tháng hoặc theo chu kỳ thanh toán.
Nếu bạn muốn ít tình huống “hôm qua còn được”, hãy hiển thị cả hai rõ ràng và làm cho thời điểm reset cụ thể để khách hàng có thể dự đoán hành vi.
Bắt đầu từ lỗi bạn muốn ngăn. Nếu spike gây timeout, bạn cần kiểm soát burst ngắn; nếu một vài endpoint làm chi phí tăng mạnh, bạn cần ngân sách theo chi phí; nếu gặp brute force hoặc scraping, bạn cần biện pháp chống lạm dụng nghiêm ngặt.
Một cách nhanh là hỏi: “Nếu endpoint này tăng 10×, thứ gì sẽ hỏng trước: độ trễ, chi phí, hay an ninh?” Rồi thiết kế giới hạn theo mục tiêu đó.
Dùng limit theo người dùng để ngăn một cá nhân làm chậm đồng nghiệp, và theo tổ chức để giữ workspace trong giới hạn ngân sách và năng lực. Thêm giới hạn theo token khi một khóa tích hợp chia sẻ có thể vượt trội người dùng tương tác.
Xử lý per-IP như lưới an toàn chống abuse, vì mạng chia sẻ có thể khiến giới hạn IP vô tình chặn người dùng hợp lệ.
Token bucket là lựa chọn tốt khi bạn muốn cho phép short bursts nhưng vẫn giữ trung bình ổn định. Nó phù hợp với UX khi dashboard gây ra vài request đồng thời.
Nếu backend không chịu được spike, giải pháp nghiêm ngặt hơn như leaky bucket hoặc xếp hàng rõ ràng sẽ nhất quán hơn, nhưng ít khoan dung với burst.
Thêm concurrency limit khi tổn hại đến từ quá nhiều request đang xử lý cùng lúc chứ không phải số lượng yêu cầu. Điều này hay gặp với endpoint chậm, long polling, streaming hoặc export lớn.
Concurrency cap ngăn client “vẫn trong 60 requests/phút” nhưng giữ hàng trăm kết nối mở cùng lúc.
Trả về HTTP 429 khi bạn đang throttle, và kèm body lỗi rõ ràng nói scope nào bị chặn (user, org, IP, hay token) và khi nào client có thể thử lại. Header hữu ích nhất là Retry-After, vì nó cho client biết chính xác nên chờ bao lâu.
Cũng trả các header rate limit trên request thành công để khách hàng thấy họ đang gần giới hạn trước khi bị chặn.
Quy tắc đơn giản: nếu Retry-After có mặt, hãy chờ ít nhất thời gian đó trước khi retry. Nếu không, dùng exponential backoff kèm chút randomness để tránh nhiều client retry đồng loạt.
Giới hạn retry: không để delay giữa các lần tăng vô hạn, và đừng retry các lỗi cần thay đổi (auth, validation) vì chúng sẽ không thành công bằng retry thuần túy.
Dùng hard limit khi vượt mức sẽ gây hại cho khách hàng khác hoặc sinh chi phí ngay lập tức. Dùng soft limit khi bạn muốn cảnh báo trước, cho thời gian sửa lỗi hoặc cho phép nâng cấp trước khi chặn.
Mẫu thực tế: cảnh báo ở ngưỡng 80–90% rồi mới áp dụng chặn, giảm số ticket hỗ trợ cấp cứu mà vẫn ngăn việc dùng tràn lan.
Giữ giới hạn IP ở mức rộng rãi và chủ yếu nhằm mục đích chống abuse, vì nhiều công ty dùng chung một IP công cộng (NAT, Wi‑Fi văn phòng, nhà mạng di động). Nếu đặt giới hạn IP nghiêm ngặt, bạn có thể vô tình chặn cả khách hàng khi một script chạy sai.
Cho việc điều tiết bình thường, ưu tiên per-user và per-org; per-IP chỉ là backstop.
Triển khai theo giai đoạn để thấy tác động trước khi gây ảnh hưởng cho khách hàng. Bắt đầu với “chỉ báo cáo” để log những gì sẽ bị chặn, rồi áp dụng cho một nhóm endpoint nhỏ hoặc một tập con tenant, sau đó mở rộng.
Theo dõi spike 429, độ trễ do limiter thêm vào, và các identity bị chặn nhiều nhất—những tín hiệu này cho biết ngưỡng hoặc chiều hạn đang sai trước khi thành một cơn hỗ trợ.