27 thg 9, 2025·8 phút
Triển khai Blue/Green & Canary: Chiến lược phát hành rõ ràng
Tìm hiểu khi nào dùng Blue/Green hay Canary, cách dịch chuyển lưu lượng hoạt động, cần giám sát gì, và các bước triển khai/quay lui thực tế để phát hành an toàn hơn.
Blue/Green và Canary có nghĩa là gì
Việc đưa mã mới lên sản phẩm luôn có rủi ro vì một lý do đơn giản: bạn không thực sự biết nó chạy ra sao cho đến khi người dùng thực tế tương tác. Blue/Green và Canary là hai cách phổ biến để giảm rủi ro đó trong khi giữ thời gian chết ở mức thấp nhất có thể.
Blue/Green nói đơn giản
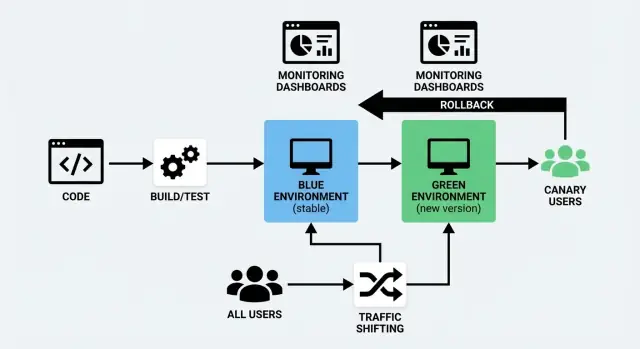
Một triển khai blue/green sử dụng hai môi trường riêng biệt nhưng tương tự nhau:
- Blue: phiên bản đang phục vụ người dùng (môi trường “đang chạy”).
- Green: môi trường thứ hai, sẵn sàng để bạn triển khai phiên bản mới.
Bạn chuẩn bị môi trường Green ở hậu trường—triển khai bản build mới, chạy kiểm tra, làm nóng—rồi chuyển lưu lượng từ Blue sang Green khi bạn tự tin. Nếu có vấn đề, bạn có thể chuyển lại nhanh.
Ý tưởng chính không phải là “hai màu”, mà là một chuyển đổi sạch và có thể đảo ngược.
Canary nói đơn giản
Một phát hành canary là một triển khai dần dần. Thay vì chuyển tất cả cùng lúc, bạn gửi phiên bản mới cho một phần nhỏ người dùng trước (ví dụ 1–5%). Nếu mọi thứ ổn, bạn mở rộng dần từng bước cho đến khi 100% lưu lượng dùng phiên bản mới.
Ý chính là học hỏi từ lưu lượng thực tế trước khi cam kết hoàn toàn.
Mục tiêu chung: phát hành an toàn hơn với ít thời gian chết hơn
Cả hai cách đều là chiến lược triển khai nhằm:
- giảm tác động tới người dùng khi có sự cố
- hỗ trợ triển khai không gián đoạn (hoặc gần như vậy tùy hệ thống)
- làm cho việc quay lui bớt căng thẳng và dễ dự đoán hơn
Chúng thực hiện điều này theo những cách khác nhau: Blue/Green tập trung vào một lần chuyển nhanh giữa các môi trường, trong khi Canary tập trung vào phơi bày có kiểm soát thông qua dịch chuyển lưu lượng.
Không có lựa chọn “tốt nhất” duy nhất
Không có cách nào luôn vượt trội. Lựa chọn phù hợp phụ thuộc vào cách sản phẩm được sử dụng, mức độ tin cậy của việc kiểm thử, tốc độ bạn cần phản hồi, và kiểu lỗi bạn muốn tránh.
Nhiều đội cũng kết hợp cả hai—dùng Blue/Green để đơn giản hoá hạ tầng và các kỹ thuật Canary để phơi bày người dùng dần dần.
Trong các phần tiếp theo, chúng ta sẽ so sánh trực tiếp và chỉ ra khi nào mỗi cách phù hợp nhất.
Blue/Green vs Canary: So sánh nhanh
Blue/Green và Canary đều là cách phát hành thay đổi mà không làm gián đoạn người dùng—nhưng chúng khác nhau ở cách lưu lượng chuyển sang phiên bản mới.
Lưu lượng chuyển như thế nào
Blue/Green chạy hai môi trường đầy đủ: “Blue” (hiện tại) và “Green” (mới). Bạn xác thực Green, rồi chuyển toàn bộ lưu lượng cùng lúc—như gạt một công tắc đã kiểm soát.
Canary gửi phiên bản mới đến một phần nhỏ người dùng trước (ví dụ 1–5%), rồi dịch chuyển lưu lượng dần dần khi bạn theo dõi hiệu suất thực tế.
Ưu nhược điểm đáng lưu ý
| Yếu tố | Blue/Green | Canary |
|---|---|---|
| Tốc độ | Chuyển nhanh sau khi xác thực | Chậm hơn theo thiết kế (ramp dần) |
| Rủi ro | Trung bình: nếu sai thì ảnh hưởng mọi người sau khi chuyển | Thấp hơn: vấn đề thường hiện ra trước khi rollout đầy đủ |
| Độ phức tạp | Trung bình (hai môi trường, chuyển sạch) | Cao hơn (chia lưu lượng, phân tích, bước dần) |
| Chi phí | Cao hơn (gần như gấp đôi năng lực trong thời gian rollout) | Thường thấp hơn (có thể tận dụng năng lực hiện có) |
| Phù hợp cho | Thay đổi lớn, phối hợp quy mô | Cải tiến nhỏ, triển khai thường xuyên |
Hướng dẫn quyết định đơn giản
Chọn Blue/Green khi bạn muốn một khoảnh khắc chuyển đổi sạch và dự đoán được—đặc biệt cho thay đổi lớn, di cư, hoặc phát hành cần tách rõ “cũ vs mới”.
Chọn Canary khi bạn tung bản thường xuyên, muốn học từ thực tế an toàn, và muốn giảm vùng ảnh hưởng bằng cách để các chỉ số hướng dẫn mỗi bước.
Nếu chưa chắc, bắt đầu với Blue/Green cho tính đơn giản vận hành, rồi thêm Canary cho các dịch vụ rủi ro cao khi hệ thống giám sát và thói quen quay lui đã chắc.
Khi nào Blue/Green là lựa chọn phù hợp
Blue/Green là lựa chọn mạnh khi bạn muốn phát hành giống như “gạt công tắc”. Bạn chạy hai môi trường giống sản xuất: Blue (hiện tại) và Green (mới). Khi Green được xác minh, bạn chuyển người dùng sang đó.
Bạn cần gần như không có thời gian chết
Nếu sản phẩm không chấp nhận cửa sổ bảo trì hiển thị—quy trình thanh toán, hệ thống đặt vé, dashboard người đăng nhập—Blue/Green hữu ích vì phiên bản mới được khởi động, làm nóng và kiểm tra trước khi người dùng thực sự được chuyển sang. Phần lớn “thời gian deploy” diễn ra ở bên lề, không hiển thị trước khách hàng.
Bạn muốn quay lui đơn giản nhất có thể
Quay lui thường chỉ là chuyển lưu lượng về Blue. Điều này giá trị khi:
- bản phát hành phải đảo ngược trong vài phút
- bạn muốn tránh sửa nóng khẩn cấp dưới áp lực
- cần phản ứng lỗi rõ ràng, lặp lại được
Lợi ích chính là quay lui không yêu cầu xây lại hay deploy lại—nó chỉ là một công tắc lưu lượng.
Thay đổi cơ sở dữ liệu có thể giữ tương thích
Blue/Green dễ khi migration DB tương thích ngược, vì trong thời gian ngắn Blue và Green có thể cùng tồn tại (và có thể cả hai đọc/ghi tuỳ cách bạn định tuyến và chạy job).
Phù hợp tốt với:
- thay đổi lược đồ dạng bổ sung (cột nullable, bảng mới)
- mở rộng định dạng dữ liệu sao cho mã cũ có thể bỏ qua
Không phù hợp nếu bạn xóa cột, đổi tên trường, hoặc thay đổi ý nghĩa tại chỗ—những việc này có thể phá vỡ lời hứa “chuyển về” trừ khi bạn thiết kế multi-step migration.
Bạn có thể chịu được môi trường trùng lặp và điều khiển định tuyến
Blue/Green yêu cầu dung lượng thêm (hai stack) và một cách để điều hướng lưu lượng (load balancer, ingress, hoặc routing của nền tảng). Nếu bạn đã có tự động hoá để provision môi trường và một cần gạt định tuyến sạch, Blue/Green trở thành mặc định thực tế cho các phát hành độ tin cậy cao.
Khi nào Canary phù hợp hơn
Phát hành canary là chiến lược triển khai nơi bạn tung thay đổi tới một phần nhỏ người dùng trước, học từ kết quả, rồi mở rộng. Đây là lựa chọn khi bạn muốn giảm rủi ro mà không biến cả hệ thống thành một thay đổi lớn cùng lúc.
Bạn có nhiều lưu lượng—và chỉ số rõ ràng
Canary hoạt động tốt nhất cho ứng dụng có lưu lượng lớn vì 1–5% lưu lượng vẫn có thể tạo dữ liệu đáng tin nhanh. Nếu bạn đã theo dõi các chỉ số rõ ràng (tỉ lệ lỗi, độ trễ, chuyển đổi, hoàn tất thanh toán, timeout API), bạn có thể xác thực release từ hành vi thực tế thay vì chỉ dựa vào môi trường test.
Bạn lo về hiệu năng và các trường hợp cạnh
Một số vấn đề chỉ xuất hiện dưới tải thật: truy vấn DB chậm, cache miss, độ trễ vùng, thiết bị lạ, hoặc luồng người dùng hiếm. Với canary, bạn xác nhận thay đổi không tăng lỗi hoặc làm giảm hiệu năng trước khi tới mọi người.
Bạn cần rollout theo giai đoạn, không phải một lần cắt
Nếu sản phẩm phát hành thường xuyên, có nhiều đội đóng góp, hoặc gồm các thay đổi có thể giới thiệu dần (tinh chỉnh UI, thử nghiệm giá, logic đề xuất), canary phù hợp. Bạn có thể tăng từ 1% → 10% → 50% → 100% dựa trên quan sát.
Feature flags là một phần của bộ công cụ
Canary kết hợp tốt với feature flags: bạn deploy mã an toàn, rồi bật tính năng cho một tập người dùng, vùng hoặc tài khoản. Quay lui ít kịch tính—thường chỉ tắt flag thay vì deploy lại.
Nếu bạn hướng tới progressive delivery, canary thường là điểm khởi đầu linh hoạt nhất.
Xem thêm: bài viết về feature flags và progressive delivery
Cơ bản về dịch chuyển lưu lượng (không dùng biệt ngữ)
Dịch chuyển lưu lượng đơn giản là kiểm soát ai nhận phiên bản mới và khi nào. Thay vì gạt mọi người cùng lúc, bạn di chuyển các yêu cầu dần dần (hoặc chọn lọc) từ phiên bản cũ sang phiên bản mới. Đây là trái tim thực tiễn của cả blue/green deployment và canary release—và cũng là điều giúp triển khai không gián đoạn trở nên thực tế.
“Vô-lăng”: nơi lưu lượng được định tuyến
Bạn có thể dịch chuyển lưu lượng ở vài điểm phổ biến trong stack. Lựa chọn đúng tuỳ vào nền tảng bạn chạy và mức độ kiểm soát chi tiết bạn cần.
- Load balancer: chia yêu cầu giữa hai môi trường hoặc hai nhóm server.
- Ingress controller (Kubernetes): định tuyến đến Services khác nhau dựa trên luật.
- Service mesh: điều khiển lưu lượng giữa các dịch vụ với luật chính xác và quan sát tốt hơn.
- CDN / edge routing: hữu ích khi muốn quyết định định tuyến gần người dùng, thường cho traffic web.
Bạn không cần mọi lớp. Chọn một “nguồn sự thật” cho việc định tuyến để quản lý phát hành không trở thành đoán mò.
Các cách chia lưu lượng phổ biến
Hầu hết đội dùng một (hoặc kết hợp) các cách sau cho dịch chuyển lưu lượng:
- Theo phần trăm: 1% → 5% → 25% → 50% → 100%. Đây là mẫu canary cổ điển.
- Dựa trên header: định tuyến các yêu cầu có header cụ thể (ví dụ từ công cụ QA hoặc tester nội bộ) tới phiên bản mới.
- Đoàn người dùng: chuyển cho nhóm cụ thể trước—nhân viên, người dùng beta, một vùng, hoặc phân hạng khách hàng.
Theo phần trăm dễ giải thích nhất, nhưng đoàn người dùng an toàn hơn vì bạn kiểm soát ai thấy thay đổi (và tránh làm các khách hàng lớn bất ngờ trong giờ đầu).
Session và cache: hai “cái bẫy” thường gặp
Hai điều thường phá vỡ kế hoạch triển khai tốt:
Session dính (sticky sessions). Nếu hệ thống khoá người dùng vào một server/phiên bản, chia 10% lưu lượng có thể không thực sự giống 10%. Nó cũng gây lỗi khó hiểu khi người dùng bật qua lại giữa các phiên bản trong cùng phiên.
Làm nóng cache. Phiên bản mới thường chạm cache lạnh (CDN, cache ứng dụng, cache truy vấn DB). Điều đó có thể trông như thoái lui về hiệu năng ngay cả khi mã ổn. Dự kiến thời gian làm nóng cache trước khi tăng lưu lượng, đặc biệt cho trang lưu lượng cao và endpoint tốn kém.
Làm cho thay đổi lưu lượng thành thao tác có kiểm soát
Xử lý thay đổi routing như thay đổi production, không phải bấm nút ngẫu hứng.
Ghi chép:
- ai được phép thay đổi tỷ lệ lưu lượng
- như thế nào được phê duyệt (on-call? release manager? ticket thay đổi?)
- ở đâu làm (cấu hình load balancer, luật ingress, chính sách mesh)
- “dừng” nghĩa là gì (cú huých để tạm dừng rollout và theo kế hoạch quay lui)
Một chút quản trị giúp tránh người tốt ý muốn “nhích lên 50%” khi bạn còn đang kiểm tra canary.
Cần theo dõi gì khi rollout
Tổ chức một buổi diễn tập phát hành
Xây một workflow, triển khai nó, và luyện tập quay lui để ngày phát hành thật sự bình tĩnh.
Rollout không chỉ là “deploy thành công?” Mà là “người dùng thực có trải nghiệm tệ hơn không?” Cách dễ nhất để bình tĩnh khi Blue/Green hoặc Canary là theo dõi một tập tín hiệu nhỏ trả lời: hệ thống có khỏe không, và thay đổi có làm tổn hại khách hàng không?
Bốn tín hiệu cốt lõi: lỗi, độ trễ, bão hoà, tác động người dùng
Tỉ lệ lỗi: theo dõi HTTP 5xx, thất bại yêu cầu, timeout, và lỗi phụ thuộc (DB, thanh toán, API bên thứ ba). Một canary tăng “lỗi nhỏ” vẫn có thể tạo tải hỗ trợ lớn.
Độ trễ: theo dõi p50 và p95 (và p99 nếu có). Thay đổi giữ trung bình ổn nhưng vẫn có thể tạo các chậm chờn dài khiến người dùng cảm nhận được.
Bão hoà: xem mức “đầy” của hệ thống—CPU, memory, disk IO, kết nối DB, độ sâu queue, thread pool. Vấn đề bão hoà thường xuất hiện trước khi sập hoàn toàn.
Tín hiệu tác động người dùng: đo những gì người dùng thực sự trải nghiệm—thất bại checkout, tỉ lệ đăng nhập thành công, kết quả tìm kiếm trả về, tỉ lệ crash app, thời gian tải trang quan trọng. Những chỉ số này thường ý nghĩa hơn chỉ số hạ tầng.
Xây dashboard phát hành mọi người đọc được
Tạo một dashboard nhỏ vừa một màn hình và chia sẻ trong kênh phát hành. Giữ nhất quán giữa các rollout để mọi người không phải đi tìm biểu đồ.
Bao gồm:
- tỉ lệ lỗi (tổng + endpoint quan trọng)
- độ trễ (p50/p95 cho các đường dẫn then chốt)
- bão hoà (3 hạn chế hàng đầu cho stack, ví dụ CPU app, kết nối DB, độ sâu queue)
- KPI tác động người dùng (1–3 luồng kinh doanh quan trọng)
Nếu chạy canary, phân đoạn chỉ số theo phiên bản/nhóm instance để so sánh canary vs baseline trực tiếp. Với blue/green, so sánh môi trường mới và cũ trong cửa sổ cutover.
Đặt ngưỡng rõ ràng cho quyết định tạm dừng/quay lui
Quyết định trước khi thay đổi lưu lượng. Ví dụ ngưỡng có thể là:
- tỉ lệ lỗi tăng X% so baseline trong Y phút
- p95 latency vượt ngưỡng cố định (hoặc tăng X% so baseline)
- KPI tác động người dùng rơi xuống dưới mức chấp nhận được
Số cụ thể tuỳ dịch vụ, nhưng quan trọng là đồng thuận. Khi mọi người biết kế hoạch quay lui và trigger, bạn tránh tranh luận khi khách hàng đang bị ảnh hưởng.
Cảnh báo tập trung vào cửa sổ rollout
Thêm (hoặc siết) cảnh báo trong thời gian rollout:
- tăng đột ngột 5xx/timeout
- thoái lui độ trễ trên các route then chốt
- tăng nhanh các tín hiệu bão hoà (pool kết nối, queue)
Giữ cảnh báo hành động được: “cái gì thay đổi, ở đâu, và làm gì tiếp theo.” Nếu cảnh báo ồn ào, người ta sẽ bỏ qua tín hiệu quan trọng khi dịch chuyển lưu lượng.
Kiểm tra trước phát hành để bắt lỗi sớm
Phần lớn thất bại rollout không phải do “bug lớn” mà do sai lệch nhỏ: config thiếu, migration DB sai, chứng chỉ hết hạn, hoặc tích hợp khác hành xử khác trong môi trường mới. Kiểm tra tiền phát hành là cơ hội bắt những việc này khi vùng ảnh hưởng còn nhỏ.
Bắt đầu với health check và smoke test
Trước khi thay lưu lượng (dù blue/green hay canary), xác nhận phiên bản mới cơ bản còn sống và có thể phục vụ:
- đảm bảo endpoint health trả OK (không chỉ “process đang chạy”)
- xác nhận phụ thuộc: DB, cache, queue, object storage, nhà cung cấp email/SMS
- xác nhận secrets và biến môi trường tồn tại và scope đúng
Chạy test end-to-end nhanh trên môi trường mới
Unit test tốt, nhưng không chứng minh hệ thống deploy hoạt động. Chạy một bộ end-to-end tự động ngắn trên môi trường mới, hoàn thành trong vài phút.
Tập trung vào luồng xuyên dịch vụ (web → API → DB → bên thứ ba), và ít nhất một yêu cầu “thực” cho tích hợp chính.
Xác minh các hành trình người dùng then chốt
Test tự động đôi khi bỏ sót. Kiểm tra thủ công ngắn các luồng chính:
- đăng nhập và đặt lại mật khẩu
- luồng thanh toán/checkout (kể cả đường lỗi)
- các hành động “tạo / cập nhật / xoá” cơ bản
Nếu hỗ trợ nhiều vai trò (admin vs customer), kiểm tra tối thiểu một hành trình cho mỗi vai trò.
Giữ checklist sẵn sàng
Checklist biến tri thức nội bộ thành chiến lược triển khai lặp lại. Giữ nó ngắn và hành động được:
- migration DB áp dụng và có thể đảo ngược (hoặc rõ là an toàn)
- observability sẵn sàng: logs, dashboard, alert cho chỉ số chính
- kế hoạch quay lui đã review (ai, như thế nào, và “dừng” là gì)
Khi các kiểm tra này thành thói quen, dịch chuyển lưu lượng là bước được kiểm soát—không phải một cú nhảy niềm tin.
Blue/Green Rollout: Playbook thực tế
Sở hữu đường dẫn phát hành
Giữ quyền kiểm soát bằng cách xuất mã nguồn bất cứ khi nào bạn cần.
Blue/green dễ chạy khi bạn coi nó như checklist: chuẩn bị, deploy, xác thực, chuyển, quan sát, rồi dọn dẹp.
1) Deploy lên Green (không chạm người dùng)
Đưa phiên bản mới lên Green trong khi Blue tiếp tục phục vụ. Đồng bộ config và secrets để Green thực sự là bản mirror.
2) Xác thực Green trước khi chuyển lưu lượng
Làm các kiểm tra tín hiệu cao nhanh: app khởi động sạch, trang chính tải, thanh toán/đăng nhập hoạt động, và logs bình thường. Nếu có smoke test tự động, chạy bây giờ. Đây cũng là lúc kiểm tra dashboard và alert cho Green.
3) Lập kế hoạch migration DB an toàn (mở/rút)
Blue/green khó khi DB thay đổi. Dùng cách mở/rút:
- Mở (expand): thêm cột/bảng mới tương thích ngược.
- Deploy Green để nó hoạt động với cả lược đồ cũ và mới.
- Rút (contract): loại bỏ trường cũ sau khi Blue nghỉ và bạn tự tin mã mới ổn định.
Điều này tránh tình huống “Green chạy, Blue bị lỗi” khi chuyển.
4) Làm nóng cache và xử lý job nền
Trước khi chuyển, làm nóng cache quan trọng (trang chủ, truy vấn phổ biến) để người dùng không chịu chi phí “khởi động lạnh”.
Với job nền/cron, quyết định ai chạy:
- chạy job chỉ ở một môi trường trong cutover để tránh xử lý đôi
5) Chuyển lưu lượng, rồi quan sát
Gạt routing từ Blue sang Green (load balancer/DNS/ingress). Theo dõi tỉ lệ lỗi, độ trễ và KPI kinh doanh trong một cửa sổ ngắn.
6) Xác minh sau chuyển và dọn dẹp
Kiểm tra theo kiểu người dùng thực, rồi giữ Blue sẵn sàng tạm thời như fallback. Khi ổn định, tắt job Blue, lưu log, và deprovision Blue để giảm chi phí và nhầm lẫn.
Canary Rollout: Playbook thực tế
Canary là về học an toàn. Thay vì gửi toàn bộ người dùng, bạn phơi bày một lát lưu lượng thực, quan sát chặt, rồi mới mở rộng. Mục tiêu không phải “chậm lại” mà là “chứng minh an toàn” bằng dữ liệu ở mỗi bước.
Kế hoạch ramp đơn giản (1–5% → 25% → 50% → 100%)
- Chuẩn bị canary
Deploy phiên bản mới cạnh phiên bản ổn định. Đảm bảo bạn có thể định tuyến tỉ lệ lưu lượng rõ ràng cho từng phiên bản, và cả hai hiển thị trong giám sát (dashboard hoặc tag riêng giúp so sánh).
- Giai đoạn 1: 1–5%
Bắt đầu rất nhỏ. Đây nơi các lỗi hiển nhiên hiện ra nhanh: endpoint hỏng, config thiếu, migration DB bất ngờ, hoặc spike độ trễ.
Ghi chú cho giai đoạn:
- thay đổi trong release (kể cả config nhỏ)
- kỳ vọng xảy ra
- quan sát (lỗi, độ trễ, tác động người dùng)
- Giai đoạn 2: 25%
Nếu giai đoạn 1 sạch, tăng lên ~25%. Bạn sẽ thấy đa dạng thực tế hơn: hành vi người dùng khác nhau, thiết bị hiếm, và concurrency cao hơn.
- Giai đoạn 3: 50%
Nửa lưu lượng là nơi vấn đề về năng lực và hiệu năng rõ hơn. Nếu có giới hạn scale, thường thấy dấu hiệu ở đây.
- Giai đoạn 4: 100% (promote)
Khi chỉ số ổn và tác động người dùng chấp nhận được, chuyển toàn bộ và tuyên bố promoted.
Chọn khoảng thời gian cho mỗi bước
Thời gian tùy theo rủi ro và lưu lượng:
- Thay đổi rủi ro cao hoặc lưu lượng thấp: đợi lâu hơn mỗi giai đoạn để có đủ tín hiệu (ví dụ 30–60 phút hoặc hơn). Dịch vụ ít lưu lượng có thể cần vài giờ để thấy mẫu đáng tin.
- Thay đổi rủi ro thấp với lưu lượng lớn: giai đoạn ngắn hơn được (5–15 phút), vì dữ liệu thu nhanh.
Cân nhắc chu kỳ kinh doanh. Nếu sản phẩm có đỉnh (giờ ăn trưa, cuối tuần, chạy thanh toán), chạy canary đủ lâu để bao phủ điều kiện hay gây lỗi.
Tự động hoá promotion và rollback
Rollout tay tạo chần chừ và không nhất quán. Tự động nơi có thể:
- promote khi chỉ số chính ổn định trong cửa sổ định trước
- rollback khi ngưỡng bị vi phạm (ví dụ tỉ lệ lỗi hoặc độ trễ vượt giới hạn)
Tự động không loại bỏ phán đoán con người—nó giảm độ trễ.
Xem mỗi giai đoạn như một thí nghiệm
Với mỗi bước, ghi:
- tóm tắt thay đổi
- tiêu chí thành công
- kết quả quan sát
- quyết định (promote, giữ, hoặc rollback) và lý do
Những ghi chú này biến lịch sử rollout thành playbook cho lần sau—và giúp điều tra sự cố dễ hơn.
Kế hoạch quay lui và xử lý thất bại
Quay lui dễ nhất khi bạn quyết trước xấu là gì và ai có quyền bấm nút. Kế hoạch quay lui không phải bi quan—nó ngăn các lỗi nhỏ thành gián đoạn dài.
Xác định trigger quay lui rõ ràng
Chọn danh sách ngắn tín hiệu và ngưỡng để không phải tranh luận khi sự cố. Trigger phổ biến:
- tỉ lệ lỗi: spike 5xx, thất bại checkout, lỗi đăng nhập, timeout API
- độ trễ: p95/p99 vượt ngưỡng đã đồng ý trong cửa sổ (ví dụ 5–10 phút)
- KPI kinh doanh: sụt chuyển đổi, thành công thanh toán, đăng ký
Làm cho trigger đo đạc được (“p95 > 800ms trong 10 phút”) và gán người chịu trách nhiệm (on-call, release manager) có quyền hành động ngay.
Giữ quay lui nhanh (và nhàm chán)
Tốc độ quan trọng hơn sự tinh tế. Quay lui của bạn nên là một trong các cách:
- đảo ngược dịch chuyển lưu lượng (thường cho blue/green và canary): đưa lưu lượng về phiên bản trước biết chắc
- deploy lại phiên bản trước: nếu hạ tầng thay đổi, đẩy build ổn định cuối cùng và chạy health checks
Tránh “sửa tay rồi tiếp tục rollout” là bước đầu. Ổn định trước, điều tra sau.
Lập kế hoạch cho rollout một phần
Với canary, một số người dùng có thể đã tạo dữ liệu dưới phiên bản mới. Quyết trước:
- có chuyển ngay người dùng canary về lại không, hay giữ họ ở canary để đánh giá?
- nếu định dạng dữ liệu thay đổi, DB có tương thích ngược không? Nếu không, rollback có thể cần giải pháp khác.
Review sau sự kiện để cải thiện lần sau
Khi ổn định, viết note sau hành động ngắn: điều gì kích hoạt rollback, tín hiệu thiếu, và sẽ thay checklist gì. Xem đó là vòng cải tiến sản phẩm cho quy trình phát hành, không phải đổ lỗi.
Feature Flags và Progressive Delivery
Mang ý tưởng Canary lên Mobile
Tạo ứng dụng Flutter và lặp an toàn khi bạn tung thay đổi dần dần.
Feature flags cho phép tách “deploy” (đưa mã lên production) khỏi “release” (bật cho người dùng). Điều này quan trọng vì bạn có thể dùng cùng pipeline—blue/green hay canary—nhưng kiểm soát phơi bày bằng một công tắc.
Deploy không áp lực, release có chủ ý
Với flags, bạn merge và deploy an toàn ngay cả khi tính năng chưa sẵn sàng cho mọi người. Mã tồn tại nhưng ngủ. Khi tự tin, bạn bật flag dần—thường nhanh hơn so với đẩy build mới—và nếu có vấn đề, tắt flag là xong.
Bật theo mục tiêu (không tất cả hoặc không gì)
Progressive delivery là tăng dần truy cập có chủ ý. Flag có thể bật cho:
- nhóm người dùng cụ thể (nhân viên, beta, hạng trả phí)
- vùng (bắt đầu một quốc gia hoặc data center)
- tỉ lệ người dùng (1% → 10% → 50% → 100%)
Điều này hữu ích khi canary cho thấy phiên bản mới ổn, nhưng bạn vẫn muốn quản lý rủi ro tính năng riêng.
Hàng rào ngăn “nợ flag”
Feature flags mạnh nhưng cần quản trị. Một vài hàng rào giữ chúng gọn và an toàn:
- chủ sở hữu: mỗi flag có team hoặc người chịu trách nhiệm
- hạn xoá: đặt ngày gỡ hoặc ngày review để flag cũ không tích tụ
- tài liệu: viết flag làm gì, ảnh hưởng ai, và cách quay lui
Quy tắc thực tế: nếu ai đó không trả lời được “tắt flag sẽ xảy ra gì?” thì flag chưa sẵn sàng.
Để biết hướng dẫn sâu hơn về sử dụng flag trong chiến lược phát hành, tham khảo bài viết chuyên sâu về feature flags và chiến lược phát hành.
Cách chọn chiến lược và bắt đầu
Chọn giữa blue/green và canary không phải về “cái nào tốt hơn” mà là về rủi ro bạn muốn kiểm soát, và điều bạn có thể vận hành với đội và tooling hiện tại.
Cách nhanh để quyết
Nếu ưu tiên hàng đầu là một cutover sạch, dự đoán được và nút “về phiên bản cũ” dễ dàng, blue/green thường đơn giản hơn.
Nếu ưu tiên là giảm vùng ảnh hưởng và học từ lưu lượng thực trước khi mở rộng, canary an toàn hơn—đặc biệt khi thay đổi thường xuyên hoặc khó kiểm thử.
Quy tắc thực tế: chọn cách đội bạn có thể chạy nhất quán vào 2 giờ sáng khi có gì đó sai.
Bắt đầu nhỏ: pilot một thứ
Chọn một service (hoặc một luồng người dùng) và pilot vài release. Chọn thứ đủ quan trọng để có ý nghĩa, nhưng không quá thiết yếu khiến mọi người tê liệt. Mục tiêu là xây thói quen dịch chuyển lưu lượng, giám sát và quay lui.
Viết runbook ngắn (và phân công)
Ngắn thôi—một trang là được:
- “ tốt ” nghĩa là gì (chỉ số chính và ngưỡng)
- ai chịu trách nhiệm trong rollout
- cách tạm dừng, quay lui và truyền thông
Khi có chủ sở hữu rõ, chiến lược không thành khuyến nghị.
Dùng những gì bạn có trước
Trước khi thêm nền tảng mới, xem công cụ bạn đang dùng: cấu hình load balancer, script deploy, giám sát, và quy trình sự cố. Thêm tooling mới chỉ khi nó thực sự bớt đau trong pilot.
Nếu bạn xây và gửi dịch vụ nhanh, nền tảng kết hợp tạo app và kiểm soát triển khai có thể giảm gánh vận hành. Ví dụ, Koder.ai là một nền tảng giúp tạo app từ giao diện chat—và deploy/host chúng với tính năng an toàn như snapshots và rollback, hỗ trợ custom domains và xuất mã nguồn. Những tính năng đó phù hợp với mục tiêu bài viết: làm cho phát hành lặp lại, có khả quan sát và có thể đảo ngược.
Bước tiếp theo gợi ý
Nếu bạn muốn xem các tuỳ chọn triển khai và workflow được hỗ trợ, xem phần giá và tài liệu triển khai. Rồi lên lịch pilot đầu tiên, ghi lại điều gì hiệu quả, và lặp lại runbook sau mỗi rollout.