02 Eyl 2025·8 dk
API'ler İçin Protobuf vs JSON: Hız, Boyut ve Uyumluluk
Protobuf ve JSON'u API'ler için karşılaştırın: payload boyutu, hız, okunabilirlik, araç desteği, sürümleme ve gerçek ürünlerde hangi formatın daha uygun olduğunu öğrenin.
Protobuf ve JSON'u API'ler için karşılaştırın: payload boyutu, hız, okunabilirlik, araç desteği, sürümleme ve gerçek ürünlerde hangi formatın daha uygun olduğunu öğrenin.
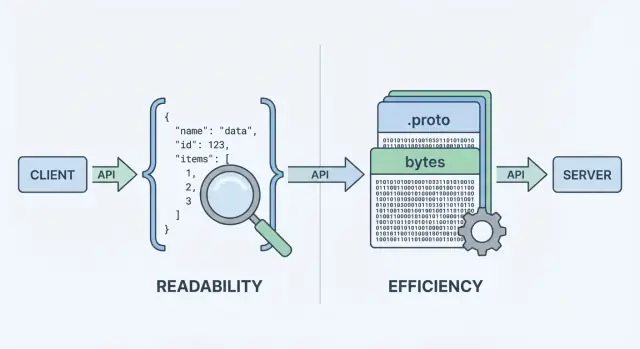
API'niz veri gönderip aldığında, istek ve yanıt gövdelerindeki bilgiyi temsil edecek bir veri formatına ihtiyaç vardır. Bu format daha sonra ağ üzerinden taşınacak byte dizilerine serileştirilir ve istemci/sunucu tarafında tekrar nesnelere deserialize edilir.
En yaygın iki seçenek JSON ve Protocol Buffers (Protobuf)'dır. Aynı iş verisini (kullanıcılar, siparişler, zaman damgaları, öğe listeleri) temsil edebilirler, fakat performans, payload boyutu ve geliştirici iş akışı bakımından farklı ödünler verirler.
JSON (JavaScript Object Notation), nesneler ve diziler gibi basit yapılardan oluşan metin tabanlı bir formattır. REST API'lerde popülerdir çünkü okunması, loglanması ve curl veya tarayıcı DevTools gibi araçlarla incelenmesi kolaydır.
JSON'un her yerde olmasının büyük nedeni: çoğu dilde güçlü destek vardır ve bir yanıtı görsel olarak hemen anlayabilirsiniz.
Protobuf Google tarafından yaratılmış bir ikili serileştirme formatıdır. Metin göndermek yerine .proto gibi bir şema ile tanımlanmış kompakt ikili bir temsil gönderir. Şema alanları, türleri ve sayısal etiketleri tanımlar.
İkili ve şema odaklı olduğu için Protobuf genelde daha küçük payload üretir ve daha hızlı parse edilebilir—bu, yüksek istek hacimlerinde, mobil ağlarda veya gecikme hassas hizmetlerde önemlidir (genellikle gRPC kurulumlarında kullanılır, fakat yalnızca gRPC ile sınırlı değildir).
Gönderdiğiniz şeyi kodlamadan nasıl kodladığınız ayrıdır. Bir “kullanıcı” (id, isim, e-posta) hem JSON hem de Protobuf'ta modellenebilir. Fark şu maliyetlerde ortaya çıkar:
Tek boyuta uyan bir cevap yok. Birçok halka açık API için JSON varsayılan kalmaya devam ediyor çünkü erişilebilir ve esnektir. Hizmetler arası iç iletişim, performans hassas sistemler veya katı sözleşmeler gerektiğinde Protobuf daha iyi bir seçim olabilir. Bu rehberin amacı ideoloji değil kısıtlamalarınıza göre seçim yapmanıza yardımcı olmaktır.
Bir API veri döndürürken “nesneleri” doğrudan ağ üzerinden gönderemez. Önce onları byte dizisine dönüştürmelidir. Bu dönüşüm serileştirmedir—veriyi gönderilebilir bir forma paketleme gibidir. Diğer tarafta istemci bu byte'ları tekrar nesnelere çevirir (deserileştirme).
Tipik istek/yanıt akışı şöyle işler:
Bu “kodlama adımı” format seçiminin önemli olduğu yerdir. JSON kodlama {\"id\":123,\"name\":\"Ava\"} gibi okunabilir metin üretir. Protobuf ikili bytes üretir; insana anlamlı değildir, uygun araçlar olmadan okunamaz.
Her yanıt paketlenip açılmak zorunda olduğundan, format şunları etkiler:
API stiliniz kararınızı etkileyebilir:
curl ile test etmek kolay ve loglamak/incelemek basittir.gRPC ile JSON kullanmak (transcoding ile) veya Protobuf'u düz HTTP üzerinde kullanmak mümkündür; ancak yığınınızın varsayılan ergonomisi (frameworkler, gateway'ler, istemci kütüphaneleri ve hata ayıklama alışkanlıkları) günlük işletimi kolaylaştıran seçimi belirler.
People compare protobuf vs json genelde iki metrikle başlar: payload'un ne kadar büyük olduğu ve encode/decode süresinin ne kadar olduğu. Başlık basittir: JSON metindir ve genelde yer kaplar; Protobuf ikili ve kompakt olduğundan daha az yer kaplar.
JSON alan isimlerini tekrarlar ve sayıları, boolean'ları ve yapıyı metin olarak gönderir; bu yüzden genelde daha fazla byte gönderir. Protobuf alan isimlerini sayısal etiketlerle değiştirir ve değerleri verimli paketler; bu da özellikle büyük nesneler, tekrar eden alanlar ve derin iç içe yapılar için belirgin şekilde daha küçük payload'lar sağlar.
Yine de sıkıştırma farkı daraltabilir. Gzip veya brotli ile JSON'un tekrar eden anahtarları iyi sıkıştırılır, dolayısıyla gerçek dünyadaki boyut farkı küçülebilir. Protobuf da sıkıştırılabilir ancak göreli kazanç genelde daha küçüktür.
JSON ayrıştırıcıları metni tokenize etmeli, doğrulamalı, stringleri sayılara çevirmeli ve kaçış/whitespace/unicode gibi kenar durumlarla uğraşmalıdır. Protobuf çözme daha doğrudandır: etiket oku → tipli değeri oku. Birçok hizmette Protobuf CPU süresini ve çöp oluşumunu azaltır, bu da p95/p99 gecikmeyi iyileştirebilir.
Mobil ağlarda veya yüksek gecikmeli hatlarda daha az byte genelde daha hızlı transfer ve daha az radyo zamanı (pil üzerinde olumlu etkisi olabilir) demektir. Ancak yanıtlar zaten küçükse TLS el sıkışması, sunucu işlem süresi veya diğer overhead'ler öne çıkabilir—format seçiminin etkisi görünmez olabilir.
Gerçek payload'larınızla ölçün:
Bu, “API serileştirme” tartışmalarını sizin API'niz için güvenilir verilere dönüştürür.
Geliştirici deneyiminde JSON genelde öndedir. Bir JSON isteği veya yanıtını hemen hemen her yerde inceleyebilirsiniz: tarayıcı DevTools, curl çıktısı, Postman, reverse proxy'ler ve düz metin loglar. Bir şey bozulduğunda “gerçekte ne gönderdik?” genelde kopyala-yapıştır kadar kolaydır.
Protobuf farklıdır: kompakt ve katıdır ama insan tarafından okunabilir değildir. Ham Protobuf byte'larını loglarsanız base64 blob'ları veya okunmaz ikili görürsünüz. Yükü anlamak için doğru .proto şemasına ve bir decode aracına ihtiyacınız olur (protoc, dil spesifik araçlar veya servisin ürettiği tipler gibi).
JSON ile sorun çoğunlukla şudur: loglanmış payload'u al, gizli bilgileri çıkar, curl ile replay et ve minimal test vakasına ulaşırsın.
Protobuf ile genellikle şunları yaparsınız:
Bu ekstra adım yönetilebilir—ancak ekibin tekrarlanabilir bir iş akışına sahip olması gerekir.
Yapısal loglama her iki formatı da kolaylaştırır. İstek ID'leri, method isimleri, kullanıcı/hesap tanımlayıcıları ve kritik alanları loglayın, tüm gövdeleri değil.
Protobuf için özellikle:
.proto kullanıldı?” kafa karışıklığı olmasın.JSON için, diffları ve olay zaman çizelgelerini kolaylaştırmak üzere kanonikleştirilmiş JSON (anahtar sıralaması sabit) loglamayı düşünün.
API'ler sadece veri taşımakla kalmaz—anlam taşırlar. JSON ile Protobuf arasındaki en büyük fark, o anlamın ne kadar açık ve zorlayıcı tanımlandığıdır.
JSON varsayılan olarak “şemasız”dır: Herhangi bir nesne, herhangi alanlarla gönderilebilir ve birçok istemci makul görünüyorsa kabul eder. Bu esneklik başlangıçta kullanışlıdır, fakat hataları gizleyebilir. Yaygın sorunlar:
userId, diğerinde user_id veya kod yoluna göre eksik alanlar."42", "true", "2025-12-23" gibi gönderilebilir—kolay üretilir, kolay yanlış yorumlanır.null "bilinmiyor", "ayarlanmadı" veya "kasıtlı boş" anlamına gelebilir ve istemciler farklı davranabilir.JSON Schema veya OpenAPI ekleyebilirsiniz ama JSON kendisi bunu zorunlu kılmaz.
Protobuf bir .proto dosyası ile şema gerektirir. Şema ortak bir sözleşme belirtir:
Bu sözleşme istemeden yapılan değişiklikleri önlemeye yardımcı olur—örneğin bir integer'ı string'e çevirme hataları, üretilmiş kodun beklediği türlerden dolayı fark edilebilir.
Protobuf ile sayılar sayı olarak kalır, enum'lar tanımlı değerlere bağlıdır ve timestamp'ler genellikle well-known types ile modellenir (ad-hoc string yerine). "Ayarlanmadı" durumu, proto3'te optional alanlar veya wrapper tipleri kullanıldığında default değerlerden ayırt edilebilir.
Eğer API'niz kesin tiplere ve farklı ekipler/diller arasında öngörülebilir parse davranışına bağımlıysa, Protobuf JSON'a göre daha güçlü rehberlik sağlar.
API'ler evrilir: alan eklersiniz, davranışı değiştirirsiniz ve eski parçaları emekliye ayırırsınız. Amaç sözleşmeyi tüketicileri şaşırtmadan değiştirmektir.
İyi bir evrim stratejisi her iki tarafı da hedefler; genelde minimum bar geriye dönük uyumluluktur.
Protobuf'ta her alanın bir numarası vardır (örn. email = 3). Bu numara—alan adı değil—wire üzerinde gönderilen bilgiyi tanımlar. Bu yüzden:
Güvenli değişiklikler (çoğunlukla)
Riskli değişiklikler (çoğunlukla kırıcı)
En iyi uygulama: eski numara/isimleri reserved ile ayırın ve değişiklik günlüğü tutun.
JSON dahili olarak şema içermediği için uyumluluk uygulamalarınıza bağlıdır:
Değişiklikleri erken belgeleyin: bir alan emekliye ayrıldığında ne kadar süre destekleneceği ve yerine neyin geldiği. Basit bir sürümleme politikası yayınlayın (örn. “eklemeler non-breaking; kaldırmalar yeni major sürüm ister”) ve buna uyun.
JSON ve Protobuf arasında seçim genelde API'nizin nerede çalışması gerektiğine ve ekibinizin neyi sürdürmek istediğine bağlıdır.
JSON neredeyse evrenseldir: her tarayıcı ve backend runtime bunu parse edebilir. Web uygulamasında fetch() + JSON.parse() en kolay yoludur ve proxy'ler, API gateway'leri ve gözlemlenebilirlik araçları genelde JSON'u doğal olarak anlar.
Protobuf tarayıcıda da çalışır, ama sıfır maliyetli bir varsayılan değildir. Genelde bir Protobuf kütüphanesi (veya üretilmiş JS/TS kodu) eklemeniz, bundle boyutunu yönetmeniz ve Protobuf göndereceğiniz HTTP uç noktalarını tarayıcı araçlarının kolayca inceleyip inceleyemeyeceğini belirlemeniz gerekir.
iOS/Android ve backend dillerinde (Go, Java, Kotlin, C#, Python vb.) Protobuf desteği olgunlaşmıştır. Protobuf genelde platformlara özgü kütüphaneler ve .proto dosyalarından kod üretimi varsayar.
Kod üretimi şu faydaları getirir:
Maliyetleri ise:
.proto paketleri yayınlama, sürüm sabitleme)Protobuf sıklıkla gRPC ile birlikte anılır; bu size servis tanımları, istemci stub'ları, stream'ler ve interceptors gibi eksiksiz bir araç hikayesi sunar. gRPC'yi düşünüyorsanız Protobuf doğal bir eşleşmedir.
Geleneksel JSON REST API inşa ediyorsanız JSON'un araç ekosistemi (tarayıcı araçları, curl-dostu hata ayıklama, genel gateway desteği) daha basittir—özellikle halka açık API'ler ve hızlı entegrasyonlar için.
API yüzeyini hâlâ keşfediyorsanız, her iki stilde de hızlı prototip yapmak faydalı olabilir. Örneğin, Koder.ai kullanan ekipler genellikle geniş uyumluluk için bir JSON REST API ve iç verimlilik için dahili gRPC/Protobuf servisi oluşturup gerçek payload'larla karşılaştırma yaparlar. Koder.ai full-stack uygulamalar (React web, Go + PostgreSQL backend, Flutter mobil) üretebildiği için şemalar üzerinde iterasyonu kolaylaştırır ve format kararlarını büyük refaktörlere dönüştürmez.
JSON ve Protobuf seçimi sadece payload boyutu veya hız hakkında değildir. Ayrıca cache katmanları, gateway'ler ve ekibinizin olay anında güvendiği araçlarla ne kadar iyi uyuştuğunu da etkiler.
Çoğu HTTP cache altyapısı (tarayıcı cache'leri, reverse proxy'ler, CDN'ler) HTTP semantiği üzerine optimize edilmiştir; gövde formatından bağımsızdır. Bir CDN uygun yanıtı cache'leyebilir.
Bununla birlikte birçok ekip kenarda HTTP/JSON bekler çünkü incelemek ve sorun gidermek kolaydır. Protobuf ile cache'leme çalışır, fakat dikkat etmeniz gerekenler:
Vary)Cache-Control, ETag, Last-Modified)Her iki formatı da destekliyorsanız içerik pazarlama kullanın:
Accept: application/json veya Accept: application/x-protobuf gönderirContent-Type ile yanıt verirCache'lerin bunu anlaması için Vary: Accept ekleyin. Aksi halde bir cache JSON yanıtını saklayıp Protobuf istemcisine servis edebilir.
API gateway'leri, WAF'ler, istek/yanıt dönüştürücüler ve gözlemlenebilirlik araçları genelde JSON gövdelerini varsayarlar:
İkili Protobuf bu özellikleri sınırlayabilir; veya araçlarınız Protobuf-aware değilse decode adımları eklemeniz gerekir.
Yaygın bir model: kenarlarda JSON, içerde Protobuf:
Bu, dış entegrasyonları basit tutarken Protobuf'un performans avantajlarını kontrol ettiğiniz iç yollarda yakalamanıza olanak verir.
JSON veya Protobuf seçimi verinin nasıl kodlandığını ve parse edildiğini değiştirir—fakat kimlik doğrulama, şifreleme, yetkilendirme ve sunucu tarafı doğrulama gibi temel güvenlik gereksinimlerinin yerini almaz. Hızlı bir serializer, doğrulanmamış girdileri kabul eden bir API'yi kurtaramaz.
Protobuf'un ikili ve okunmaz olması onu “daha güvenli” yapmaz. Saldırganlar verinin insan tarafından okunabilir olmasına ihtiyaç duymaz; endpoint'inize erişmeleri yeterlidir. API gizli alanlar sızdırıyorsa, geçersiz durumları kabul ediyorsa veya zayıf auth varsa, format değiştirmek problemi çözmez.
Transport'u şifreleyin (TLS), yetkilendirme kontrollerini uygulayın, girdileri doğrulayın ve seçtiğiniz format ne olursa olsun güvenli loglama yapın.
Her iki format da ortak riskler taşır:
API'leri yük altında ve kötü niyetli kullanımda güvenilir tutmak için aynı korumaları her iki formata da uygulayın:
Özet: “ikili vs metin formatı” esas olarak performans ve ergonomiyi etkiler. Güvenlik ve güvenilirlik ise tutarlı limitler, güncel bağımlılıklar ve açık doğrulama ile sağlanır—hangi serializer kullandığınızdan bağımsız olarak.
JSON ile Protobuf arasında seçim “hangisi daha iyi”dan ziyade API'nizin neyi optimize etmesi gerektiğiyle ilgilidir: insan dostu ve erişilebilir olmak mı, yoksa verimlilik ve katı sözleşmeler mi.
JSON genelde geniş uyumluluk ve kolay hata ayıklama gerektiğinde güvenli bir tercihtir.
Tipik senaryolar:
Protobuf genelde insan okunabilirlikten ziyade performans ve tutarlılık önemli olduğunda öne çıkar.
Tipik senaryolar:
Bu sorularla hızlıca daraltın:
Eğer hâlâ kararsızsanız, “kenarlarda JSON, içerde Protobuf” yaklaşımı pragmatik bir uzlaşıdır.
Format değiştirmek bir şeyleri baştan yazmak değil; tüketiciler için riski azaltmaktır. En güvenli yollar API'yi kullanılabilir tutar ve geri almayı kolaylaştırır.
Düşük riskli bir alan seçin—genelde iç hizmet çağrısı veya tek bir read-only endpoint. Bu, Protobuf şemasını, üretilmiş istemcileri ve gözlemlenebilirlik değişikliklerini test etmenizi sağlar.
Pratik ilk adım, mevcut bir kaynağın Protobuf temsilini eklemek, JSON şeklini aynı tutmaktır. Böylece veri modelinin nerede belirsiz olduğunu hızlıca görürsünüz (null vs eksik, sayılar vs stringler, tarih formatları) ve şemada düzeltebilirsiniz.
Dış API'ler için çift destek genelde en sorunsuz yoldur:
Content-Type ve Accept başlıklarıyla pazarlayın./v2/...) açın.Bu süre zarfında her iki formatın da aynı kaynak-modelinden üretilmesini sağlayın ki küçük farklar oluşmasın.
Planlayın:
.proto dosyalarını, alan yorumlarını ve somut istek/yanıt örneklerini (hem JSON hem Protobuf) yayınlayın ki tüketiciler veriyi doğru yorumladıklarından emin olsun. Kısa bir “geçiş rehberi” ve değişiklik günlüğü destek yükünü azaltır.
JSON veya Protobuf seçimi ideolojiden çok trafiğinizin, istemcilerinizin ve operasyonel kısıtlarınızın gerçeğiyle ilgilidir. En güvenilir yol ölçmek, kararları belgelemek ve API değişikliklerini sıkıcı yapmak—yani tahmin edilebilir ve küçük tutmaktır.
Temsili endpoint'lerde küçük bir deney çalıştırın.
Ölçtükleriniz:
Staging'de üretim benzeri verilerle başlatın, sonra üretimde küçük bir trafik diliminde doğrulayın.
JSON Schema/OpenAPI veya .proto dosyaları olsun:
Protobuf seçseniz bile dokümantasyonu dostça tutun:
Doküman veya SDK rehberleri varsa bunları görünür yapın (ör. /docs, /blog). Fiyatlama veya kullanım limitleri format seçimlerini etkiliyorsa bunu da belirtin (/pricing).
JSON metin tabanlı, okunması, loglanması ve yaygın araçlarla test edilmesi kolay bir formattır. Protobuf ise .proto şemasıyla tanımlanan kompakt bir ikili formattır; genellikle daha küçük payload ve daha hızlı parsing sağlar.
Tercihi ihtiyaçlara göre yapın: erişim ve hata ayıklama öncelikli ise JSON, verimlilik ve katı sözleşmeler öncelikli ise Protobuf seçin.
API'ler nesneleri değil byte’ları gönderir. Serialization sunucu nesnelerinizi taşınacak bir payload'a (JSON metni veya Protobuf ikili) dönüştürür; deserialization bu byte’ları tekrar istemci/sunucu nesnelerine çevirir.
Format seçimi bant genişliğini, gecikmeyi ve encode/decode için harcanan CPU'yu etkiler.
Çoğu durumda evet—özellikle büyük veya iç içe nesneler ve tekrarlı alanlarda Protobuf, alan isimleri yerine sayısal etiketler ve verimli ikili kodlama kullandığından daha küçük olabilir.
Ancak gzip/brotli etkinse, JSON’un tekrar eden anahtarları iyi sıkıştırılır; sahadaki boyut farkı daralabilir. Hem ham hem de sıkıştırılmış boyutları ölçün.
Olabilir. JSON ayrıştırıcıları metin tokenize etmeli, kaçışları/unicode'u işleyip stringleri sayılara dönüştürmelidir. Protobuf çözme daha doğrudandır (etiket → tipli değer), bu yüzden çoğu durumda CPU süresini ve atıkları azaltır.
Yine de payload çok küçükse gecikme TLS, ağ RTT ve uygulama işinden kaynaklanıyor olabilir.
Varsayılan olarak daha zordur. JSON insan tarafından okunur ve DevTools, loglar, curl, Postman gibi araçlarla kolayca incelenir. Protobuf ikili olduğu için genellikle ilgili .proto şeması ve decode araçları gerekir.
İyi bir uygulama: ikili payload'un yanında decode edilmiş, redakte edilmiş bir debug görünümü (çoğunlukla JSON) loglamak.
JSON varsayılan olarak "şemasız"dır; bir JSON Schema/OpenAPI uygulamadıkça farklı yollarla gönderilen alanlar, string olarak gönderilen sayılar veya belirsiz null semantiği gibi tutarsızlıklara yol açabilir.
Protobuf ise .proto dosyasıyla tipleri zorunlu kılar, güçlü tipli kod üretimi sağlar ve çoklu ekip/dil ortamlarında evrilebilir sözleşmeleri netleştirir.
Protobuf uyumluluğu esas olarak alan numaraları (tag) ile sağlanır. Güvenli değişiklikler genelde yeni, kullanılmamış numaralara sahip opsiyonel alan eklemektir. Zararlı değişiklikler arasında aynı numaranın yeniden kullanılması veya alan tipinin uyumsuz biçimde değiştirilmesi vardır.
Protobuf için reserved kullanın ve değişiklik günlüğü tutun. JSON için ise eklemeci değişiklikleri tercih edin, tipleri değiştirmekten kaçının ve bilinmeyen alanları yok sayın.
Evet. İçerik pazarlığı (content negotiation) kullanın:
Accept: application/json veya Accept: application/x-protobuf gönderirContent-Type ile yanıt verirVary: Accept ekleyinAraçlar pazarlamayı zorlaştırıyorsa ayrı bir endpoint veya sürüm geçici çözüm olabilir.
Çevresel kısıtlarınıza bağlıdır:
Protobuf seçerken kod üretimi, CI iş akışları ve şema sürümlemeyi göz önünde bulundurun.
Her ikisini de güvensiz girdi olarak muamele edin. Format seçimi güvenlik katmanı değildir.
Her iki format için pratik önlemler:
Ayrıca parser/kütüphaneleri güncel tutun.