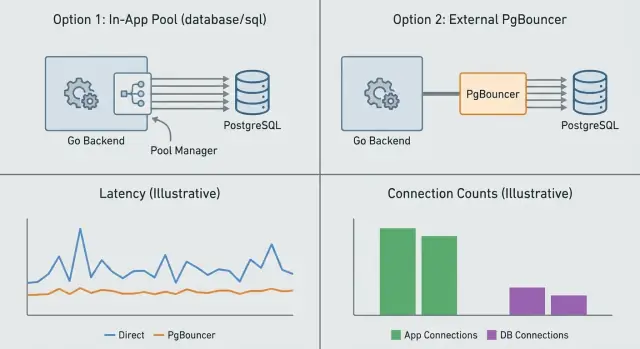
Gecikme sıçramalarının çoğunlukla bağlantılarla nasıl başladığı\n\nBir veritabanı bağlantısı, uygulamanız ile Postgres arasındaki bir telefon hattı gibidir. Bir bağlantı açmak hem uçlarda zaman ve kaynak alır: TCP/TLS kurulumu, kimlik doğrulama, bellek ve Postgres tarafında bir backend süreci. Bir bağlantı havuzu bu “telefon hatlarından” küçük bir seti açık tutar, böylece uygulamanız her istek için yeniden aramak yerine bunları yeniden kullanır.\n\nHavuz kapalıysa veya yanlış boyutlandırıldıysa genelde önce net bir hata görmezsiniz. Rastgele yavaşlamalar görürsünüz. Normalde 20–50 ms alan istekler aniden 500 ms veya 5 saniye alır, p95 fırlar. Sonra zaman aşımı hataları, ardından “too many connections” veya uygulama içinde boş bir bağlantı beklerken oluşan kuyruk görülür.\n\nBağlantı limitleri küçük uygulamalar için bile önemlidir çünkü trafik patlayıcıdır. Bir pazarlama e-postası, bir cron işi veya birkaç yavaş endpoint onlarca isteğin aynı anda veritabanına gitmesine neden olabilir. Her istek yeni bir bağlantı açarsa, Postgres bağlantıları kabul edip yönetmekle çok fazla kapasitesini harcar. Zaten bir havuzunuz varsa ama çok büyükse, çok fazla aktif backend ile Postgres'i aşırı yükleyip bağlam değişimi ve bellek baskısı tetikleyebilirsiniz.\n\nErken belirtilere dikkat edin:\n\n- Ortalama gecikme normal görünürken p95/p99 gecikme sıçramaları\n- Trafik patlamalarında kümelenen zaman aşımı hataları\n- Uygulamada “bağlantı bekleniyor” süresinin artması\n- Postgres tarafında sık bağlantı açma/kapatma veya bağlantı doygunluğu\n\nHavuzlama bağlantı değişimini azaltır ve Postgres'in patlamaları idare etmesine yardımcı olur. Yavaş SQL'i düzeltmez. Eğer bir sorgu tam tablo taraması yapıyorsa veya kilit bekliyorsa, havuzlama sistemin başarısız olma şeklini (daha erken kuyruklama, daha sonra zaman aşımı) değiştirir ama sorguyu hızlandırmaz.\n\n## Uygulama havuzlama vs PgBouncer: her birinin çözdüğü problem\n\nBağlantı havuzlama, aynı anda kaç veritabanı bağlantısı olduğunu ve bunların nasıl yeniden kullanıldığını kontrol etmekle ilgilidir. Bunu uygulama içinde (uygulama düzeyi havuzlama) veya Postgres önünde ayrı bir servisle (PgBouncer) yapabilirsiniz. İlgili ama farklı sorunları çözerler.\n\nUygulama düzeyi havuzlama (Go'da genellikle yerleşik database/sql pool) işlem başına bağlantıları yönetir. Ne zaman yeni bir bağlantı açılacağını, ne zaman yeniden kullanılacağını ve boşta kalanların ne zaman kapatılacağını belirler. Bu her istekte kurulum maliyetinden kaçınır. Yapamayacağı şey, birden fazla uygulama örneği arasında koordinasyon sağlamaktır. Eğer 10 replika çalıştırıyorsanız, pratikte 10 ayrı havuzunuz olur.\n\nPgBouncer uygulamanız ile Postgres arasında durur ve birçok istemci adına havuzlama yapar. Kısa ömürlü istekler, çok sayıda uygulama örneği veya patlayan trafik olduğunda en faydalıdır. Yüzlerce istemci bağlantısı aynı anda gelse bile Postgres'e giden sunucu tarafı bağlantılarını sınırlar.\n\nSorumlulukların basit bir ayrımı:\n\n- Uygulama havuzu bir uygulama örneği içindeki eşzamanlılığı şekillendirir ve her istekte yeniden bağlanmayı engeller.\n- PgBouncer tüm örneklerde toplam Postgres bağlantı sayısını sınırlar ve patlamaları düzeler.\n- Postgres'in yine de CPU, IO ve bellek için sabit sınırları vardır. Havuzlama kapasite yaratmaz.\n\nHer katmanın net bir amacı olduğu sürece birlikte çalışabilirler ve “çift havuzlama” problemleri oluşmaz: her Go süreci için makul bir database/sql havuzu ve küresel bir bağlantı bütçesini zorlayan PgBouncer.\n\nÇoğu zaman karışıklık “daha fazla havuz = daha fazla kapasite” düşüncesidir. Genelde bunun anlamı tersidir. Her servis, worker ve replika kendi büyük havuzuna sahipse toplam bağlantı sayısı patlayabilir ve kuyruklama, bağlam değişimi ve ani gecikme sıçramalarına yol açar.\n\n## Go database/sql havuzlama gerçekte nasıl davranır\n\nGo'da sql.DB tek bir bağlantı değil, bir bağlantı havuzu yöneticisidir. db.Query veya db.Exec çağırdığınızda database/sql boşta bir bağlantı kullanmaya çalışır. Eğer yoksa, limitinize kadar yeni bir bağlantı açabilir veya isteği bekletebilir.\n\nBu bekleme, “esrarengiz gecikme”nin sıklıkla kaynağıdır. Havuz doygun olduğunda istekler uygulama içinde kuyruğa girer. Dışarıdan bakınca Postgres yavaşlamış gibi görünür, ama süre aslında boş bir bağlantı bekleyerek geçiyordur.\n\n### Önemli ayarlar\n\nÇoğu ayar dört ayara dökülür:\n\n- MaxOpenConns: açık bağlantılar (boşta + kullanımda) için sert limit. Buna ulaşınca çağıranlar bloklanır.\n- MaxIdleConns: yeniden kullanım için hazır kaç bağlantı tutulacağı. Çok düşükse sık yeniden bağlanma olur.\n- ConnMaxLifetime: bağlantıları periyodik olarak döndürür. Load balancer'lar ve NAT zaman aşımı için faydalı ama çok düşükse churn oluşturur.\n- ConnMaxIdleTime: çok uzun süre boşta kalan bağlantıları kapatır.\n\nBağlantı yeniden kullanımı genelde gecikmeyi ve veritabanı CPU'sunu düşürür çünkü sürekli kurulum (TCP/TLS, auth, session init) yapılmaz. Ama aşırı büyük bir havuz ters etki de yaratabilir: Postgres'in iyi idare edebileceğinden fazla eşzamanlı sorguya izin vererek içerme ve ek yük yaratır.\n\nİşlemler yerine toplamlarda düşünün. Eğer her Go örneği 50 açık bağlantıya izin veriyorsa ve 20 örneğe ölçekleniyorsanız, fiilen 1.000 bağlantıya izin vermiş olursunuz. Bu sayıyı Postgres sunucunuzun rahatça çalıştırabileceği sayıyla karşılaştırın.\n\nPratik bir başlangıç, MaxOpenConns'ı örnek başına beklenen eşzamanlılığa bağlamak ve sonra arttırmadan önce havuz metrikleri (in-use, idle, wait time) ile doğrulamaktır.\n\n## PgBouncer temelleri ve havuzlama modları\n\nPgBouncer, uygulamanız ile PostgreSQL arasında küçük bir proxy'dir. Servisiniz PgBouncer'a bağlanır ve PgBouncer Postgres'e sınırlı sayıda gerçek sunucu bağlantısı tutar. Patlamalar sırasında PgBouncer istemci işlerini kuyruğa alır, hemen daha fazla Postgres backend oluşturmak yerine. Bu kuyruk kontrollü bir yavaşlama ile veritabanının çökmesi arasındaki fark olabilir.\n\n### Üç havuz modu\n\nPgBouncer'ın üç havuz modu vardır:\n\n- Session pooling: bir istemci bağlı kaldığı sürece aynı sunucu bağlantısını tutar.\n- Transaction pooling: bir istemci bir transaction boyunca sunucu bağlantısını ödünç alır, sonra geri verir.\n- Statement pooling: bir istemci tek bir ifade için sunucu bağlantısını ödünç alır.\n\nSession pooling doğrudan Postgres'e bağlantılara en yakın davranandır. En az şaşırtıcı olandır ama patlayıcı yük sırasında daha az sunucu bağlantısı tasarrufu sağlar.\n\n### Go HTTP API'leri için genelde ne uyuyor\n\nTipik Go HTTP API'leri için transaction pooling genelde güçlü bir varsayıldır. Çoğu istek küçük bir sorgu veya kısa bir transaction yapar ve sonra biter. Transaction pooling birçok istemci bağlantısının daha küçük bir Postgres bağlantı bütçesini paylaşmasına izin verir.\n\nTakas, oturum durumudur. Transaction modunda, tek bir sunucu bağlantısına bağlı olacağını varsayan şeyler bozulabilir veya garip davranabilir, örneğin:\n\n- bir kez oluşturulup sonra tekrar kullanılan prepared statement'lar\n- kalıcı olmasını beklediğiniz oturum ayarları (SET, SET ROLE, search_path)\n- ifadeler arasında kullanılan geçici tablolar ve advisory lock'lar\n\nUygulamanız bu tür duruma bağımlıysa session pooling daha güvenlidir. Statement pooling en kısıtlayıcıdır ve web uygulamaları için nadiren uygundur.\n\nYararlı bir kural: eğer her istek ihtiyacını tek bir transaction içinde kurabiliyorsa, transaction pooling yük altında gecikmeyi daha sabit tutma eğilimindedir. Uzun ömürlü oturum davranışına ihtiyacınız varsa session pooling kullanın ve uygulamada daha sıkı limitlere odaklanın.\n\n## Bir Go backend için doğru stratejiyi seçmek\n\nEğer database/sql kullanan bir Go servisi çalıştırıyorsanız, zaten uygulama tarafında bir havuzunuz var. Birçok ekip için bu yeterlidir: birkaç örnek, istikrarlı trafik ve aşırı patlayıcı olmayan sorgular. Bu durumda en basit ve en güvenli seçenek Go havuzunu ayarlamak, veritabanı bağlantı limitini gerçekçi tutmak ve burada durmaktır.\n\nPgBouncer en çok veritabanına aynı anda çok fazla istemci bağlantısı geldiğinde yardımcı olur. Bu durum çok sayıda uygulama örneği (veya serverless tarzı ölçekleme), patlayıcı trafik ve çok sayıda kısa sorgu ile ortaya çıkar.\n\nPgBouncer yanlış modda kullanılırsa zarar da verebilir. Kodunuz oturum durumuna (geçici tablolar, tekrar kullanılan prepared statement'lar, çağrılar arasında tutulan advisory lock'lar veya oturum düzeyindeki ayarlar) bağımlıysa, transaction pooling kafa karıştırıcı hatalara yol açabilir. Gerçekten session davranışına ihtiyacınız varsa session pooling kullanın veya PgBouncer'dan kaçınıp uygulama havuzlarını dikkatle boyutlandırın.\n\n### Basit bir karar kuralı\n\nAşağıdaki kurala uyun:\n\n- 1–3 uygulama örneğiniz varsa ve toplam açık bağlantılar veritabanı limitinin altında rahatsa, sadece uygulama havuzunu kullanın.\n- Çok sayıda örnek veya otomatik ölçekleme varsa ve örnek başına maksimum açık bağlantıların toplamı Postgres'in kaldırabileceğinin üzerine çıkabiliyorsa PgBouncer ekleyin.\n- Çoğu istek kısa ise (hızlı okumalar, küçük yazmalar) PgBouncer genelde daha fazla fayda sağlar.\n- İstekler bağlantıyı uzun süre tutuyorsa (yavaş raporlar, uzun transaction'lar), önce sorguları düzeltin ve havuz boyutlarında muhafazakar olun.\n\n## Adım adım: güvenli şekilde havuz boyutlandırma ve dağıtım\n\nBağlantı limitleri bir bütçedir. Bütçeyi bir anda harcarsanız, her yeni istek bekler ve kuyruk gecikmesi fırlayabilir. Amaç, verimi koruyarak eşzamanlılığı kontrollü biçimde sınırlamaktır.\n\n### Pratik dağıtım dizisi\n\n1) Bugünün piklerini ve kuyruk gecikmesini ölçün. Pik aktif bağlantıları (ortalama değil), ayrıca istekler ve kilit sorgular için p50/p95/p99 alın. Herhangi bir bağlantı hatası veya zaman aşımını not edin.\n\n2) Uygulama için güvenli bir Postgres bağlantı bütçesi belirleyin. max_connections'tan başlayın ve yönetim erişimi, migration'lar, arka plan işleri ve patlamalar için boşluk bırakın. Eğer birden fazla servis veritabanını paylaşıyorsa bütçeyi kasıtlı olarak bölüştürün.\n\n3) Bütçeyi örnek başına Go limitlerine eşleyin. Uygulama bütçesini örnek sayısına bölün ve MaxOpenConns'ı buna (veya biraz altına) ayarlayın. MaxIdleConns'ı sık yeniden bağlantı olmaması için yeterince yüksek tutun ve yaşam sürelerini bağlantıları ara sıra yenileyecek ama churn yaratmayacak şekilde ayarlayın.\n\n4) Sadece gerekiyorsa PgBouncer ekleyin ve bir mod seçin. Oturum durumuna ihtiyacınız varsa session pooling; en büyük sunucu bağlantısı azaltımını istiyorsanız ve uygulamanız uyumluysa transaction pooling.\n\n5) Kademeli dağıtın ve önce/sonra karşılaştırın. Aynı anda birden fazla şeyi değiştirmeyin: canary uygulayın, sonra kuyruk bekleme süresi, p95 gecikme ve veritabanı CPU'sunu karşılaştırın.\n\nÖrnek: Postgres servisiniz güvenle 200 bağlantı verebiliyorsa ve 10 Go örneğiniz varsa, örnek başına MaxOpenConns=15-18 ile başlayın. Bu patlamalar için boşluk bırakır ve her örneğin aynı anda tavan yapma olasılığını azaltır.\n\n## Erken sorunu yakalamak için izlenecek metrikler\n\nHavuzlama sorunları nadiren önce “çok fazla bağlantı” şeklinde görünür. Çoğu zaman bekleme süresinde yavaş bir artış görürsünüz ve sonra p95/p99 aniden yükselir.\n\nÖnce uygulamanızın raporladıklarına bakın. database/sql ile açık bağlantılar, kullanımda (in-use), boşta (idle), bekleme sayısı ve bekleme süresini izleyin. Eğer trafik aynıyken bekleme sayısı artıyorsa, havuz yetersiz veya bağlantılar çok uzun tutuluyor demektir.\n\nVeritabanı tarafında aktif bağlantıları vs max'i, CPU'yu ve kilit aktivitesini takip edin. CPU düşük ama gecikme yüksekse genelde kuyruklama veya kilitlenme vardır, ham işlem gücü değil.\n\nPgBouncer çalıştırıyorsanız üçüncü bir görüş ekleyin: istemci bağlantıları, Postgres'e olan sunucu bağlantıları ve kuyruk derinliği. Büyüyen bir kuyruk fakat sabit sunucu bağlantıları, bütçenin doygun olduğunu net gösterir.\n\nİyi uyarı sinyalleri:\n\n- p95/p99 yükselirken p50 normal kalıyor\n- uygulama tarafı bağlantı bekleme süresinin artması, özellikle zaman aşımından önce\n- PgBouncer kuyruğunun boşalmadan büyümesi\n- hata oranı ve zaman aşımı sayısının birlikte artması\n- uzun süreli sorgularla birlikte artan kilitler\n\n## Sıçramalara yol açan yaygın yanlış yapılandırmalar\n\nHavuzlama sorunları genelde patlamalar sırasında ortaya çıkar: istekler bir bağlantı için bekler, sonra her şey tekrar normale döner. Kök neden çoğunlukla tek bir örnekte makul görünen ama çok kopya ile tehlikeli olan ayardır.\n\nYaygın nedenler:\n\n- Örnek başına MaxOpenConns ayarlanıp küresel bütçe göz ardı edilmesi. Örnek başına 100 bağlantı ve 20 örnek = 2.000 bağlantı potansiyeli.\n- Çok fazla boşta bağlantı. Boşta kalan backend'ler hâlâ bellek tüketir ve diğer işleri sıkıştırabilir.\n- ConnMaxLifetime / ConnMaxIdleTime çok kısa. Çok sayıda bağlantı aynı anda yenilenirken reconnect fırtınası tetiklenebilir.\n- PgBouncer transaction pooling ile oturum bağımlı kod. Temp tablolar, advisory lock'lar ve oturum ayarları ince hatalarla çalışmayı bırakabilir.\n- Arka plan işler ve sağlık kontrollerinin patlamalar yaratması. Kısa aralıklı pingler veya “her istek için aç-kapa” desenleri yeni bağlantı dalgaları yaratabilir.\n\nBasit bir azaltma yöntemi: havuzlamayı uygulama-yerel varsayılan değil paylaşılmış bir limit olarak ele alın: toplam bağlantıları sınırlandırın, ölçülü boşta havuz tutun ve senkronize reconnectlerden kaçınacak kadar uzun yaşam süreleri kullanın.\n\n## Talep bağlantı bütçenizi aştığında ne yapmalı\n\nTrafik patladığında genelde üç sonuçtan biri olur: istekler boş bir bağlantı için kuyruğa girer, istekler zaman aşımına uğrar veya her şey o kadar yavaşlar ki yeniden denemeler üst üste binmeye başlar.\n\nKuyruklama sinsi olandır. Handler hala çalışıyor ama veritabanı bağlantısı için beklemede. Bu bekleme yanıt süresinin bir parçası olur; küçük bir havuz 50 ms'lik bir sorguyu yük altında saniyeler haline getirebilir.\n\nYardımcı bir model: havuzunuzda 30 kullanılabilir bağlantı varsa ve bir anda 300 eşzamanlı istek veritabanına ihtiyaç duyuyorsa, 270 tanesi beklemek zorundadır. Eğer her istek bağlantıyı 100 ms tutuyorsa, kuyruk gecikmesi hızla saniyelere çıkar.\n\nAçık bir zaman aşımı bütçesi belirleyin ve ona bağlı kalın. Uygulama zaman aşımı veritabanı zaman aşımından biraz daha kısa olmalı ki işler hızlıca başarısız olsun ve baskıyı azaltın, sonsuza dek bekleyip işi asla serbest bırakmayın.\n\n- Uygulama: bir istek süresi sınırı ve DB çağrısı için biraz daha kısa bir deadline\n- DB: tek bir kötü sorgunun bağlantıları tutmasını engelleyecek statement_timeout\n- Havuzlayıcı (kullanılıyorsa): kuyruk bekleme zaman aşımı, sonsuz kuyruk yerine reddi sağlamak için\n\nSonra geri basınç ekleyin ki havuzu aşmayın. Öngörülebilir birkaç mekanizma seçin: endpoint başına eşzamanlılık sınırı koyma, açık hatalarla yük atma (429 gibi) veya arka plan işleri kullanıcı trafiğinden ayırma.\n\nVe en nihayetinde, önce yavaş sorguları düzeltin. Havuz baskısı altında yavaş sorgular bağlantıları daha uzun tutar, bu beklemeleri artırır, zaman aşımı yaratır ve yeniden denemeler birikir. Bu geri besleme döngüsü “biraz yavaş”ı “her şey yavaş”a çevirir.\n\n## Tahmin olmadan yük testi ve kapasite planlama\n\nYük testini bağlantı bütçenizi doğrulamanın bir yolu olarak ele alın, sadece throughput değil. Amaç, havuzlamanın baskı altındayken staging'de olduğu gibi davrandığını doğrulamaktır.\n\nGerçekçi trafikle test edin: aynı istek karışımı, patlama desenleri ve üretimde çalıştırdığınız uygulama örneği sayısı. "Tek endpoint" kıyaslamaları genelde havuz problemlerini saklar ve üretim günü sürpriz olur.\n\nBir ısınma (warm-up) süreci ekleyin ki soğuk cache'ler ve ramp-up etkileri ölçümlere karışmasın. Havuzların normal boyutuna ulaşmasına izin verin, sonra kaydetmeye başlayın.\n\nStratejileri karşılaştırıyorsanız iş yükünü aynı tutun ve şunları çalıştırın:\n\n- sadece uygulama havuzlaması (ayarlanmış database/sql, PgBouncer yok)\n- PgBouncer önünde (uygulamalar küçük havuzlar tutar, PgBouncer sunucu bağlantılarını sınırlar)\n- her ikisi birlikte (küçük uygulama havuzları + PgBouncer)\n\nHer çalışmadan sonra tekrar kullanabileceğiniz küçük bir skor kartı kaydedin:\n\n- steady-state ve patlama sırasında p95 ve p99 istek gecikmesi\n- maksimum toplam bağlantılar (istemci ve sunucu tarafı)\n- kuyruk süresi sinyalleri (boş bağlantı bekleme)\n- hata oranı ve zaman aşımı sayısı\n- gecikmenin hızla yükselmeye başladığı noktadaki throughput\n\nZamanla bu, kapasite planlamayı tahminden çıkarıp tekrarlanabilir hale getirir.\n\n## Hızlı kontrol listesi ve sonraki adımlar\n\nHavuz boyutlarına dokunmadan önce bir sayı yazın: bağlantı bütçeniz. Bu, bu ortam için (dev, staging, prod) güvenli maksimum aktif Postgres bağlantı sayısıdır; arka plan işleri ve yönetim erişimi dahil. Eğer söyleyemiyorsanız şans eseri ayarlıyorsunuz demektir.\n\nHızlı kontrol listesi:\n\n- Go'da açık bir maksimum ayarlayın ve (örnek sayısı x MaxOpenConns) bütçeye (veya PgBouncer tavanına) uyduğundan emin olun.\n- Zaman aşımı koyun ki "sonsuz beklemek" bir patlama olayı gizlemesin.\n- PgBouncer kullanıyorsanız, oturum durumunuza uygun bir havuz modu seçin.\n- Sürekli reconnect oluşturan çok kısa bağlantı ömürlerinden kaçının.\n- max_connections ve ayrılmış bağlantılar planınızla uyuştuğunu doğrulayın.\n\nGeri alma kolay bir rollout planı:\n\n1) Değişiklikleri staging'e uygulayın ve üretimle eşdeğer bir yük testi çalıştırın.\n2) Üretime küçük adımlarla dağıtın (örneklerin bir alt kümesi veya tek bir servis gibi).\n3) En az bir pik penceresi boyunca p95 gecikmeyi, havuz bekleme süresini, hataları ve Postgres bağlantı sayılarını izleyin.\n4) Eğer p95 fırlar veya havuz bekleme artarsa, geri alın ve eşzamanlılığı veya havuz limitlerini düşürün.\n\nEğer Go + PostgreSQL uygulamanızı Koder.ai (koder.ai) üzerine kuruyorsanız, Planning Mode değişikliği ve ne ölçeceğinizi haritalamanıza yardımcı olabilir; snapshot'lar ve geri alma mekanizmaları tail gecikme kötüleşirse geri dönmeyi kolaylaştırır.\n\nSonraki adım: bir sonraki trafik sıçramasından önce bir ölçüm ekleyin. Uygulamada "bağlantı için harcanan zaman" genelde en faydalı metriktir çünkü kullanıcılar hissetmeden önce havuz baskısını gösterir.