14 Eki 2025·7 dk
GraphQL Nedir? API'ler ve Veri Getirme için Açık Rehber
GraphQL'in ne olduğunu, sorgular/mutasyonlar ve şemaların nasıl çalıştığını, REST yerine ne zaman kullanılması gerektiğini ve pratik artı/eksi yönlerini örneklerle öğrenin.
GraphQL'in ne olduğunu, sorgular/mutasyonlar ve şemaların nasıl çalıştığını, REST yerine ne zaman kullanılması gerektiğini ve pratik artı/eksi yönlerini örneklerle öğrenin.
GraphQL, bir sorgu dili ve API çalışma zamanıdır. Basitçe: bir uygulamanın (web, mobil veya başka bir servis) API’den veriyi açık, yapılandırılmış bir istekle talep etme ve sunucunun bu isteğe uygun bir yanıt döndürme yöntemidir.
Birçok API istemcileri sabit bir uç noktanın döndürdüğünü kabul etmeye zorlar. Bu genellikle iki soruna yol açar:
GraphQL ile istemci tam olarak ihtiyaç duyduğu alanları isteyebilir; ne fazlası ne eksigi. Bu, farklı ekranların (veya farklı uygulamaların) aynı temel verinin farklı “dilimlerine” ihtiyaç duyduğu durumlarda özellikle faydalıdır.
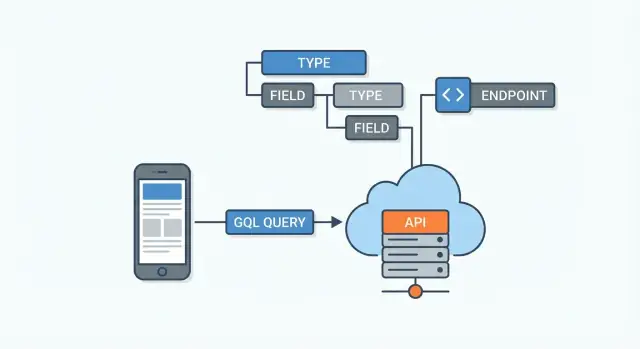
GraphQL tipik olarak istemci uygulamalar ile veri kaynaklarınız arasında bulunur. Bu veri kaynakları şunlar olabilir:
GraphQL sunucusu bir sorgu alır, her istenen alanın doğru yerden nasıl alınacağını belirler ve nihai JSON yanıtını birleştirir.
GraphQL’i özel şekilli bir yanıt sipariş etmek olarak düşünün:
GraphQL sıklıkla yanlış anlaşılır, bu yüzden bazı açıklamalar:
Bu temel tanımı—sorgu dili + API çalışma zamanı—aklınızda tutarsanız, diğer her şey için sağlam bir temel olur.
GraphQL, pratik bir ürün problemini çözmek için yaratıldı: ekipler UI ekranlarına uyan API’lar yapmakla çok vakit harcıyordu.
Geleneksel endpoint tabanlı API'lar genellikle ya ihtiyacınız olmayan verileri göndermek ya da ihtiyacınız olanı almak için ekstra çağrılar yapmak zorunda olma arasında bir tercih sunar. Ürünler büyüdükçe bu sürtünme yavaşlayan sayfalar, karmaşık istemci kodu ve frontend-backend ekipleri arasında zor koordinasyon olarak görünür.
Aşırı veri çekme, bir endpoint “tam” bir obje döndürdüğünde fakat bir ekranın sadece birkaç alana ihtiyacı olduğunda ortaya çıkar. Örneğin mobil profil görünümü sadece isim ve avatar gerektirebilir, ama API adresler, tercihleri, denetim alanları gibi fazladan veriler döndürebilir. Bu bant genişliğini boşa harcar ve kullanıcı deneyimini olumsuz etkileyebilir.
Eksik veri çekme tam tersidir: tek bir endpoint bir görünümün ihtiyacı olan her şeyi içermez, bu yüzden istemci birden fazla istek yapmak ve sonuçları birleştirmek zorunda kalır. Bu gecikmeyi artırır ve kısmi hatalar ortaya çıkma ihtimalini yükseltir.
Birçok REST tarzı API değişime yanıt olarak yeni uç noktalar ekler veya versiyonlar (v1, v2, v3) kullanır. Versiyonlama gerekebilir ama uzun ömürlü bakım işi yaratır: eski istemciler eski sürümleri kullanmaya devam ederken yeni özellikler başka yerde birikir.
GraphQL'in yaklaşımı, mevcut alanları kararlı tutarken zamanla yeni alanlar ve türler ekleyerek şemayı evrimleştirmektir. Bu genellikle yalnızca yeni UI ihtiyaçlarını desteklemek için “yeni sürümler” oluşturma baskısını azaltır.
Modern ürünlerin nadiren sadece bir tüketicisi olur. Web, iOS, Android ve partner entegrasyonları farklı veri şekillerine ihtiyaç duyar.
GraphQL her istemcinin tam olarak ihtiyaç duyduğu alanları talep etmesine izin verecek şekilde tasarlanmıştır—backend her ekran veya cihaz için ayrı bir uç nokta yaratmak zorunda kalmaz.
Bir GraphQL API, şema ile tanımlanır. Bunu sunucu ile her istemci arasındaki anlaşma olarak düşünün: hangi verinin var olduğunu, nasıl bağlandığını ve nelerin istenebileceğini listeler. İstemciler uç noktaları tahmin etmez—şemeyi okurlar ve belirli alanları isterler.
Şema türlerden (ör. User veya Post) ve alanlardan (ör. name veya title) oluşur. Alanlar diğer türlere işaret edebilir; GraphQL ilişkileri bu şekilde modeller.
İşte SDL (Schema Definition Language) ile basit bir örnek:
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Şema güçlü şekilde tiplenmiş olduğu için GraphQL bir isteği çalıştırmadan önce doğrulayabilir. Eğer bir istemci var olmayan bir alan isterse (ör. şemada olmayan Post.publishDate), sunucu isteği net hatalarla reddedebilir veya kısmen yerine getirebilir—belirsiz "belki çalışır" davranışı olmaz.
Şemalar büyümek üzere tasarlanmıştır. Genellikle yeni alanlar ekleyebilirsiniz (ör. User.bio) ve mevcut istemcileri bozmadan ilerlersiniz, çünkü istemciler sadece istedikleri alanı alır. Alanları kaldırmak veya değiştirmek daha hassastır; bu yüzden ekipler genellikle önce alanları kullanımdan kaldırır (deprecate) ve istemcileri kademeli olarak taşır.
Bir GraphQL API genellikle tek bir endpoint üzerinden sunulur (örneğin, /graphql). Birden fazla kaynak için farklı URL’ler çağırmak yerine (örn. /users, /users/123, /users/123/posts) tek bir yere sorgu gönderir ve hangi veriyi geri istediğinizi tanımlarsınız.
Bir sorgu temel olarak bir "alışveriş listesi" gibidir. Basit alanları (örn. id, name) ve aynı istekte iç içe veriyi (örn. bir kullanıcının son gönderileri) talep edebilirsiniz—gereksiz alanları indirmeden.
Küçük bir örnek:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
GraphQL yanıtları öngörülebilirdir: aldığınız JSON, sorgunuzun yapısını yansıtır. Bu frontend üzerinde çalışmayı kolaylaştırır çünkü verinin nerede görüneceğini tahmin etmeniz veya farklı yanıt formatlarını ayrıştırmanız gerekmez.
Basitleştirilmiş bir yanıt şöyle görünebilir:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Eğer bir alanı istemezseniz, dahil edilmez. Eğer isterseniz, beklediğiniz yerde bulunur—bu da GraphQL sorgularını her ekran veya özellik için tam gereken veriyi almak adına temiz bir yol yapar.
Sorgular okumak için; mutasyonlar ise GraphQL API’sinde veriyi değiştirmek (oluşturma, güncelleme, silme) için kullanılır.
Çoğu mutasyon aynı deseni izler:
input nesnesi gibi yapılandırılmış bir girdi gönderir (güncellenecek alanlar vb.).GraphQL mutasyonları genellikle bilerek veri döndürür, sadece "success: true" yerine. Güncellenmiş nesneyi (veya en azından id ve ana alanları) dönmek UI için şunları sağlar:
Yaygın bir tasarım, hem güncellenmiş varlığı hem de varsa hataları içeren bir "payload" tipidir.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
UI odaklı API’ler için iyi bir kural: bir sonraki durumu render etmek için neye ihtiyacınız varsa onu döndürün (ör. güncellenmiş user ve varsa errors). Bu istemciyi basit tutar, neyin değiştiğini tahmin etmeyi önler ve hataların daha zarifce ele alınmasını sağlar.
Bir GraphQL şeması nelerin istenebileceğini tanımlar. Resolver'lar ise bunun gerçekte nasıl alınacağını açıklar. Bir resolver, şemanızdaki belirli bir alana bağlı bir fonksiyondur. Bir istemci o alanı istediğinde GraphQL ilgili resolver'ı çağırır ve değeri alır veya hesaplar.
GraphQL bir sorguyu istenen şekil üzerinde yürüyerek çalıştırır. Her alan için eşleşen resolver bulunur ve çalıştırılır. Bazı resolver'lar zaten bellekte olan bir nesnenin özelliğini döndürür; diğerleri veritabanı çağrısı, başka bir servis çağrısı veya birden fazla kaynağın birleştirilmesi olabilir.
Örneğin şemanızda User.posts varsa, posts resolver'ı userId ile posts tablosunu sorgulayabilir veya ayrı bir Posts servisini çağırabilir.
Resolver'lar şema ile gerçek sistemleriniz arasındaki yapıştırıcıdır:
Bu eşleme esnektir: arka uç uygulamanızı değiştirebilirsiniz, yeter ki şema tutarlı kalsın, istemci sorgu şeklini değiştirmek zorunda kalmasın.
Resolver'lar her alan ve her liste öğesi için çalıştırılabildiğinden, birçok küçük çağrıyı istemeden tetiklemek kolaydır (örneğin 100 kullanıcı için gönderileri 100 ayrı sorgu ile almak). Bu "N+1" deseni yanıtları yavaşlatabilir.
Yaygın düzeltmeler arasında toplu alma (batching) ve önbellekleme (ör. ID’leri toplayıp tek sorguda çekmek) ve istemcilerin hangi iç içe alanları isteyebileceği konusunda bilinçli olmak yer alır.
Yetkilendirme genellikle resolverlarda (veya ortak middleware’lerde) uygulanır çünkü resolverlar kimin istediğini (context üzerinden) ve hangi veriye erişildiğini bilir. Doğrulama iki seviyede olur: GraphQL tip/şekil doğrulamayı otomatik olarak yapar, resolverlar ise iş kurallarını (ör. "sadece adminler bu alanı ayarlayabilir") uygular.
GraphQL’e yeni başlayanları şaşırtan şeylerden biri bir isteğin "başarılı" olabileceği ama yine de hata içerebileceğidir. Bunun nedeni GraphQL’in alan odaklı olmasıdır: bazı alanlar çözümlenebilirken diğerleri çözümlenemeyebilir, bu yüzden kısmi veri dönebilirsiniz.
Tipik bir GraphQL yanıtı hem data hem de errors dizisi içerebilir:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Bu faydalıdır: istemci hâlâ olanı render edebilir (örneğin kullanıcı profili) ve eksik alanla başa çıkabilir.
data genellikle null olur.Hata mesajlarını hata ayıklama için değil, son kullanıcı için yazın. Stack trace, veritabanı isimleri veya iç ID’ler gibi detayları açığa çıkarmaktan kaçının. İyi bir desen:
messageextensions.coderetryable: true)Ayrıntılı hataları sunucu tarafında bir request ID ile loglayın ki içeriği ifşa etmeden inceleyebilesiniz.
Web ve mobil uygulamalarınızın paylaşacağı küçük bir hata “sözleşmesi” tanımlayın: ortak extensions.code değerleri (UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT gibi), ne zaman toast gösterileceği vs alan içi hata gösterimi ve kısmi veri ile ne yapılacağı. Tutarlılık her istemcinin kendi hata kurallarını icat etmesini engeller.
Subscriptions, veri değiştikçe istemcilere veri itme yoludur; istemcinin sürekli sorması yerine sunucu değişikliği anında iletir. Genellikle kalıcı bağlantı üzerinden (çoğunlukla WebSockets) teslim edilir, böylece sunucu bir şey olduğunda olayları hemen gönderebilir.
Bir subscription bir sorguya benzer, ama sonuç tek bir yanıt değildir. O bir sonuç akışıdır—her biri bir olayı temsil eder.
Altta yatan olarak, bir istemci bir konuya (ör. bir sohbet uygulamasında messageAdded) abone olur. Sunucu bir olay yayınladığında, bağlı abonelere subscription’ın seçim kümesine uygun bir payload gönderilir.
Subscriptions, değişikliklerin anında beklendiği yerlerde parlamak için idealdir:
Polling ile istemci her N saniyede bir "Yeni bir şey var mı?" diye sorar. Bu basittir ama özellikle hiçbir şey değişmediğinde istekleri boşa harcar ve hâlâ gecikmeli hissedebilir.
Subscriptions ile sunucu “İşte güncelleme” diye anında bildirir. Bu gereksiz trafiği azaltabilir ve algılanan hızı artırabilir—ama bağlantıları açık tutma ve gerçek zamanlı altyapıyı yönetme maliyeti getirir.
Güncellemeler seyrekse, zaman açısından kritik değilse veya kolayca gruplandırılabiliyorsa polling (veya kullanıcı eylemlerinden sonra yeniden alma) genellikle yeterlidir.
Ayrıca operasyonel ek yük getirir: bağlantı ölçeklendirme, uzun ömürlü oturumlarda yetkilendirme, yeniden denemeler ve izleme. İyi bir kural: sadece gerçek zamanlılık ürün gereksinimi olduğunda subscriptions kullanın, yalnızca hoş bir özellik olduğu için değil.
GraphQL sıklıkla “istemciye güç verir” diye tanımlanır; ama bu gücün maliyetleri vardır. Ödünleri baştan bilmek, GraphQL’in ne zaman iyi bir uyum olduğunu ve ne zaman gereksiz olduğunu anlamanıza yardımcı olur.
En büyük kazanım esnek veri getirmedir: istemciler tam olarak ihtiyaç duydukları alanları isteyebilir, bu aşırı veri çekmeyi azaltabilir ve UI değişikliklerini hızlandırabilir.
Diğer büyük avantaj, GraphQL şeması tarafından sağlanan güçlü sözleşmedir. Şema türler ve kullanılabilir operasyonlar için tek gerçek kaynağı haline gelerek iş birliğini ve araçları geliştirir.
Ekipler genellikle front-end geliştiricilerin yeni uç noktalar beklemeden yineleyebilmesinden dolayı daha iyi istemci üretkenliği görür; Apollo Client gibi araçlar tipler üretebilir ve veri getirmeyi kolaylaştırır.
GraphQL, önbelleklemeyi daha karmaşık hale getirebilir. REST ile önbellekleme genellikle “her URL için”dir. GraphQL’de birçok sorgu aynı endpoint’i paylaşır; bu yüzden önbellekleme sorgu şekillerine, normalleştirilmiş cache’lere ve dikkatli sunucu/istemci yapılandırmasına dayanır.
Sunucu tarafında performans tuzakları vardır. Küçük görünen bir sorgu birçok arka uç çağrısı tetikleyebilir; bu yüzden resolverları dikkatle tasarlamak (batching, N+1’den kaçınma, pahalı alanları kontrol etme) gerekir.
Ayrıca bir öğrenme eğrisi vardır: şemalar, resolverlar ve istemci kalıpları endpoint tabanlı API’lara alışkın ekipler için yabancı olabilir.
İstemciler çok fazla sorgu yapabildiği için GraphQL API’ler sorgu derinliği ve karmaşıklık sınırları uygulamalıdır; kötüye kullanım veya kazara "çok büyük" istekleri önlemek için.
Kimlik doğrulama ve yetkilendirme sadece rota düzeyinde değil, alan düzeyinde de uygulanmalıdır; çünkü farklı alanların farklı erişim kuralları olabilir.
Operasyonel olarak GraphQL’i anlayan loglama, izleme ve tracing için yatırım yapın: operasyon adlarını, değişkenleri (dikkatli), resolver sürelerini ve hata oranlarını takip edin ki yavaş sorguları ve regresyonları erken tespit edebilesiniz.
GraphQL ve REST her ikisi de uygulamaların sunucuyla konuşmasını sağlar, ama bu konuşmayı çok farklı şekillerde yapılandırırlar.
REST kaynak tabanlıdır. Veriyi /users/123 veya /orders?userId=123 gibi birden fazla endpoint çağırarak alırsınız. Her endpoint sunucu tarafından kararlaştırılmış sabit bir veri şekli döndürür.
REST ayrıca HTTP semantiklerine dayanır: GET/POST/PUT/DELETE yöntemleri, durum kodları ve önbellekleme kuralları. Bu, basit CRUD işlemleri veya tarayıcı/proxy önbelleğiyle sıkı çalışma gerektiğinde REST’i doğal kılar.
GraphQL şema tabanlıdır. Birden çok uç nokta yerine genellikle tek bir uç nokta vardır ve istemci hangi alanları istediğini tanımlayan bir sorgu gönderir. Sunucu sorguyu GraphQL şemasına karşı doğrular ve sorgu şekline uyan bir yanıt döner.
Bu "istemci odaklı seçim" GraphQL’in özellikle birden çok ilişkili modelden veri gerektiren UI ekranlarında aşırı/eksik veri çekmeyi azaltabilmesini açıklar.
REST genellikle daha uygun olur:
Birçok ekip karışık kullanır:
Pratik soru "Hangisi daha iyi?" değil, "Hangi kullanım durumu en az karmaşıklıkla uyuyor?" olmalıdır.
GraphQL API tasarımı, ekranları inşa eden insanlar için bir ürün olarak ele alındığında en kolay olur; veritabanınızı birebir yansıtmak yerine gerçek kullanım senaryolarından başlayın. Küçük başlayın, gerçek kullanım durumlarıyla doğrulayın ve ihtiyaçlar arttıkça genişletin.
Ana ekranlarınızı listeleyin (örn. “Ürün listesi”, “Ürün detay”, “Ödeme”). Her ekran için tam olarak hangi alanlara ve hangi etkileşimlere ihtiyaç duyduğunu yazın.
Bu, "tanrısal sorgulardan" kaçınmanıza, aşırı veri çekmeyi azaltmanıza ve nerede filtreleme, sıralama ve sayfalandırma gerektiğini netleştirmenize yardımcı olur.
Önce temel türlerinizi tanımlayın (örn. User, Product, Order) ve ilişkilerini. Sonra ekleyin:
Veritabanı isimlendirmesinden ziyade iş dili isimlendirmesini tercih edin. "placeOrder" "createOrderRecord"dan niyetini daha iyi anlatır.
İsimlendirmeyi tutarlı tutun: öğe için tekil (product), koleksiyon için çoğul (products). Sayfalandırma için genellikle birini seçersiniz:
Yapıyı erken seçin çünkü API’nin yanıt yapısını şekillendirir.
GraphQL şema açıklamaları (descriptions) destekler—bunları alanlar, argümanlar ve uç durumlar için kullanın. Ardından dökümana birkaç örnek yapıştırın (sayfalandırma ve yaygın hata senaryoları dahil). İyi tanımlanmış bir şema introspeksiyon ve API explorer’ları çok daha kullanışlı kılar.
GraphQL ile başlamak çoğunlukla iyi desteklenen birkaç araç seçmek ve güvenilir bir iş akışı kurmakla ilgilidir. Her şeyi bir anda benimsemeye gerek yok—bir sorguyu uçtan uca çalışır hale getirin, sonra genişletin.
Stack’inize ve ne kadar "hazır paket" istediğinize bağlı olarak bir sunucu seçin:
Pratik ilk adım: küçük bir şema (birkaç tür + bir sorgu) tanımlayın, resolver’ları uygulayın ve gerçek bir veri kaynağına bağlayın (hatta hafif bir hafızada liste olsa bile).
Eğer fikirden çalışan bir API’ye daha hızlı geçmek istiyorsanız, Koder.ai gibi bir vibe-coding platformu React ön yüz, Go + PostgreSQL arka uç ile küçük bir tam-yığın uygulamayı iskeletleyip sohbet yoluyla şema/resolver’larda yinelemenize yardımcı olabilir—hazır olduğunuzda kaynak kodunu dışa aktarabilirsiniz.
Ön uçta seçim genellikle daha katı kurallar ister misiniz yoksa esneklik mi diye bağlıdır:
REST’den göç ediyorsanız, önce bir ekran veya özellik için GraphQL kullanarak başlayın ve yaklaşım kendini kanıtlayana dek diğer parçalar için REST’i koruyun.
Şemanızı bir API sözleşmesi gibi ele alın. Faydalı test katmanları:
Derinleşmek için devam edin:
GraphQL, bir sorgu dili ve API çalışma zamanıdır. İstemciler, tam olarak hangi alanları istediklerini tanımlayan bir sorgu gönderir ve sunucu bu yapıyı yansıtan bir JSON yanıt döner.
Bunu istemciler ile bir veya daha fazla veri kaynağı (veritabanları, REST servisleri, üçüncü taraf API’ler, mikroservisler) arasındaki bir katman olarak düşünmek en doğru yaklaşımdır.
GraphQL öncelikle şunlara yardımcı olur:
İstemcinin yalnızca belirli alanları (iç içe alanlar dahil) talep etmesine izin vererek, GraphQL gereksiz veri transferini azaltabilir ve istemci kodunu sadeleştirebilir.
GraphQL şunlar değildir:
Onu bir depolama veya performans sihirbazı değil, bir API sözleşmesi + yürütme motoru olarak değerlendirin.
Çoğu GraphQL API tek bir endpoint (genellikle /graphql) üzerinden sunulur. Birden fazla URL yerine farklı operasyonları (sorgular/mutasyonlar) o tek noktaya gönderirsiniz.
Pratik sonuç: önbellekleme ve gözlemlenebilirlik genellikle URL yerine operasyon adı + değişkenler üzerinden ele alınır.
Şema, API sözleşmesidir. Şunları tanımlar:
User, Post)User.name)User.posts)Şema olduğu için sunucu sorguları yürütmeden önce doğrulayabilir ve alanlar yoksa net hatalar dönebilir.
GraphQL sorguları okuma işlemleridir. Gereken alanları belirtirsiniz ve yanıt JSON’u sorgunun yapısını yansıtır.
İpuçları:
query GetUserWithPosts).posts(limit: 2)).Mutasyonlar yazma işlemleridir (oluştur/güncelle/sil). Yaygın bir desen:
input nesnesi gönderinSadece success: true yerine veri döndürmek, UI’nin anında güncelleme yapmasına ve cache’lerin tutarlı kalmasına yardımcı olur.
Resolver'lar, her alanın nasıl elde edileceğini söyleyen alan düzeyinde fonksiyonlardır.
Genelde resolverlar şunları yapar:
Yetkilendirme genellikle resolverlarda (veya ortak middleware’de) uygulanır çünkü hangi kullanıcının hangi veriye eriştiğini bağlam (context) üzerinden bilirler.
N+1 desenini kolayca oluşturabilirsiniz (ör. 100 kullanıcı için ayrı ayrı gönderi çekmek).
Yaygın çözümler:
Resolver sürelerini ölçün ve tek bir istekte yinelenen aramaları izleyin.
GraphQL, başarılı bir isteğin aynı zamanda errors dizisi içerebileceği bir yanıta izin verir. Bu, bazı alanlar çözümlenip diğerleri çözümlenemediğinde (ör. yetki yok veya downstream zaman aşımı) kısmi veri dönebileceği anlamına gelir.
İyi uygulamalar:
messagelar yazınextensions.code değerleri kullanın (ör. FORBIDDEN, BAD_USER_INPUT)İstemciler kısmi veriyi ne zaman göstereceklerine veya işlemi tam bir hata olarak mı değerlendireceklerine karar vermelidir.