27 Ağu 2025·7 dk
Arka plan görevleri için Go işçi havuzları: yeniden deneme, iptal ve temiz kapanış
Go işçi havuzları, küçük ekiplerin ağır altyapı eklemeden önce basit desenlerle yeniden denemeler, iptal ve temiz kapanış destekli arka plan görevlerini çalıştırmasına yardımcı olur.
Neden arka plan işleri hızla karışır
Küçük bir Go serviste arka plan işi genellikle basit bir amaçla başlar: HTTP yanıtını hızlı döndür, ağır işi sonra yap. Bu e-posta göndermek, resim boyutlandırmak, başka bir API ile senkronize etmek, arama indekslerini yeniden oluşturmak veya gece raporları çalıştırmak olabilir.
Sorun şu ki bu işler üretimde gerçek iş; yalnızca istek işleme sırasında doğal olarak sahip olduğunuz güvenlik önlemleri yok. Bir HTTP handler’dan başlatılan bir goroutine başlangıçta iyi hissedilir, ta ki deploy ortada bir görevi durdurana, bir üst servis yavaşlayana ya da aynı istek yeniden denenip işi iki kez tetikleyene kadar.
İlk ağrı noktaları öngörülebilir:
- Tıkanan işler: bir çağrı takılır ve işçiler ilerlemeyi durdurur.
- Çift işler: HTTP katmanındaki yeniden denemeler aynı işi tekrar çalıştırır.
- Kapanış planı yok: süreç kapanır ve işler kaybolur ya da yarım kalır.
- Sessiz hatalar: hatalar bir kez (ya da hiç) loglanır ve kaybolur.
- Yeniden deneme fırtınaları: başarısız işler anında yeniden denenir ve bağımlılıkları aşırı yükler.
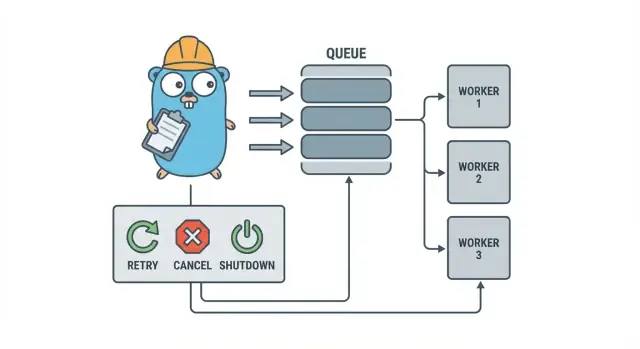
İşte burada küçük, açık bir desen olan Go işçi havuzu fayda sağlar. Eşzamanlılığı bir tercih haline (N işçi), “bunu sonra yap”ı net bir iş türüne dönüştürür ve yeniden denemeleri, zaman aşımı ve iptalleri ele alacağınız tek bir yer verir.
Örnek: bir SaaS uygulamasının fatura göndermesi gerekiyor. Bir toplu aktarım sonrası 500 eşzamanlı gönderim istemezsiniz ve bir isteğin yeniden denenmesi yüzünden aynı faturayı tekrar göndermek de istemezsiniz. Bir işçi havuzu verimliliği sınırlamanıza izin verir ve “#123 faturayı gönder” gibi birimi takip edilen bir iş yapmanıza olanak tanır.
Bir işçi havuzu dayanıklı, çapraz süreç garantileri gerektiğinde doğru araç değildir. Eğer işler çökmelerden kurtulmalı, geleceğe planlanmalı veya birden fazla servis tarafından işlenmeli ise muhtemelen gerçek bir kuyruk ve iş durumu için kalıcı depolama gerekir.
İşçi havuzu modelini basitçe anlatmak
Bir Go işçi havuzu kasıtlı olarak sıkıcıdır: işi kuyruğa koy, sabit sayıda işçi kuyruktan çeksin ve bütün sistemin temiz kapanabildiğinden emin ol.
Temel terimler:
- İş (Job): “bu resmi yeniden boyutlandır” veya “bu faturayı gönder” gibi tek bir iş birimi.
- Kuyruk: işlerin beklediği yer.
- İşçi (Worker): tekrar tekrar bir iş alıp çalıştıran bir goroutine.
- Dispatcher: işleri kabul eden ve kuyruğa veren kısım.
Birçok süreç içi tasarımda bir Go channel kuyruktur. Buffered bir channel, üreticiler bloklanmadan önce sınırlı sayıda iş tutabilir. Bu bloklama geriye baskıdır (backpressure) ve genellikle servisinizin sınırsız istek kabul edip trafik zirvelerinde belleğin bitmesini engelleyen şeydir.
Buffer boyutu sistemin hissini değiştirir. Küçük bir buffer baskıyı çabuk görünür kılar (çağıranlar daha erken bekler). Daha büyük bir buffer kısa patlamaları düzeltir ama aşırı yükü sonra gizleyebilir. Mükemmel bir sayı yoktur, yalnızca ne kadar beklemeyi tolere edebileceğinize uyan bir sayı vardır.
Ayrıca havuz boyutunun sabit mi yoksa değişebilen mi olacağına karar verirsiniz. Sabit havuzlar anlaması daha kolaydır ve kaynak kullanımını öngörülebilir kılar. Otomatik ölçeklenen işçiler düzensiz yüklerde yardımcı olabilir, fakat ne zaman ölçekleneceği, ne kadar ve ne zaman azaltılacağı gibi ek kararlar getirir.
Son olarak, süreç içi bir havuzda “ack” genellikle sadece “işçi işi bitirdi ve hata dönmedi” anlamına gelir. Dış bir broker yoktur, bu yüzden kodunuz “bitti”nin ne olduğunu ve bir iş başarısız ya da iptal olduğunda ne olacağını tanımlar.
Tasarım hedefleri: yeniden deneme, iptal ve temiz kapanış
Bir işçi havuzu mekanik olarak basittir: sabit sayıda işçi çalıştırın, onlara iş verin ve işleyin. Değer kontroldedir: öngörülebilir eşzamanlılık, net hata işleme ve yarım kalmış işi bırakmayan bir kapanış yolu.
Küçük ekipleri ayakta tutan üç hedef:
- Eşzamanlılığı sınırla böylece bir zirve veritabanını veya dış bir API’yı bozmaz.
- İşi kaybetmemek (ya da en azından neyin bırakıldığını ve nedenini kesin olarak bilmek).
- Hata ayıklanabilir kalmak: her iş loglar ve birkaç sayaçla izlenebilir olmalı.
Çoğu hata sıradan olsa da, onları farklı ele almak istersiniz:
- Geçici hatalar (ağ kesintileri, rate limit) ki bunlar yeniden denenmeli.
- Kalıcı hatalar (geçersiz giriş, eksik kayıt) ki tekrar denenmemeli.
- Zaman aşımı (bir bağımlılık takılır) ve işçilerin tıkanmasını engellemek için kesilmeli.
İptal hata ile aynı şey değildir. Bu bir karardır: bir kullanıcı iptal etti, bir deploy sürecinizi değiştirdi veya servis kapanıyor. Go’da iptali context iptali ile birinci sınıf sinyal olarak ele alın ve her işin pahalı işe başlamadan önce ve çalışırken birkaç güvenli noktada bunu kontrol etmesini sağlayın.
Temiz kapanış birçok havuzun dağıldığı yerdir. İşler için “güvenli”nin ne anlama geldiğine erken karar verin: uçta olan işleri bitirir misiniz yoksa hızlıca durup sonra yeniden çalıştırılmasını mı beklersiniz? Pratik bir akış:
- Yeni işleri kabul etmeyi durdurun.
- İşçilere mevcut işten sonra durmalarını söyleyin (veya hemen durmalarını isteyin).
- Bir son tarihe kadar bekleyin, sonra zorla çıkın.
Bu kuralları erken tanımlarsanız yeniden denemeler, iptal ve kapanış küçük ve öngörülebilir kalır, ev yapımı bir çerçeveye dönüşmez.
Adım adım: basit bir işçi havuzu oluşturma
Bir işçi havuzu, kanaldan iş çeken ve işi yapan birkaç goroutineden ibarettir. Önemli kısım temelleri öngörülebilir hale getirmektir: bir iş nasıl görünür, işçiler nasıl durur ve tüm işin bittiğini nasıl anlarsınız.
Basit bir Job tipiyle başlayın. Loglar için bir ID, işlenecek yük, yeniden denemeler için bir deneme sayacı, zaman damgaları ve iş başına context verisi saklayacak bir yer verin.
package jobs
import (
"context"
"sync"
"time"
)
type Job struct {
ID string
Payload any
Attempt int
Enqueued time.Time
Started time.Time
Ctx context.Context
Meta map[string]string
}
type Pool struct {
ctx context.Context
cancel context.CancelFunc
jobs chan Job
wg sync.WaitGroup
}
func New(size, queue int) *Pool {
ctx, cancel := context.WithCancel(context.Background())
p := \u00026Pool{ctx: ctx, cancel: cancel, jobs: make(chan Job, queue)}
for i := 0; i \u0003c size; i++ {
go p.worker(i)
}
return p
}
func (p *Pool) worker(_ int) {
for {
select {
case \u0003c-p.ctx.Done():
return
case job, ok := \u0003c-p.jobs:
if !ok {
return
}
p.wg.Add(1)
job.Started = time.Now()
_ = job // call your handler here
p.wg.Done()
}
}
}
// Submit blocks when the queue is full (backpressure).
func (p *Pool) Submit(job Job) error {
if job.Enqueued.IsZero() {
job.Enqueued = time.Now()
}
select {
case \u0003c-p.ctx.Done():
return context.Canceled
case p.jobs \u0003c- job:
return nil
}
}
func (p *Pool) Stop() { p.cancel() }
func (p *Pool) Wait() { p.wg.Wait() }
Hemen vereceğiniz birkaç pratik seçim:
- Kuyruk boyutunu ne kadar beklemeyi tolere edebileceğinize göre seçin.
- Geri baskının (backpressure) çağıranlar için ne anlama geldiğine karar verin: blokla mı, hata mı döndür, yoksa düşür mü?
Stop()veWait()'i ayrı tutun, böylece önce alımı durdurup sonra uçta olan işleri bekleyebilirsiniz.
Framework haline getirmeden yeniden denemeler eklemek
Yeniden denemeler faydalıdır, ama aynı zamanda işçi havuzlarını karışık hale getirir. Hedefi dar tutun: yalnızca başka bir denemenin başarılı olma ihtimali gerçek olduğunda yeniden deneyin ve işe yaramayacağında çabuk durun.
Önce neyin yeniden denenebilir olduğuna karar verin. Geçici problemler (ağ kesintileri, zaman aşımı, “daha sonra deneyin” cevapları) genellikle yeniden denemeye değerdir. Kalıcı olanlar (geçersiz veri, eksik kayıt, yetki reddi) yeniden denenmemelidir.
Küçük bir yeniden deneme politikası genellikle yeterlidir:
- Hataları yeniden denenebilir / denenemez olarak işaretleyin (örneğin
Retryable(err)yardımcı fonksiyonu ile sarmalayın). - Maksimum deneme sayısı belirleyin (genellikle 3–5). Bundan ötesi genelde zaman yakmaktır.
- İşlerin senkronize şekilde yeniden denememesini sağlamak için jitter ile üstel backoff kullanın.
- Gecikmeyi sınırlandırın (örneğin, asla 30 saniyeden fazla uyuma).
- Yeniden denemeleri deneme numarası, sonraki gecikme ve iş ID’si ile loglayın.
Backoff karmaşık olmak zorunda değildir. Yaygın bir şekil: delay = min(base * 2^(attempt-1), max) ve sonra jitter ekleyin (yaklaşık +/- %20 rastgeleleştirin). Jitter önemlidir; aksi halde birçok işçi aynı anda başarısız olur ve aynı anda yeniden dener.
Gecikme nerede olmalı? Küçük sistemler için işçinin içinde time.Sleep yapmak uygundur, ama bu bir işçi yuvasını meşgul eder. Yeniden denemeler nadir ise bu kabul edilebilir. Yeniden denemeler yaygın ya da gecikmeler uzunsa işi tekrar kuyruğa koyup “çalıştırma zamanı” ile yeniden planlamayı düşünün, böylece işçiler diğer işlerle meşgul olabilir.
Son başarısızlıkta açık olun. Başarısız işi ve son hatayı inceleme için saklayın, yeniden oynatmak için yeterli bağlamı loglayın veya düzenli olarak kontrol edeceğiniz bir "dead" listesine atın. Sessiz düşürmelerden kaçının. Hatayı saklayan bir havuz, yeniden denemesi olmayan bir havuzdan daha kötüdür.
İptal ve zaman aşımı: çalışmayı gerçekten durdurmak
Eşzamanlamayı değiştirmeden önce anlık görüntü alın
Yeniden denemeleri veya kapanış mantığını değiştirmeden önce bir anlık görüntü alın, sonra güvenle geri alın.
İşçi havuzları yalnızca durdurulabildiğinde güvenli hisseder. Basit kural: her bloke olabilecek katmanda context.Context geçirin. Bu, gönderim, yürütme ve temizliği kapsar.
Pratik bir kurulum iki zaman sınırı kullanır:
- Bir iş başına zaman aşımı, böylece bir görev bir işçiyi sonsuza dek tutamaz.
- Bir kapanış zaman aşımı, böylece süreç bazı işler işbirliği yapmasa bile çıkabilir.
Bağlamı uçtan uca kullanın
Her işe, işçinin bağlamından türetilmiş kendi context’ini verin. O zaman her yavaş çağrı (DB, HTTP, kuyruklar, dosya I/O) bu context’i kullanmalı ki erken dönebilinsin.
func worker(ctx context.Context, jobs \u0003c-chan Job) {
for {
select {
case \u0003c-ctx.Done():
return
case job, ok := \u0003c-jobs:
if !ok { return }
jobCtx, cancel := context.WithTimeout(ctx, job.Timeout)
_ = job.Run(jobCtx) // Run must respect jobCtx
cancel()
}
}
}
Eğer Run DB’nizi veya bir API’yi çağırıyorsa bu çağrılara context’i bağlayın (QueryContext, NewRequestWithContext veya context kabul eden client metodları gibi). Bir yerlerde bunu göz ardı ederseniz iptal “elinden geleni yapma” olur ve genellikle en çok gerektiğinde başarısız olur.
Kısmi iş ve “yeniden denemesi güvenli” adımlar
İptal iş ortasında olabilir, bu yüzden kısmi çalışmayı normal varsayın. Yeniden çalıştırmalarda çoğaltmayı önlemek için idempotent adımlar hedefleyin. Yaygın yaklaşımlar: ekleme için benzersiz anahtarlar kullanmak (veya upsert), ilerleme işaretçileri yazmak (başlandı/bitti), devam etmeden önce sonucu saklamak ve adımlar arasında ctx.Err() kontrolü yapmak.
Kapanışı bir son tarih gibi ele alın: yeni işleri kabul etmeyi durdurun, işçi context’lerini iptal edin ve uçta olan işlerin kapanış zaman aşımına kadar çıkması için sadece o kadar bekleyin.
Temiz kapanış: süreç çıkmak zorunda kaldığında ne yapılmalı
Temiz bir kapanışın bir görevi vardır: yeni iş almayı durdur, uçta olan işleri durmaları için söyle ve sistemi garip bir durumda bırakmadan çık.
Önce sinyallerle başlayın. Çoğu dağıtımda yerelde SIGINT, süreç yöneticisi veya container runtime’dan SIGTERM görürsünüz. Bir sinyal geldiğinde iptal edilen bir kapanış context’i kullanın ve bunu havuzunuza ve iş handler’larına iletin.
Sonra yeni iş kabul etmeyi durdurun. Artık kimsenin okunmayan bir kanala sonsuza kadar gönderim yapmasına izin vermeyin. Gönderimleri kapalı bir bayrak kontrolü yapan ya da kapanış context’ini seçen tek bir fonksiyonun arkasına koyun.
Kuyruktaki işe ne olacağına karar verin:
- Tüket (Drain): zaten sırada olanları bitir, ama yeni gönderimleri reddet.
- At (Drop): henüz başlamamış olanları at.
Tüketme ödeme ve e-posta gibi şeyler için daha güvenlidir. Atma, önbelleği yeniden hesaplamak gibi “yapılması iyi olur” görevler için uygundur.
Pratik bir kapanış sırası:
- SIGINT/SIGTERM yakalayın ve paylaşılan context’i iptal edin.
- Gönderimleri durdurun (gönderme yolunu kapatın, her zaman iş kanalını kapatmak zorunda değilsiniz).
- İşçilerin bitmesine izin verin ya da context’e göre abort edin.
- WaitGroup ile işçileri bekleyin.
- Bir son tarih uygulayın, sonra çıkın.
Son tarih önemlidir. Örneğin, uçta olan işlerin durması için 10 saniye verin. Bu süreden sonra hâlâ çalışanları loglayın ve çıkın. Bu deployları öngörülebilir kılar ve takılı süreçlerden kaçınır.
İşçi havuzları için günlükleme ve basit metrikler
Bir sonraki yapınız için kredi kazanın
Kısa bir yazı yayınlayın ve Koder.ai üzerinde kullanabileceğiniz kredi kazanın.
Bir işçi havuzu bozulduğunda nadiren yüksek sesle başarısız olur. İşler yavaşlar, yeniden denemeler birikir ve biri “hiçbir şey olmuyor” diye rapor eder. Günlükleme ve birkaç temel sayaç bunu net bir hikâyeye dönüştürür.
Her işe sabit bir ID verin (veya gönderim zamanında oluşturun) ve bu ID’yi her log satırında bulundurun. Logları tutarlı yapın: bir iş başladığında bir satır, bittiğinde bir satır ve başarısız olduğunda bir satır. Eğer yeniden deneme varsa deneme sayısını ve sonraki gecikmeyi loglayın.
Basit bir log şekli:
- start: job_id, worker_id, attempt, kind
- finish: job_id, worker_id, attempt, duration_ms
- fail/retry: job_id, worker_id, attempt, err, next_delay_ms
Metrikler minimum kalsın ama yine de faydalı olsun. Kuyruk uzunluğunu, uçta olan işleri, toplam başarı ve hataları, iş gecikmesini (en azından ortalama ve maks) takip edin. Kuyruk uzunluğu sürekli artıyor ve uçta olan sayısı işçi sayısına sabitlenmişse doygundasınız demektir. Göndericiler iş kanalına veri gönderirken bloklanıyorsa backpressure çağırana ulaşmış demektir. Bu her zaman kötü değildir, ama kasıtlı olmalı.
“İşler takıldıysa” kontrol edilecekler: süreç hâlâ iş alıyor mu, kuyruğun uzunluğu artıyor mu, işçiler canlı mı ve en uzun süredir hangi işler çalışıyor? Uzun çalışma süreleri genellikle eksik zaman aşımlarına, yavaş bağımlılıklara veya asla durmayan bir yeniden deneme döngüsüne işaret eder.
Gerçekçi bir örnek: küçük bir SaaS arka plan kuyruğu
Bir sipariş PAID durumuna geçtiğini düşünün. Ödeme sonrası hemen bir fatura PDF’si oluşturup müşteriye e-posta atmak ve iç ekibi bilgilendirmek gerekiyor. Bu işi web isteğinin engellemesini istemezsiniz. Bu, işçi havuzu için iyi bir uyum çünkü iş gerçek ama sistem hâlâ küçük.
İş yükü minimal olabilir: geri kalanını veritabanından almak için yeterli alan. API handler, sipariş güncellemesiyle aynı transaction içinde jobs(status='queued', type='send_invoice', payload, attempts=0) gibi bir satır yazar, sonra arka plan döngüsü sıradaki işleri poll edip işçi kanalına iter.
type SendInvoiceJob struct {
OrderID string
CustomerID string
Email string
}
Bir işçi bunu alıp mutlu yolunda: siparişi yükler, faturayı oluşturur, e-posta sağlayıcısını çağırır ve işi tamamlandı olarak işaretler.
Yeniden denemeler işin gerçek olduğu yerdir. E-posta sağlayıcınızın geçici bir kesintisi varsa, 1.000 işi sonsuza dek başarısız olmasını ya da her saniye sağlayıcıyı dövmesini istemezsiniz. Pratik yaklaşım:
- Ağ hatalarını ve 5xx cevapları yeniden denenebilir olarak kabul edin.
- Üstel backoff kullanın ve maksimum gecikme koyun (ör. 5s, 15s, 45s, 2m).
- Deneme sayısını sınırlandırın (ör. 10) ve sonra işi başarısız olarak işaretleyin.
- Son hatayı kaydedin ki destek ne olduğunu görebilsin.
Kesinti sırasında işler queued -> in_progress -> tekrar queued (gelecek çalıştırma zamanı ile) şeklinde hareket eder. Sağlayıcı toparlandığında işçiler kuyruğu boşaltır.
Deployu hayal edin. SIGTERM gönderirsiniz. Sürecin yeni iş almayı durdurup uçta olan işleri bitirmesi gerekir. Poll’ü durdurun, işçi kanalına gönderimi durdurun ve işçileri bir süreyle bekleyin. Biten işler tamamlandı olarak işaretlensin. Son tarih geldiğinde hâlâ çalışan işler tekrar queued olarak işaretlenmeli (veya bir watchdog ile in_progress bırakılmalı) ki yeni versiyon başladıktan sonra alınabilsin.
Yaygın hatalar ve tuzaklar
Arka plan işleme hatalarının çoğu iş mantığında değil. Yük altında veya kapanış sırasında ortaya çıkan koordinasyon hatalarından gelir.
Klasik bir tuzak, bir kanalı birden fazla yerden kapatmaktır. Sonuç genelde yeniden üretmesi zor bir panic olur. Her kanal için bir sahip seçin (genelde üretici) ve yalnızca o close(jobs) çağrısın.
Yeniden denemeler iyi niyetle bile arızalara yol açabilir. Her şeyi yeniden denerseniz kalıcı hataları da yeniden denersiniz. Bu zaman israfına, artan yük ve küçük bir sorunu olaya çevirmeye yol açar. Hataları sınıflandırın ve yeniden denemeleri sınırlayın.
Çoğaltmalar (duplicates) dikkat edin. İşçi ortasında çökebilir, zaman aşımı iş bittikten sonra tetiklenebilir veya deploy sırasında yeniden kuyruğa alınabilir. İş idempotent değilse çoğaltmalar gerçek zarara yol açar: iki fatura, iki hoşgeldin e-postası, iki iade.
En sık görülen hatalar:
- Aynı kanalın birden fazla goroutine tarafından kapatılması.
- Kalıcı hataları yeniden denemek yerine yüzeye çıkarmamak.
- İdempotency anahtarı olmaması, böylece çoğaltmalar yan etki yaratır.
- Bellekte sınırı olmayan kuyruğun bellek tüketimini artırması.
context.Context’i görmezden gelmek, böylece kapanış başladığında işler devam eder.
Sınırsız kuyruklar özellikle sinsidir. Bir iş dalgası bellekte gizlice birikebilir. Sınırlı bir channel buffer’ı tercih edin ve dolduğunda ne olacağına karar verin: blokla, düşür veya hata döndür.
Gönderim öncesi hızlı kontrol listesi
Fatura iş hattı prototipi oluşturun
Ödeme sonrası fatura boru hattını ve arka plan işleyici döngüsünü tek bir tanımdan oluşturun.
İşçi havuzunu production’a göndermeden önce işi yaşam döngüsünü açıkça anlatabiliyor olmalısınız. Birisi “bu iş şu anda nerede?” diye sorduğunda cevap tahmin olmamalı.
Pratik bir ön uç kontrol listesi:
- Her durumu ve geçişi adlandırabiliyorsunuz: queued, picked up, running, finished, failed (ve bunları neyin taşıdığını).
- Eşzamanlılık tek bir düğme ile kontrol ediliyor (
workerCount) ve değiştirmek kodu yeniden yazmayı gerektirmiyor. - Yeniden denemeler sınırlı: maksimum deneme sayısı belli, backoff büyüyor ve kalıcı hatalar kasıtlı bir yere gidiyor.
- Kapanış davranışı kanıtlanmış: alımı durduruyorsunuz, uçta olan işleri bitiriyorsunuz ve yine de bir sert zaman aşımı var.
- Loglar temel soruları yanıtlıyor: job ID, deneme numarası, süre ve hata nedeni.
Yayınlamadan önce bir gerçekçi deneme yapın: 100 "makbuz e-postası gönder" işi sıraya koyun, 20’sini başarısız olmaya zorlayın, sonra çalışmanın ortasında servisi yeniden başlatın. Yeniden denemelerin beklendiği gibi davrandığını, yan etkilerin tekrar etmediğini ve zaman aşımı geldiğinde iptalin gerçekten işi durdurduğunu görmelisiniz.
Herhangi bir madde belirsizse şimdi sıkılaştırın. Küçük düzeltmeler daha sonra günler kazandırır.
Sonraki adımlar: daha ağır altyapıya ne zaman geçilmeli (ve ne zaman değil)
Basit bir süreç içi havuz, ürün gençken çoğu zaman yeterlidir. İşleriniz "yapılması iyi olan" türdeyse (e-postalar, önbellek yenileme, rapor üretme) ve onları yeniden çalıştırabiliyorsanız, bir işçi havuzu sistemi anlaşılır kılar.
Süreç içi havuzu aştığınızın işaretleri
Aşağıdaki baskı noktalarına dikkat edin:
- Birden fazla uygulama örneği çalıştırıyorsunuz ve yalnızca birinin işi alması gerekiyor.
- Dayanıklılık gerekiyor (işler çökmeden ve deploylardan kurtulmalı).
- Kim ne zaman neyi kuyrukladı, ne zaman çalıştı ve sonucu ne oldu gibi bir denetim izi istiyorsunuz.
- Hizmetler arası backpressure kontrollerine ihtiyacınız var, sadece tek bir süreç içinde değil.
- Güçlü zamanlama veya saatler/günler süren gecikmelerle güvenilir uyanış istiyorsunuz.
Eğer bunların hiçbiri doğru değilse, daha ağır araçlar fazla hareketli parça ekleyebilir ve değerini aşabilir.
Yavaşça taşıma, yeniden yazmadan
En iyi korunma kararlı bir iş arayüzüdür: küçük bir payload tipi, bir ID ve açık bir sonuç döndüren bir handler. Böylece kuyruk altyapısını daha sonra (bellek içi kanaldan veritabanı tablosuna, sonra adanmış bir kuyruğa) değiştirseniz bile iş mantığını değiştirmek gerekmez.
Pratik bir ara adım, PostgreSQL’den iş okuyan, kilitleyip sahiplenen ve durum güncelleyen küçük bir Go servistir. Dayanıklılık ve temel denetim izini elde ederken aynı işçi mantığını korursunuz.
Hızlıca prototip oluşturmak isterseniz, Koder.ai (koder.ai) bir sohbet isteminden Go + PostgreSQL başlangıç projesi üretebilir; içinde arka plan işleri tablosu ve bir işçi döngüsü olur ve snapshot/rollback özellikleri yeniden denemeler ve kapanış davranışını ayarlarken yardımcı olabilir.