08 ก.ค. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับติดตามการพึ่งพาข้ามทีม
เรียนรู้วิธีวางแผนและสร้างเว็บแอปสำหรับติดตามการพึ่งพาข้ามทีม: โมเดลข้อมูล, UX, เวิร์กโฟลว์, การแจ้งเตือน, การบูรณาการ และขั้นตอนการใช้งาน
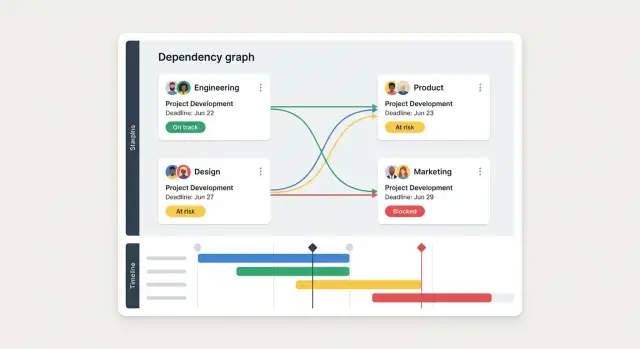
เรียนรู้วิธีวางแผนและสร้างเว็บแอปสำหรับติดตามการพึ่งพาข้ามทีม: โมเดลข้อมูล, UX, เวิร์กโฟลว์, การแจ้งเตือน, การบูรณาการ และขั้นตอนการใช้งาน
ก่อนออกแบบหน้าจอหรือเลือกเทคสแตก ให้ชัดเจนว่าคำว่า “dependency” หมายถึงอะไรในองค์กรของคุณ ถ้าคนใช้คำนี้กับทุกอย่าง แอปของคุณจะจบลงที่การติดตามอะไรไม่เป็นชิ้นเป็นอัน
เขียนคำนิยามสั้น ๆ ที่ทุกคนสามารถพูดซ้ำได้ แล้วระบุว่าสิ่งใดเข้าข่าย หมวดหมู่ที่พบบ่อยได้แก่:
นอกจากนี้ให้กำหนดสิ่งที่ ไม่ ถือเป็น dependency (เช่น “การปรับปรุงที่อยากได้” ความเสี่ยงทั่วไป หรืองานภายในที่ไม่ขัดขวางทีมอื่น) เพื่อให้ระบบไม่รก
การติดตาม dependency ล้มเหลวเมื่อสร้างมาเพื่อ PM อย่างเดียวหรือวิศวกรอย่างเดียว ตั้งชื่อผู้ใช้หลักและสิ่งที่แต่ละคนต้องการภายใน 30 วินาที:
เลือกผลลัพธ์จำนวนเล็ก ๆ เช่น:
จับปัญหาที่แอปต้องแก้ในวันแรก: สเปรดชีตเก่าๆ เจ้าของไม่ชัด วันที่พลาด ความเสี่ยงที่ซ่อนอยู่ และอัปเดตสถานะกระจัดกระจายตามแชท
เมื่อคุณเห็นพ้องกันในสิ่งที่ต้องติดตามและผู้ใช้แล้ว ให้ยึดคำศัพท์และวงจรชีวิตร่วมกัน คำนิยามร่วมกันเปลี่ยน “รายการตั๋ว” ให้เป็นระบบที่ลดการขัดขวางได้
เลือกลิสต์สั้น ๆ ของประเภทที่ครอบคลุมสถานการณ์จริงส่วนใหญ่ และทำให้แต่ละประเภทจดจำง่าย:
เป้าหมายคือความสอดคล้อง: สองคนควรจัดประเภท dependency เดียวกันได้เหมือนกัน
ระเบียน dependency ควรเล็กแต่ครบพอที่จะจัดการ:
ถ้าปล่อยให้สร้าง dependency โดยไม่มีทีมเจ้าของหรือวันที่ คุณกำลังสร้าง "ตัวติดตามความกังวล" ไม่ใช่เครื่องมือการประสานงาน
ใช้โมเดลสถานะเรียบง่ายที่ตรงกับวิธีการทำงานจริงของทีม:
Proposed → Accepted → In progress → Ready → Delivered/Closed, บวก Rejected
เขียนกฎการเปลี่ยนสถานะไว้ เช่น: “การ Accepted ต้องมีทีมเจ้าของและวันที่เป้าหมายเบื้องต้น” หรือ “Ready ต้องมีหลักฐาน”
สำหรับการปิดงาน ให้บังคับทั้งหมดต่อไปนี้:
คำนิยามเหล่านี้จะเป็นกระดูกสันหลังของตัวกรอง การเตือน และการทบทวนสถานะต่อไป
ตัวติดตาม dependency จะสำเร็จหรือล้มเหลวตามว่าคนสามารถบรรยายความจริงได้โดยไม่ทะเลาะกับเครื่องมือ เริ่มจากชุดวัตถุเล็ก ๆ ที่ตรงกับวิธีทีมพูด จากนั้นเพิ่มโครงสร้างเมื่อมันช่วยป้องกันความสับสน
ใช้ระเบียนหลักไม่กี่ประเภท:
หลีกเลี่ยงการสร้างประเภทแยกสำหรับทุกเคสยิบย่อย ดีกว่าที่จะเพิ่มฟิลด์ไม่กี่อย่าง (เช่น “type: data/API/approval”) แทนที่จะแยกโมเดลตั้งแต่แรก
Dependency มักเกี่ยวข้องกับหลายกลุ่มและหลายงาน แบบจำลองนี้ควรสะท้อนชัดเจน:
สิ่งนี้ป้องกันความคิดที่เปราะบางว่า “หนึ่ง dependency = หนึ่งตั๋ว” และทำให้รายงานสะสมทำได้
วัตถุหลักแต่ละชิ้นควรมีฟิลด์ตรวจสอบ:
ไม่ใช่ dependency ทุกตัวจะมีทีมในโครงสร้างองค์กรของคุณ เพิ่มระเบียน Owner/Contact (ชื่อ องค์กร อีเมล/Slack หมายเหตุ) และให้ dependency ชี้ไปยังมันได้ จะช่วยให้บล็อกจากผู้ขายหรือแผนกอื่นมองเห็นได้โดยไม่ต้องบังคับให้พวกเขาเป็นส่วนหนึ่งของทีมภายใน
ถ้าไม่มีการกำหนดบทบาทอย่างชัดเจน การติดตาม dependency จะกลายเป็นเธรดคอมเมนต์: ทุกคนคิดว่าอีกฝ่ายจะทำ และวันที่ก็ถูก “ปรับ” โดยไม่มีบริบท แบบบทบาทชัดเจนทำให้แอปน่าเชื่อถือและการยกระดับคาดเดาได้
เริ่มจากสี่บทบาททั่วไปและบทบาทผู้ดูแลระบบหนึ่งบทบาท:
ทำให้ Owner ต้องมีและเป็นคนเดียว: หนึ่ง dependency หนึ่งเจ้าของที่รับผิดชอบ คุณยังสามารถรองรับ collaborators (ผู้ร่วมงานจากทีมอื่น) แต่ collaborators ไม่ควรแทนที่ความรับผิดชอบ
เพิ่มเส้นทางการยกระดับเมื่อ Owner ไม่ตอบ: แจ้งเตือน Owner ก่อน จากนั้นผู้จัดการของเขา (หรือหัวหน้าทีม) แล้วถึง program/release owner—ตามโครงสร้างองค์กรของคุณ
แยกระหว่าง “แก้ไขรายละเอียด” กับ “เปลี่ยนข้อตกลง” ค่าเริ่มต้นที่ใช้งานได้จริง:
ถ้ารองรับ initiatives ส่วนตัว ให้กำหนดว่าใครเห็น (เช่น เฉพาะทีมที่เกี่ยวข้อง + Admin) หลีกเลี่ยง “dependency ลับ” ที่ทำให้ทีมส่งมอบประหลาดใจ
อย่าซ่อนความรับผิดชอบไว้ในเอกสารนโยบาย แสดงมันบนทุก dependency:
การติดป้าย “Accountable vs Consulted” บนฟอร์มจะลดการส่งผิดที่และทำให้การทบทวนสถานะเร็วขึ้น
ตัวติดตาม dependency จะทำงานได้ก็ต่อเมื่อคนหารายการของตัวเองในไม่กี่วินาทีและอัปเดตได้โดยไม่ต้องคิดมาก ออกแบบรอบคำถามที่พบบ่อย: “ฉันขัดขวางใคร?”, “ใครขัดขวางฉัน?”, และ “มีอะไรจะช้าหรือไม่?”
เริ่มจากชุดมุมมองเล็ก ๆ ที่ตรงกับวิธีทีมพูดเกี่ยวกับงาน:
ความล้มเหลวของเครื่องมือส่วนใหญ่เกิดที่การ “อัปเดรรายวัน” ปรับให้เร็ว:
ใช้ สีประกอบกับป้ายข้อความ (อย่าใช้สีอย่างเดียว) และรักษาคำศัพท์ให้สอดคล้อง เพิ่ม "Last updated" อย่างเด่นบนทุก dependency และเตือนว่า "ไม่อัปเดต" เมื่อไม่มีการสัมผัสเป็นระยะเวลาที่กำหนด (เช่น 7–14 วัน) เพื่อกระตุ้นให้อัปเดตโดยไม่ต้องบังคับประชุม
ทุก dependency ควรมีเธรดเดียวที่บันทึก:
เมื่อหน้ารายละเอียดบอกเรื่องราวครบ การทบทวนสถานะจะเร็วขึ้น—และหลายการประชุมย่อยจะหายไปเพราะคำตอบถูกเขียนไว้แล้ว
ตัวติดตาม dependency จะสำเร็จหรือล้มเหลวจากการกระทำประจำวัน ถ้าทีมสร้างคำขอไม่สะดวก ตอบคำขอไม่ได้ชัดเจน หรือปิดวงจรโดยไม่มีหลักฐาน แอปจะกลายเป็นแค่ "บอร์ด FYI" ไม่ใช่เครื่องมือปฏิบัติการ
เริ่มจากฟลูว์ "Create request" เดียวที่จับสิ่งที่ทีมผู้ให้ต้องส่งทำ ทำไมมันสำคัญ และเมื่อไหร่ที่ต้องการ ทำให้มีโครงสร้าง: วันที่ที่ขอ เกณฑ์การยอมรับ และลิงก์ไปยัง epic/spec ที่เกี่ยวข้อง
จากนั้น บังคับสถานะการตอบรับชัดเจน:
วิธีนี้หลีกเลี่ยงความล้มเหลวที่พบบ่อยที่สุด: dependency แบบ “อาจจะ” เงียบ ๆ ที่ดูปกติจนถึงวันที่เกิดปัญหา
กำหนดความคาดหวังแบบน้ำหนักเบาในเวิร์กโฟลว์ เช่น:
เป้าหมายไม่ใช่การบังคับ แต่คือการทำให้ข้อตกลงเป็นปัจจุบันเพื่อให้การวางแผนตรงไปตรงมา
ให้ทีมสามารถตั้ง dependency เป็น At risk พร้อมบันทึกสั้น ๆ และขั้นตอนถัดไปได้ เมื่อมีการเปลี่ยน วันที่ครบกำหนด หรือ สถานะ ให้ระบุเหตุผล (เลือกจากเมนู + ข้อความอิสระ) กฎเดียวนี้สร้างประวัติเพื่อทำให้การทบทวนย้อนหลังและการยกระดับเป็นข้อเท็จจริง ไม่ใช่อารมณ์
“ปิด” ควรหมายความว่า dependency ถูกตอบสนองจริง ๆ ต้องการ หลักฐาน: ลิงก์ไปยัง PR ที่ถูกรวมแล้ว ตั๋วที่ปล่อยแล้ว เอกสาร หรือบันทึกการอนุมัติ ถ้าการปิดคลุมเครือ ทีมจะทำให้รายการเป็นสีเขียวเร็วเกินไปเพื่อลดเสียง
รองรับการอัปเดตเป็นกลุ่มในระหว่างการทบทวนสถานะ: เลือกหลาย dependency แล้วตั้งสถานะให้เหมือนกัน เพิ่มบันทึกร่วมกัน (เช่น “re-planned after Q1 reset”) หรือขอการอัปเดต วิธีนี้ทำให้แอปเร็วพอที่จะใช้ในการประชุมจริง ไม่ใช่แค่หลังประชุม
การแจ้งเตือนควรปกป้องการส่งมอบ ไม่ใช่รบกวนมากเกินไป วิธีที่ง่ายที่สุดที่จะสร้างเสียงรบกวนคือแจ้งทุกคนเกี่ยวกับทุกเรื่อง ดังนั้นออกแบบการแจ้งเตือนรอบ จุดตัดสินใจ (ต้องมีการกระทำ) และ สัญญาณความเสี่ยง (สิ่งใดกำลังเบี่ยงเบน)
โฟกัสเวอร์ชันแรกกับเหตุการณ์ที่เปลี่ยนแผนหรือเรียกร้องการตอบสนอง:
แต่ละทริกเกอร์ควรแมปไปยังขั้นตอนถัดไปที่ชัดเจน: ยอมรับ/ปฏิเสธ, เสนอวันที่ใหม่, เพิ่มบริบท, หรือยกระดับ
ตั้งค่าเริ่มต้นเป็น การแจ้งเตือนในแอป (เพื่อให้การแจ้งเตือนผูกกับระเบียน dependency) บวก อีเมล สำหรับสิ่งที่ไม่รอได้
เสนอการผสานแชทเป็นตัวเลือก—Slack หรือ Microsoft Teams—แต่ถือเป็นช่องทางส่ง ไม่ใช่ระบบหลัก ข้อความแชทควร deep-link กลับไปยังรายการนั้น (เช่น /dependencies/123) และรวมบริบทขั้นต่ำ: ใครต้องทำอะไร บริบทที่เปลี่ยน และต้องทำเมื่อไหร่
ให้การควบคุมระดับทีมและผู้ใช้:
ตรงนี้เองที่ "watchers" มีบทบาท: แจ้งผู้ ร้องขอ ทีม เจ้าของ และผู้มีส่วนได้เสียที่ถูกเพิ่มอย่างชัดเจน—หลีกเลี่ยงการประกาศวงกว้าง
การยกระดับควรอัตโนมัติแต่ระมัดระวัง: แจ้งเมื่อ dependency เกินกำหนด, วันที่ถูกเลื่อนซ้ำ ๆ, หรือเมื่อสถานะบล็อกไม่มีอัปเดตในช่วงเวลาที่กำหนด
ส่งการยกระดับไปยังระดับที่เหมาะสม (หัวหน้าทีม, ผู้จัดการโปรแกรม) และรวมประวัติการเปลี่ยนแปลงเพื่อให้ผู้รับสามารถลงมือโดยไม่ต้องตามหาบริบท
การบูรณาการควรขจัดการป้อนข้อมูลซ้ำ ไม่ใช่เพิ่มภาระการตั้งค่า ทางที่ปลอดภัยคือเริ่มจากระบบที่ทีมไว้วางใจ (issue tracker ปฏิทิน และการยืนยันตัวตน) ทำให้เวอร์ชันแรกเป็นแบบอ่านอย่างเดียวหรือทางเดียว แล้วขยายเมื่อต้องการ
เลือก tracker หลัก (Jira, Linear, หรือ Azure DevOps) และรองรับฟลูว์แบบลิงก์ก่อน:
PROJ-123)วิธีนี้หลีกเลี่ยง "สองแหล่งความจริง" ในขณะที่ยังให้การมองเห็น dependency การซิงก์สองทางแบบเลือกได้สามารถเพิ่มทีหลังเฉพาะฟิลด์เล็ก ๆ พร้อมกฎการขัดแย้งที่ชัดเจน
มิลสโตนและเดดไลน์มักเก็บใน Google Calendar หรือ Microsoft Outlook เริ่มด้วยการอ่านเหตุการณ์มาใส่ในไทม์ไลน์ dependency ของคุณ (เช่น “Release Cutoff”, “UAT Window”) โดยไม่เขียนกลับ
การซิงก์ปฏิทินแบบอ่านอย่างเดียวช่วยให้ทีมยังคงวางแผนในที่ที่ทำงานอยู่แล้ว ในขณะที่แอปของคุณแสดงผลกระทบและวันที่ที่จะเกิดขึ้นในที่เดียว
Single sign-on ลดแรงต้านการเริ่มใช้และการลอยของสิทธิ์ เลือกตามความเป็นจริงลูกค้า:
ถ้าคุณยังเริ่มต้น ให้ส่งหนึ่งผู้ให้บริการก่อนและอธิบายวิธีร้องขอผู้ให้บริการอื่นๆ
แม้ทีมที่ไม่ใช่เทคนิคก็ได้ประโยชน์เมื่อ ops ภายในสามารถอัตโนมัติการโอนงาน ให้ endpoints และ event hooks ไม่กี่ตัวพร้อมตัวอย่างคัดวาง
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Webhooks อย่าง dependency.created และ dependency.status_changed ช่วยให้ทีมผสานกับเครื่องมือภายในโดยไม่ต้องรอ roadmap ของคุณ สำหรับรายละเอียดเพิ่มเติม ให้ดูที่ /docs/integrations.
แดชบอร์ดคือที่ที่แอป dependency ทำประโยชน์: เปลี่ยน "ฉันคิดว่าเราถูกบล็อก" ให้เป็นภาพรวมที่ชัดเจนร่วมกันว่าต้องรีบจัดการอะไรก่อนการเช็คอินถัดไป
แดชบอร์ดแบบ "ขนาดเดียวเหมาะกับทุกคน" มักล้มเหลว ให้ดีไซน์มุมมองไม่กี่แบบที่ตรงกับวิธีการประชุม:
สร้างชุดรายงานเล็ก ๆ ที่คนน่าจะใช้จริงในการทบทวน:
แต่ละรายงานควรตอบว่า: “ใครต้องทำอะไรต่อ?” รวมเจ้าของ วันที่คาด และการอัปเดตล่าสุด
ทำให้การกรองเร็วและชัดเจน เพราะการประชุมส่วนใหญ่เริ่มจาก “เอาเฉพาะ… ให้ดู” รองรับตัวกรองเช่น ทีม, initiative, สถานะ, ช่วงวันที่ครบกำหนด, ระดับความเสี่ยง, และ แท็ก (เช่น “security review”, “data contract”, “release train”) บันทึกตัวกรองที่ใช้บ่อยเป็นมุมมองชื่อ เช่น “Release A — 14 วันถัดไป”
ไม่ใช่ทุกคนจะทำงานในแอปตลอดเวลา ให้:
ถ้าคุณเสนอระดับชำระเงิน ให้มีการควบคุมการแชร์ที่เอื้อต่อผู้ดูแล และชี้ไปที่ /pricing สำหรับรายละเอียด
คุณไม่จำเป็นต้องมีแพลตฟอร์มซับซ้อนเพื่อส่งตัวติดตาม dependency MVP ระบบสามส่วนง่าย ๆ ก็พอ: UI เว็บสำหรับคน, API สำหรับกฎและการบูรณาการ, และฐานข้อมูลเป็นแหล่งข้อมูลจริง ให้ค่าน้ำหนักกับ "เปลี่ยนแปลงง่าย" มากกว่า "สมบูรณ์แบบ" คุณจะเรียนรู้จากการใช้งานจริงมากกว่าการออกแบบล่วงนาน
จุดเริ่มต้นที่สมเหตุสมผลอาจเป็น:
ถ้าคาดว่าจะมีการผสาน Slack/Jira เร็ว ๆ นี้ เก็บการผสานเป็นโมดูล/งานแยกที่คุยกับ API เดียวกัน แทนให้เครื่องมือนอกเขียนตรงลง DB
ถ้าต้องการถึงผลิตภัณฑ์ใช้งานได้เร็วโดยไม่ตั้งค่าเองทั้งหมด กระบวนการ vibe-coding อาจช่วย เช่น Koder.ai สามารถสร้าง React UI และ backend Go + PostgreSQL จากสเปคที่คุยในแชท แล้วให้คุณวนปรับด้วย planning mode, snapshots, และ rollback คุณยังคงเป็นเจ้าของการตัดสินใจสถาปัตยกรรม แต่ลดระยะจาก “ข้อกำหนด” ถึง “ไพล็อตใช้งานได้” และส่งออกซอร์สโค้ดเมื่อพร้อมจะย้ายเข้าใน
หน้าจอส่วนใหญ่เป็นมุมมองรายการ: dependency เปิด, บล็อกเกอร์ตามทีม, การเปลี่ยนแปลงสัปดาห์นี้ ออกแบบให้รองรับได้:
ข้อมูล dependency อาจมีรายละเอียดการส่งมอบที่อ่อนไหว ใช้ least-privilege access (การมองเห็นระดับทีมเมื่อเหมาะสม) และเก็บ audit logs สำหรับการแก้ไข—ใครเปลี่ยนอะไรและเมื่อไหร่ บันทึกตรวจสอบนี้ลดข้อถกเถียงในการทบทวนสถานะและทำให้เครื่องมือเชื่อถือได้
การเปิดตัวแอปติดตาม dependency คือการเปลี่ยนนิสัยมากกว่าฟีเจอร์ มองการเปิดตัวเหมือนการปล่อยสินค้า: เริ่มเล็ก พิสูจน์คุณค่า แล้วขยายพร้อมจังหวะการปฏิบัติที่ชัดเจน
เลือก 2–4 ทีม ที่ทำงานใน ริเริ่มร่วมหนึ่ง (ตัวอย่าง release train หรือโปรแกรมลูกค้าหนึ่งโครงการ) กำหนดเกณฑ์ความสำเร็จที่วัดได้ภายในไม่กี่สัปดาห์:
รักษาการตั้งค่าไพล็อตให้เรียบง่าย: มีแค่ฟิลด์และมุมมองที่ตอบคำถามว่า "อะไรถูกบล็อก โดยใคร และเมื่อไหร่?"
ทีมส่วนใหญ่ติดตาม dependency ในสเปรดชีต นำเข้าได้แต่ต้องทำอย่างมีเจตนา:
รันการ QA ข้อมูลสั้น ๆ กับผู้ใช้ไพล็อตเพื่อตรวจคำจำกัดความและแก้แถวที่กำกวม
การยอมรับติดเมื่อแอปสนับสนุนจังหวะที่มีอยู่ จัดให้มี:
ถ้าคุณสร้างอย่างรวดเร็ว (เช่น ใช้ Koder.ai ในการวนไอเดีย) ใช้ environment/snapshots เพื่อทดสอบการเปลี่ยนแปลงฟิลด์ที่จำเป็น สถานะ และแดชบอร์ดกับทีมไพล็อต—แล้วเลื่อนขึ้น (หรือย้อนกลับ) โดยไม่กระทบทุกคน
ติดตามจุดที่คนติด: ฟิลด์ที่สับสน สถานะหายไป หรือมุมมองที่ไม่ตอบคำถามทบทวน ปรับข้อเสนอแนะทุกสัปดาห์ในไพล็อต แล้วปรับฟิลด์และมุมมองเริ่มต้นก่อนเชิญทีมเพิ่มเติม ลิงก์ "Report an issue" ไปที่ /support ช่วยให้วงจรปิดเร็ว
เมื่อแอปติดตาม dependency เปิดใช้งาน ความเสี่ยงใหญ่ที่สุดไม่ใช่เรื่องเทคนิค—แต่เป็นพฤติกรรม ทีมส่วนใหญ่ไม่ได้ละทิ้งเครื่องมือเพราะมัน "ไม่ทำงาน" แต่เพราะการอัปเดตรู้สึกเป็นทางเลือก สับสน หรือมีเสียงรบกวน
ฟิลด์มากเกินไป. ถ้าการสร้าง dependency เหมือนกรอกฟอร์ม ผู้คนจะเลื่อนหรือข้าม เริ่มด้วยฟิลด์ขั้นต่ำที่ต้องการ: ชื่อ, ทีมผู้ร้อง, ทีมเจ้าของ, "การกระทำถัดไป", วันที่ครบกำหนด, และสถานะ
ความเป็นเจ้าของไม่ชัดเจน. ถ้าไม่ชัดว่าใครต้องทำถัดไป dependency จะกลายเป็นเธรดสถานะ ทำให้ “owner” และ “next action owner” ชัดเจนและแสดงโดดเด่น
ไม่มีนิสัยการอัปเดต. แม้ UI ดี ถ้ารายการล้าสมัย แอปก็ล้ม เพิ่มการกระตุ้นอ่อนโยน: ไฮไลต์รายการล้าสมัยในรายการ ส่งเตือนเมื่อวันที่ครบกำหนดใกล้หรือการอัปเดตล่าสุดนานแล้ว และทำให้อัปเดทง่าย (เปลี่ยนสถานะคลิกเดียว + บันทึกสั้น)
ปริมาณการแจ้งเตือนเกินพอดี. ถ้าทุกคอมเมนต์แจ้งทุกคน ผู้ใช้จะปิดเสียงระบบ ค่าเริ่มต้นให้ผู้ติดตามที่เลือกและส่งสรุป (รายวัน/สัปดาห์) สำหรับเรื่องไม่เร่งด่วน
ถือว่า “next action” เป็นฟิลด์ชั้นหนึ่ง: ทุก dependency เปิดควรมีขั้นตอนถัดไปชัดเจนและบุคคลรับผิดชอบหนึ่งคน ถ้าไม่มี รายการไม่ควรดูว่า "ครบ" ในมุมมองสำคัญ
นอกจากนี้กำหนดความหมายของ “เสร็จ” (เช่น แก้ไขแล้ว ไม่จำเป็นแล้ว หรือย้ายไป tracker อื่น) และต้องการเหตุผลการปิดสั้น ๆ เพื่อหลีกเลี่ยงรายการซอมบี้
ตัดสินใจว่าใครเป็นเจ้าของแท็ก รายชื่อทีม และหมวดหมู่ โดยทั่วไปเป็นหน้าที่ของผู้จัดการโปรแกรมหรือบทบาท ops พร้อมการควบคุมการเปลี่ยนแปลงแบบน้ำหนักเบา ตั้งนโยบายการเกษียณ: เก็บ initiative เก่าเป็น archive อัตโนมัติหลัง X วันปิด และทบทวนแท็กที่ไม่ได้ใช้ทุกไตรมาส
เมื่อการยอมรับเสถียรแล้ว พิจารณาการอัปเกรดที่เพิ่มมูลค่าโดยไม่เพิ่มแรงต้าน:
ถ้าต้องการวิธีมีโครงสร้างในการจัดลำดับความสำคัญ ให้เชื่อมแต่ละไอเดียกับพิธีทบทวน (การประชุมสถานะประจำสัปดาห์, การวางแผนรีลีส, การทบทวนเหตุการณ์) เพื่อให้การปรับปรุงขับเคลื่อนด้วยการใช้งานจริง ไม่ใช่การเดา
เริ่มจากคำนิยามแบบประโยคเดียวที่ทุกคนพูดซ้ำได้ แล้วระบุสิ่งที่เข้าข่าย (งาน, ผลลัพธ์, การตัดสินใจ, สิทธิ์/การเข้าถึง)
นอกจากนี้ให้เขียนสิ่งที่ ไม่ เข้าข่าย (สิ่งที่เป็น "nice-to-have", ความเสี่ยงทั่วไป, งานภายในที่ไม่ขัดขวางทีมอื่น) เพื่อป้องกันไม่ให้ระบบกลายเป็น "ตัวติดตามความกังวล" ที่คลุมเครือ
อย่างน้อย ออกแบบให้รองรับ:
ถ้าสร้างมาเพื่อกลุ่มเดียว กลุ่มอื่นจะไม่อัปเดต และระบบจะล้าสมัย
ใช้วงจรสถานะเล็ก ๆ ที่สอดคล้อง เช่น:
จากนั้นกำหนดกฎสำหรับการเปลี่ยนสถานะ (เช่น “Accepted ต้องมีทีมเจ้าของและวันที่เป้าหมาย” หรือ “Ready ต้องมีหลักฐาน”) ความสม่ำเสมอสำคัญกว่าความซับซ้อน
กำหนดเฉพาะสิ่งที่จำเป็นสำหรับการประสานงาน:
ถ้าอนุญาตให้ขาดเจ้าของหรือวันที่ คุณจะเก็บรายการที่ไม่สามารถดำเนินการได้
ทำให้การปิดงานพิสูจน์ได้จริง ต้องการ:
วิธีนี้จะป้องกันการอัปเดตเป็นสีเขียวก่อนเวลาเพื่อลดเสียงรบกวน
กำหนดบทบาทสี่แบบในชีวิตประจำวันบวกกับ Admin:
รักษา “หนึ่ง dependency หนึ่ง owner” เพื่อหลีกเลี่ยงความคลุมเครือ; ใช้ collaborators เป็นผู้ช่วย ไม่ใช่ผู้รับผิดชอบ
เริ่มจากมุมมองที่ตอบคำถามประจำวัน:
ปรับให้การอัปเดตทำได้เร็ว: เทมเพลต, แก้ไขแบบอินไลน์, คีย์ลัด และแสดง "Last updated" อย่างเด่น
แจ้งเตือนเฉพาะจุดที่ต้องตัดสินใจหรือสัญญาณความเสี่ยง:
ใช้ผู้ติดตาม (watchers) แทนการประกาศวงกว้าง, รองรับโหมดสรุปรายวัน/สัปดาห์ และรวมการแจ้งเตือนเพื่อลดเสียงซ้ำซ้อน
ผสานเพื่อลดการป้อนข้อมูลซ้ำ ไม่ใช่สร้างแหล่งข้อมูลสองที่:
dependency.created, dependency.status_changed)เก็บแชท (Slack/Teams) เป็นช่องทางส่งข้อความที่เชื่อมลึกกลับไปยังรายการ ไม่ใช่ระบบหลักของข้อมูล
เริ่มด้วยไฟล์ pilot ที่มุ่งเป้า:
ปฏิบัติกับรายการที่ไม่มี owner หรือวันที่เป็น "ไม่สมบูรณ์" และปรับปรุงจากข้อเสนอแนะผู้ใช้