06 พ.ย. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับติดตามเหตุการณ์และ Postmortems
พิมพ์แนวทางปฏิบัติพร้อมขั้นตอนปฏิบัติ เพื่อออกแบบ สร้าง และเปิดตัวเว็บแอปสำหรับติดตามเหตุการณ์และ postmortem ตั้งแต่เวิร์กโฟลว์ไปจนถึงแบบจำลองข้อมูลและ UX
พิมพ์แนวทางปฏิบัติพร้อมขั้นตอนปฏิบัติ เพื่อออกแบบ สร้าง และเปิดตัวเว็บแอปสำหรับติดตามเหตุการณ์และ postmortem ตั้งแต่เวิร์กโฟลว์ไปจนถึงแบบจำลองข้อมูลและ UX
ก่อนร่างหน้าจอหรือเลือกฐานข้อมูล ให้ตกลงร่วมกันก่อนว่าทีมคุณหมายถึง "เว็บแอปติดตามเหตุการณ์" อย่างไร — และการ "จัดการ postmortem" ควรทำอะไรบ้าง ทีมมักใช้คำเดียวกันแต่หมายถึงต่างกัน: สำหรับบางทีม เหตุการณ์คือปัญหาที่ลูกค้ารายงานใดๆ; สำหรับบางทีม อาจหมายถึงแค่การล่มระดับ Sev-1 ที่ต้องโยงทีม on-call ขึ้นมาเท่านั้น.
เขียนคำนิยามสั้นๆ ที่ตอบคำถามเหล่านี้:
คำนิยามนี้จะขับเคลื่อนเวิร์กโฟลว์การตอบสนองเหตุการณ์ของคุณและช่วยป้องกันไม่ให้แอปกลายเป็นเคร่งครัดเกินไป (ไม่มีใครใช้) หรือหลวมเกินไป (ข้อมูลไม่สอดคล้อง).
ตัดสินใจว่า postmortem คืออะไรในองค์กรของคุณ: สรุปสั้นๆ สำหรับทุกเหตุการณ์ หรือ RCA แบบเต็มเฉพาะเหตุการณ์ร้ายแรงระดับสูง ระบุให้ชัดเจนว่าจุดประสงค์คือการเรียนรู้, การปฏิบัติตามข้อกำหนด, ลดการเกิดซ้ำ หรือทั้งสามอย่าง
กฎที่เป็นประโยชน์: ถ้าคุณคาดหวังว่า postmortem จะต้องนำไปสู่การเปลี่ยนแปลง เครื่องมือต้องรองรับการ ติดตาม action items ไม่ใช่แค่เก็บเอกสาร
ทีมส่วนใหญ่สร้างแอปแบบนี้เพื่อแก้ปัญหาซ้ำๆ ไม่กี่อย่าง:
เก็บลิสต์นี้ให้กระชับ ฟีเจอร์ทุกอย่างที่เพิ่มต้องแก้ปัญหาอย่างน้อยหนึ่งข้อจากนี้
เลือกตัวชี้วัดไม่กี่ตัวที่วัดได้โดยอัตโนมัติจากโมเดลข้อมูลของแอป:
สิ่งเหล่านี้จะเป็นเมตริกการปฏิบัติการและ "คำจำกัดความของเสร็จ" สำหรับการปล่อยแรก
แอปเดียวกันรองรับบทบาทต่างกันในการ ปฏิบัติการ on-call:
หากออกแบบสำหรับทุกคนพร้อมกัน คุณจะได้ UI ที่รก แทนที่จะทำเช่นนั้น ให้เลือกผู้ใช้หลักสำหรับ v1 — แล้วมั่นใจว่าคนอื่นยังหาอะไรที่ต้องการได้ผ่านมุมมอง ดาชบอร์ด และสิทธิ์ที่ปรับแต่งได้ในภายหลัง
เวิร์กโฟลว์ที่ชัดเจนช่วยป้องกันสองความล้มเหลวทั่วไป: เหตุการณ์ค้างเพราะไม่มีใครรู้ "ขั้นตอนต่อไปคืออะไร" และเหตุการณ์ที่ดูเหมือน "เสร็จ" แต่ไม่เกิดการเรียนรู้จริง เริ่มจากการแม็ปวงจรชีวิตตั้งแต่ต้นจนจบ แล้วผูกบทบาทและสิทธิ์กับแต่ละขั้นตอน
ทีมส่วนใหญ่ใช้เส้นทางเรียบง่าย: ตรวจพบ → แยกประเภท → บรรเทา → แก้ไข → เรียนรู้ แอปของคุณควรสะท้อนด้วยชุดขั้นตอนที่คาดเดาได้ไม่กี่ขั้น ไม่ใช่เมนูเลือกไม่รู้จบ
กำหนดความหมายของคำว่า "เสร็จ" สำหรับแต่ละขั้น ตัวอย่างเช่น บรรเทาอาจหมายถึงผลกระทบต่อลูกค้าหยุดแล้ว แม้ว่าสาเหตุรากยังไม่ทราบ
เก็บบทบาทให้ชัดเจนเพื่อให้คนสามารถลงมือทำได้โดยไม่รอประชุม:
UI ควรแสดง "เจ้าของปัจจุบัน" ชัดเจน และเวิร์กโฟลว์ควรรองรับการมอบหมายใหม่ (reassign, เพิ่มผู้ตอบ, สลับ commander)
เลือกสถานะที่จำเป็นและการเปลี่ยนที่อนุญาต เช่น Investigating → Mitigated → Resolved เพิ่มกลไกคุ้มกัน:
แยก อัปเดตภายใน (รวดเร็ว ยุทธศาสตร์ สามารถรกได้) ออกจาก อัปเดตถึงผู้มีส่วนได้ส่วนเสีย (ชัดเจน ตราประทับเวลา คัดกรองแล้ว) สร้างสตรีมอัปเดตสองชุดที่มีเทมเพลต การมองเห็น และกฎการอนุมัติแตกต่างกัน — บ่อยครั้ง commander จะเป็นผู้เผยแพร่เพียงคนเดียวสำหรับอัปเดตถึงผู้มีส่วนได้ส่วนเสีย
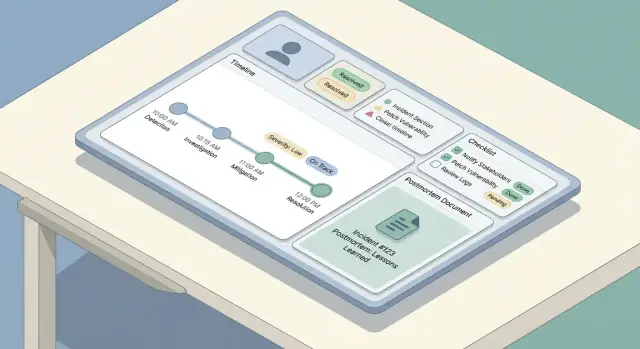
เครื่องมือติดตามเหตุการณ์ที่ดีกลับให้ความรู้สึก "เรียบง่าย" ใน UI เพราะโมเดลข้อมูลภายใต้เรียบและสอดคล้อง ก่อนสร้างหน้าจอ ตัดสินใจว่าเก็บวัตถุใด มีความสัมพันธ์อย่างไร และข้อมูลใดต้องถูกเก็บให้เป็นประวัติ
เริ่มจากชุดวัตถุชั้นหนึ่งขนาดเล็ก:
ความสัมพันธ์ส่วนใหญ่เป็น one-to-many:
ใช้ตัวระบุที่เสถียร (UUID) สำหรับ incident และ event แต่คนยังต้องการรหัสอ่านง่าย เช่น INC-2025-0042 ซึ่งสร้างจากลำดับได้
ออกแบบพวกนี้ตั้งแต่แรกเพื่อให้กรอง ค้นหา และรายงานได้:
ข้อมูลเหตุการณ์มีความละเอียดอ่อนและมักถูกทวนสอบภายหลัง ปฏิบัติต่อการแก้ไขเหมือนข้อมูล — ไม่ใช่การเขียนทับ:
โครงสร้างนี้ทำให้ฟีเจอร์ในอนาคต—การค้นหา เมตริก และสิทธิ์—ทำได้ง่ายขึ้นโดยไม่ต้องเขียนทับ
เมื่อเกิดปัญหา งานของแอปคือทำให้การพิมพ์น้อยลงและความชัดเจนมากขึ้น ส่วนนี้ครอบคลุม "เส้นทางการเขียน": วิธีที่คนสร้างเหตุการณ์ อัปเดตมัน และสร้างเรื่องราวเมื่อย้อนดูภายหลัง
เก็บฟอร์มรับเหตุการณ์ให้สั้นพอที่จะกดส่งขณะกำลังแก้ปัญหา ชุดฟิลด์บังคับที่ดีคือ:
ส่วนที่เหลือควรเป็นทางเลือกในช่วงสร้างเหตุการณ์ (ผลกระทบ ลิงก์ตั๋วลูกค้า สาเหตุที่คาดว่าเกิดขึ้น) ใช้ค่าเริ่มต้นอัจฉริยะ: ตั้ง start time เป็น "now", เลือก ทีม on-call ของผู้ใช้ล่วงหน้า และเสนอปุ่มเดียว "Create & open incident room"
UI อัปเดตควรออกแบบให้เหมาะกับการแก้ไขเล็กๆ ซ้ำๆ ให้แผงอัปเดตกะทัดรัดที่มี:
ทำให้การอัปเดตเป็นแบบ append-friendly: แต่ละอัปเดตกลายเป็นรายการที่ตราประทับเวลา ไม่ใช่การเขียนทับข้อความก่อนหน้า
สร้างไทม์ไลน์ที่ผสม:
วิธีนี้สร้างเล่าเรื่องที่เชื่อถือได้โดยไม่บังคับให้คนจดบันทึกทุกคลิก
ระหว่างการล่ม หลายอัปเดตเกิดขึ้นจากโทรศัพท์ ให้ให้ความสำคัญกับหน้าจอที่เร็วและมีแรงเสียดทานต่ำ: ปุ่มสัมผัสใหญ่ หน้ากรอกหนึ่งหน้าที่เลื่อนได้ ร่างผลงานออฟไลน์ และปุ่มหนึ่งแตะอย่าง “Post update” และ “Copy incident link”
Severity คือ “ปุ่มปรับความเร็ว” ของการตอบสนองเหตุการณ์: บอกคนว่าต้องทำอย่างเร่งด่วนแค่ไหน ต้องสื่อสารกว้างขวางเพียงใด และแลกเปลี่ยนอะไรได้บ้าง
หลีกเลี่ยงป้ายกำกับคลุมเครือเช่น “สูง/กลาง/ต่ำ” ให้แต่ละระดับแมปกับความคาดหวังปฏิบัติการที่ชัดเจน — โดยเฉพาะเวลาในการตอบและรอบการสื่อสาร
ตัวอย่าง:
ทำให้กฎเหล่านี้มองเห็นได้ใน UI ทุกครั้งที่เลือกความร้ายแรง เพื่อให้ผู้ตอบไม่ต้องหาเอกสารภายนอกระหว่างการล่ม
เช็คลิสต์ช่วยลดภาระความคิดเมื่อคนตึงเครียด เก็บให้สั้น ปฏิบัติได้ และผูกกับบทบาท
รูปแบบที่มีประโยชน์คือแบ่งเป็นส่วนไม่กี่ส่วน:
ทำให้รายการเช็คลิสต์มีตราประทับเวลาและระบุผู้กระทำ เพื่อให้กลายเป็นส่วนหนึ่งของบันทึกเหตุการณ์
เหตุการณ์มักอยู่ในหลายเครื่องมือ แอปของคุณควรให้ผู้ตอบแนบลิงก์ไปยัง:
ชอบลิงก์ที่มี "ประเภท" (เช่น Runbook, Ticket) เพื่อให้กรองได้ในภายหลัง
หากองค์กรติดตามเป้าหมายความเสถียร ให้เพิ่มฟิลด์น้ำหนักเบา เช่น SLO affected (yes/no), estimated error budget burn, และ customer SLA risk ให้เป็นทางเลือก — แต่เติมง่ายระหว่างหรือหลังเหตุการณ์เมื่อรายละเอียดยังสด
Postmortem ที่ดีก็ต้องเริ่มง่าย จำได้ และสม่ำเสมอที่สุด วิธีที่ง่ายคือให้เทมเพลตเริ่มต้น (มีฟิลด์บังคับน้อย) และเติมจากบันทึกเหตุการณ์อัตโนมัติ เพื่อให้คนคิดมากกว่าพิมพ์ซ้ำ
เทมเพลตในแอปควรบาลานซ์โครงสร้างกับความยืดหยุ่น:
ทำให้ “Root cause” เป็นทางเลือกในช่วงแรกถ้าต้องการเผยแพร่เร็ว แต่ บังคับก่อนอนุมัติขั้นสุดท้าย
Postmortem ไม่ควรเป็นเอกสารแยก เมื่อสร้าง postmortem ให้แนบอัตโนมัติ:
ใช้ข้อมูลเหล่านี้เติมเทมเพลต เช่น บล็อก “Impact” สามารถเริ่มด้วยเวลาเริ่ม/จบและความร้ายแรงปัจจุบัน ส่วน “What we did” ดึงจากรายการไทม์ไลน์
เพิ่มเวิร์กโฟลว์น้ำหนักเบาเพื่อไม่ให้ postmortem ค้าง:
ในแต่ละขั้น ให้จับ decision notes: อะไรเปลี่ยน ทำไมเปลี่ยน ใครอนุมัติ เพื่อหลีกเลี่ยงการแก้ไขเงียบและช่วยการทวนสอบ/การเรียนรู้ในอนาคต
ถ้าต้องการ UI เรียบง่าย ให้ปฏิบัติการทบทวนเหมือนคอมเมนต์ที่มีผลลัพธ์ชัดเจน (Approve / Request changes) และเก็บการอนุมัติสุดท้ายเป็นบันทึกที่ไม่แก้ไขได้
สำหรับทีมที่ต้องการ ให้เชื่อมสถานะ “Published” กับเวิร์กโฟลว์การอัปเดตสถานะ (ดูข้อความอ้างอิง) โดยไม่ต้องคัดลอกเนื้อหาด้วยมือ
Postmortem จะลดการเกิดซ้ำได้ก็ต่อเมื่องานติดตามถูกทำจริง ถือ action items เป็นเอนทิตีชั้นหนึ่งในแอปของคุณ — ไม่ใช่ย่อหน้าปลายเอกสาร
แต่ละ action item ควรมีฟิลด์สม่ำเสมอเพื่อให้ติดตามและวัดผลได้:
เพิ่มเมตาดาต้าจิ๋วที่มีประโยชน์: แท็ก (เช่น “monitoring”, “docs”), คอมโพเนนต์/บริการ, และ “created from” (incident ID และ postmortem ID)
อย่าขัง action items ไว้ในหน้า postmortem เดียว ให้มี:
นี่จะเปลี่ยนการติดตามให้เป็นคิวปฏิบัติการ มากกว่าบันทึกกระจัดกระจาย
งานบางอย่างเกิดซ้ำ (game days รายไตรมาส, ทบทวน runbook) รองรับ เทมเพลตที่เกิดซ้ำ สร้างรายการใหม่ตามกำหนดในขณะที่แต่ละครั้งยังติดตามเป็นอิสระ
ถ้าทีมใช้ตัวติดตามงานอื่นแล้ว ให้อนุญาตให้ action item มี ลิงก์อ้างอิงภายนอก และ ID ภายนอก ในขณะที่แอปคุณยังเป็นแหล่งอ้างอิงเหตุการณ์และการยืนยัน
สร้างการเตือนน้ำหนักเบา: แจ้งเจ้าของเมื่อใกล้ครบกำหนด ติดธงงานค้างให้หัวหน้าทีม และแสดงรูปแบบค้างชำระในรายงาน ทำให้กฎปรับแต่งได้เพื่อให้สอดคล้องกับการปฏิบัติการ on-call และความเป็นจริงของภาระงาน
เหตุการณ์และ postmortem มักมีรายละเอียดละเอียดอ่อน — ข้อมูลลูกค้า รหัสภายใน การค้นพบด้านความปลอดภัย หรือปัญหาผู้ขาย กฎการเข้าถึงชัดเจนทำให้เครื่องมือมีประโยชน์สำหรับการร่วมมือโดยไม่กลายเป็นจุดรั่วไหลข้อมูล
เริ่มด้วยชุดบทบาทเล็กๆ ที่เข้าใจง่าย:
ถ้ามีหลายทีม ให้พิจารณา ขอบเขตบทบาทตามบริการ/ทีม (เช่น “Payments Editors”) แทนการให้สิทธิ์ทั่วทั้งระบบ
จัดประเภทเนื้อหาแต่แรก ก่อนผู้ใช้สร้างนิสัย:
รูปแบบปฏิบัติได้คือทำเครื่องหมายส่วนต่างๆ เป็น Internal หรือ Shareable และบังคับในการส่งออกและหน้าสถานะ เหตุการณ์ด้านความปลอดภัยอาจต้องมีประเภทเหตุการณ์แยกต่างหากที่มีค่าเริ่มต้นเข้มงวดกว่า
สำหรับทุกการเปลี่ยนแปลงที่ incidents และ postmortems ให้บันทึก: ใครเปลี่ยนอะไร และเมื่อไร รวมถึงการแก้ไข severity, timestamps, impact, และการอนุมัติสุดท้าย ทำให้ audit logs ค้นหาได้และไม่สามารถแก้ไขได้
รองรับการยืนยันตัวตนที่แข็งแรง: อีเมล + MFA หรือ magic link และเพิ่ม SSO (SAML/OIDC) หากผู้ใช้คาดหวัง ใช้เซสชันอายุสั้น คุกกี้ปลอดภัย ป้องกัน CSRF และยกเลิกเซสชันอัตโนมัติเมื่อมีการเปลี่ยนบทบาท
เมื่อเหตุการณ์กำลังดำเนิน ผู้คนมักสแกน — ไม่อ่าน UI ควรทำให้สถานะปัจจุบันเห็นได้ในไม่กี่วินาที ขณะเดียวกันให้ผู้ตอบสามารถขุดรายละเอียดโดยไม่หลงทาง
เริ่มจากสามหน้าจอที่ครอบคลุมเวิร์กโฟลว์หลัก:
กฎง่ายๆ: หน้ารายละเอียดเหตุการณ์ควรตอบคำถาม "ตอนนี้เกิดอะไรขึ้น?" ที่หัวเรื่อง และ "เรามาถึงจุดนี้ได้อย่างไร?" ด้านล่าง
เหตุการณ์เพิ่มขึ้นเร็ว ทำให้การค้นหาต้องรวดเร็วและยืดหยุ่น:
เสนอ saved views เช่น My open incidents หรือ Sev-1 this week เพื่อให้วิศวกร on-call ไม่ต้องสร้างฟิลเตอร์ซ้ำทุกกะ
ใช้ป้ายสีที่คงที่ ปลอดภัยต่อการมองเห็นทั่วทั้งแอป และหลีกเลี่ยงเฉดสีที่คล้ายกันจนทำให้สับสน เก็บพจนานุกรมสถานะเดียวกันทุกที่: บนลิสต์ รายละเอียดหัวเรื่อง และเหตุการณ์ในไทม์ไลน์
เมื่อมองเร็ว ผู้ตอบควรเห็น:
ให้ความสำคัญกับการสแกน:
ออกแบบสำหรับช่วงเวลาที่เลวร้ายที่สุด: หากใครบางคนพักผ่อนไม่พอและรับการเรียกผ่านโทรศัพท์ UI ก็ยังต้องชี้แนะแนวทางให้ทำงานได้รวดเร็ว
การผนวกรวมคือสิ่งที่เปลี่ยนเครื่องมือติดตามเหตุการณ์จาก "ที่เก็บบันทึก" เป็นระบบที่ทีมใช้งานจริง เริ่มจากรายการระบบที่ต้องเชื่อมต่อ: มอนิเตอร์/observability (PagerDuty/Opsgenie, Datadog, CloudWatch), แชท (Slack/Teams), อีเมล, ตั๋ว (Jira/ServiceNow), และหน้าสถานะ
ทีมส่วนใหญ่ใช้แบบผสม:
Alerts มีเสียงดัง รีทราย และมักมาถึงไม่เรียงลำดับ กำหนด idempotency key ที่เสถียรต่อเหตุการณ์ผู้ให้บริการ (เช่น: provider + alert_id + occurrence_id) และเก็บมันพร้อมข้อจำกัดความเป็นเอกลักษณ์ สำหรับการ dedupe ให้ตัดสินใจเช่น "บริการเดียวกัน + ลายเซ็นเดียวกันภายใน 15 นาที" ให้ต่อเข้ากับ incident เดิมแทนสร้างใหม่
ชัดเจนว่าแอปของคุณรับผิดชอบอะไรและอะไรยังอยู่ในเครื่องมือแหล่งที่มา:
เมื่อการผนวกรวมล้มเหลว ให้ลดความสามารถช้าๆ: คิวรอ retry แสดงคำเตือนบนเหตุการณ์ ("การโพสต์ Slack ล่าช้า") และให้ผู้ปฏิบัติงานดำเนินการด้วยมือได้เสมอ
ปฏิบัติต่ออัปเดตสถานะเป็นผลลัพธ์ชั้นหนึ่ง: การกระทำ "Update" โครงสร้างใน UI ควรสามารถโพสต์ไปยังแชท แนบในไทม์ไลน์เหตุการณ์ และซิงค์กับหน้าสถานะได้โดยไม่ขอให้ผู้ตอบเขียนข้อความเดียวกันสามครั้ง
เครื่องมือติดตามเหตุการณ์เป็นระบบที่ใช้ในระหว่างการล่ม ดังนั้นให้เลือกความเรียบง่ายและความน่าเชื่อถือเหนือความใหม่ ไฟในที่สุดสแตกที่ดีที่สุดมักเป็นสแตกที่ทีมของคุณสามารถสร้าง ดูแล และแก้ไขได้ตอนตีสองอย่างมั่นใจ
เริ่มจากสิ่งที่วิศวกรของคุณส่งจริงในโปรดักชัน เฟรมเวิร์กเว็บมาตรฐาน (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) มักปลอดภัยกว่าการใช้เฟรมเวิร์กใหม่ที่คนเดียวเข้าใจ
สำหรับการเก็บข้อมูล ฐานข้อมูลเชิงสัมพันธ์ (PostgreSQL/MySQL) เหมาะกับเรคอร์ดเหตุการณ์: incidents, updates, participants, action items, postmortems ได้ประโยชน์จากธุรกรรมและความสัมพันธ์ที่ชัดเจน เพิ่ม Redis เฉพาะเมื่อจำเป็นจริงๆ สำหรับแคช คิว หรือล็อกชั่วคราว
โฮสติ้งทำได้ตั้งแต่แพลตฟอร์มจัดการ (Render/Fly/Heroku-like) หรือคลาวด์ที่คุณใช้ (AWS/GCP/Azure) เลือกฐานข้อมูลจัดการและแบ็กอัพที่จัดการได้เมื่อเป็นไปได้
เหตุการณ์ที่กำลังเกิดจะดีกว่าถ้ามีการอัปเดตเรียลไทม์ แต่คุณอาจไม่ต้อง websockets ตั้งแต่วันแรก
แนวทางปฏิบัติ: ออกแบบ API/อีเวนต์ให้เริ่มจาก polling แล้วอัปเกรดเป็น websockets ภายหลังโดยไม่ต้องเขียน UI ใหม่
ถ้าแอปนี้ล้มระหว่างเหตุการณ์ มันจะเป็นส่วนหนึ่งของเหตุการณ์ด้วย เพิ่ม:
ปฏิบัติต่อแอปนี้เหมือนระบบโปรดักชัน:
ถ้าต้องการตรวจสอบเวิร์กโฟลว์และหน้าจอก่อนลงทุนเต็มที่ วิธี vibe-coding ทำงานได้: ใช้เครื่องมืออย่าง Koder.ai เพื่อสร้างต้นแบบที่ทำงานได้จากสเปคแชทที่ละเอียด แล้วทำซ้ำกับผู้ตอบในการซ้อมจริง เนื่องจาก Koder.ai สามารถผลิต frontend React พร้อม backend Go + PostgreSQL (และรองรับการส่งออกซอร์สโค้ด) คุณสามารถทำเวอร์ชันแรกเป็นต้นแบบทิ้งได้ หรือใช้เป็นจุดเริ่มต้นที่ทีมทำให้แข็งแกร่งต่อได้ — โดยไม่เสียบทเรียนจากการซ้อมจริง
ส่งเครื่องมือเหตุการณ์โดยไม่ซ้อมเป็นความเสี่ยง ทีมที่ดีที่สุดปฏิบัติต่อเครื่องมือนี้เหมือนระบบปฏิบัติการ: ทดสอบเส้นทางสำคัญ ซ้อมสถานการณ์จริง เปิดตัวทีละน้อย และปรับอยู่เสมอตามการใช้งานจริง
โฟกัสที่ฟลูว์ที่คนต้องพึ่งพาในความเครียดสูง:
เพิ่ม regression tests ที่ยืนยันสิ่งที่ห้ามพัง: timestamps, โซนเวลา, และลำดับเหตุการณ์ เรื่องราวเหตุการณ์ต้องถูกต้อง — ถ้าไทม์ไลน์ผิด ความเชื่อถือจะหาย
บั๊กสิทธิ์เป็นความเสี่ยงด้านปฏิบัติการและความปลอดภัย เขียนเทสต์ที่พิสูจน์ว่:
ทดสอบกรณีใกล้เคียง เช่น ผู้ใช้สูญเสียการเข้าถึงกลางเหตุการณ์ หรือการปรับโครงสร้างทีมที่เปลี่ยนสมาชิก
ก่อนเปิดใช้กว้าง ให้ซ้อมสถานการณ์พร้อมใช้แอปเป็นแหล่งข้อมูลหลัก เลือกสถานการณ์ที่องค์กรคุ้นเคย (เช่น ล่มบางส่วน ล่าช้าข้อมูล ปัญหาจากบุคคลที่สาม) สังเกต friction: ช่องสับสน ข้อมูลขาด คลิกมากเกินไป ความเป็นเจ้าของไม่ชัด
เก็บข้อเสนอแนะทันทีและแปลงเป็นการปรับปรุงเล็กๆ ที่เร็ว
เริ่มจากทีมพายล็อตหนึ่งและเทมเพลตที่เตรียมไว้ (ประเภทเหตุการณ์ เช็คลิสต์ เทมเพลต postmortem) ให้การฝึกสั้นๆ และคู่มือหน้าเดียว "วิธีการรันเหตุการณ์ของเรา" เชื่อมจากแอป
ติดตามเมตริกการยอมรับและปรับปรุงปัญหาที่ทำให้ติดขัด: เวลาในการสร้าง ร้อยละเหตุการณ์ที่มีอัปเดต อัตราการทำ postmortem ให้เสร็จ และเวลาในการปิด action-item ถือเป็นเมตริกผลิตภัณฑ์ — ไม่ใช่เมตริกการปฏิบัติตาม — และปรับปรุงอย่างต่อเนื่องทุกรีลีส
Start by writing a concrete definition your org agrees on:
That definition should map directly to your workflow states and required fields so data stays consistent without becoming burdensome.
Treat postmortems as a workflow, not a document:
If you expect change, you need action-item tracking and reminders—not just storage.
A practical v1 set is:
Skip advanced automation until these flows work smoothly under stress.
Use a small number of predictable stages aligned to how teams actually work:
Define “done” for each stage, then add guardrails:
This prevents stalled incidents and improves the quality of later analysis.
Model a few clear roles and tie them to permissions:
Make the current owner/commander unmistakable in the UI and allow delegation (reassign, rotate commander).
Keep the data model small but structured:
Use stable identifiers (UUIDs) plus a human-friendly key (e.g., INC-2025-0042). Treat edits as history with created_at/created_by and an audit log for changes.
Separate streams and apply different rules:
Implement different templates/visibility, and store both in the incident record so you can reconstruct decisions later without leaking sensitive details.
Define severity levels with explicit expectations (response urgency and comms cadence). For example:
Surface the rules in the UI wherever severity is chosen so responders don’t need external docs during an outage.
Treat action items as structured records, not free text:
Then provide global views (overdue, due soon, by owner/service) and lightweight reminders/escalation so follow-ups don’t vanish after the review meeting.
Use provider-specific idempotency keys and dedup rules:
provider + alert_id + occurrence_idAlways allow manual linking as a fallback when APIs or integrations fail.