17 ธ.ค. 2568·2 นาที
การจัดพูลการเชื่อมต่อ PostgreSQL: App pooling vs PgBouncer
การ pooled การเชื่อมต่อ PostgreSQL: เปรียบเทียบพูลในแอปกับ PgBouncer สำหรับ backend Go เมตริกที่ควรเฝ้า และการตั้งค่าผิดพลาดที่ทำให้เกิดการกระโดดของ latency
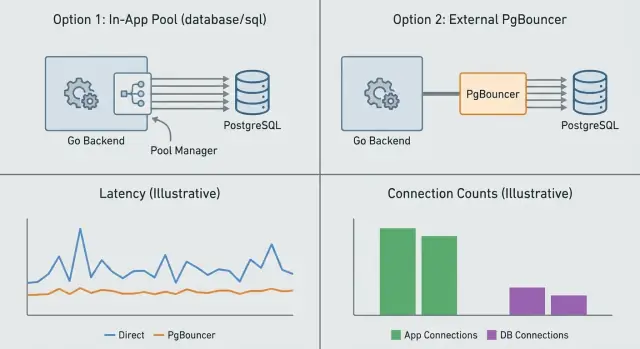
การ pooled การเชื่อมต่อ PostgreSQL: เปรียบเทียบพูลในแอปกับ PgBouncer สำหรับ backend Go เมตริกที่ควรเฝ้า และการตั้งค่าผิดพลาดที่ทำให้เกิดการกระโดดของ latency
database/sql) จัดการการเชื่อมต่อต่อ process มันตัดสินใจจะเปิดการเชื่อมต่อใหม่เมื่อไร จะใช้ซ้ำตัวไหน และจะปิดตัวไหนที่เป็น idle ซึ่งช่วยหลีกเลี่ยงค่าใช้จ่ายการตั้งค่าในทุกคำขอ ข้อจำกัดคือมันไม่สามารถประสานข้ามหลายอินสแตนซ์แอปได้ หากคุณรัน 10 replica ก็เท่ากับมี 10 พูลแยกกัน\n\nPgBouncer ยืนอยู่ระหว่างแอปกับ Postgres และพูลในนามของลูกค้าหลายราย มันมีประโยชน์เมื่อคุณมีคำขอสั้นมาก มีหลายอินสแตนซ์แอป หรือทราฟฟิกเป็นระลอก มันจำกัดการเชื่อมต่อฝั่งเซิร์ฟเวอร์กับ Postgres แม้จะมีการเชื่อมต่อจากลูกค้าร้อย ๆ มาถึงพร้อมกัน ในช่วงพีค PgBouncer จะคิวงานแทนที่จะสร้าง backend ใหม่ทันที ซึ่งการคิวแบบนี้อาจเป็นความแตกต่างระหว่างการหน่วงที่ควบคุมได้และฐานข้อมูลที่ล่ม\n\nสรุปหน้าที่แบบง่าย ๆ:\n\n- App pooling กำหนดความขนานภายในอินสแตนซ์แอปเดียวและหลีกเลี่ยงการ reconnect ต่อคำขอ\n- PgBouncer จำกัดจำนวนการเชื่อมต่อรวมกับ Postgres ข้ามทุกอินสแตนซ์และเกลี่ยระลอกทราฟฟิก\n- Postgres ยังคงมีข้อจำกัดด้าน CPU, IO และหน่วยความจำ การพูลไม่สามารถสร้างทรัพยากรเพิ่มได้\n\nทั้งสองสามารถทำงานร่วมกันได้โดยไม่เกิดปัญหา “double pooling” ตราบเท่าที่แต่ละชั้นมีบทบาทชัดเจน: ตั้ง database/sql pool ที่สมเหตุสมผลต่อ process Go หนึ่งตัว และใช้ PgBouncer เป็นตัวบังคับงบประมาณการเชื่อมต่อระดับรวม\n\nความสับสนทั่วไปคือคิดว่า “พูลมากขึ้นแปลว่ามีความสามารถมากขึ้น” จริง ๆ มักจะตรงกันข้าม หากทุกบริการ worker และ replica มีพูลขนาดใหญ่ ตัวเลขการเชื่อมต่อรวมจะพุ่งและก่อให้เกิดการคิว context switching และการกระโดดของ latency อย่างฉับพลัน\n\n## พฤติกรรมจริงของ database/sql ใน Go\n\nใน Go, sql.DB เป็นตัวจัดการ connection pool ไม่ใช่การเชื่อมต่อเดียว เมื่อคุณเรียก db.Query หรือ db.Exec database/sql พยายามใช้การเชื่อมต่อที่ idle หากไม่มีมันอาจเปิดการเชื่อมต่อใหม่ (จนถึงขีดจำกัดของคุณ) หรือนำคำขอมารอ\n\nการรอนี่แหละที่มักเป็นแหล่งที่มาของ “ความหน่วงลึกลับ” เมื่อพูลถูกอิ่มคำขอจะคิวอยู่ภายในแอป จากภายนอกมันจะดูเหมือนว่า Postgres ช้าลง แต่จริง ๆ เวลานั้นถูกใช้ไปรอการเชื่อมต่อว่าง\n\n### ปุ่มที่ควรปรับ\n\nการปรับส่วนมากอยู่ที่การตั้งค่าสี่อย่าง:\n\n- MaxOpenConns: ขีดจำกัดจำนวนการเชื่อมต่อที่เปิดได้ (idle + กำลังใช้งาน) เมื่อถึงค่านี้ caller จะบล็อก\n- MaxIdleConns: จำนวนการเชื่อมต่อที่นั่งรอพร้อมใช้ ยิ่งต่ำเกินไปจะทำให้ reconnect บ่อย\n- ConnMaxLifetime: บังคับรีไซเคิลการเชื่อมต่อเป็นช่วง ๆ ช่วยกับ load balancer และ NAT timeout แต่ถ้าตั้งสั้นเกินไปจะเกิด churn\n- ConnMaxIdleTime: ปิดการเชื่อมต่อที่ไม่ถูกใช้งานนานเกินไป\n\nการนำการเชื่อมต่อกลับมาใช้มักลด latency และ CPU ของ DB เพราะหลีกเลี่ยงการตั้งค่าใหม่แต่ละครั้ง แต่พูลที่ใหญ่เกินไปกลับทำให้เกิดคำสั่งพร้อมกันมากเกินกว่าที่ Postgres จะรับไหว เพิ่มการแย่งทรัพยากรและ overhead\n\nคิดเป็นยอดรวม ไม่ใช่ต่อ process ถ้าแต่ละอินสแตนซ์ Go อนุญาต 50 การเชื่อมต่อและคุณสเกลเป็น 20 อินสแตนซ์ เท่ากับอนุญาต 1,000 การเชื่อมต่อ เปรียบเทียบตัวเลขนั้นกับสิ่งที่เซิร์ฟเวอร์ Postgres ของคุณจะรันได้อย่างราบรื่น\n\nแนวทางเริ่มต้นที่ใช้งานได้คือผูก MaxOpenConns กับความขนานที่คาดว่าจะเกิดขึ้นต่ออินสแตนซ์ แล้วตรวจสอบด้วยเมตริกพูล (in-use, idle, และ wait time) ก่อนจะเพิ่มขึ้น\n\n## พื้นฐานของ PgBouncer และโหมดการพูล\n\nPgBouncer เป็น proxy ขนาดเล็กระหว่างแอปกับ PostgreSQL บริการของคุณเชื่อมต่อกับ PgBouncer และ PgBouncer เก็บการเชื่อมต่อจริงต่อ Postgres ไว้จำกัด ในช่วงพีค PgBouncer จะคิวงานลูกค้าแทนการสร้าง backend ใหม่ ซึ่งการมีคิวนี้อาจเป็นความแตกต่างระหว่างการชะลอตัวที่ควบคุมได้กับฐานข้อมูลที่ล่ม\n\n### สามโหมดการพูล\n\nPgBouncer มีสามโหมดการพูล:\n\n- Session pooling: ลูกค้าจะเก็บการเชื่อมต่อเซิร์ฟเวอร์เดิมตราบเท่าที่เชื่อมต่ออยู่\n- Transaction pooling: ลูกค้าเช่าเชื่อมต่อเซิร์ฟเวอร์แค่ช่วง transaction แล้วคืนกลับ\n- Statement pooling: ลูกค้าเช่าเชื่อมต่อเซิร์ฟเวอร์แค่สำหรับคำสั่งเดียว\n\nSession pooling ให้พฤติกรรมเหมือนการเชื่อมต่อตรงไปยัง Postgres มากที่สุด และคาดเดาได้น้อยสุด แต่ประหยัดการเชื่อมต่อฝั่งเซิร์ฟเวอร์ได้น้อยกว่าในช่วงโหลดเป็นระลอก\n\n### อะไรที่มักเข้ากับ Go HTTP API\n\nสำหรับ Go HTTP API ธรรมดา transaction pooling มักเป็นค่าเริ่มต้นที่ดี เพราะคำขอส่วนใหญ่เป็นการคิวรีเล็ก ๆ หรือ transaction สั้น ๆ แล้วเสร็จ Transaction pooling ให้ลูกค้าหลายการเชื่อมต่อแชร์งบการเชื่อมต่อ Postgres ที่เล็กกว่า\n\nข้อแลกเปลี่ยนคือสถานะ session ในโหมด transaction สิ่งที่คาดหวังว่าคงอยู่บนการเชื่อมต่อเดียวอาจเสียหรือทำงานผิดพลาดได้ รวมถึง:\n\n- prepared statements ที่สร้างครั้งเดียวแล้วนำมาใช้ซ้ำภายหลัง\n- การตั้งค่า session ที่คาดว่าจะคงอยู่ (SET, SET ROLE, search_path)\n- ตารางชั่วคราว (temporary tables) และ advisory locks ที่ใช้ข้ามหลายคำสั่ง\n\nถ้าแอปของคุณพึ่งพาสถานะแบบนั้น session pooling ปลอดภัยกว่า Statement pooling เข้มงวดที่สุดและไม่ค่อยเหมาะกับเว็บแอป\n\nกฎที่เป็นประโยชน์: ถ้าคำขอแต่ละรายการสามารถตั้งค่าที่ต้องการภายใน transaction เดียวได้ transaction pooling มักจะทำให้ latency เสถียรกว่าในช่วงโหลด หากต้องการพฤติกรรม session ยาวนาน ให้ใช้ session pooling และตั้งข้อจำกัดในแอปให้เข้มงวดกว่า\n\n## วิธีเลือกกลยุทธ์ที่ถูกต้องสำหรับ backend Go\n\nถ้าคุณรันบริการ Go ที่ใช้ database/sql คุณก็มีพูลฝั่งแอปอยู่แล้ว สำหรับหลายทีม นั่นเพียงพอ: มีอินสแตนซ์ไม่กี่ตัว ทราฟฟิกสม่ำเสมอ และคำสั่งไม่กระโดดมาก ในกรณีนั้นตัวเลือกที่เรียบง่ายและปลอดภัยคือปรับพูลของ Go ให้อยู่ในระดับที่เหมาะสม รักษาขีดจำกัดการเชื่อมต่อให้สมเหตุสมผล แล้วจบที่นั่น\n\nPgBouncer ช่วยได้มากเมื่อฐานข้อมูลโดนการเชื่อมต่อจากลูกค้าจำนวนมากพร้อมกัน ปรากฏเมื่อมีหลายอินสแตนซ์แอป (หรือสเกลแบบ serverless), ทราฟฟิกเป็นระลอก, และคำสั่งสั้น ๆ จำนวนมาก\n\nPgBouncer ก็อาจทำให้ปัญหาเกิดขึ้นหากใช้ในโหมดที่ผิด หากโค้ดของคุณพึ่งพาสถานะ session (temp tables, prepared statements ข้ามคำขอ, advisory locks ข้ามการเรียก, หรือการตั้งค่า session) transaction pooling อาจทำให้เกิดความผิดพลาดที่สับสน หากคุณต้องการพฤติกรรมแบบ session จริง ๆ ให้ใช้ session pooling หรือข้าม PgBouncer แล้วปรับขนาดพูลในแอปอย่างระมัดระวัง\n\n### กฎตัดสินใจง่าย ๆ\n\nใช้กฎตัดสินใจนี้เป็นแนวทาง:\n\n- หากมี 1–3 อินสแตนซ์และจำนวนการเชื่อมต่อรวมยังอยู่ต่ำกว่าขีดจำกัดฐานข้อมูล ให้ใช้เฉพาะพูลในแอป\n- หากมีหลายอินสแตนซ์หรือ autoscaling และผลรวมของ max open connections อาจเกินสิ่งที่ Postgres รับไหว ให้เพิ่ม PgBouncer\n- หากคำขอส่วนใหญ่สั้น (อ่านเร็ว เขียนเล็ก) PgBouncer มักคุ้มค่า\n- หากคำขอใช้การเชื่อมต่อยาว (รายงานช้า transaction ยาว) แก้คำสั่งช้าให้ก่อนและระมัดระวังขนาดพูล\n\n## ขั้นตอนทีละขั้น: กำหนดขนาดและเปิดใช้งานพูลอย่างปลอดภัย\n\nข้อจำกัดการเชื่อมต่อเป็นงบประมาณ หากใช้งบทั้งหมดพร้อมกัน คำขอใหม่ทุกอันจะรอและ tail latency จะพุ่ง เป้าหมายคือจำกัดความขนานในทางที่ควบคุมได้ ในขณะเดียวกันรักษาผลผลิตให้คงที่\n\n### ลำดับการเปิดใช้งานที่เป็นประโยชน์\n\n1) วัดจุดสูงสุดและ tail latency ปัจจุบัน บันทึกการเชื่อมต่อ active สูงสุด (ไม่ใช่ค่าเฉลี่ย) พร้อม p50/p95/p99 ของคำขอและคิวรีสำคัญ และหมายเหตุข้อผิดพลาดหรือ timeout ที่เกิด\n\n2) ตั้งงบการเชื่อมต่อปลอดภัยสำหรับแอป เริ่มจาก max_connections แล้วหักที่ว่างให้ admin, migrations, งานแบ็กกราวด์, และการระเบิด หากหลายบริการใช้ฐานข้อมูลเดียวกัน ให้แบ่งงบอย่างตั้งใจ\n\n3) แมปงบไปยังขีดจำกัด Go ต่ออินสแตนซ์ หารงบแอปด้วยจำนวนอินสแตนซ์และตั้ง MaxOpenConns ให้เท่าหรือเล็กกว่าเล็กน้อย ตั้ง MaxIdleConns ให้พอเพียงเพื่อหลีกเลี่ยง reconnect บ่อย และตั้งอายุการใช้งานให้รีไซเคิลเป็นบางครั้งโดยไม่เกิด churn\n\n4) เพิ่ม PgBouncer เฉพาะเมื่อจำเป็น และเลือกโหมด ใช้ session pooling หากต้องการสถานะ session คงอยู่ ใช้ transaction pooling เมื่อต้องการลดการเชื่อมต่อฝั่งเซิร์ฟเวอร์มากที่สุดและแอปเข้ากันได้\n\n5) นำขึ้นอย่างค่อยเป็นค่อยไปและเปรียบเทียบก่อน-หลัง เปลี่ยนทีละอย่าง ทดสอบแบบ canary แล้วเปรียบเทียบ tail latency, pool wait time, และ CPU ของ DB\n\nตัวอย่าง: หาก Postgres ให้บริการของคุณได้อย่างปลอดภัย 200 การเชื่อมต่อและคุณรัน 10 อินสแตนซ์ Go ให้เริ่มที่ MaxOpenConns=15-18 ต่ออินสแตนซ์ แบบนี้เหลือช่องสำหรับระลอกและลดความเป็นไปได้ที่ทุกอินสแตนซ์จะชนเพดานพร้อมกัน\n\n## เมตริกที่ควรเฝ้าดูเพื่อจับปัญหาให้เร็ว\n\nปัญหาพูลมักไม่ปรากฏเป็น “too many connections” ก่อน แต่จะเห็นการเพิ่มขึ้นช้า ๆ ของเวลารอ แล้วตามด้วยการกระโดดของ p95 และ p99\n\nเริ่มจากสิ่งที่แอปรายงานได้ ใน database/sql เฝ้าดู open connections, in-use, idle, wait count, และ wait time หาก wait count เพิ่มในขณะที่ทราฟฟิกคงที่ แปลว่าพูลเล็กเกินไปหรือการเชื่อมต่อถูกถือไว้นานเกินไป\n\nฝั่งฐานข้อมูล ติดตาม active connections เทียบกับ max, CPU, และ activity ของ lock หาก CPU ต่ำแต่ latency สูง มักเป็นการคิวหรือ lock ไม่ใช่การประมวลผลล้วน ๆ\n\nหากใช้ PgBouncer ให้เพิ่มมุมมองที่สาม: client connections, server connections ต่อ Postgres, และ queue depth หากคิวเพิ่มขึ้นแต่ว่า server connections คงที่ นั่นคือสัญญาณชัดเจนว่าคุณอิ่มงบแล้ว\n\nสัญญาณเตือนที่ดี:\n\n- p95/p99 เพิ่ม ในขณะที่ p50 ยังปกติ\n- เวลารอการเชื่อมต่อ (ฝั่งแอป) เพิ่ม โดยเฉพาะก่อนเกิด timeout\n- คิว PgBouncer เพิ่มเร็วกว่าที่ลดลง\n- อัตราข้อผิดพลาดและ timeout เพิ่มพร้อมกัน\n- lock เพิ่มควบคู่กับคำสั่งที่รันนาน\n\n## การตั้งค่าที่พบบ่อยที่ทำให้เกิดการกระโดดของ latency\n\nปัญหาพูลมักปรากฏในช่วงระลอก: คำขอถูกคิวรอการเชื่อมต่อ แล้วทุกอย่างกลับมาปกติ สาเหตุรากมักเป็นการตั้งค่าที่สมเหตุสมผลบนอินสแตนซ์เดียว แต่เป็นภัยเมื่อรันหลายสำเนาของบริการ\n\nสาเหตุปกติ:\n\n- MaxOpenConns ตั้งต่ออินสแตนซ์โดยไม่คิดงบรวม 100 ต่ออินสแตนซ์ 20 อินสแตนซ์เท่ากับ 2,000 การเชื่อมต่อ\n- มีการเชื่อมต่อ idle มากเกินไป backend ที่ idle ยังคงใช้หน่วยความจำและเบียดเบียนงานอื่นได้\n- ConnMaxLifetime / ConnMaxIdleTime ตั้งสั้นเกินไป ทำให้เกิด reconnect storm เมื่อหลายการเชื่อมต่อรีไซเคิลพร้อมกัน\n- PgBouncer ในโหมด transaction กับโค้ดที่พึ่ง session Temp tables, advisory locks และ session setting อาจพังแบบเงียบ ๆ\n- งานแบ็กกราวด์และ health check สร้างระลอก ping บ่อยหรือรูปแบบ “เปิด-ปิดต่อคำขอ” ทำให้เกิดคลื่นการเชื่อมต่อใหม่\n\nวิธีง่าย ๆ เพื่อลดการกระโดดคือถือว่าการพูลเป็นขีดจำกัดร่วม ไม่ใช่ค่าเริ่มต้นแอปท้องถิ่น: จำกัดการเชื่อมต่อรวม ขนาดพูล idle ปานกลาง และตั้งอายุการใช้งานให้ไม่เกิดการ reconnect แบบซิงโครไนซ์บ่อย ๆ\n\n## ทำอย่างไรเมื่อความต้องการเกินงบการเชื่อมต่อ\n\nเมื่อทราฟฟิกพุ่ง คุณมักจะเห็นหนึ่งในสามผลลัพธ์: คำขอคิวรอการเชื่อมต่อ, คำขอ timeout, หรือทุกอย่างช้าจน retry กองกัน\n\nการคิวเป็นสิ่งที่แอบแฝง ตัว handler ยังคงรันแต่รอการเชื่อมต่อ เวลาการรอนั้นกลายเป็นส่วนหนึ่งของเวลาตอบกลับ ดังนั้นพูลเล็กอาจเปลี่ยนคำขอที่ปกติ 50 ms ให้กลายเป็นหลายวินาทีภายใต้โหลด\n\nแบบจำลองคิดง่าย ๆ: หากพูลของคุณมี 30 การเชื่อมต่อที่ใช้งานได้และทันใดนั้นมี 300 คำขอพร้อมกันที่ต้องใช้ฐานข้อมูล 270 คำขอต้องรอ หากแต่ละคำขอถือการเชื่อมต่อ 100 ms tail latency จะกระโดดเป็นวินาทีได้เร็วมาก\n\nตั้งงบเวลา (timeouts) ให้ชัดเจนและยึดตามมัน เวลาของแอปควรสั้นกว่า timeout ของ DB เล็กน้อยเพื่อให้ fail fast และลดแรงกดดันแทนที่จะปล่อยงานแขวนไว้\n\n- แอป: กำหนด deadline ของคำขอ และ deadline รอบการเรียก DB ให้สั้นกว่า\n- DB: statement_timeout เพื่อไม่ให้คำสั่งช้าตัวเดียวถือการเชื่อมต่อตลอดไป\n- Pooler (หากใช้): ตั้ง pool wait timeout เพื่อให้ได้การปฏิเสธแทนการคิวไม่สิ้นสุด\n\nจากนั้นเพิ่ม backpressure เพื่อไม่ให้เกินพูลตั้งต้น เลือกกลไกหนึ่งหรือสองอย่างที่คาดการณ์ได้ เช่น จำกัดความขนานต่อ endpoint, ดรอปโหลดด้วยข้อผิดพลาดชัดเจน (เช่น 429), หรือแยกงานแบ็กกราวด์ออกจากทราฟฟิกผู้ใช้\n\nสุดท้าย แก้คำสั่งช้าก่อน ในเงื่อนไขที่มีพูลคำสั่งช้าทำให้การถือการเชื่อมต่อยาวขึ้น เพิ่มการรอ เพิ่ม timeout และกระตุ้น retry วงวนนี้คือวิถีที่ “ช้าหน่อย” กลายเป็น “ทุกอย่างช้า”\n\n## การทดสอบโหลดและการวางแผนความจุโดยไม่ต้องเดา\n\nถือการทดสอบโหลดเป็นการยืนยันงบการเชื่อมต่อ ไม่ใช่แค่ผ่าน throughput เป้าหมายคือยืนยันว่าการพูลทำงานภายใต้แรงกดดันแบบเดียวกับในสเตจจิ้ง\n\nทดสอบด้วยทราฟฟิกที่สมจริง: สัดส่วนคำขอแบบเดียวกัน รูปแบบการระเบิด และจำนวนอินสแตนซ์แอปเท่ากับที่รันใน production เบนช์มาร์ค “endpoint เดียว” มักซ่อนปัญหาพูลจนถึงวันเปิดตัว\n\nรวมช่วง warm-up เพื่อไม่วัดผล cold cache และเอฟเฟกต์การ ramp-up ให้พูลถึงขนาดปกติ แล้วเริ่มบันทึกตัวเลข\n\nหากเปรียบเทียบกลยุทธ์ ให้รันภายใต้โหลดเดียวกัน:\n\n- เฉพาะ app pooling (ปรับ database/sql ให้เหมาะสม ไม่มี PgBouncer)\n- PgBouncer ข้างหน้า (แอปเก็บพูลเล็ก PgBouncer จำกัดการเชื่อมต่อเซิร์ฟเวอร์)\n- ทั้งสองร่วมกัน (พูลแอปเล็ก + PgBouncer)\n\nหลังแต่ละการทดสอบ บันทึกสกอร์การ์ดเล็ก ๆ ที่ใช้ซ้ำได้หลังแต่ละ release:\n\n- p95 และ p99 ของคำขอทั้งใน steady state และระหว่างระลอก\n- จำนวนการเชื่อมต่อสูงสุดรวม (ฝั่ง client และฝั่ง server)\n- สัญญาณเวลาในการคิว (waiting for a free connection)\n- อัตราข้อผิดพลาดและจำนวน timeout\n- throughput ณ จุดที่ latency เริ่มพุ่งเร็ว\n\nเมื่อเวลาผ่านไป วิธีนี้จะทำให้การวางแผนความจุกลายเป็นสิ่งที่ทำซ้ำได้ แทนที่จะเป็นการเดา\n\n## เช็คลิสต์ด่วนและขั้นตอนถัดไป\n\nก่อนปรับขนาดพูล ให้เขียนตัวเลขหนึ่งตัวลงไป: งบเชื่อมต่อของคุณ นั่นคือจำนวนการเชื่อมต่อ Postgres ที่ปลอดภัยสูงสุดสำหรับสภาพแวดล้อมนี้ (dev, staging, prod) รวมงานแบ็กกราวด์และการเข้าถึงของแอดมิน หากคุณบอกไม่ได้แปลว่าคุณกำลังเดา\n\nเช็คลิสต์ด่วน:\n\n- ตั้ง max ใน Go ชัดเจน และแน่ใจว่า (instances x MaxOpenConns) เข้ากับงบ (หรือขีดจำกัด PgBouncer)\n- ตั้ง timeout เพื่อไม่ให้ “รอไปเรื่อย ๆ” ซ่อนปัญหาจนเกิดระลอก\n- หากใช้ PgBouncer ให้เลือกโหมดพูลที่สอดคล้องกับการใช้สถานะ session ของคุณ\n- หลีกเลี่ยงอายุการเชื่อมต่อสั้นมากที่ทำให้เกิด reconnect ตลอดเวลา\n- ยืนยันว่า max_connections และการจองการเชื่อมต่อสอดคล้องกับแผนของคุณ\n\nแผนการเปิดใช้งานที่ยกเลิกได้ง่าย:\n\n1) เปลี่ยนในสเตจจิ้ง ภายใต้การทดสอบโหลดที่จำลองความขนานและสัดส่วนอ่าน/เขียนของ production\n2) เปิดใน production แบบก้าวเล็ก (กลุ่มอินสแตนซ์หรือบริการทีละชุด)\n3) เฝ้าดู p95 latency, pool wait time, ข้อผิดพลาด และจำนวนการเชื่อมต่อ Postgres ผ่านหน้าต่างพีคอย่างน้อยหนึ่งรอบ\n4) หาก p95 กระโดดหรือ pool wait spike ให้ย้อนกลับและลดความขนานหรือขนาดพูล\n\nหากคุณกำลังสร้างและโฮสต์แอป Go + PostgreSQL บน Koder.ai (koder.ai), Planning Mode สามารถช่วยให้คุณแมปการเปลี่ยนแปลงและสิ่งที่จะวัดได้ และ snapshots พร้อม rollback ทำให้ย้อนกลับได้ง่ายหาก tail latency แย่ลง\n\nขั้นตอนต่อไป: เพิ่มการวัดหนึ่งรายการก่อนที่ทราฟฟิกจะพุ่งขึ้น “เวลาที่ใช้ไปรอการเชื่อมต่อ” ในแอปมักเป็นตัวชี้วัดที่มีประโยชน์ที่สุด เพราะมันแสดงแรงกดดันของพูลก่อนที่ผู้ใช้จะรู้สึกถึงปัญหา\nA pool keeps a small set of PostgreSQL connections open and reuses them across requests. This avoids paying the setup cost (TCP/TLS, auth, backend process setup) over and over, which helps keep tail latency steady during bursts.
When the pool is saturated, requests wait inside your app for a free connection, and that wait time shows up as slow responses. This often looks like “random slowness” because averages can stay fine while p95/p99 jump during traffic bursts.
No, it mostly changes how the system behaves under load by reducing reconnect churn and controlling concurrency. If a query is slow because of scans, locks, or poor indexing, pooling can’t make it fast; it can only limit how many slow queries run at once.
App pooling manages connections per process, so each app instance has its own pool and its own limits. PgBouncer sits in front of Postgres and enforces a global connection budget across many clients, which is especially useful when you have many replicas or spiky traffic.
If you run a small number of instances and your total open connections stay comfortably under the database limit, tuning Go’s database/sql pool is usually enough. Add PgBouncer when many instances, autoscaling, or bursty traffic could push total connections beyond what Postgres can handle smoothly.
A good default is to set a total connection budget for the service, then divide it by the number of app instances and set MaxOpenConns slightly below that per instance. Start small, watch wait time and p95/p99, and only increase if you’re sure the database has headroom.
Transaction pooling is often a strong default for typical HTTP APIs because it lets many client connections share fewer server connections and stays stable during bursts. Use session pooling if your code relies on session state persisting across statements, such as temp tables, session settings, or prepared statements reused across requests.
Prepared statements, temp tables, advisory locks, and session-level settings can behave differently because a client may not get the same server connection next time. If you need those features, either keep everything within a single transaction per request or switch to session pooling to avoid confusing failures.
Watch p95/p99 latency alongside app pool wait time, because wait time often rises before users complain. On Postgres, track active connections, CPU, and locks; on PgBouncer, track client connections, server connections, and queue depth to see if you’re saturating your connection budget.
First, stop unlimited waiting by setting request deadlines and a DB statement timeout so one slow query can’t hold connections forever. Then add backpressure by limiting concurrency for DB-heavy endpoints or shedding load, and reduce connection churn by avoiding overly short connection lifetimes that cause reconnect storms.