23 ต.ค. 2568·2 นาที
การกรองฝั่งเซิร์ฟเวอร์ vs ฝั่งไคลเอนต์: เช็คลิสต์ตัดสินใจ
เช็คลิสต์การเลือกระหว่างการกรองฝั่งเซิร์ฟเวอร์กับฝั่งไคลเอนต์ โดยพิจารณาจากขนาดข้อมูล ความหน่วง สิทธิ์การเข้าถึง และการแคช เพื่อหลีกเลี่ยงการรั่วไหลของ UI และการหน่วง
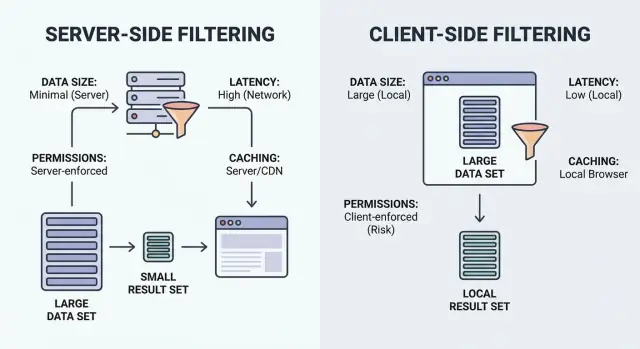
เช็คลิสต์การเลือกระหว่างการกรองฝั่งเซิร์ฟเวอร์กับฝั่งไคลเอนต์ โดยพิจารณาจากขนาดข้อมูล ความหน่วง สิทธิ์การเข้าถึง และการแคช เพื่อหลีกเลี่ยงการรั่วไหลของ UI และการหน่วง
การกรองใน UI มากกว่าแค่กล่องค้นหาเดียว มันมักจะรวมหลายการกระทำที่เปลี่ยนสิ่งที่ผู้ใช้เห็น: การค้นหาด้วยข้อความ (ชื่อ, อีเมล, หมายเลขคำสั่ง), เฟซเซ็ต (สถานะ, เจ้าของ, ช่วงวันที่, แท็ก) และการเรียงลำดับ (ล่าสุด, มูลค่าสูงสุด, กิจกรรมล่าสุด).
คำถามสำคัญไม่ใช่ว่าเทคนิคไหน “ดีกว่า” แต่คือชุดข้อมูลทั้งหมดอยู่ที่ไหน และใครได้รับสิทธิ์เข้าถึง หากเบราว์เซอร์ได้รับเรคคอร์ดที่ผู้ใช้ไม่ควรเห็น UI อาจเปิดเผยข้อมูลที่ละเอียดอ่อนแม้จะซ่อนไว้ทางสายตาก็ตาม.
การถกเถียงส่วนใหญ่เกี่ยวกับการกรองฝั่งเซิร์ฟเวอร์กับฝั่งไคลเอนต์ เป็นการตอบสนองต่อความล้มเหลวสองอย่างที่ผู้ใช้สังเกตได้ทันที:
มีประเด็นที่สามที่สร้างรายงานบั๊กไม่รู้จบ: ผลลัพธ์ที่ไม่สอดคล้องกัน หากตัวกรองบางอย่างทำงานบนไคลเอนต์และบางอย่างบนเซิร์ฟเวอร์ ผู้ใช้จะเห็นจำนวน หน้า และยอดรวมที่ไม่ตรงกัน ซึ่งทำให้ความเชื่อมั่นแตกสลายอย่างรวดเร็ว โดยเฉพาะในรายการที่แบ่งหน้า
ค่าเริ่มต้นที่ใช้งานได้จริงคือเรียบง่าย: ถ้าผู้ใช้ไม่ได้รับอนุญาตให้เข้าถึงชุดข้อมูลทั้งหมด ให้กรองบนเซิร์ฟเวอร์ ถ้าพวกเขาได้รับอนุญาตและชุดข้อมูลเล็กพอที่จะโหลดได้เร็ว การกรองบนไคลเอนต์ก็โอเค
การกรองก็คือ “แสดงรายการที่ตรงตามเงื่อนไข” คำถามคือการจับคู่เกิดขึ้นที่ไหน: ในเบราว์เซอร์ของผู้ใช้ (ไคลเอนต์) หรือบนแบ็กเอนด์ของคุณ (เซิร์ฟเวอร์)
การกรองฝั่งไคลเอนต์ ทำงานในเบราว์เซอร์ แอปดาวน์โหลดชุดเรคคอร์ด (มักเป็น JSON) แล้วนำตัวกรองมาประยุกต์ในเครื่อง มันอาจรู้สึกทันทีหลังจากโหลดข้อมูล แต่ทำงานได้เมื่อชุดข้อมูลเล็กพอที่จะส่งและปลอดภัยพอที่จะเปิดเผย
การกรองฝั่งเซิร์ฟเวอร์ ทำงานบนแบ็กเอนด์ของคุณ เบราว์เซอร์ส่งค่าตัวกรอง (เช่น status=open, owner=me, createdAfter=Jan 1) แล้วเซิร์ฟเวอร์ส่งเฉพาะผลลัพธ์ที่ตรงกัน ในความเป็นจริงนี่มักเป็น endpoint ของ API ที่รับตัวกรอง สร้างคำสั่งฐานข้อมูล และส่งรายการที่แบ่งหน้าพร้อมยอดรวม
แบบจำลองง่าย ๆ ในหัว:
การตั้งค่าผสมเป็นเรื่องปกติ แบบแผนที่ดีคือตรวจสอบตัวกรอง “ใหญ่” บนเซิร์ฟเวอร์ (สิทธิ์ การเป็นเจ้าของ ช่วงวันที่ การค้นหา) แล้วใช้สวิตช์เล็ก ๆ ใน UI ท้องถิ่น (เช่น ซ่อนรายการที่เก็บถาวร แท็กด่วน หรือการมองคอลัมน์) โดยไม่ต้องขอข้อมูลใหม่
การเรียงลำดับ การแบ่งหน้า และการค้นหามักเกี่ยวข้องกับการตัดสินใจเดียวกัน เพราะส่งผลต่อขนาด payload ความรู้สึกของผู้ใช้ และข้อมูลที่คุณเปิดเผย
เริ่มจากคำถามที่เป็นประโยชน์ที่สุด: คุณจะส่งข้อมูลเท่าไรไปยังเบราว์เซอร์ถ้ากรองที่ไคลเอนต์? ถ้าคำตอบจริง ๆ คือ “มากกว่าจำนวนหน้าจอไม่กี่หน้า” คุณจะจ่ายค่าด้านเวลาในการดาวน์โหลด ความจำ และการทำงานที่ช้าลง
คุณไม่ต้องการประมาณที่แม่นยำ แค่มองขนาดคร่าว ๆ: ผู้ใช้อาจเห็นกี่แถว และขนาดเฉลี่ยต่อแถวเท่าไร รายการ 500 รายการที่มีฟิลด์สั้น ๆ แตกต่างจาก 50,000 รายการที่แต่ละแถวมีหมายเหตุยาว ๆ ข้อความรูปแบบรวย หรือออบเจ็กต์ซ้อนกัน
เรคคอร์ดที่ “กว้าง” คือฆาตกร payload เงียบ ๆ ตารางอาจดูเล็กตามจำนวนแถว แต่หนักหากแต่ละแถวมีหลายฟิลด์ สตริงยาว หรือข้อมูลที่ join มา (ติดต่อ + บริษัท + กิจกรรมล่าสุด + ที่อยู่เต็ม + แท็ก) แม้จะแสดงแค่สามคอลัมน์ ทีมงานมักจะส่ง “ทุกอย่าง เผื่อไว้” ทำให้ payload เพิ่มขึ้น
คิดถึงการเติบโตด้วย ชุดข้อมูลที่พอได้ในวันนี้อาจเจอปัญหาหลังผ่านไปไม่กี่เดือน ถ้าข้อมูลเติบโตเร็ว ให้ถือว่าการกรองที่ไคลเอนต์เป็นทางลัดระยะสั้น ไม่ใช่ค่าเริ่มต้น
กฎคร่าว ๆ:
ข้อสุดท้ายสำคัญกว่าประสิทธิภาพด้วย “เราจะส่งชุดข้อมูลทั้งหมดไปยังเบราว์เซอร์ได้ไหม?” ก็เป็นคำถามด้านความปลอดภัย ถ้าคำตอบไม่ใช่ "ใช่" แบบมั่นใจ อย่าส่ง
การเลือกวิธีกรองมักล้มเหลวที่ความรู้สึก ไม่ใช่ความถูกต้อง ผู้ใช้ไม่วัดเป็นมิลลิวินาที แต่สังเกตการหน่วง การกระพริบ และผลลัพธ์ที่กระโดดไปรอบ ๆ ขณะพิมพ์
เวลาสามารถหายไปในหลายจุด:
กำหนดว่า “เร็วพอ” สำหรับหน้าจอนี้คืออะไร รายการบางหน้าอาจต้องการการพิมพ์ที่ตอบสนองและการเลื่อนที่ลื่น ส่วนหน้ารายงานอาจรอได้สั้น ๆ ตราบใดที่ผลลัพธ์แรกปรากฏเร็ว
อย่าใช้แค่ Wi‑Fi ในออฟฟิศเป็นมาตรฐาน ในการเชื่อมต่อช้า การกรองที่ไคลเอนต์อาจดูดีหลังโหลดครั้งแรก แต่การโหลดครั้งแรกอาจช้า ในขณะที่การกรองบนเซิร์ฟเวอร์จะทำให้ payload เล็ก แต่สามารถรู้สึกหน่วงถ้าส่งคำขอทุกครั้งที่พิมพ์
ออกแบบให้เข้ากับการป้อนข้อมูลของมนุษย์ ใช้ debounce ระหว่างการพิมพ์ สำหรับชุดผลลัพธ์ใหญ่ ให้ใช้การโหลดทีละส่วนเพื่อให้หน้าแสดงบางอย่างเร็วและยังคงลื่นขณะเลื่อน
สิทธิ์ควรตัดสินแนวทางการกรองของคุณมากกว่าความเร็ว ถ้าเบราว์เซอร์เคยได้รับข้อมูลที่ผู้ใช้ไม่ควรเห็น แปลว่าคุณมีปัญหาแล้ว แม้จะซ่อนในปุ่มที่ปิดใช้งานหรือคอลัมน์พับไว้ก็ตาม
เริ่มจากการตั้งชื่อว่าสิ่งใดในหน้าจอนี้ถือเป็นข้อมูลละเอียดอ่อน บางฟิลด์ชัดเจน (อีเมล เบอร์โทร ที่อยู่) อื่น ๆ มักถูกมองข้าม: หมายเหตุภายใน ต้นทุนหรือมาร์จิ้น กฎการตั้งราคาพิเศษ คะแนนความเสี่ยง ธงการดูแลข้อความ
กับดักใหญ่คือ “เรากรองที่ไคลเอนต์ แต่แค่แสดงแถวที่อนุญาต” นั่นยังหมายความว่าชุดข้อมูลทั้งหมดถูกดาวน์โหลด ใครก็ได้ดูการตอบกลับเครือข่าย เปิด dev tools หรือบันทึก payload การซ่อนคอลัมน์ใน UI ไม่ใช่การควบคุมการเข้าถึง
การกรองฝั่งเซิร์ฟเวอร์ปลอดภัยกว่าเมื่อการอนุญาตแตกต่างกันตามผู้ใช้ โดยเฉพาะเมื่อผู้ใช้ต่างกันเห็นแถวหรือฟิลด์ต่างกัน
ตรวจสอบอย่างรวดเร็ว:
ถ้าตอบใช่สำหรับข้อใด ให้คงการกรองและการเลือกฟิลด์ไว้บนเซิร์ฟเวอร์ ส่งเฉพาะสิ่งที่ผู้ใช้ได้รับอนุญาตให้เห็น และใช้กฎเดียวกันกับการค้นหา การเรียงลำดับ การแบ่งหน้า และการส่งออก
ตัวอย่าง: ในรายการติดต่อ CRM เซลส์รีพ์ดูบัญชีของตัวเองได้เท่านั้น ในขณะที่ผู้จัดการดูได้ทั้งทีม ถ้าเบราว์เซอร์ดาวน์โหลดรายชื่อติดต่อทั้งหมดแล้วกรองในเครื่อง รีพ์ยังสามารถกู้คืนบัญชีที่ซ่อนอยู่จากการตอบกลับการเรียกดู การกรองฝั่งเซิร์ฟเวอร์ป้องกันได้โดยไม่ส่งแถวเหล่านั้นเลย
การแคชทำให้หน้าจอรู้สึกทันที แต่อาจแสดงความจริงที่ผิดได้ กุญแจคือการตัดสินใจว่าอนุญาตให้ใช้ซ้ำอะไร นานแค่ไหน และเหตุการณ์ใดจะล้างมัน
เริ่มจากเลือกหน่วยของการแคช การแคชรายการทั้งหมดง่ายแต่มักสิ้นเปลืองแบนด์วิดท์และเก่าเร็ว การแคชเป็นเพจเหมาะกับ infinite scroll การแคชผลลัพธ์ของคำค้นหา (ตัวกรอง + การเรียงลำดับ + การค้นหา) ถูกต้องแต่โตเร็วถ้าผู้ใช้ลองชุดค่ามาก
ความสดสำคัญกว่าบางโดเมน ถ้าข้อมูลเปลี่ยนเร็ว (ระดับสต็อก ยอดคงเหลือ สถานะการจัดส่ง) แม้แคช 30 วินาทีก็ทำให้ผู้ใช้สับสน ถ้าข้อมูลเปลี่ยนช้า (ข้อมูลอ้างอิง ระเบียนเก่า) การแคชยาวกว่ามักโอเค
วางแผนการล้างก่อนเขียนโค้ด นอกจากเวลาผ่านไป ตัดสินใจว่าจะให้เหตุการณ์ใดบังคับรีเฟรช: สร้าง/แก้ไข/ลบ การเปลี่ยนสิทธิ์ การนำเข้าหรือการรวมข้อมูลแบบกลุ่ม การเปลี่ยนสถานะ การเลิกทำ/ย้อนกลับ และงานแบ็กกราวด์ที่อัปเดตฟิลด์ที่ผู้ใช้กรอง
ยังต้องตัดสินใจว่าการแคชอยู่ที่ไหน หน่วยความจำเบราว์เซอร์ทำให้การนำทางกลับ/หน้าเร็ว แต่สามารถรั่วข้อมูลข้ามบัญชีได้ถ้าไม่ใส่คีย์ตามผู้ใช้และองค์กร แคชฝั่งแบ็กเอนด์ปลอดภัยกว่าในด้านสิทธิ์และความสอดคล้อง แต่ต้องรวมลายเซ็นเต็มของตัวกรองและตัวตนของผู้เรียกเพื่อไม่ให้ผลลัพธ์ปะปน
ตั้งเป้าหมายที่ไม่ต่อรอง: หน้าจอควรรู้สึกเร็วโดยไม่รั่วข้อมูล
ทีมส่วนใหญ่โดนแบบเดียวกัน: UI ดูดีในเดโม แต่ข้อมูลจริง สิทธิ์จริง และความเร็วเครือข่ายจริงเปิดเผยข้อบกพร่อง
ความล้มเหลวที่ร้ายแรงที่สุดคือปฏิบัติต่อการกรองเป็นแค่การนำเสนอ ถ้าเบราว์เซอร์ได้รับเรคคอร์ดที่ไม่ควรมี คุณก็แพ้แล้ว
สองสาเหตุทั่วไป:
ตัวอย่าง: นักศึกษาฝึกงานควรเห็นลีดจากภูมิภาคของตนเท่านั้น ถ้า API คืนทุกภูมิภาคและ dropdown กรองใน React นักศึกษาฝึกงานยังคงดึงรายการเต็มได้
ความหน่วงมักมาจากสมมติฐาน:
ปัญหาเล็ก ๆ แต่ทรมานคือกฎไม่ตรงกัน ถ้าเซิร์ฟเวอร์จัดการ “starts with” ต่างจาก UI ผู้ใช้จะเห็นจำนวนไม่ตรงกัน หรือไอเท็มหายไปหลังรีเฟรช
ตรวจสองมุมมอง: ผู้ใช้ที่อยากรู้อยากเห็น และวันที่เครือข่ายแย่
การทดสอบง่าย ๆ: สร้างเรคคอร์ดที่ถูกจำกัดและยืนยันว่ามันไม่ปรากฏใน payload ยอดรวม หรือแคช แม้จะกรองกว้างหรือเคลียร์ตัวกรอง
ลองนึกภาพ CRM ที่มีติดต่อ 200,000 ราย เซลส์รีพ์เห็นเฉพาะบัญชีของตัวเอง ผู้จัดการเห็นทั้งทีม และแอดมินเห็นทั้งหมด หน้าจอมีการค้นหา ตัวกรอง (สถานะ, เจ้าของ, กิจกรรมล่าสุด) และการเรียงลำดับ
การกรองที่ไคลเอนต์ล้มเหลวเร็วที่นี่ payload หนัก การโหลดครั้งแรกช้า และความเสี่ยงการรั่วสูง แม้ UI จะซ่อนแถว เบราว์เซอร์ก็ยังได้รับข้อมูล นอกจากนี้ยังสร้างแรงกดดันบนอุปกรณ์: อาร์เรย์ขนาดใหญ่ การเรียงลำดับหนัก การรันตัวกรองซ้ำ ๆ การใช้หน่วยความจำสูง และแครชบนโทรศัพท์รุ่นเก่า
วิธีที่ปลอดภัยคือการกรองฝั่งเซิร์ฟเวอร์พร้อมการแบ่งหน้า ไคลเอน์ส่งค่าตัวกรองและข้อความค้นหา เซิร์ฟเวอร์ส่งเฉพาะแถวที่ผู้ใช้ได้รับอนุญาตให้เห็น และกรองเรียงลำดับไว้แล้ว
แบบแผนปฏิบัติได้:
ข้อยกเว้นเล็ก ๆ ที่การกรองที่ไคลเอนต์พอใช้ได้: ข้อมูลเล็ก ๆ คงที่ เช่น dropdown สำหรับ “สถานะติดต่อ” ที่มี 8 ค่า โหลดครั้งเดียวและกรองท้องถิ่นได้ปลอดภัย
ทีมมักไม่ถูกทำร้ายเพราะเลือกผิดครั้งเดียว แต่เพราะเลือกต่างกันในแต่ละหน้าจอ แล้วพยายามแก้ปัญหาการรั่วและหน้าช้าภายใต้ความกดดัน
เขียนบันทึกการตัดสินใจสั้น ๆ ต่อหน้าจอ ระบุ: ขนาดชุดข้อมูล ต้นทุนการส่ง อะไรคือ “เร็วพอ” ฟิลด์ไหนละเอียดอ่อน และจะจัดการแคชอย่างไร (หรือไม่) เก็บเซิร์ฟเวอร์และ UI ให้ตรงกันเพื่อไม่ให้เกิด “ความจริงสองชุด” สำหรับการกรอง
ถ้าคุณสร้างหน้าจออย่างรวดเร็วใน Koder.ai (koder.ai) ควรตัดสินใจก่อนว่าตัวกรองใดต้องบังคับบนแบ็กเอนด์ (สิทธิ์และการเข้าถึงระดับแถว) และตัวสวิตช์เล็ก ๆ ไหนอยู่ในเลเยอร์ React การเลือกว่าอย่างใดอย่างหนึ่งตั้งแต่ต้นมักป้องกันการเขียนโค้ดแก้ไขที่มีค่าใช้จ่ายสูงภายหลัง
Default to server-side when users have different permissions, the dataset is large, or you care about consistent pagination and totals. Use client-side only when the full dataset is small, safe to expose, and fast to download.
Because anything the browser receives can be inspected. Even if the UI hides rows or columns, a user can still see data in network responses, cached payloads, or in-memory objects.
It usually happens when you ship too much data and then filter/sort large arrays on every keystroke, or when you fire a server request for every keypress without debouncing. Keep payloads small and avoid doing heavy work on each input change.
Keep one source of truth for the “real” filters: permissions, search, sorting, and pagination should be enforced on the server together. Then limit client-side logic to small UI-only toggles that don’t change the underlying dataset.
Client-side caching can show stale or wrong data, and it can leak data across accounts if not keyed properly. Server-side caching is safer for permissions, but it must include the full filter signature and the caller identity so results don’t get mixed.
Ask two questions: how many rows could a user realistically have, and how large is each row in bytes. If you wouldn’t comfortably load it on a typical mobile connection or on an older device, move filtering to the server and paginate.
Server-side. If roles, teams, regions, or ownership rules change what someone can see, the server must enforce row and field access. The client should only receive records and fields the user is allowed to view.
Define the filter and sort contract first: accepted filter fields, default sorting, pagination rules, and how search matches (case, accents, partial matches). Then implement the same logic consistently on the backend and test that totals and pages match.
Debounce typing so you don’t request on every keypress, and keep old results visible until new results arrive to reduce flicker. Use pagination or progressive loading so the user sees something quickly without blocking on a huge response.
Apply permissions first, then filters and sorting, and return only one page plus a total count. Avoid sending “extra fields just in case,” and ensure caching keys include user/org/role so a rep never receives data meant for a manager.