31 ส.ค. 2568·2 นาที
การเปลี่ยนสคีมาโดยไม่หยุดทำงานด้วยรูปแบบ Expand/Contract
เรียนรู้การเปลี่ยนสคีมาโดยไม่หยุดทำงานด้วยรูปแบบ expand/contract: เพิ่มคอลัมน์อย่างปลอดภัย, backfill ทีละแบตช์, ปล่อยโค้ดที่เข้ากันได้ย้อนหลัง แล้วค่อยลบเส้นทางเก่า
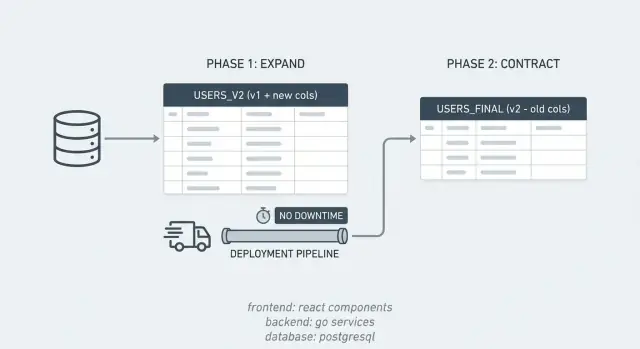
เรียนรู้การเปลี่ยนสคีมาโดยไม่หยุดทำงานด้วยรูปแบบ expand/contract: เพิ่มคอลัมน์อย่างปลอดภัย, backfill ทีละแบตช์, ปล่อยโค้ดที่เข้ากันได้ย้อนหลัง แล้วค่อยลบเส้นทางเก่า
full_name เป็น first_name และ last_name คุณเพิ่มคอลัมน์ใหม่ (expand), ปล่อยโค้ดที่อ่าน/เขียนได้สองรูปแบบ, backfill แถวเก่า, แล้วค่อยดรอป full_name เมื่อมั่นใจว่าไม่มีใครใช้มันแล้ว (contract)\n\n## สิ่งที่มักทำในเฟส "expand"\n\nเฟส expand คือการเพิ่มตัวเลือกใหม่ ไม่ใช่การลบของเก่า\n\nการเคลื่อนไหวแรกที่พบบ่อยคือการเพิ่มคอลัมน์ใหม่ ใน PostgreSQL ปลอดภัยที่สุดมักเป็นการเพิ่มเป็น nullable และไม่มี default การเพิ่มคอลัมน์ที่ไม่เป็น NULL พร้อม default อาจทำให้เกิดการเขียนตารางใหม่หรือล็อกหนัก ขึ้นอยู่กับเวอร์ชัน Postgres และการเปลี่ยนแปลงที่แน่นอน ลำดับที่ปลอดภัยกว่าคือ: เพิ่มแบบ nullable, ปล่อยโค้ดที่ทนได้, backfill, แล้วค่อยบังคับ NOT NULL ทีหลัง\n\nดัชนียังต้องระวัง การสร้างดัชนีแบบปกติอาจบล็อกการเขียนนานกว่าที่คาดไว้ เมื่อเป็นไปได้ ให้สร้างดัชนีแบบ concurrent เพื่อให้การอ่านและเขียนยังทำงานได้ มันใช้เวลานานกว่าแต่หลีกเลี่ยงล็อกที่หยุดการปล่อย\n\nExpand ยังหมายถึงการเพิ่มตารางใหม่ได้ด้วย ถ้าคุณย้ายจากคอลัมน์เดียวไปเป็นความสัมพันธ์ many-to-many คุณอาจเพิ่มตารางเชื่อม (join table) ในขณะที่ยังเก็บคอลัมน์เก่าไว้ ทางเก่ายังทำงานในขณะที่โครงสร้างใหม่เริ่มเก็บข้อมูล\n\nในการปฏิบัติ expand มักรวมถึง:\n\n- การเพิ่มคอลัมน์ nullable หรือเทเบิลใหม่ควบคู่กับของเดิม\n- การสร้างดัชนีในวิธีที่ไม่บล็อกเมื่อเป็นไปได้\n- ใช้ feature flags เพื่อควบคุมการเปิดอ่านหรือเขียนใหม่\n- เขียนทั้งฟิลด์เก่าและใหม่ (dual-write) เมื่อต้องการ\n- ทำให้การอ่านรองรับย้อนหลัง (เก่า ใหม่ หรือ fallback)\n\nหลัง expand เวอร์ชันแอปเก่าและใหม่ควรทำงานร่วมกันโดยไม่มีปัญหา\n\n## ปล่อยโค้ดที่คงความเข้ากันได้\n\nความเจ็บปวดจากการปล่อยส่วนใหญ่เกิดช่วงกลาง: บางเซิร์ฟเวอร์รันโค้ดใหม่ บางเครื่องยังโค้ดเก่า ขณะที่ฐานข้อมูลกำลังเปลี่ยน จุดมุ่งหมายของคุณชัดเจน: ทุกเวอร์ชันระหว่าง rollout ต้องทำงานได้กับทั้งสคีมาเก่าและสคีมาแบบขยาย\n\nแนวทางทั่วไปคือ dual-write หากคุณเพิ่มคอลัมน์ใหม่ แอปเวอร์ชันใหม่เขียนทั้งคอลัมน์เก่าและคอลัมน์ใหม่ เวอร์ชันเก่ายังเขียนเฉพาะของเก่า ซึ่งยังใช้ได้เพราะของเก่ายังอยู่ ให้คอลัมน์ใหม่เป็น optional ก่อน และเลื่อนการบังคับข้อจำกัดจนกว่าผู้เขียนทั้งหมดจะอัพเกรด\n\nการอ่านมักจะเปลี่ยนอย่างระมัดระวังกว่าเขียน ช่วงหนึ่งให้การอ่านยังอยู่ที่คอลัมน์เก่า (ซึ่งคุณมั่นใจว่าเติมเต็มแล้ว) หลังจาก backfill และยืนยันแล้ว ให้เปลี่ยนการอ่านไปใช้คอลัมน์ใหม่โดยมี fallback กลับไปคอลัมน์เก่าถ้าของใหม่ยังหาย\n\nรักษารูปแบบผลลัพธ์ API ให้คงที่ในขณะที่ฐานข้อมูลเปลี่ยนอยู่ภายใน แม้คุณจะเพิ่มฟิลด์ภายในใหม่ พยายามหลีกเลี่ยงการเปลี่ยนรูปแบบการตอบกลับจนกว่าผู้บริโภคทั้งหมดจะพร้อม (เว็บ โมบาย อินทิเกรชัน)\n\nการปล่อยที่เป็นมิตรต่อการย้อนกลับมักเป็นแบบนี้:\n\n- Release 1: เพิ่มคอลัมน์ใหม่และปล่อยโค้ดที่อ่านข้อมูลเก่าและเขียนทั้งสองคอลัมน์\n- Release 2: backfill แถวที่มีอยู่ แล้วปล่อยโค้ดที่อ่านคอลัมน์ใหม่เป็นหลักแต่ยัง fallback ได้\n- Release 3: หยุดเขียนคอลัมน์เก่า (แต่ยังเก็บไว้)\n- Release 4: ลบการอ่านเก่า แล้วลบคอลัมน์เก่า\n\nแนวคิดสำคัญคือขั้นที่ไม่สามารถย้อนกลับได้จริง ๆ คือการดรอปโครงสร้างเก่า ดังนั้นจึงเลื่อนขั้นตอนนั้นไปจนท้ายสุด\n\n## Backfill ข้อมูลอย่างปลอดภัย (โดยไม่ทำให้ DB โหลดเกิน)\n\nBackfill เป็นที่ที่การเปลี่ยนสคีมาส่วนใหญ่พัง คุณต้องเติมคอลัมน์ใหม่สำหรับแถวเก่าโดยไม่ทำให้เกิดล็อกยาว ๆ คิวรีช้า หรือการเพิ่มโหลดแบบไม่คาดคิด\n\nการแบ่งเป็นแบตช์มีความสำคัญ ตั้งเป้าขนาดแบตช์ที่เสร็จเร็ว (วินาที ไม่ใช่นาที) หากแต่ละแบตช์เล็ก คุณสามารถหยุด ย่อขนาด และปรับงานได้โดยไม่บล็อกการปล่อย\n\nเพื่อเกาะความคืบหน้า ให้ใช้ cursor ที่เสถียร ใน PostgreSQL มักเป็น primary key ประมวลผลแถวตามลำดับและเก็บ id สุดท้ายที่ทำเสร็จ หรือทำงานเป็นช่วง id วิธีนี้หลีกเลี่ยงการสแกนทั้งตารางเมื่อ job รีสตาร์ท\n\nนี่คือลวดลายง่าย ๆ:\n\nsql\nUPDATE my_table\nSET new_col = ...\nWHERE new_col IS NULL\n AND id > $last_id\nORDER BY id\nLIMIT 1000;\n\n\nทำให้การอัพเดตมีเงื่อนไข (เช่น WHERE new_col IS NULL) เพื่อให้ job เป็น idempotent การรันซ้ำจะกระทบเฉพาะแถวที่ยังต้องการงาน ลดการเขียนซ้ำที่ไม่จำเป็น\n\nวางแผนรับข้อมูลใหม่ที่มาถึงระหว่าง backfill ลำดับปกติคือ:\n\n- อัพเดตโค้ดแอปก่อนเพื่อให้การเขียนใหม่เติมฟิลด์ใหม่ด้วย\n- backfill แถวประวัติทีละแบตช์\n- รัน loop จับ up สั้น ๆ เพื่อเช็กแถวล่าสุดอีกครั้ง\n- ถ้าจำเป็น เพิ่ม guardrail (เช่น trigger หรือ default) เพื่อป้องกันการเกิด NULL ใหม่\n\nการ backfill ที่ดีคือการทำงานที่น่าเบื่อ: สม่ำเสมอ วัดผลได้ และหยุดได้ง่ายถ้าฐานข้อมูลร้อน\n\n## ยืนยันว่ามิกเกรชันเสร็จจริง\n\nช่วงที่เสี่ยงที่สุดไม่ใช่การเพิ่มคอลัมน์ แต่เป็นการตัดสินใจว่าจะพึ่งพามัน\n\nก่อนจะทำ contract ให้พิสูจน์สองเรื่อง: ข้อมูลใหม่ครบถ้วน และระบบผลิตอ่านข้อมูลใหม่อย่างปลอดภัย\n\nเริ่มจากการเช็คความสมบูรณ์ที่เร็วและทำซ้ำได้:\n\n- ยืนยันว่าคอลัมน์ใหม่ไม่มี NULL ที่ไม่คาดคิด\n- เปรียบเทียบจำนวนแถวที่ควรจะถูกเติมกับจำนวนที่ถูกเติมแล้ว\n- ตรวจสอบตัวอย่าง ID สักชุดและเปรียบเทียบค่าเก่า vs ใหม่\n- ทดสอบกรณีขอบเขต (สตริงว่าง ศูนย์ ระเบียนเก่า ๆ มาก)\n- รันการเช็คเดิมซ้ำทีหลังเพื่อตรวจว่าค่าไม่เปลี่ยนเพี้ยน\n\nหากคุณใช้ dual-write ให้เพิ่มการเช็คความสอดคล้องเพื่อจับบั๊กเงียบ ๆ เช่น รันคิวรีทุกชั่วโมงหาค่าแถวที่ old_value <> new_value แล้วแจ้งเตือนถ้าไม่เป็นศูนย์ นี่เป็นวิธีเร็วในการค้นพบว่าผู้เขียนบางตัวยังอัพเดตเฉพาะคอลัมน์เก่า\n\nดูสัญญาณพื้นฐานของ production ขณะที่มิกเกรชันรัน ถ้าเวลา query หรือการรอล็อกพุ่งขึ้น คิวรีการยืนยันของคุณเองอาจเพิ่มโหลดได้ สังเกตอัตราข้อผิดพลาดสำหรับพาธที่อ่านคอลัมน์ใหม่ โดยเฉพาะหลังการ deploy\n\nควรรักษาสองเส้นทางไว้นานแค่ไหน? พอที่จะผ่านอย่างน้อยหนึ่งรอบการปล่อยเต็มและการรัน backfill ซ้ำ หลายทีมใช้ 1–2 สัปดาห์ หรือจนกว่าจะมั่นใจว่าไม่มีเวอร์ชันแอปเก่ารันอยู่\n\n## เฟส Contract: ลบเส้นทางเก่า\n\nContract คือจุดที่ทีมกลัวเพราะมันรู้สึกเหมือนจุดไร้การย้อนกลับ หากทำ expand ถูกต้อง Contract ส่วนใหญ่เป็นงานเก็บกวาด และสามารถทำเป็นขั้นตอนเล็ก ๆ ที่เสี่ยงต่ำได้\n\nเลือกช่วงเวลาที่เหมาะสม อย่าดรอปอะไรทันทีหลัง backfill เสร็จ ให้รออย่างน้อยหนึ่งรอบการปล่อยเต็มเพื่อให้ delayed jobs และ edge cases โชว์ตัว\n\nลำดับ contract ปลอดภัยมักเป็นแบบนี้:\n\n- หยุด dual-write และยืนยันว่าการเขียนใหม่ลงเฉพาะคอลัมน์ใหม่\n- เอาการอ่านเก่าออกในแอปเพื่อให้ fallback หายไป\n- ลบโค้ดทางเลือกที่ตายแล้ว feature flags และงานแบ็กกราวด์ที่อ้างอิงสคีมาเก่า\n- ลบ trigger ชั่วคราว งานซิงค์ หรือมุมมองความเข้ากันได้\n- ลบดัชนีและข้อจำกัดที่ตายแล้ว แล้วดรอปคอลัมน์เก่า\n\nถ้าเป็นไปได้ แยก contract ออกเป็นสอง release: ตัวหนึ่งลบการอ้างอิงโค้ด (พร้อม logging เพิ่ม) และอีกตัวหนึ่งลบวัตถุฐานข้อมูล การแยกแบบนี้ทำให้การย้อนกลับและการแก้ปัญหาง่ายขึ้นมาก\n\nข้อเฉพาะของ PostgreSQL สำคัญที่นี่ การดรอปคอลัมน์ส่วนใหญ่เป็นการเปลี่ยน metadata แต่ก็ต้องใช้ล็อก ACCESS EXCLUSIVE ชั่วคราว วางแผนช่วงเวลาที่ค่อนข้างสงบและทำให้ migration เร็ว หากคุณสร้างดัชนีเพิ่ม ให้ลบด้วย DROP INDEX CONCURRENTLY เพื่อหลีกเลี่ยงการบล็อกการเขียน (คำสั่งนี้ไม่สามารถรันใน transaction block ได้ ดังนั้นเครื่องมือมิกเกรชันของคุณต้องรองรับ)\n\n## ข้อผิดพลาดและกับดักที่พบบ่อย\n\nมิกเกรชันแบบไม่หยุดทำงานล้มเหลวเมื่อฐานข้อมูลกับแอปไม่เห็นด้วยในสิ่งที่อนุญาต รูปแบบนี้ใช้ได้ก็ต่อเมื่อทุกสถานะกลางปลอดภัยสำหรับทั้งโค้ดเก่าและโค้ดใหม่\n\n### กับดักที่ทำให้ production พัง\n\nความผิดพลาดเหล่านี้เกิดบ่อย:\n\n- เพิ่ม NOT NULL เร็วเกินไป ในขณะที่เวอร์ชันเก่ายังเขียนแถวโดยไม่มีฟิลด์ใหม่\n- Backfill ตารางขนาดใหญ่ใน transaction เดียว ซึ่งอาจถือล็อก ทำให้ bloat ตาราง และทำให้เกิด timeout\n- สมมติว่าการตั้ง default ไม่มีผลเสีย ใน PostgreSQL ค่าบางอย่างอาจทำให้เกิด table rewrite\n- สลับการอ่านไปคอลัมน์ใหม่ก่อนที่การเขียนจะเติมข้อมูลอย่างน่าเชื่อถือ\n- ลืมผู้เขียนและผู้อ่านอื่น ๆ (cron jobs, workers, รายงาน)\n\nสถานการณ์สมจริง: คุณเริ่มเขียน full_name จาก API แต่ background job ที่สร้างผู้ใช้ยังตั้งค่าแค่ first_name และ last_name งานรันกลางคืน แทรกแถวที่มี full_name = NULL และโค้ดภายหลังสมมติว่า full_name จะมีค่าตลอดเวลา\n\n### วิธีหลีกเลี่ยงการติดค้างกลางมิกเกรชัน\n\nปฏิบัติต่อแต่ละขั้นเหมือนเป็น release ที่อาจรันเป็นวัน:\n\n- ให้คอลัมน์ใหม่เป็น nullable ในช่วงเปลี่ยนผ่าน และบังคับความต้องการในโค้ดก่อน\n- Backfill ทีละน้อยพร้อมหยุดได้ และเฝ้าดูโหลด DB\n- ทำให้โค้ดทน: อ่านทั้งสองทาง เขียนทั้งสองทางเมื่อจำเป็น จัดการกับค่าที่หาย\n- ตรวจสอบทุกจุดที่แตะตาราง รวมถึง workers และรายงาน\n\n## เช็กลิสต์ด่วนก่อนแต่ละการปล่อย\n\nเช็กลิสต์ที่ทำซ้ำได้ช่วยให้คุณไม่ปล่อยโค้ดที่ทำงานได้แค่กับสภาวะฐานข้อมูลเดียว\n\nก่อน deploy ให้ยืนยันว่าฐานข้อมูลมีชิ้นส่วนที่ขยายแล้ว (คอลัมน์/ตารางใหม่ ดัชนีสร้างในวิธีที่ล็อกน้อย) แล้วยืนยันว่าแอปทนต่อการเปลี่ยน: ควรทำงานได้กับรูปแบบเก่า รูปแบบขยาย และสถานะที่ backfill ครึ่งหนึ่ง\n\nเก็บเช็กลิสต์สั้น ๆ:\n\n- Expansion is present: ออบเจ็กต์สคีมาใหม่มีอยู่และถูกเพิ่มในวิธีที่ล็อกน้อย\n- Compatibility is real: แอปทำงานกับสคีมาเก่าและขยายได้ รวมถึง workers และเส้นทางแอดมิน\n- Backfill is controlled: แบตช์เล็ก หยุดได้ พร้อมเมตริกความคืบหน้าเบื้องต้น\n- Read switch is planned: รู้ชัดเมื่อใดจะย้ายการอ่าน และจะย้อนกลับอย่างไรหากผลผิดพลาด\n- Contract is delayed: รออย่างน้อยหนึ่งหรือสองรอบการปล่อยก่อนลบออบเจ็กต์เก่า\n\nมิกเกรชันถือว่าเสร็จเมื่อการอ่านใช้ข้อมูลใหม่ การเขียนไม่ต้องรักษาข้อมูลเก่าอีกต่อไป และคุณยืนยันการ backfill อย่างน้อยด้วยการเช็คง่าย ๆ (นับหรือสุ่มตัวอย่าง)\n\n## ตัวอย่างสมจริง: แทนคอลัมน์โดยไม่หยุดทำงาน\n\nสมมติว่าคุณมีตาราง PostgreSQL customers ที่มีคอลัมน์ phone เก็บค่าสายโทรที่ไม่เป็นระเบียบ (รูปแบบต่างกัน บางทีก็ว่าง) คุณต้องการแทนด้วย phone_e164 แต่ไม่สามารถบล็อกการปล่อยหรือปิดแอปได้\n\nลำดับ expand/contract ที่สะอาดจะเป็นแบบนี้:\n\n- Expand: เพิ่ม phone_e164 เป็น nullable ไม่มี default และยังไม่ใส่ข้อจำกัดเข้มงวด\n- Compatible deploy: อัพเดตโค้ดให้เขียนทั้ง phone และ phone_e164 แต่ยังอ่านจาก phone เพื่อไม่ให้ผู้ใช้เห็นการเปลี่ยนแปลง\n- Backfill: แปลงแถวที่มีอยู่เป็นแบตช์เล็ก ๆ (เช่น 1,000 แถวต่อครั้ง)\n- Switch reads: ปล่อยโค้ดที่อ่าน phone_e164 ก่อนโดย fallback มาที่ phone ถ้ามันยัง NULL\n- Contract: เมื่อแน่ใจว่าทุกอย่างใช้ phone_e164 แล้ว เอา fallback ออก ดรอป phone แล้วใส่ข้อจำกัดเข้มงวดถ้าจำเป็น\n\nการย้อนกลับยังง่ายเมื่อแต่ละขั้นเข้ากันได้ย้อนหลัง หากการสลับการอ่านมีปัญหา ให้ย้อนกลับแอปและฐานข้อมูลยังมีทั้งสองคอลัมน์ ถ้า backfill ทำให้โหลดสูง ให้หยุดงาน ลดขนาดแบตช์ แล้วทำต่อทีหลัง\n\nถ้าต้องการให้ทีมอยู่ในหน้าเดียวกัน จดแผนในที่เดียว: SQL ที่แน่นอน จะปล่อยไหนสลับการอ่านอย่างไร วัดความเสร็จอย่างไร (เช่น เปอร์เซ็นต์ non-NULL phone_e164) และใครรับผิดชอบแต่ละขั้นตอน\n\n## ขั้นตอนต่อไป: ทำให้เป็นขั้นตอนที่ทำซ้ำได้\n\nExpand/contract ทำงานได้ดีที่สุดเมื่อมันรู้สึกเป็นกิจวัตร เขียน runbook สั้น ๆ ที่ทีมใช้ซ้ำสำหรับการเปลี่ยนสคีมาแต่ละครั้ง ควรมีหน้าเดียวและชัดเจนพอให้คนใหม่ทำตามได้\n\nเทมเพลตปฏิบัติประกอบด้วย:\n\n- Expand (มิกเกรชันที่แน่นอน)\n- การเปลี่ยนโค้ด (สิ่งที่ต้องเข้ากันได้ย้อนหลัง และจุดที่ใช้ dual-read หรือ dual-write)\n- Backfill (ขนาดแบตช์ อัตรา จำกัด ชั่วคราว หยุด/ต่อ)\n- Verify (คิวรีและเมตริกที่พิสูจน์ความถูกต้อง)\n- Contract (จะลบอะไรและเมื่อใด)\n\nกำหนดความรับผิดชอบล่วงหน้า "ทุกคนคิดว่าอีกคนจะทำ contract" คือสาเหตุที่คอลัมน์เก่าและ feature flags อยู่ยาวเป็นเดือน\n\nแม้ backfill จะรันออนไลน์ ควรจัดตารางในช่วงที่ทราฟฟิกน้อย จะง่ายกว่าที่จะเก็บแบตช์เล็ก ดูโหลด DB และหยุดได้อย่างรวดเร็วถ้า latency เพิ่ม\n\nถ้าคุณสร้างและ deploy ด้วย Koder.ai (koder.ai), Planning Mode อาจเป็นวิธีที่มีประโยชน์ในการวางแผนเฟสและจุดตรวจก่อนแตะ production กฎความเข้ากันได้ยังคงใช้ แต่การเขียนขั้นตอนลงไปทำให้ยากที่จะข้ามขั้นตอนน่าเบื่อที่ป้องกันการหยุดทำงานเพราะฐานข้อมูลถูกใช้งานร่วมกันโดยทุกเวอร์ชันของแอปที่กำลังรันอยู่ ระหว่างการปล่อยแบบ rolling deploys และงานแบ็กกราวด์ จะมีโค้ดเวอร์ชันเก่าและใหม่ทำงานพร้อมกัน การมิกเกรชันที่เปลี่ยนชื่อ คอลัมน์ที่ถูกลบ หรือการเพิ่มข้อจำกัด อาจทำให้เวอร์ชันใดเวอร์ชันหนึ่งที่ไม่ได้ถูกเขียนให้รองรับสภาวะสคีมาใหม่เกิดข้อผิดพลาดได้
หมายความว่าคุณออกแบบมิกเกรชันให้ทุกสถานะกลางของฐานข้อมูลใช้งานร่วมกับโค้ดเก่าและโค้ดใหม่ได้ คุณเพิ่มโครงสร้างใหม่ก่อน รันทั้งสองเส้นทางไปสักพัก แล้วค่อยลบโครงสร้างเก่าเมื่อมั่นใจว่าไม่มีอะไรอาศัยมันอยู่แล้ว
Expand คือการเพิ่มคอลัมน์ ตาราง หรือดัชนีใหม่โดยไม่ลบสิ่งที่แอปปัจจุบันต้องการ ส่วน Contract คือขั้นตอนทำความสะอาดที่ลบคอลัมน์เก่า การอ่าน/เขียนเก่า และตรรกะซิงค์ชั่วคราวหลังจากยืนยันว่าเส้นทางใหม่ทำงานเต็มที่แล้ว
การเพิ่มคอลัมน์แบบ Nullable และไม่มีค่า Default มักเป็นจุดเริ่มต้นที่ปลอดภัย เพราะหลีกเลี่ยงล็อกหนัก ๆ และยังทำให้โค้ดเก่าทำงานได้ จากนั้น deploy โค้ดที่ทนต่อการไม่มีคอลัมน์หรือค่า NULL แล้วค่อย backfill ทีละน้อย และค่อยบังคับข้อจำกัดเช่น NOT NULL ทีหลัง
ใช้เมื่อช่วงเปลี่ยนผ่านที่เวอร์ชันใหม่เขียนทั้งฟิลด์เก่าและฟิลด์ใหม่พร้อมกัน วิธีนี้ช่วยให้ข้อมูลสอดคล้องขณะที่ยังมีอินสแตนซ์หรืองานที่ยังเขียนเฉพาะฟิลด์เก่าอยู่
ทำเป็นชุดเล็ก ๆ ที่เสร็จเร็ว และทำให้แต่ละชุดเป็น idempotent เพื่อให้การรันซ้ำจะอัพเดตเฉพาะแถวที่ยังต้องการเท่านั้น คอยดูเวลา query, การรอล็อก และ replication lag พร้อมหยุดหรือย่อขนาดชุดถ้าฐานข้อมูลเริ่มร้อน
เช็คความสมบูรณ์ เช่น จำนวนแถวที่ยังเป็น NULL ในคอลัมน์ใหม่ เปรียบเทียบค่าเก่ากับค่าใหม่จากตัวอย่าง หรือรันการตรวจสอบความสอดคล้องอย่างต่อเนื่อง หากมี dual-write ให้รันคิวรีตรวจหาความไม่ตรงกันแล้วแจ้งเตือนเมื่อไม่เป็นศูนย์ และสังเกตข้อผิดพลาดหลังการ deploy เพื่อจับจุดที่ยังอ่านสคีมาเก่า
การตั้ง NOT NULL เร็วเกินไป, backfill ตารางใหญ่ในธุรกรรมเดียว, สมมติว่าการตั้ง Default ไม่มีค่าใช้จ่ายใน PostgreSQL (บางครั้งจะทำให้ table rewrite), การสลับการอ่านก่อนที่การเขียนจะเติมข้อมูลอย่างน่าเชื่อถือ และการลืมผู้เขียน/ผู้อ่านอื่น ๆ (cron jobs, workers, exports, รายงาน) เป็นตัวอย่างที่พบบ่อย
หลังจากหยุดเขียนฟิลด์เก่าและย้ายการอ่านไปที่ฟิลด์ใหม่โดยไม่พึ่ง fallback แล้วรอให้มั่นใจว่าไม่มีเวอร์ชันแอปเก่ายังรันอยู่หรือมีงานที่ยังอ้างอิงสคีมาเก่า หลายทีมแยกเป็น release แยกต่างหากเพื่อให้การ rollback ง่ายขึ้น
ถ้าคุณทนได้กับหน้าต่างบำรุงรักษาและทราฟฟิกน้อย การมิกเกรชันแบบครั้งเดียวอาจพอใช้ได้ แต่ถ้ามีผู้ใช้จริง หลายอินสแตนซ์ แอปเวิร์กเกอร์ หรือต้องรักษา SLA รูปแบบ expand/contract มักคุ้มค่าที่จะลงแรงเพิ่มเพราะช่วยให้การปล่อยและการย้อนกลับปลอดภัยขึ้น; ใน Koder.ai Planning Mode การเขียนขั้นตอนและการตรวจสอบล่วงหน้าช่วยลดการข้ามขั้นตอนสำคัญที่มักทำให้เกิดการหยุดทำงาน