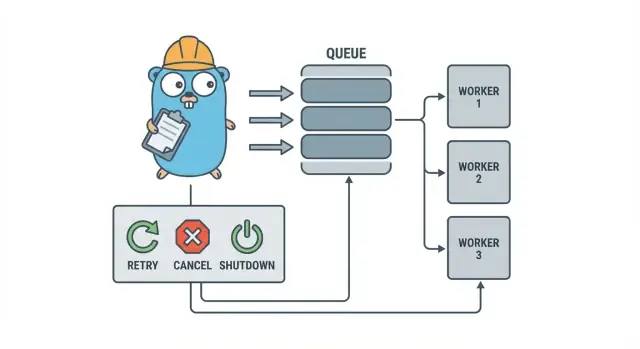
ทำไมงานพื้นหลังถึงวุ่นวายได้เร็ว\n\nในบริการ Go ขนาดเล็ก งานพื้นหลังมักเริ่มจากเป้าหมายง่าย ๆ: คืน HTTP response ให้เร็ว แล้วค่อยทำงานช้า ๆ ข้างหลัง นั่นอาจเป็นการส่งอีเมล ย่อรูป ซิงก์ไปยัง API ภายนอก สร้างดัชนีค้นหาใหม่ หรือรันรายงานตอนกลางคืน\n\nปัญหาคือ งานเหล่านี้เป็นงานจริงใน production เพียงแต่ขาดราวกันตกที่คุณจะได้จากการจัดการ request โดยตรง การปล่อย goroutine จาก HTTP handler ดูเหมือนจะโอเคจนกว่าจะมีการ deploy ท่ามกลางงานกำลังทำ อยู่ ๆ upstream API ช้าลง หรือคำขอเดียวถูกรีไทรและทำให้งานรันสองครั้ง\n\nปัญหาแรกที่คาดเดาได้คือ:\n\n- : การเรียกครั้งเดียวค้าง ทำให้ workers หยุดความคืบหน้า\n- : การรีไทรในชั้น HTTP ทำให้งานเดียวกันรันซ้ำ\n- : process ปิดไปแล้วงานหายหรือทำไม่เสร็จ\n- : error ถูกล็อกเพียงครั้งเดียว (หรือไม่ถูกล็อกเลย) แล้วหายไป\n- : งานที่ล้มเหลวลองใหม่ทันทีและทำให้ dependency โหลดเกิน\n\nนี่คือที่มาของ pattern เล็ก ๆ ชัดเจนอย่าง Go worker pool: มันทำให้การทำงานแบบขนานเป็นการตัดสินใจที่ควบคุมได้ (N workers), เปลี่ยน “ทำทีหลัง” ให้เป็นชนิดงานที่ชัดเจน และให้จุดเดียวในการจัดการ retries, timeouts, และการยกเลิก\n\nตัวอย่าง: แอป SaaS ต้องส่งใบแจ้งหนี้ คุณไม่อยากให้มีการส่งพร้อมกัน 500 ครั้งหลังการนำเข้าชุดเดียว และคุณก็ไม่อยากส่งซ้ำเพราะ request ถูกรีไทร Worker pool ช่วยจำกัด throughput และถือว่า “ส่ง invoice #123” เป็นหน่วยงานที่ติดตามได้\n\nWorker pool ไม่ใช่เครื่องมือที่เหมาะเมื่อคุณต้องการการรับประกันแบบทนทานข้าม process หากงานต้องรอดจากการล่ม ต้องถูกตั้งเวลาในอนาคต หรือถูกประมวลผลโดยหลายบริการ คุณน่าจะต้องการคิวจริง ๆ พร้อม storage คงทนสำหรับสถานะงาน\n\n## แบบจำลอง worker pool อธิบายแบบง่าย\n\nGo worker pool ตั้งใจให้ธรรมดา: ใส่งานลงคิว ให้ชุด worker ที่กำหนดจำนวนดึงงานออกมา แล้วมั่นใจว่าทั้งระบบสามารถหยุดอย่างสะอาดได้\n\nคำนิยามพื้นฐาน:\n\n- : หน่วยงานหนึ่งงาน เช่น “ย่อรูปนี้” หรือ “ส่งอีเมลใบแจ้งหนี้นี้”\n- : ที่ที่งานรอ\n- : goroutine ที่วนดึงงานแล้วประมวลผล\n- : ส่วนที่รับงานและป้อนเข้าไปในคิว\n\nในการออกแบบแบบ in-process หลายครั้ง ของ Go คือคิว ช่องแบบมี buffer สามารถเก็บงานจำนวนจำกัดก่อนที่ผู้ผลิตจะบล็อก การบล็อกนั้นคือ backpressure ซึ่งมักหยุดไม่ให้บริการรับงานไม่จำกัดจนหน่วยความจำหมดเมื่อทราฟฟิกพุ่ง\n\nขนาด buffer เปลี่ยนอาการของระบบได้ Buffer เล็กทำให้เห็นแรงกดเร็ว (caller ต้องรอนานขึ้น) Buffer ใหญ่ช่วยปรับให้รับช่วงสั้น ๆ ได้ แต่ซ่อนการโอเวอร์โหลดไว้จนกว่าจะสายไปแล้ว ไม่มีตัวเลขที่สมบูรณ์แบบ มีแต่น้อยที่เหมาะกับระดับการรอที่คุณยอมรับได้\n\nคุณยังเลือกได้ด้วยว่า pool จะคงที่หรือปรับขนาดได้ Pool คงที่เข้าใจง่ายและทำให้การใช้ทรัพยากรคาดเดาได้ Auto-scaling ช่วยงานโหลดไม่สม่ำเสมอได้ แต่เพิ่มการตัดสินใจที่ต้องดูแล (เมื่อไรจะ scale เพิ่ม ลดเท่าไร และเมื่อไรจะ scale กลับ)\n\nสุดท้าย “ack” ใน pool แบบ in-process มักหมายถึง “worker ทำงานเสร็จและคืนค่า error เป็น nil” ไม่มี broker ภายนอกยืนยันการส่ง ดังนั้นโค้ดของคุณจะเป็นคนกำหนดว่า “เสร็จ” คืออะไรและจะทำอย่างไรเมื่องานล้มเหลวหรือถูกยกเลิก\n\n## เป้าหมายการออกแบบ: การลองใหม่ การยกเลิก และการปิดอย่างสะอาด\n\nWorker pool กลไกเรียบง่าย: รันจำนวน worker ที่กำหนด ป้อนงานเข้าไป แล้วประมวลผล มูลค่าของมันคือการควบคุม: ความขนานที่คาดเดาได้ การจัดการความล้มเหลวที่ชัดเจน และเส้นทางการปิดที่จะไม่ทิ้งงานครึ่งหนึ่ง\n\nสามเป้าหมายที่ทำให้ทีมเล็กอยู่รอด:\n\n- เพื่อไม่ให้การพุ่งของโหลดทำให้ฐานข้อมูลหรือ API ภายนอกพัง\n- (หรืออย่างน้อยรู้ชัดว่าถูกทิ้งเพราะอะไร)\n- : ทุกงานควรติดตามได้ผ่าน logs และตัวนับพื้นฐานไม่กี่ตัว\n\nความล้มเหลวส่วนใหญ่ไม่น่าตื่นเต้น แต่คุณยังอยากแยกแยะพวกมัน:\n\n- (เน็ตเวิร์กกระตุก, rate limit) ที่ควรลองใหม่\n- (ข้อมูลเข้าไม่ถูกต้อง, รายการหาย) ที่ไม่ควรลองใหม่\n- (dependency ค้าง) ที่ต้องตัดออกเพื่อไม่ให้ workers อุดตัน\n\nการยกเลิกไม่ใช่แค่ “error” มันคือการตัดสินใจ: ผู้ใช้ยกเลิก, deploy มาแทนที่ process, หรือบริการกำลังจะปิด ใน Go ให้ถือการยกเลิกเป็นสัญญาณระดับหนึ่งโดยใช้ context cancellation และให้แต่ละงานเช็คมันก่อนเริ่มงานหนัก ๆ และในจุดที่ปลอดภัยระหว่างการทำงาน\n\nการปิดอย่างสะอาดคือจุดที่หลาย ๆ pool พัง ตัดสินใจตั้งแต่ต้นว่า “ปลอดภัย” สำหรับงานของคุณหมายถึงอะไร: ทำงานที่กำลังทำให้เสร็จหรือหยุดทันทีแล้วรันใหม่ทีหลัง? กระบวนการที่ปฏิบัติได้คือ:\n\n- หยุดรับงานใหม่\n- บอก workers ให้หยุดหลังงานปัจจุบัน (หรือหยุดทันที)\n- รอจนถึงเส้นตาย แล้วบังคับออก\n\nถ้าคุณกำหนดกฎพวกนี้ตั้งแต่แรก การลองใหม่ การยกเลิก และการปิดจะเล็กและคาดเดาได้ แทนที่จะกลายเป็น framework ที่ทำเองขึ้นมาเอง\n\n## ทีละขั้น: สร้าง worker pool พื้นฐาน\n\nWorker pool คือกลุ่ม goroutine ที่ดึงงานจาก channel แล้วทำงาน สิ่งสำคัญคือต้องทำให้พื้นฐานคาดเดาได้: งานหน้าตาอย่างไร, workers หยุดอย่างไร, และจะรู้ได้อย่างไรว่างานทั้งหมดเสร็จแล้ว\n\nเริ่มด้วยชนิด ง่าย ๆ ให้มันมี ID (สำหรับล็อก), payload (สิ่งที่จะประมวลผล), ตัวนับความพยายาม (useful สำหรับ retries), ตราประทับเวลา, และที่เก็บ context per-job\n\n\n\nมีการตัดสินใจเชิงปฏิบัติที่คุณจะต้องทำตั้งแต่ต้น:\n\n- เลือกขนาดคิวตามระดับการรอที่คุณทนได้\n- ตัดสินใจว่า backpressure สำหรับ caller หมายถึงอะไร: บล็อก, คืน error, หรือทิ้งงาน\n- แยก และ ให้ชัด เพื่อให้คุณหยุดรับงานก่อน แล้วค่อยรอให้งานที่อยู่ระหว่างทำเสร็จ\n\n## เพิ่ม retries โดยไม่ทำให้เป็น framework\n\nRetries มีประโยชน์ แต่ก็มักทำให้ worker pool ยุ่ง Keep เป้าหมายให้แคบ: ลองใหม่เฉพาะเมื่อการลองใหม่มีโอกาสสำเร็จจริง ๆ และหยุดเมื่อมันไม่มีทาง\n\nเริ่มด้วยการตัดสินใจว่าอะไร retryable ข้อผิดพลาดชั่วคราว (เน็ตเวิร์ก, timeouts, ตอบกลับว่า "ลองใหม่ทีหลัง") มักคุ้มค่าที่จะลองใหม่ ข้อผิดพลาดถาวร (ข้อมูลเข้าไม่ถูกต้อง, รายการหาย, ไม่มีสิทธิ์) ไม่ควรถูกลองใหม่\n\nนโยบาย retry เล็ก ๆ มักพอแล้ว:\n\n- ทำเครื่องหมายข้อผิดพลาดว่า retryable หรือไม่ (เช่น ห่อด้วย helper)\n- ตั้ง max attempts (บ่อย ๆ คือ 3–5) เกินกว่านั้นมักเสียเวลา\n- ใช้ exponential backoff พร้อม jitter เพื่อไม่ให้งานลองใหม่พร้อมกัน\n- จำกัดความช้า (เช่น อย่านอนเกิน 30 วินาที)\n- บันทึกการลองใหม่พร้อมหมายเลข attempt, การหน่วงครั้งถัดไป, และ job ID\n\nรูปทรงของ backoff ไม่จำเป็นต้องซับซ้อน รูปแบบทั่วไปคือ: แล้วเพิ่ม jitter (สุ่ม +/- 20%) Jitter สำคัญเพราะถ้าไม่อย่างนั้นหลาย worker จะล้มพร้อมกันแล้วลองใหม่พร้อมกัน\n\nความหน่วงควรอยู่ที่ไหน? สำหรับระบบเล็ก ๆ การ sleep ภายใน worker ก็พอใช้ได้ แต่จะผูก slot ของ worker ไว้ หาก retries หายาก นั่นยอมรับได้ หาก retries พบมากหรือความหน่วงยาว คิดเรื่องการ re-enqueue งานพร้อม timestamp ให้รันภายหลังเพื่อให้ workers ยุ่งกับงานอื่น\n\nเมื่อสุดท้ายล้มเหลว จงชัดเจน เก็บงานที่ล้มเหลว (และ error ล่าสุด) เพื่อให้รีวิว บันทึกบริบทพอที่จะ replay หรือนำไปไว้ใน dead list ที่ตรวจเป็นประจำ หลีกเลี่ยงการทิ้งแบบเงียบ Pool ที่ซ่อนความล้มเหลวเลวร้ายกว่าการไม่มี retries เลย\n\n## การยกเลิกและ timeout ที่หยุดงานได้จริง\n\nWorker pool จะปลอดภัยเมื่อคุณหยุดได้จริง กฎง่าย ๆ คือ: ส่ง ผ่านทุกชั้นที่อาจบล็อก นั่นรวม submission, execution, และ cleanup\n\nการตั้งค่าปฏิบัติใช้สองขีดจำกัดเวลาหลัก:\n\n- เพื่อไม่ให้ task เดียวกิน worker ตลอดไป\n- เพื่อให้ process ออกได้แม้งานบางงานไม่ยอมให้ความร่วมมือ\n\n### ใช้ context ให้ครอบคลุม\n\nให้แต่ละงานมี context ของตัวเองที่สืบทอดมาจาก context ของ worker แล้วทุกการเรียกที่ช้า (DB, HTTP, คิว, I/O ไฟล์) ต้องใช้ context นั้นเพื่อให้กลับได้ก่อนเวลา\n\n\n\nถ้า เรียก DB หรือ API ให้ส่ง context เข้าไปในการเรียกเหล่านั้น (เช่น , , หรือเมธอด client ที่รับ context) ถ้าคุณละเลยที่ไหนสักแห่ง การยกเลิกจะเป็น "best effort" และมักล้มเหลวเมื่อคุณต้องการมันที่สุด\n\n### งานที่ทำได้บางส่วนและขั้นตอนที่ "ปลอดภัยสำหรับการลองใหม่"\n\nการยกเลิกอาจเกิดขึ้นกลางคัน จงถือว่าการทำงานบางส่วนเป็นเรื่องปกติ พยายามทำให้ขั้นตอนเป็น idempotent เพื่อ rerun แล้วไม่เกิดผลข้างเคียงซ้ำ ๆ แนวทางทั่วไปคือใช้คีย์เฉพาะสำหรับ insert (หรือ upsert), เขียนตัวบอกความคืบหน้า (started/done), เก็บผลลัพธ์ก่อนทำต่อ, และเช็ค ระหว่างขั้นตอน\n\nถือการปิดเป็นเส้นตาย: หยุดรับงานใหม่ ยกเลิก contexts ของ worker และรอเพียงจนถึง timeout การปิดสำหรับงานที่อยู่ระหว่างทำให้สิ้นสุด\n\n## การปิดอย่างสะอาด: ควรทำอะไรเมื่อ process ต้องออก\n\nการปิดอย่างสะอาดมีหน้าที่หนึ่ง: หยุดรับงานใหม่, บอกงานที่กำลังทำให้หยุด, และออกโดยไม่ทิ้งระบบในสถานะประหลาด\n\nเริ่มจากสัญญาณ ในการดีพลอยส่วนใหญ่คุณจะเห็น SIGINT ท้องถิ่นและ SIGTERM จาก process manager หรือ container runtime ใช้ shutdown context ที่ยกเลิกเมื่อสัญญาณมาถึง แล้วส่งเข้า pool และ job handlers\n\nถัดไป หยุดรับงานใหม่ อย่าให้ callers บล็อกตลอดไปพยายาม submit เข้า channel ที่ไม่มีใครอ่านอีก เก็บการ submit ไว้หลังฟังก์ชันเดียวที่เช็ค closed flag หรือ select บน shutdown context ก่อนส่ง\n\nแล้วตัดสินใจว่าจะทำอะไรกับงานที่อยู่ในคิว:\n\n- : ทำงานที่อยู่ในคิวให้เสร็จ แต่ปฏิเสธการส่งใหม่\n- : ทิ้งงานที่ยังไม่ถูกเริ่ม\n\nการ drain ปลอดภัยกว่าสำหรับเรื่องเช่นการชำระเงินและอีเมล การ drop ใช้ได้กับงาน "nice to have" เช่นการคำนวณแคชใหม่\n\nลำดับการปิดปฏิบัติได้จริง:\n\n- ดัก SIGINT/SIGTERM และยกเลิก shared context\n- หยุดการ submit (close submit path, ไม่จำเป็นต้องปิด work channel ทันที)\n- ให้ workers ทำงานให้เสร็จหรือยกเลิกตาม context\n- รอ workers ด้วย WaitGroup\n- บังคับเส้นตายแล้วออก\n\nเส้นตายสำคัญ เช่น ให้เวลา in-flight jobs 10 วินาทีเพื่อหยุด หลังจากนั้นบันทึกว่ายังมีงานไหนกำลังรันอยู่แล้วออก นั่นทำให้การ deploy คาดเดาได้และหลีกเลี่ยง process ติดค้าง\n\n## การล็อกและเมตริกง่าย ๆ สำหรับ worker pool\n\nเมื่อ worker pool พัง มันไม่ค่อยล้มแบบดัง Jobs จะช้าลง retries กอง และมีคนบอกว่า "ไม่มีอะไรเกิดขึ้น" Logging และตัวนับพื้นฐานไม่กี่ตัวช่วยให้เรื่องชัดเจน\n\nให้ทุกงานมี ID คงที่ (หรือสร้างตอน submit) และใส่มันในทุกบรรทัดล็อก รักษา logs ให้สม่ำเสมอ: หนึ่งบรรทัดตอนงานเริ่ม, หนึ่งตอนงานจบ, หนึ่งตอนงานล้ม ถ้าคุณลองใหม่ ให้ล็อกหมายเลข attempt และการหน่วงครั้งถัดไป\n\nรูปแบบล็อกง่าย ๆ:\n\n- start: job_id, worker_id, attempt, kind\n- finish: job_id, worker_id, attempt, duration_ms\n- fail/retry: job_id, worker_id, attempt, err, next_delay_ms\n\nเมตริกสามารถเรียบง่ายแล้วให้ผลดี ติดตามความยาวคิว, งานที่กำลังรัน, จำนวนสำเร็จและล้มเหลวรวม, และ latency ของงาน (อย่างน้อยค่าเฉลี่ยและค่าสูงสุด) หากความยาวคิวเพิ่มขึ้นเรื่อย ๆ และงานที่รันเต็มที่ที่จำนวน worker คุณอิ่มตัว หาก submitters บล็อกในการส่งเข้า jobs channel แปลว่า backpressure ถึง caller — ไม่ใช่เรื่องไม่ดีเสมอไป แต่ควรเป็นผลโดยตั้งใจ\n\nเมื่อ "งานติด" ให้เช็คว่ากระบวนการยังรับงานอยู่ไหม ความยาวคิวเพิ่มไหม workers ยังทำงานอยู่ไหม และงานไหนรันนานสุด ๆ runtime ยาวมักชี้ไปที่ missing timeouts, dependency ช้า, หรือ loop การลองใหม่ที่ไม่มีที่สิ้นสุด\n\n## ตัวอย่างที่สมจริง: คิวพื้นหลังสำหรับ SaaS เล็ก ๆ\n\nนึกภาพ SaaS เล็ก ๆ ที่ออร์เดอร์เปลี่ยนเป็น PAID ทันทีหลังการชำระ คุณต้องส่ง PDF ใบแจ้งหนี้ อีเมลหาลูกค้า และแจ้งทีมภายใน คุณไม่อยากให้สิ่งนี้บล็อกเว็บ request นี่คือกรณีที่เหมาะกับ worker pool เพราะงานเป็นเรื่องจริง แต่ระบบยังเล็ก\n\npayload ของงานอาจน้อย: พอที่จะดึงข้อมูลที่เหลือจากฐานข้อมูลได้ handler ของ API เขียนแถวอย่าง ใน transaction เดียวกับการอัปเดตออร์เดอร์ แล้ววงลูปพื้นหลัง polling หา queued jobs และป้อนเข้า worker channel\n\n\n\nเมื่อ worker หยิบมันขึ้นมา เส้นทางที่สมบูรณ์แบบคือ: โหลดออร์เดอร์ สร้าง invoice เรียก email provider แล้วมาร์กงานว่าเสร็จ\n\nRetries คือจุดที่เรื่องจริงจัง ถ้า provider อีเมลมีปัญหาชั่วคราว คุณไม่ต้องการให้ 1,000 งานล้มเหลวตลอดไปหรือโจมตี provider ทุกวินาที แนวทางปฏิบัติได้แก่:\n\n- ถือว่า network errors และ 5xx เป็น retryable\n- ใช้ exponential backoff พร้อม max delay (เช่น 5s, 15s, 45s, 2m)\n- จำกัด attempts (เช่น 10) แล้วมาร์กงานว่า failed\n- บันทึก error ล่าสุดเพื่อให้ทีมซัพพอร์ตดูได้\n\nระหว่างการขัดข้อง งานจะย้ายจาก queued ไป in_progress แล้วกลับไป queued พร้อมเวลารันในอนาคต พอ provider คืนกลับมา workers จะไล่ลด backlog ได้ตามธรรมชาติ\n\nลองนึกถึง deploy คุณส่ง SIGTERM กระบวนการควรหยุดรับงานใหม่แต่ทำงานที่กำลังทำให้เสร็จ หยุด polling หยุดป้อนช่อง worker และรอ workers ด้วยเส้นตาย งานที่เสร็จจะถูกมาร์กว่า done งานที่ยังรันเมื่อเส้นตายมาถึงควรถูกมาร์กกลับเป็น queued (หรือทิ้งไว้ใน progress พร้อม watchdog) เพื่อให้ถูกหยิบขึ้นโดยเวอร์ชันใหม่\n\n## ข้อผิดพลาดและกับดักที่พบบ่อย\n\nบั๊กส่วนใหญ่ในการประมวลผลงานพื้นหลังไม่ใช่ใน logic ของงาน แต่เป็นการประสานงานที่แสดงเฉพาะเมื่อโหลดสูงหรือตอน shutdown\n\nกับดักคลาสสิกคือการปิด channel จากมากกว่าที่เดียว ผลลัพธ์คือ panic ที่ยากจะทำซ้ำ ให้เจ้าของหนึ่งคนสำหรับแต่ละ channel (มักเป็นผู้ผลิต) และให้ที่เดียวนั้นเรียก \n\nRetries เป็นอีกพื้นที่ที่ความตั้งใจดีทำให้เกิด outage หากคุณลองใหม่ทุกอย่าง คุณจะลองใหม่กับความล้มเหลวถาวรด้วย สิ้นเปลืองเวลา เพิ่มโหลด และอาจกลายเป็น incident จำแนก error และจำกัด retries ด้วยนโยบายชัดเจน\n\nการซ้ำจะเกิดขึ้นแม้การออกแบบรอบคอบ Workers อาจ crash กลางงาน timeout อาจเกิดหลังงานเสร็จ หรือคุณอาจ requeue ตอน deploy ถ้างานไม่ idempotent การซ้ำจะทำให้ผลข้างเคียงซ้ำ: สองใบแจ้งหนี้ สองอีเมลต้อนรับ สองการคืนเงิน\n\nข้อผิดพลาดที่พบบ่อยที่สุด:\n\n- ปิด channel เดียวกันจากหลาย goroutine\n- ลองใหม่กับความล้มเหลวถาวรแทนที่จะยกขึ้นมาให้เห็น\n- ไม่มี idempotency key ทำให้ duplicates สร้างผลร้าย\n- คิวในหน่วยความจำไม่จำกัดที่เติบโตจนหน่วยความจำพุ่ง\n- มองข้าม ทำให้งานยังคงทำต่อแม้เริ่ม shutdown แล้ว\n\nคิวไม่จำกัดในหน่วยความจำเจ๋งมากในการซ่อนปัญหา ช่วงพุ่งของงานอาจกองใน RAM เงียบ ๆ เลือก channel แบบ bounded และตัดสินใจว่าจะทำอะไรเมื่อมันเต็ม: บล็อก, ทิ้ง, หรือคืน error\n\n## รายการตรวจสอบด่วนก่อนนำขึ้น production\n\nก่อนส่ง worker pool เข้าผลิต คุณควรอธิบายวงจรชีวิตงานด้วยวาจาได้ ถ้ามีคนถามว่า “งานนี้อยู่ตรงไหนตอนนี้?” คำตอบไม่ควรเดา\n\nรายการตรวจสอบก่อนขึ้นจริงเชิงปฏิบัติ:\n\n- คุณสามารถตั้งชื่อแต่ละสถานะและการเปลี่ยน: queued, picked up, running, finished, failed (และอะไรที่ย้ายระหว่างสถานะเหล่านั้น)\n- ความขนานเป็นปุ่มเดียว (เช่น ) และการเปลี่ยนไม่ต้องเขียนโค้ดใหม่\n- Retries ถูกจำกัด: max attempts ชัดเจน, backoff โตขึ้น, และความล้มเหลรถาวรไหลไปที่ที่ตั้งใจไว้\n- พฤติกรรมการปิดผ่านการทดสอบ: หยุดรับ, ให้ in-flight งานเสร็จ, และยังมี hard timeout\n- logs ตอบคำถามพื้นฐาน: job ID, หมายเลข attempt, เวลาใช้, และเหตุผลของ error\n\nทำการซ้อมจริงก่อนปล่อย: ใส่ 100 งาน "ส่งอีเมลใบเสร็จ", บังคับให้ 20 งานล้ม แล้ว restart service ระหว่างรัน คุณควรเห็น retries ทำงานตามคาด ไม่มีผลข้างเคียงซ้ำ และการยกเลิกหยุดงานจริงตอนเส้นตายมาถึง\n\nถ้าข้อใดคลุมเครือ ให้ปรับให้แน่นตอนนี้ การแก้ไขเล็กน้อยตรงนี้ประหยัดวันต่อมา\n\n## ขั้นตอนถัดไป: เมื่อใดควรเพิ่มโครงสร้างพื้นฐานมากขึ้น (และเมื่อใดไม่ควร)\n\nin-process pool แบบเรียบง่ายเพียงพอเมื่อผลิตภัณฑ์ยังเล็ก หากงานเป็น "nice to have" (ส่งอีเมล, รีเฟรชแคช, สร้างรายงาน) และคุณสามารถรันใหม่ได้ worker pool ทำให้ระบบเข้าใจง่าย\n\n### สัญญาณว่าคุณโตเกิน pool ใน process\n\nสังเกตจุดกดดันเหล่านี้:\n\n- คุณรันหลาย instance ของแอปและต้องการให้หนึ่งในนั้นเท่านั้นหยิบงาน\n- คุณต้องการ durability (งานต้องรอดจาก crash และ deploy)\n- คุณต้องการ audit trail: ใครใส่ งานอะไร เมื่อไหร่ และผลลัพธ์เป็นอย่างไร\n- คุณต้องการควบคุม backpressure ข้ามบริการ ไม่ใช่แค่ใน process เดียว\n- คุณต้องการการตั้งเวลาหรือดีเลย์ยาว (ชั่วโมงหรือวัน) พร้อม wake-up ที่เชื่อถือได้\n\nถ้าไม่มีข้อเหล่านี้ เครื่องมือที่หนักกว่าอาจเพิ่มความซับซ้อนมากกว่าค่า\n\n### ย้ายทีละน้อยโดยไม่เขียนใหม่ทั้งระบบ\n\nเกราะป้องกันที่ดีที่สุดคือ interface งานที่นิ่ง: payload เล็ก ๆ, ID, และ handler ที่คืนผลลัพธ์ชัดเจน แล้วคุณสามารถสลับ backend ของคิวทีหลังได้ (จาก in-memory channel เป็นตารางฐานข้อมูล แล้วค่อยเป็นคิวเฉพาะ) โดยไม่ต้องเปลี่ยนโค้ดธุรกิจ\n\nก้าวกลาง ๆ ที่ปฏิบัติได้จริงคือบริการ Go เล็ก ๆ ที่อ่านงานจาก PostgreSQL, ครอบงานด้วย lock, และอัปเดตสถานะ คุณได้ durability และ audit พื้นฐานในขณะที่เก็บ logic worker เดิมไว้\n\nถ้าต้องการ prototype เร็ว ๆ Koder.ai (koder.ai) สามารถสร้าง starter Go + PostgreSQL จาก prompt แชท รวมถึงตารางงานพื้นหลังและ loop worker และ snapshot กับ rollback ของมันช่วยขณะที่คุณปรับ retries และพฤติกรรมการปิด\n