Vad det här inlägget tar upp (och varför det spelar roll)
Snowflake populariserade en enkel men långtgående idé inom molndatalagring: håll datalagring och fråga‑compute separerade. Den uppdelningen påverkar två vardagliga problem för datateam — hur warehouses skalas och hur du betalar för dem.
Istället för att se warehouset som en fast "låda" (där fler användare, mer data eller mer komplexa frågor alla slåss om samma resurser) låter Snowflakes modell dig lagra data en gång och starta upp rätt mängd compute när du behöver det. Resultatet blir ofta snabbare svarstider, färre flaskhalsar under toppar och tydligare kontroll över vad som kostar (och när).
Tema #1: prestanda och skalning utan de vanliga avvägningarna
Det här inlägget förklarar på vanligt språk vad det verkligen betyder att separera lagring och compute — och hur det påverkar:
- Konkurrens (många som kör frågor samtidigt)
- Elastisk skalning (att skala compute upp och ner)
- Kostnadsbeteende (betala för compute endast medan det körs, plus löpande lagring)
Vi pekar också ut var modellen inte magiskt löser allt — eftersom vissa kostnads‑ och prestandeöverraskningar kommer från hur arbetslaster är designade, inte från plattformen i sig.
Tema #2: varför ekosystemet kan vara lika viktigt som rå prestanda
En snabb plattform är inte hela historien. För många team beror tiden till värde på om du enkelt kan koppla warehouset till verktygen du redan använder — ETL/ELT‑pipelines, BI‑dashboards, katalog/‑governance‑verktyg, säkerhetskontroller och partnerdatasätt.
Snowflakes ekosystem (inklusive datadelningsmönster och marketplace‑lik distribution) kan korta implementationstider och minska specialbyggd engineering. Detta inlägg beskriver vad "ekosystemdjup" ser ut som i praktiken och hur du utvärderar det för din organisation.
För vem det är
Guiden är skriven för dataansvariga, analytiker och icke‑specialiserade beslutsfattare — alla som behöver förstå avvägningarna bakom Snowflake‑arkitektur, skalning, kostnad och integrationsval utan att drunkna i leverantörsjargong.
Före uppdelningen: varför traditionella warehousen når begränsningar
Traditionella datawarehouses byggdes kring ett enkelt antagande: du köper (eller hyr) en fast mängd hårdvara och kör allt på samma låda eller kluster. Det fungerade bra när arbetslaster var förutsägbara och tillväxt var gradvis — men gav strukturella begränsningar när datavolymer och användarantal accelererade.
Den klassiska modellen: fasta kluster och noggrann kapacitetsplanering
On‑prem‑system (och tidiga cloud‑"lift‑and‑shift"‑distributioner) såg ofta ut så här:
- Ett enda MPP‑kluster hanterade lagring, CPU och minne tillsammans.
- Du dimensionerade klustret för toppbelastning, eftersom omdimensionering var långsamt, riskabelt eller krävde driftstopp.
- Kapacitetsplanering blev ett återkommande projekt: prognostisera tillväxt, motivera budget, beställa hårdvara, installera, migrera.
Även när leverantörer erbjöd "noder" så kvarstod kärnmönstret: skalning betydde ofta att lägga till större eller fler noder i en delad miljö.
Smärtan: långsam skalning, bortkastade kostnader och köbildning
Denna design ger några vanliga huvudvärk:
- Långsam skalning: Om ett kvartalsrapporteringstryck plötsligt behöver mer kapacitet så kan du inte alltid lägga till det snabbt. Du väntar, eller överdimensionerar "för säkerhets skull".
- Idle‑kapacitet: Kluster dimensionerade för toppar står oanvända större delen av tiden — men du betalar ändå (hårdvarukostnad, licenser, driftstid).
- Köbildning under belastning: När flera team kör frågor samtidigt konkurrerar de om samma resurser. Tunga jobb kan blockera interaktiva dashboards, leda till timeouts, frustrerade intressenter och regler som "kör inte den frågan under kontorstid".
Verktyg och integrationer: kraftfulla men ofta sköra
Eftersom dessa warehousen var tätt kopplade till sina miljöer växte integrationer ofta organiskt: kundanpassade ETL‑skript, handbyggda connectors och engångspipelines. De fungerade — tills ett schema ändrades, ett uppströmsystem flyttade eller ett nytt verktyg introducerades. Att hålla allt igång kunde kännas som konstant underhåll snarare än stadig utveckling.
Kärnidén: separera lagring och compute
Traditionella datawarehouses binder ofta ihop två mycket olika jobb: lagring (var din data bor) och compute (kraften som läser, joinerar, aggregerar och skriver den datan).
Lagring vs. compute (enkelt uttryckt)
Lagring är som ett långtidsförråd: tabeller, filer och metadata hålls säkra och billiga, designade för hållbarhet och alltid tillgänglighet.
Compute är som kökspersonalen: det är setet av CPU och minne som faktiskt "lagar" dina frågor — kör SQL, sorterar, skannar, bygger resultat och hanterar flera användare samtidigt.
Nyckelbytet: skala dem oberoende
Snowflake separerar de två så att du kan justera varje del utan att tvinga den andra att förändras.
- Om datavolymen växer, lägger du till mer lagring (vanligtvis inkrementellt och förutsägbart).
- Om rapporttrafiken spikar, lägger du till mer compute (genom att ändra storlek eller lägga till virtuella warehouses) utan att flytta eller duplicera underliggande data.
I praktiken förändrar detta dagliga operationer: du behöver inte "köpa för mycket" compute bara för att lagringen växer, och du kan isolera arbetslaster (t.ex. analytiker vs. ETL) så att de inte saktar ner varandra.
Vad det inte är
Denna separation är kraftfull, men inte magisk.
- Det är inte gratis skalning. Fler eller större warehouses brukar innebära högre compute‑kostnad.
- Det är inte automatisk besparing varje gång. Dåligt skrivna frågor, onödiga refresh‑scheman eller always‑on‑warehouses kan fortfarande driva kostnader.
- Det är inte en ursäkt för att hoppa över planering. Du måste fortfarande välja warehouse‑storlekar, sätta auto‑suspend‑regler och anpassa compute efter affärsbehov.
Värdet ligger i kontroll: betala för lagring och compute på sina egna villkor och matcha dem mot vad dina team faktiskt behöver.
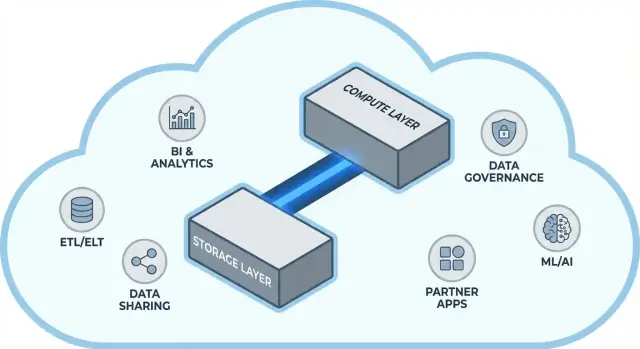
Snowflakes arkitektur i enkla termer
Snowflake är lättast att förstå som tre lager som samarbetar men kan skalas oberoende.
1) Lagring: molnobjektlagring
Dina tabeller finns slutligen som datafiler i din molnleverantörs objektlagring (tänk S3, Azure Blob eller GCS). Snowflake hanterar filformat, kompression och organisering åt dig. Du "kopplar inte på diskar" eller dimensionerar lagringsvolymer — lagringen växer i takt med datan.
2) Compute: virtuella warehouses
Compute paketeras som virtuella warehouses: oberoende kluster av CPU/minne som exekverar frågor. Du kan köra flera warehouses mot samma data samtidigt. Det är den stora skillnaden från äldre system där tunga arbetslaster tenderade att slåss om samma gemensamma resurspool.
Ett separat tjänstelager hanterar systemets "hjärna": autentisering, parsing och optimering av frågor, transaktions/metadatahantering och koordinering. Det här lagret bestämmer hur en fråga ska köras effektivt innan compute tar i datan.
Hur en fråga flödar
När du skickar SQL parser Snowflakes tjänstelager den, bygger en exekveringsplan och lämnar sedan den planen till ett valt virtuellt warehouse. Warehouset läser bara nödvändiga datafiler från objektlagring (och drar nytta av cache när det går), bearbetar dem och returnerar resultat — utan att permanent flytta din basdata in i warehouset.
Konkurens och isolering (utan jargong)
Om många människor kör frågor samtidigt kan du antingen:
- använda separata warehouses för olika team/arbetslaster (workload‑isolation), eller
- aktivera multi‑cluster‑warehouses så Snowflake kan lägga till fler compute‑kluster när efterfrågan spikar och sedan skala tillbaka.
Det är den arkitektoniska grunden för Snowflakes prestanda och kontroll mot "stökiga grannar".
Skalning och concurrency: vad som verkligen förändras
Snowflakes stora praktiska skillnad är att du skalar compute oberoende av data. Istället för att säga "warehouset blir större" får du möjlighet att justera resurser per arbetslasta — utan att kopiera tabeller, repartitionera diskar eller schemalägga driftstopp.
Elasticitet: ändra compute utan att flytta data
I Snowflake är ett virtuellt warehouse compute‑motorn som kör frågor. Du kan ändra dess storlek (t.ex. från Small till Large) på sekunder, och datan ligger kvar i delad lagring. Det betyder att prestandatuning ofta blir en enkel fråga: "Behöver den här arbetslasten mer kraft just nu?"
Det möjliggör också tillfälliga burst: skala upp för en månads‑slut‑stängning och skala sedan tillbaka när toppen är över.
Konkurens: färre köproblem
Traditionella system tvingar ofta olika team att dela samma compute, vilket förvandlar intensiva timmar till en kö. Snowflake låter dig köra separata warehouses per team eller arbetslasta — till exempel ett för analytiker, ett för dashboards och ett för ETL. Eftersom dessa warehouses läser samma underliggande data minskar problemet "min dashboard saktar ner din rapport" och gör prestandan mer förutsägbar.
Avvägningar du kommer märka
Elastisk compute är inte automatiskt framgång. Vanliga fallgropar inkluderar:
- Cold starts: suspenderade warehouses kan ta en stund att återuppta, vilket kan lägga till latens för sällan körda jobb.
- Rätt‑storleksval: överdimensionering slösar pengar; underdimensionering ger långsamma frågor och frustration.
- Behov av styrning: använd auto‑suspend/auto‑resume, resource monitors och tydligt ägarskap så warehouses inte står igång i onödan eller spretar okontrollerat.
Nettoeffekten: skalning och concurrency går från stora infrastrukturprojekt till dagliga driftsbeslut.
Kostnadsmodell: var besparingar sker (och var de inte gör det)
Spåra warehouse‑kostnader
Bygg en lättviktig kostnads‑ och användningshub som hjälper team att se vad som driver compute‑kostnader.
Hur Snowflake fakturerar i praktiken
Snowflakes "betala för det du använder" är i princip två mätare som kör parallellt:
- Compute: debiteras för den tid ditt virtuella warehouse kör (i krediter). Om det är på slår mätaren.
- Lagring: debiteras för mängden data som lagras (plus eventuell extra lagring för funktioner som Time Travel/Fail‑safe).
Denna split är där besparingar kan uppstå: du kan behålla mycket data relativt billigt samtidigt som du bara slår på compute när du behöver det.
Var kostnader lätt kryper upp
De flesta "oväntade" kostnader kommer från compute‑beteenden snarare än ren lagring. Vanliga drivare är:
- Överdimensionerade warehouses (välja större storlek än vad arbetslasten behöver)
- Alltid‑på‑arbetslaster (warehouses som lämnas igång över natt eller helger)
- Ineffektiva frågor (ofiltrerade skanningar, onödiga joins, tunga transformationer som körs upprepade gånger)
- Hög‑konkurrensmönster (många små dashboards som uppdateras konstant)
Att separera lagring och compute gör inte automatiskt frågorna effektiva — dålig SQL kan fortfarande förbruka krediter snabbt.
Praktiska kontroller som fungerar i verkligheten
Du behöver inte en redovisningsavdelning för att sköta detta — bara några skyddsåtgärder:
- Auto‑suspend / auto‑resume för att sluta betala för tomgångstid
- Resource monitors för att varna eller begränsa kreditförbrukning per warehouse/team
- Schemaläggning (kör batchjobb i definierade fönster; pausa dev/test utanför arbetstid)
- Rätt‑storlekstestning: testa mindre warehouse‑storlekar innan du skalar upp
Används väl belönar modellen disciplin: kortkörande, rätt‑dimensionerad compute ihop med förutsägbar lagringstillväxt.
Datadelning och samarbete som en förstaklass‑funktion
Snowflake behandlar delning som något du bygger in i plattformen — inte som en eftertanke limmad på exports, filsläpp och engångs‑ETL.
Dela utan kopiering (i många fall)
Istället för att skicka extrakt runt kan Snowflake låta ett annat konto fråga samma underliggande data genom en säker "share." I många scenarier behöver inte datan dupliceras till ett andra warehouse eller pushas till objektlagring för nedladdning. Konsumenten ser den delade databasen/tabellen som om den vore lokal, medan leverantören behåller kontrollen över vad som exponeras.
Denna "decouplade" metod är värdefull eftersom den minskar dataspridning, snabbar upp åtkomst och minskar antalet pipelines du måste bygga och underhålla.
Vanliga samarbetsmönster
Partner‑ och kunddelning: En leverantör kan publicera kuraterade dataset till kunder (t.ex. användningsanalys eller referensdata) med tydliga gränser — endast tillåtna scheman, tabeller eller vyer.
Intern domändelning: Centrala team kan exponera certifierade dataset till produkt, ekonomi och drift utan att varje team behöver bygga egna kopior. Det stöder en "en uppsättning siffror"‑kultur samtidigt som team får köra sin egen compute.
Styrt samarbete: Gemensamma projekt (t.ex. med en byrå, leverantör eller dotterbolag) kan arbeta mot ett delat dataset samtidigt som känsliga kolumner maskas och åtkomst loggas.
Begränsningar att planera för
Delning är inte "ställ in och glöm." Du behöver fortfarande:
- Governance: tydligt ägarskap, access‑granskningar och policys för PII/regelstyrd data.
- Kontrakt och förväntningar: vem betalar för compute, SLA:er, retention och vad som händer när definitioner ändras.
- Upptäckbarhet: utan katalog och bra namngivning hittar eller litar inte folk på rätt delad data. Koppla shares till dokumentation och din datakatalog om du har en.
Varför ekosystem kan vara lika viktigt som prestanda
Ett snabbt warehouse är värdefullt, men hastighet ensam avgör sällan om ett projekt levereras i tid. Det som ofta avgör är det omgivande ekosystemet: färdiga kopplingar, verktyg och kunskap som minskar specialarbete.
I praktiken inkluderar ett ekosystem:
- Connectors till källor och destinationer (SaaS‑appar, databaser, streamingverktyg)
- Partnerverktyg för ingestion, transformation, BI, datakvalitet och observability
- Appar och native‑integrationer som körs nära datan
- Mallarkitektur och referensdesign (vanliga modeller, mönster, driftsättningsguider)
- Community‑kunskap: exempel, forum, meetups och rekryteringsmöjligheter
Varför ekosystem ofta slår benchmarks för leveranstid
Benchmarks mäter en smal skiva av prestanda under kontrollerade förhållanden. Verkliga projekt lägger mesta tiden på:
- Att få in data pålitligt och inkrementellt
- Modellera, testa och dokumentera dataset
- Operations (övervakning, larm, kostnadskontroll)
- Säkerhetsgranskningar, åtkomstkontroller och revisioner
Om din plattform har mogna integrationer för dessa steg slipper du bygga och underhålla limkod. Det förkortar implementationstider, förbättrar tillförlitlighet och gör det enklare att byta team eller leverantör utan att skriva om allt.
En enkel utvärderingslins: täckning, kvalitet, underhåll
När du bedömer ett ekosystem, leta efter:
- Täckning: stöder det dina nyckelkällor, BI‑verktyg, orkestrering och governance‑behov?
- Kvalitet: är connectors aktivt underhållna, väl dokumenterade och beprövade i din skala?
- Underhållbarhet: hur mycket löpande arbete krävs — uppgraderingar, breaking changes, debugging och support?
Prestanda ger kapacitet; ekosystemet avgör ofta hur snabbt du kan omvandla den kapaciteten till affärsresultat.
Integrations‑ekosystem: få data in, ut och i bruk
Skicka en ops‑dashboard
Skapa en intern ops‑portal som läser Snowflake‑data utan att du bygger hela stacken för hand.
Snowflake kan köra snabba frågor, men värde uppstår när data pålitligt rör sig genom din stack: från källor in i Snowflake och ut igen till verktyg som människor använder dagligen. "Sista milen" avgör ofta om en plattform känns enkel eller ständigt skör.
Huvudkategorier av integrationer att planera för
De flesta team behöver en blandning av:
- ELT/ETL för att hämta från databaser, SaaS‑appar, filer och objektlagring.
- BI och analys‑verktyg för dashboards, självbetjäningsexploration och semantiska lager.
- Reverse ETL för att skicka kuraterad data tillbaka till CRM, marknadsföring och supportsystem.
- Orkestrering för schemaläggning, beroenden, backfills och promotion mellan miljöer.
- Streaming för nära‑realtids‑händelser och change data capture.
- ML‑verktyg för feature‑pipelines, träningsworkflows och modellövervakning.
Frågor att ställa innan du väljer connectors
Inte alla "Snowflake‑kompatibla" verktyg fungerar likadant. Vid utvärdering, fokusera på praktiska detaljer:
- Är connectorn certifierad/stödd (och av vem)? Vad är eskaleringsvägen?
- Kan den hantera inkrementella laddningar smidigt (CDC, tidsstämplar, high‑water marks)?
- Hur hanterar den schema‑drift — nya kolumner, typändringar, borttagna fält?
- Vilka garantier finns för retries, deduplicering och exactly‑once vs at‑least‑once?
Ignorera inte drift
Integrationer behöver också day‑2‑beredskap: övervakning och larm, lineage/katalog‑hooks och incident‑workflows (ticketing, jour, runbooks). Ett starkt ekosystem är inte bara fler logotyper — det är färre överraskningar när pipelines går sönder kl. 02:00.
Styrning, säkerhet och förtroende i skala
När team växer är det svåraste inom analys ofta inte hastighet — det är att se till att rätt personer har rätt data för rätt ändamål, med bevis på att kontrollerna fungerar. Snowflakes governance‑funktioner är designade för den verkligheten: många användare, många dataprodukter och frekvent delning.
Grundläggande governance som håller
Börja med tydliga roller och en least‑privilege‑inställning. Istället för att ge åtkomst direkt till individer, definiera roller som ANALYST_FINANCE eller ETL_MARKETING, och ge sedan dessa roller åtkomst till specifika databaser, scheman, tabeller och (när det behövs) vyer.
För känsliga fält (PII, finansiella identifierare) använd maskningspolicies så att människor kan fråga dataset utan att se råa värden om inte deras roll tillåter det. Para det med audit: spåra vem som frågade vad och när, så säkerhets‑ och regelefterlevnadsteam kan svara utan gissningar.
Varför governance förändrar delning och självbetjäning
God governance gör datadelning säkrare och mer skalbar. När din delningsmodell bygger på roller, policies och auditerad åtkomst kan du tryggt möjliggöra självbetjäning (fler användare som utforskar data) utan att öppna dörren för oavsiktlig exponering.
Det minskar också friktion för compliance: policies blir återupprepbara kontroller istället för engångsundantag. Det spelar roll när dataset återanvänds över projekt, avdelningar eller externa partners.
Praktiska tips som förebygger framtida smärta
- Namngivningskonventioner: standardisera namn för databaser/scheman som signalerar syfte och känslighet (t.ex.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Konsistens snabbar upp granskningar och minskar misstag.
- Miljöseparation: håll DEV/TEST/PROD logiskt separerade, med striktare kontroller i PROD. Behandla produktionsdata som undantag, inte standard.
- Åtkomstgranskningar: sätt en frekvens (månatligt för hög‑riskdata, kvartalsvis annars). Granska rollmedlemskap, inaktiva användare och privilegierade roller.
Förtroende i skala handlar mindre om en "perfekt" kontroll och mer om ett system av små, pålitliga vanor som håller åtkomst avsiktlig och förklarbar.
Workloads och bästa praxis‑mönster
Planera din Snowflake‑pilot
Skissa en 2–4 veckors pilotplan och genomför den steg för steg i planeringsläge.
Snowflake briljerar ofta när många människor och verktyg behöver fråga samma data av olika anledningar. Eftersom compute paketeras i oberoende "warehouses" kan du mappa varje arbetslasta till en form och schema som passar.
Vanlig arbetslastmappning
Analys & dashboards: Placera BI‑verktyg på ett dedikerat warehouse dimensionerat för jämn, förutsägbar frågevolym. Detta håller dashboard‑refreshes från att sinka ad hoc‑utforskning.
Ad hoc‑analys: Ge analytiker ett separat warehouse (ofta mindre) med auto‑suspend aktiverat. Du får snabb iteration utan att betala för tomgång.
Data science & experiment: Använd ett warehouse dimensionerat för tyngre skanningar och tillfälliga bursts. Om experiment spikar kan du temporärt skala upp detta warehouse utan att påverka BI‑användare.
Data‑appar & embedded analytics: Behandla apptrafik som en produktionstjänst — separat warehouse, konservativa timeouts och resource monitors för att undvika överraskande kostnader.
Om du bygger lätta interna dataappar (t.ex. en ops‑portal som frågar Snowflake och visar KPI:er) är en snabb väg att generera ett fungerande React + API‑skelett och iterera med intressenter. Plattformar som Koder.ai (en vibe‑kodningsplattform som bygger webb/server/mobilappar från chat) kan hjälpa team att prototypa dessa Snowflake‑backade appar snabbt och sedan exportera källkoden när ni är redo att driftsätta.
Bästa praxis som håller över tid
En enkel regel: separera warehouses efter målgrupp och syfte (BI, ELT, ad hoc, ML, app). Para det med goda frågevanor — undvik breda SELECT *, filtrera tidigt och håll koll på ineffektiva joins. På modelleringssidan, prioritera strukturer som matchar hur folk frågar (ofta ett rent semantiskt lager eller väl definierade marts) istället för att överoptimera fysiska layouter.
När överväga alternativ eller komplement
Snowflake ersätter inte allt. För hög‑throughput, låg‑latens transaktionella arbetslaster (typisk OLTP) är en specialiserad databas ofta bättre, med Snowflake för analys, rapportering, delning och downstream dataprodukter. Hybridupplägg är vanliga — och ofta mest praktiska.
Migrerings‑överväganden: vad att planera innan flytt
En Snowflake‑migration är sällan ett rent "lift and shift." Splitten mellan lagring och compute förändrar hur du dimensionerar, tweakar och betalar för arbetslaster — så planering i förväg undviker överraskningar senare.
Ett praktiskt migrationsflöde
Börja med en inventering: vilka datakällor matar warehouset, vilka pipelines transformerar det, vilka dashboards beror på det och vem äger varje del. Prioritera sedan efter affärspåverkan och komplexitet (t.ex. kritisk finansrapportering först, experimentella sandlådor senare).
Nästa steg, konvertera SQL och ETL‑logik. Mycket standard‑SQL överförs, men detaljer som funktioner, datumhantering, procedurkod och mönster med temp‑tabeller behöver ofta omskrivning. Validera tidigt: kör parallella outputs, jämför radantal och aggregat, och kontrollera kantfall (nulls, tidszoner, dedupliceringslogik). Slutligen planera cutover: ett freeze‑fönster, rollback‑väg, och en tydlig "definition of done" för varje dataset och rapport.
Typiska risker att vakta för
Dolda beroenden är vanligast: ett spreadsheet‑extrakt, en hårdkodad connection‑string, ett nedströmsjobb ingen minns. Prestandaöverraskningar kan inträffa när gamla tuning‑antaganden inte gäller (t.ex. överanvända små warehouses, eller många små frågor utan att tänka på koncurrens). Kostnadsspikar kommer ofta från att lämna warehouses igång, okontrollerade retries eller duplicerade dev/test‑arbetslaster. Behörighetsluckor uppstår när du migrerar från grova roller till mer granulär governance — tester bör inkludera körningar som "least privilege"‑användare.
Change management (hoppa inte över detta)
Sätt en ägarskapsmodell (vem äger data, pipelines och kostnader), leverera rollbaserad träning för analytiker och ingenjörer, och definiera en supportplan för de första veckorna efter cutover (jourrotation, incident‑runbook och en plats för att rapportera problem).
Att välja en modern dataplattaform handlar inte bara om topp‑benchmarkhastighet. Det handlar om huruvida plattformen passar dina verkliga arbetslaster, ert sätt att arbeta och de verktyg ni redan litar på.
En praktisk utvärderingschecklista
Använd dessa frågor för att styra din kortlista och samtal med leverantörer:
- Arbetslaster: Kör ni mest schemalagda dashboards, ad hoc‑analys, data science, ELT/ETL eller kundvända appar? Behöver ni förutsägbar batch‑fönster eller elastisk burst‑kapacitet?
- Konkurrensbehov: Hur många människor (eller applikationer) kommer att fråga samtidigt, och hur "spikigt" är användningen under kontorstid?
- Datadelningskrav: Behöver ni dela live‑data med partners, affärsenheter eller kunder utan att skicka filer? Förväntar ni er att konsumera tredjepartsdatasets?
- Verktygsfit: Integrerar era BI‑verktyg, orkestrering, katalog och CI/CD‑workflows smidigt? Vad går sönder om ni flyttar?
- Governance och säkerhet: Behöver ni finmaskig åtkomstkontroll, audit‑spår, maskning, retention‑policys och tydlig rollseparation?
- Kostnadsbegränsningar: Vilka kostnader spelar störst roll — löpande kostnad, peak‑kostnad eller förmågan att stänga av compute? Hur ska ni förebygga "always‑on"‑slöseri?
En kort pilotplan (2–4 veckor)
Välj två eller tre representativa dataset (inte leksaksprov): en stor faktatabell, en rörig semistrukturerad källa och en affärskritisk domän.
Kör sedan verkliga användarfrågor: dashboards under morgonpeak, analytiker‑utforskning, schemalagda laddningar och några värst‑fall‑joins. Mät: frågetid, koncurrensbeteende, tid till ingång, operativ insats och kostnad per arbetslasta.
Om en del av din utvärdering är "hur snabbt kan vi leverera något användbart", överväg att lägga till en liten leverans i piloten — till exempel en intern metrics‑app eller ett styrt data‑förfrågningsarbetsflöde som frågar Snowflake. Att bygga det tunna lagret avslöjar ofta integrations‑ och säkerhetsrealiteter snabbare än benchmarks ensam, och verktyg som Koder.ai kan snabba upp prototyp‑till‑produktion genom att generera appstrukturen via chat och låta dig exportera koden för långsiktig drift.
Föreslagna nästa steg
Om du vill ha hjälp att uppskatta kostnader och jämföra alternativ, börja med /pricing.
För migrerings‑ och governance‑rådgivning, bläddra i relaterade artiklar i /blog.